阿里云暑期实习提前批一面(技术服务平台)|讲解|0301
上一篇讲解了一位同学的快手一面面经,今天继续挑选他0229的阿里云一面面经进行讲解分析,参考回答和学习资料指引。主要是Java八股和少量数据库Mysql的考察。
本文也是 《热门面经讲解》专栏 系列文章之一,大家可以点个关注,我会持续更新

感谢这位同学的分享,预祝顺利offer!!

1.你的技术栈是Java,讲一下Java面向对象的特点?
- 你实际应用过“多态”吗,举一个具体例子,和重载有什么关系?
讲解: 基础面试题。考察封装继承多态,并且需要举例子。估计大家回答都没问题,就是举例可能有点懵。
参考回答:
1. 面向对象的三大基本特性:封装、继承和多态。
- 封装:封装是把对象的状态信息隐藏在对象内部,不允许外部程序直接访问对象内部信息,而是通过该类提供的方法进行操作。封装的主要目的是增加安全性和简化编程,用户只需要知道对象提供哪些方法,而不需要了解内部细节。
- 继承:继承是从已有的类派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力。继承实现了代码的复用,提高了软件开发的效率,也便于创建更为复杂的类。
- 多态:多态是指允许不同类的对象对同一消息作出响应。即同一操作作用于不同的对象,可以产生不同的结果。多态的实现依赖于继承、接口和重写。
2.多态示例:
- 比如在一个绘图系统中,可能会有圆形、矩形、三角形等多种图形,每种图形都有自己的绘制方法。我们可以定义一个Shape接口或抽象类,其中包含一个draw方法,然后让各种具体的图形类去实现或继承这个接口/抽象类,并覆盖draw方法。
public interface Shape {
void draw();
}
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Drawing a circle");
}
}
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Drawing a rectangle");
}
}
- 在主程序中,我们可以创建一个Shape类型的数组或列表,将不同种类的图形对象添加进去,然后遍历这个集合,调用每个对象的draw方法。由于每个对象都是Shape接口的实现类,所以它们都可以响应draw消息,但具体的实现方式是不同的,这就体现了多态。
public class Main {
public static void main(String[] args) {
List<Shape> shapes = new ArrayList<>();
shapes.add(new Circle());
shapes.add(new Rectangle());
for (Shape shape : shapes) {
shape.draw();
}
}
}
3.多态与重载的关系
多态: 主要关注的是不同对象对同一消息的响应不同,它依赖于继承、接口和方法重写(Overriding)。在上面的例子中,Circle和Rectangle都实现了Shape接口的draw方法,但具体的实现不同,这就是多态的体现。
重载: 则是在同一个类中,方法名相同但参数列表不同(包括参数个数、类型或顺序),与返回值类型无关。重载是编译时多态的一种表现,它在编译时就能确定调用哪个方法,而多态是运行时多态,只有在运行时才能确定调用哪个实现的方法。
学习指引:
面试学习: 《JavaGuide》:面向对象三大特征
2.Java中的HashMap了解吗?
- 聊聊HashMap的底层结构
- 为什么要引入红黑树,而不用其他树?
- 红黑树和二叉搜索树、AVL树有什么区别?
- HashMap会出现红黑树一直增高变成无限高的情况吗?
- HashMap读和写的时间复杂度是多少?
讲解: 直接问HashMap的结构,那就选Java8版本来讲解就行,如果面试官想问Java8之前的,那就等他问了再答。
参考回答:
1. 聊聊HashMap的底层结构: Java 8中的HashMap底层结构主要由数组和链表(或红黑树)组成。这个数组被称为“桶数组”,其中每个元素是一个桶(Bucket),桶中存放的是链表或红黑树。当HashMap中的元素较少且分布均匀时,主要使用链表存储元素;但当链表长度超过一定阈值时,外加数组长度大于64时,链表会转换为红黑树以提高查询效率。
2. 为什么选红黑树,和二叉搜索树、AVL树有什么区别?
- 二叉搜索树:在二叉搜索树中,左子节点的值小于根节点的值,右子节点的值大于根节点的值。这使得二叉搜索树在查找操作上具有优势。然而,二叉搜索树可能退化为线性结构,即链表,当数据插入顺序有序或接近有序时,其查找效率会大大降低,时间复杂度可能达到O(n)。
- AVL树:是一种高度平衡的二叉搜索树,它要求每个节点的左右子树的高度差不超过1。这种严格的平衡条件使得AVL树在查找操作上具有很高的效率,时间复杂度为O(log n)。然而,为了维护这种严格的平衡,AVL树在插入和删除操作时需要进行频繁的旋转调整,这增加了维护成本。因此,AVL树适合用于查找操作频繁但插入和删除操作较少的场景。
- 红黑树:红黑树是一种近似平衡的二叉搜索树,它通过一系列性质(如节点颜色、黑高)来维护树的平衡。与AVL树相比,红黑树的平衡条件相对宽松,因此在插入和删除操作时的维护成本较低。虽然红黑树的查找效率略低于AVL树,但其综合性能较好,适用于各种操作(插入、删除和查找)都较频繁的场景。此外,红黑树的高度近似为2log n,在实际应用中表现出良好的性能。
3. HashMap会出现红黑树一直增高变成无限高的情况吗? 不能无限增长。当集合中的节点数超过了阈值,HashMap会进行扩容,这时原始的红黑树节点会被打散,可能会退化成链表结构。
4. HashMap读和写的时间复杂度是多少? 理想情况下是O(1)常数时间复杂度。hash冲突严重的情况下可能会退化为O(n)或者O(log n),即链表和红黑树的复杂度。 但采用高质量的哈希函数、扩容机制和链表转换为红黑树等优化策略,大多数情况下是可以保证常数时间复杂度的。
学习指引:
面试学习: 《JavaGuide》| HashMap 源码分析
3.HashMap是线程安全的吗?怎么解决?
讲解:
一般这个面试题会作为一个引子,引导到ConcurrentHashMap的考察上面去。但是这里好像面试官没有细问了。
参考回答:
不是。
解决:
- 使用Collections.synchronizedMap()方法
- 使用ConcurrentHashMap
学习指引: 面试学习 《JavaGuide》|HashMap为什么线程不安全
4.解决线程安全问题还有哪些办法?
讲解:
这个题面试官的目的就是想引导话题到并发的考察上,通过你的举例,追问具体并发知识点的考察上。比如你说synchronized,那有可能就继续接着问,这里其实太多了,你就该可以说些你熟悉的,故意引导面试官去你熟悉的领域。
参考回答:
使用synchronized关键字;使用volatile关键字;使用Lock接口及其实现类;使用原子变量类;使用并发容器;使用ThreadLocal;使用并发工具类,如信号量(Semaphore);使用阻塞队列;使用线程池等。
学习指引:
面试学习:《JavaGuide》| 并发编程面试题
系统学习:书籍《Java并发编程艺术》,讲得不错但有点老;
5.volatile关键字是如何保证内存可见性的?底层是怎么实现的?
- 为什么需要保证内存可见性?
- volatile为什么要禁止指令重排,能举一个具体的指令重排出现问题的例子吗
讲解:
volatile关键字和Synchronized关键字考察点都挺多的,需要重点掌握。
参考回答:
1.如何保证内存可见性的?: Java的内存模型中,每个线程会有一个私有本地内存的抽象概念,正常情况下线程操作普通共享变量时都会在本地内存修改和读取,那就导致别的线程感知不到,出现可见性问题。而当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主内存,当有其他线程需要读取时,它也会去主内存中读取新值。这样就解决的可见性问题。
2.底层实现:
- 内存屏障(Memory Barriers):内存屏障确保处理器按照程序指定的顺序执行指令,防止编译器和处理器对指令进行重排序,从而保证了volatile变量的读写操作对其他线程立即可见。
- 缓存一致性协议(如MESI):缓存一致性协议确保多个处理器核心之间的缓存数据保持一致。当某个处理器修改了volatile变量的值时,该协议会确保其他处理器能够看到这个修改,从而保证了内存可见性。
- lock前缀指令(针对某些架构):在某些架构下,volatile变量的访问会被转换为带有lock前缀的指令。这些指令会锁定内存总线,确保对volatile变量的操作是原子的,并且会立即将变量的值写回到主内存,从而实现了内存可见性。
3.volatile为什么要禁止指令重排,能举一个具体的指令重排出现问题的例子吗?
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
例子中,uniqueInstance 采用 volatile 关键字修 饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为 uniqueInstance 分配内存空间
- 初始化 uniqueInstance
- 将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
学习指引:
系统学习:书《Java并发编程艺术》|3.4 volatile内存语义|3.8 双重检查锁定
6.Synchronized的底层原理是什么,锁升级的过程了解吗?
- 线程是怎么确定拿到锁的?锁信息具体放到哪的?
讲解: Synchronized原理,Java并发考察重点,着重掌握。
参考回答:
Synchronized的底层原理是什么?
Synchronized的底层实现依赖于JVM的Monitor机制。每个Java对象都有一个与之关联的Monitor,它控制对该对象的访问。线程通过执行monitorenter指令尝试获取Monitor锁,若成功则执行同步代码;若失败则阻塞。执行完毕后,通过monitorexit指令释放锁。这种机制确保了同一时间只有一个线程能执行synchronized保护的代码,实现线程同步。
锁升级的过程了解吗?
Synchronized的锁升级过程是为了优化同步性能,在Java虚拟机中,锁会经历无锁、偏向锁、轻量级锁和重量级锁这几个状态。当线程首次访问synchronized代码块时,会尝试使用偏向锁来减少同一线程重复获取锁的开销;如果有多个线程竞争,偏向锁会升级为轻量级锁,通过自旋等待来减少线程挂起的次数;当竞争进一步加剧时,轻量级锁会升级为重量级锁,这时会通过操作系统级别的互斥量来实现严格的线程同步,以确保线程安全。整个升级过程是根据锁的竞争激烈程度来动态调整的,以提高程序的并发性能。
线程是怎么确定拿到锁的?锁信息具体放到哪的?
- 线程确定拿到锁的过程:是通过检查锁的状态并尝试获取锁来实现的。在JVM中,锁信息具体是存放在Java对象头中的。当一个线程尝试进入synchronized代码块或方法时,JVM会检查对应对象的锁状态。如果对象的锁未被其他线程持有,即锁状态为可获取,那么该线程将成功获取锁并进入临界区执行代码。
- 锁的状态信息是Java对象头中的:包括锁是否被持有、持有锁的线程标识等。JVM通过操作对象的头部信息来实现锁的获取、释放以及等待队列的管理。当线程成功获取锁后,对象的头部信息会被更新为当前线程的标识,表示该线程拥有了这个锁。其他线程在尝试获取同一个锁时,会检查对象的头部信息,如果锁已经被其他线程持有,它们将会被阻塞直到锁被释放。
学习指引:
面试学习:《JavaGuide》|synchronized关键字
理解学习:《网课:Java并发编程78讲》|如何看到 synchronized 背后的“monitor 锁”?
系统学习:书《并发编程艺术》|2.2 synchronized的实现原理与应用
7.Synchronized加锁和ReentrantLock加锁有什么区别?
讲解: Synchronized系列常考面试题。
参考回答:
- 底层实现不同:synchronized 是依赖于 JVM 实现的,具体实现并没有直接暴露给我们;ReentrantLock 是 JDK 层面实现的,所以我们可以通过查看它的源代码,来看它是如何实现的。
- ReentrantLock 比 synchronized 增加了一些高级功能: 等待可中断;可实现公平锁;可实现选择性通知(锁可以绑定多个条件Condition)
学习指引:
面试学习:《JavaGuide》|synchronized-和-reentrantlock-有什么区别
理解学习:《网课:Java并发编程78讲》|synchronized 和 Lock 孰优孰劣,如何选择?
8.线程池了解过吗?有哪些核心参数?
- 为什么核心线程满了之后是先加入阻塞队列而不是直接加到总线程?
- 核心线程数一般设置为多少?
- IO密集型的线程数为什么一般设置为2N+1?
讲解: Java并发编程,据统计,线程池是最高频的考察点!
参考回答:
有哪些核心参数?
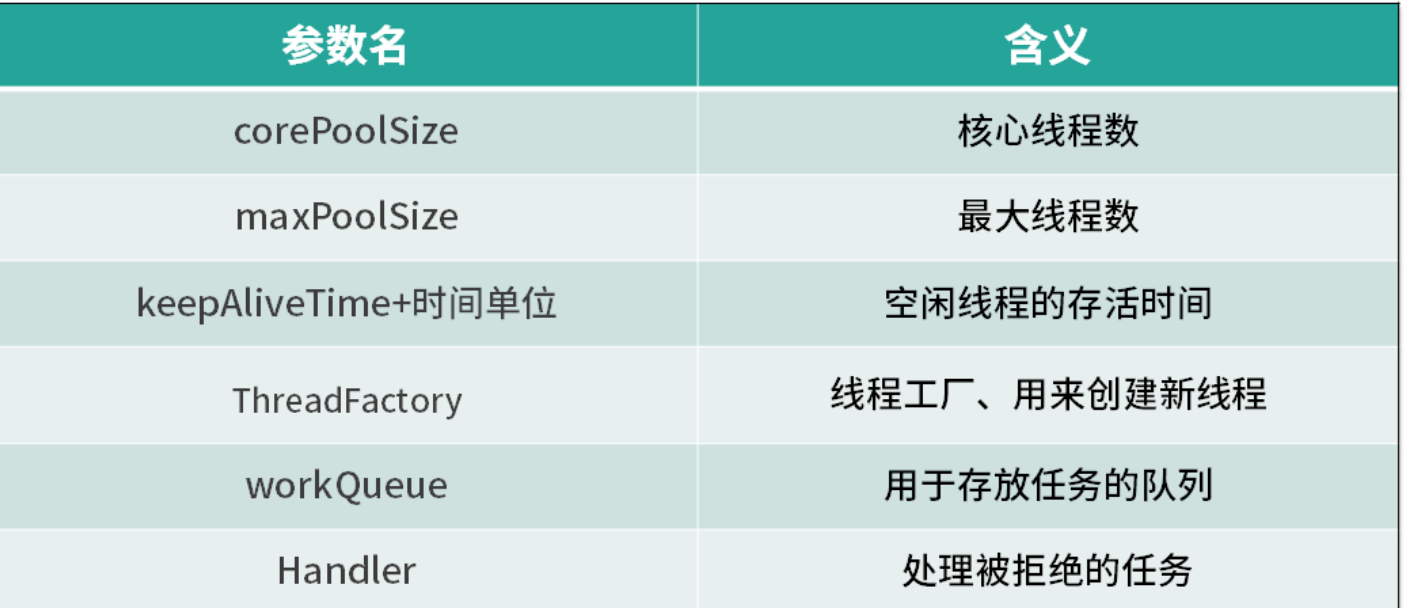
为什么核心线程满了之后是先加入阻塞队列而不是直接加到总线程? 将任务加入阻塞队列可以起到缓冲的作用,使得任务的处理更加平滑。如果直接创建新线程来处理任务,可能会导致线程数过多,从而增加系统的开销和复杂性.
核心线程数一般设置为多少?IO密集型的线程数为什么一般设置为2N+1? 核心线程数的设置并没有固定的公式或标准值,它取决于具体的应用场景、任务类型、系统资源等多个因素。一般来说,核心线程数应该根据CPU的核心数、任务的性质(CPU密集型还是IO密集型)、以及期望的响应时间等因素来进行调整。
对于CPU密集型任务,核心线程数通常设置为接近或等于CPU的核心数,以避免过多的线程上下文切换导致性能下降。而对于IO密集型任务,线程数可以设置得更多一些,因为IO操作通常不需要占用CPU的全部计算能力,更多的线程可以提高任务的并发处理能力。
这里的“2N+1”可能是一个经验值或者特定场景下的优化建议,但并不是普遍适用的规则。实际上,线程数的设置应该根据具体的任务特性、系统资源和性能目标来进行调整和优化。 最好是结合监控策略+动态配置策略进行动态调优。
学习指引:
面试学习:《JavaGuide》| 线程池
理解学习:《美团技术团队》|Java线程池实现原理及其在美团业务中的实践
9.聊聊MySQL的索引结构,为什么使用B+树而不用B树?
- 你是怎么建立索引的?一般是建立哪些字段的索引呢?
- 怎么确定语句是否走了索引?
- 如果要建立联合索引,字段的顺序有什么需要注意吗?
解析:: 考察mysql InnoDB引擎的数据结构B+树,需要回答出来为什么要选用B+树,而不是B树,也不是二叉树。 为什么B+树比他们合适,比他们块。
参考回答:
MySQL 默认的存储引擎 InnoDB 采用的是 B+ 作为索引的数据结构,原因有:
1.B+ 树的非叶子节点不存放实际的记录数据,仅存放索引,因此数据量相同的情况下,相比存储即存索引又存记录的 B 树,B+树的非叶子节点可以存放更多的索引,因此 B+ 树可以比 B 树更「矮胖」,查询底层节点的磁盘 I/O次数会更少。(为什么不选二叉树也有类似原因)
2.B+ 树有大量的冗余节点(所有非叶子节点都是冗余索引),这些冗余索引让 B+ 树在插入、删除的效率都更高,比如删除根节点的时候,不会像 B 树那样会发生复杂的树的变化;
3.B+ 树叶子节点之间用链表连接了起来,有利于范围查询,而 B 树要实现范围查询,因此只能通过树的遍历来完成范围查询,这会涉及多个节点的磁盘 I/O 操作,范围查询效率不如 B+ 树。
你是怎么建立索引的?一般是建立哪些字段的索引呢?
- 字段有唯一性限制的,比如商品编码;
- 经常用于 WHERE 查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
- 经常用于 GROUP BY 和 ORDER BY 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
怎么确定语句是否走了索引? 最常用的是使用EXPLAIN命令
如果要建立联合索引,字段的顺序有什么需要注意吗?
- 查询频率和过滤性: 将查询中最常用作过滤条件的字段放在索引的前面。选择具有高区分度(即唯一值多)的字段放在前面,这样索引可以更快地缩小搜索范围。
- 排序和分组: 如果查询经常需要按照某个字段排序或分组,考虑将该字段包含在索引中,并根据排序的顺序来确定字段在索引中的位置。
- 范围查询: 如果查询中包含范围查询(如 BETWEEN, <, <=, >, >=),则应该将范围查询涉及的字段放在索引的最后,因为一旦MySQL在索引中遇到范围查询,它就不会再继续使用索引中的后续字段。
- 覆盖索引 : 如果查询只需要访问索引中的信息,而无需访问表中的行(即覆盖索引查询),则确保索引包含查询所需的所有字段。在这种情况下,字段的顺序应该根据查询的需要来确定。
学习指引:
面试学习
《小林 coding》|为什么 MySQL 采用 B+ 树作为索引?
《掘金专栏:全解Mysql数据库》|(五)MySQL索引应用篇:建立索引的正确姿势与使用索引的最佳指南!
关联阅读:
阿里云相关:
该同学相关:
本文也是 《热门面经讲解》专栏 系列文章之一,大家可以点个关注,
#面经##阿里云##实习##阿里##暑期实习#挑选近期热门真实后端面经进行讲解分析,给出:个人分析+参考回答+学习资料指引。


 查看11道真题和解析
查看11道真题和解析