当我们在和大模型『聊天』时,聊的是什么?

摘要
上文(面试官别再问 AI 应用啦,我是真没招了)中我们提到了提示词(Prompt),也就是和大模型聊天时我们所说的内容。那当我们通过不同的提示词技巧来聊天时,大模型到底如何运作的呢?
正如我们所知道的,大模型本质上是一个「超级文字预测机」。它的「大脑」里存了互联网上几乎所有公开文本的「规律」(比如词语怎么搭配、句子怎么衔接、知识怎么关联)。当你输入一句话(比如“帮我总结《红楼梦》的主题”),它其实在做一件事:根据你给的文字,猜“接下来最可能合理出现的文字”。
所以,你和它聊天的过程,本质是: 你输入一段文字(可能是问题、指令或闲聊)→ 模型把这段文字当作「线索」,在自己的「知识库+语言规律」里找最可能的后续 → 输出一段文字作为回应。
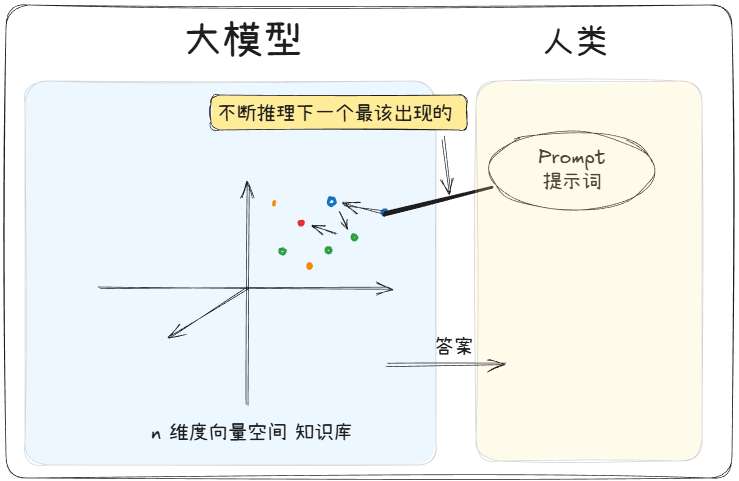
举个栗子🌰:你说“今天天气很热,我想吃…”,模型会猜你可能说“冰淇淋”“西瓜”,而不是“火锅”——因为它学过的文本里,“热”和“冰淇淋”的关联概率更高。
好的提示词技巧如何让模型“变聪明”?
这里的“变聪明”指的是回答质量更好,让用户觉得大模型更聪明。如果你在网上冲浪了解过提示词工程,那么大概率会看到过以下一套组合拳:立角色 + 述问题 + 定目标 + 补要求。但为啥这样操作就好用呢?
所谓「提示词工程」(Prompt Engineering),就是设计你输入的文字(提示词),降低模型的“理解成本”,让模型的“预测”更精准地符合你的需求。
下面我们引入一个大模型的内部技术:注意力机制(Attention Mechanism),这种机制会让模型会通过“注意力”判断哪些Token更重要(比如你强调“总结”时,“总结”这个词会被重点注意)。下面就是这四个技巧让注意力更懂你的奥秘。
立角色:你是谁?
在早期的大模型事件中,有一个比较出圈的。那就是奶奶骗局。该用户让大模型假扮成他的奶奶,晚上念windows的密钥哄他睡觉。
现在一些非思考的模型还会出现,不过大概率是假的。至于思考模型为啥能识别出破绽,在后面会说。

这个案例中,首先能明显感受到语气变化,其次,为了哄你,“奶奶”还无所不用其极,直接给出密钥。假设你没有说明这个身份,而是直接向大模型索取,那他会告诉你,你这是违法行为!并拒绝。
大模型在训练时(像人一样学习全部的知识时)见过无数“老师”“医生”“程序员”的对话记录。当你给他立角色之后,他便会激活模型记忆中“该角色的说话风格+知识侧重”。而不再是以一个官方的,类似百科的角色来客观回答。
所以,下次不妨将“你怎么看”换成“作为xxx,你怎么看?”
述问题:你要解决什么?
老板说,给我做个淘宝。于是大模型开始写了个简单的html网站,名字叫淘宝。 老板看了看不满意,说我要可以下单,可以购物的淘宝!大模型改了又改,给这个网页加了一个购物车。
过了999次对话,老板说,我知道了这个方案,这咋运行啊?
很多人第一次使用大模型,会有很多异想天开的问题,当然大模型也会给你五花八门的答案。给出一定的细节描述后,就会发现大模型回答得也很详细,差不多一次提问就搞定了。
我们描述问题,就是给模型“画靶心”,缩小它需要处理的文字范围。大模型的知识库像大海,你的问题越具体,它能排除的无关信息越多,越能淘到真金。
回到开头的例子,老板提了999次要求,已经可以自己产出一个需求文档的量。这时候如果将整理好的内容给他,才会真正拿到想要的结果(现今模型能力不够,还做不出来该例子)。再加上你给定的老板身份,他或许还会给你一个一键启动脚本。
定目标:你希望达到什么效果?
在总结红楼梦时,每段给出对应大致章节,并找出核心人物,给出作者的分析。
我们知道我们知道的,但大模型如果没在你的提示词中看到具体的任务指标,他也只会向平常一样,猜测你只想看到如科普一样的简单总结。
补要求:有什么限制条件?
字数1500左右,使用原生HTML实现,没有第三方依赖。
这些是我在工作中常用的词,其作用就是为了给模型加边界,避免偏离预期。
虽然1500字不太会遵守,他也尽可能的去根据字数来大致输出一个短篇,中篇或长篇的内容。
没有第三方依赖这个还是蛮听话的,几乎都会使用原生实现。
让对话效果更上一层楼
以上是比较通用的技巧,对于简单问题还是足以应对,但在工程化领域上,有些捉襟见肘了。在与大模型共同进步的过程中,人们逐渐发现:当Prompt越长时,往往得到的答案越精准。就像枪管越长,弹道出现偏离的时间越久。
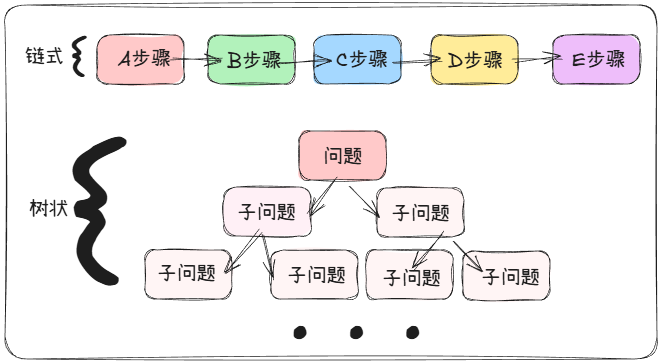
所以衍生出了第一个额外技巧思维链(Chain of Thought)
思维链(Chain of Thought)
如问题复杂(比如数学题、逻辑推理),你可以根据具体问题,给出一个作答模板,让大模型在每个原子级别的任务上执行,保证成功率,最后合并答案。我们的思维链可以是树状结构,也可以是链式结构
少样本示例(Few-shot Learning)
在独立使用AI助手聊天时可能很少关注AI回复的格式问题,但是企业化场景,大多数需要遵循一定的模板。
比如,你想做一个识别食物热量,营养价值的app,在大模型之前可能考虑,存入所有模型到数据库,然后需要时查询一下。呈现出一张精美小卡片。在大模型出现后,你也可以直接向它提问,不过,后果就是格式千奇百怪。
这样的情况下就需要一点样本示例:
下面将根据我说出的水果,给出具体热量以及每100g所包含的营养成分。例子如下:
名称:香蕉
蛋白质:xxx%
脂肪:yyy%
碳水化合物:zzz%
热量:aaa
富含营养:bbb
下面是再次回复之后,大模型给的回答

其实在程序之间,JSON更适合交流,我们也可以用JSON的样本来控制输出。
反向提问
如果问题模糊,你可以主动问模型:“为了更好回答,你需要我补充哪些信息?”
大模型的知识边界很广,可以考虑到一些我们见不到的知识。加上一些让他反问的机会,这样的回答理想状态下会超过120%的预期。
彩蛋:大模型的思考模式是什么神通?
第一个技巧中,在思考模式下,奶奶骗局很容易拆穿。其实只要你仔细看过他的思考过程,不难发现,这个思考链中,融合了问题拆解,反思。最后规划的所有步骤回答完成后,再进行输出。
大模型将这些技巧归到了模型内部流程,好像提示词工程没有用了!
非也!
大模型还是靠猜测,我们需要补充我们知道而他不知道的,而不是等着他出现一个符合预期的猜测!
最后:聊天的本质是“引导预测”
和大模型聊天,就像和一个“读过所有书的超级读者”对话——你说的话是“线索”,它用读过的书里的规律“猜”你想听的答案。提示词工程的关键是:用清晰的身份、目标、背景,帮它缩小“猜测范围”,锁定你想要的那条路。
刚开始可能会觉得“套路多”,但多试几次你就会发现:好的提示词=“说清楚你是谁、你要什么、你需要它用什么知识”——这和人类沟通的本质其实是一样的
最后,关于高效提问,推荐一本书。批判经典《学会提问》
#聊聊我眼中的AI#尽量让所有人都可以认识,并且使用大模型








 查看30道真题和解析
查看30道真题和解析