
赛博爽文写作技巧——使用Cpp魔法杖
C++基础
一些头文件作用
1. #include <cctype>
- 功能:这个头文件包含了一些用于字符处理的函数,例如,可以进行字符分类和转换的函数。
- 常用函数:
std::isdigit(char c):检查字符是否为数字(0-9)。std::isalpha(char c):检查字符是否为字母(A-Z或a-z)。std::isspace(char c):检查字符是否为空白字符(空格、制表符等)。std::toupper(char c):将字符转换为大写字母。std::tolower(char c):将字符转换为小写字母。
2. #include <chrono>
-
功能:这个头文件提供了与时间和时间间隔相关的功能,允许程序员测量时间、处理时间点和时间段等。
-
主要组成部分
:
- 时间点 (
std::chrono::time_point):代表某个时间的点。 - 时钟 (
std::chrono::steady_clock、std::chrono::high_resolution_clock、std::chrono::system_clock):提供获取当前时间的功能。 - 时间段 (
std::chrono::duration):表示时间的长度,允许以不同的单位(例如秒、毫秒、微秒等)进行表示。
- 时间点 (
3. #include <fstream>
-
std::ifstream(输入文件流):- 用于从文件中读取数据。
- 可以使用与
std::cin相同的方式读入数据。 - 一般使用成员函数如
open()、close()、read()、getline()等进行文件读取操作。
std::ifstream fin("data.txt"); fin.peek() == std::ifstream::traits_type::eof() 功能:fin.peek() 是 std::ifstream 类的成员函数,它返回下一个字符的值,但不会移动文件指针。 判断文件末尾: std::ifstream::traits_type::eof() 是 eof() 状态的标识,用来检查是否已达到文件的结束。该方法的返回值表示流是否到达了文件末尾。 通过比较 peek() 的结果与 eof(),您可以判断当前文件是否为空或是否已经到达结尾。std::ifstream(输入文件流) std::ifstream(const std::string& filename);:使用字符串文件名打开文件。 打开文件: void open(const std::string& filename);:使用字符串文件名打开。 bool is_open();:检查文件是否成功打开。 读取数据: std::ifstream& operator>>(T& value);:从文件中读取数据,支持基本数据类型。 std::string getline(std::string& str);:读取一行直到换行符,返回读取的内容。 int get();:读取下一个字符并返回。 int peek();查看下一个字符而不从输入流中移除它。返回下一个字符的值,类似于 get(),但不会影响读取位置。 检查状态: bool fail();:检查是否发生逻辑错误(如输入失败)。 bool bad();:检查是否发生文件系统错误。 bool eof();:检查是否到达文件末尾。 bool good();检查流的状态是否良好(即没有设置任何错误位)。 关闭文件: void close();:关闭打开的文件。 -
std::ofstream(输出文件流):- 用于向文件中写入数据。
- 可以使用与
std::cout相同的方式输出数据。 - 常用的成员函数包括
open()、close()、write()、<<操作符等。
std::ofstream(输出文件流) std::ofstream(const std::string& filename);:使用字符串文件名打开文件。 打开文件: void open(const std::string& filename);:使用字符串文件名打开。 bool is_open();:检查文件是否成功打开。 写入数据: std::ofstream& operator<<(const T& value);:向文件写入数据,支持基本数据类型。 void write(const char* data, std::streamsize size);:写入指定大小的数据块。 检查状态: bool fail();:检查是否发生逻辑错误。 bool bad();:检查是否发生文件系统错误。 bool good(); 关闭文件: void close();:关闭打开的文件。 -
std::fstream(文件流):- 同时支持对文件的读写操作。
- 可用于既可以读取又可以写入的文件。
4. #include
acm格式下输入输出流规范使用
#include <iostream>
#include <sstream>
#include <string>
#include <vector>
using namespace std;
int main() {
stringstream input_stream;
stringstream output_stream;
string line;
// 将每一行数据写入输入流
while (getline(cin, line)) {
input_stream << line << '\n';
}
int rows, cols;
input_stream >> rows >> cols; // 读取第一行的两个整数
// 创建一个二维数组(向量)
vector<vector<int>> matrix(rows, vector<int>(cols));
for (int i = 0; i < rows; ++i) {
for (int j = 0; j < cols; ++j) {
input_stream >> matrix[i][j];
}
}
// 输出读取的数据(可选)(实际这里是作为答案输出流)
output_stream << "读取的矩阵为:\n";
for (const auto& row : matrix) {
for (const auto& value : row) {
output_stream << value << " ";
}
output_stream << "\n";
}
// 打印输出流内容
cout << output_stream.str();
return 0;
}
一、C++基础
 C++入门基础:https://blog.csdn.net/chenlong_cxy/article/details/116990901
C++入门基础:https://blog.csdn.net/chenlong_cxy/article/details/116990901
二、类和对象
 C++类和对象(一):https://blog.csdn.net/chenlong_cxy/article/details/117194830
C++类和对象(二):https://blog.csdn.net/chenlong_cxy/article/details/117307465
C++类和对象(三):https://blog.csdn.net/chenlong_cxy/article/details/117530132
C++类和对象(一):https://blog.csdn.net/chenlong_cxy/article/details/117194830
C++类和对象(二):https://blog.csdn.net/chenlong_cxy/article/details/117307465
C++类和对象(三):https://blog.csdn.net/chenlong_cxy/article/details/117530132
三、C/C++内存管理
 C/C++内存管理:https://blog.csdn.net/chenlong_cxy/article/details/117622502
C/C++内存管理:https://blog.csdn.net/chenlong_cxy/article/details/117622502
四、模板
 C++模板初阶:https://blog.csdn.net/chenlong_cxy/article/details/117629686
C++模板进阶:https://blog.csdn.net/chenlong_cxy/article/details/120284967
C++模板初阶:https://blog.csdn.net/chenlong_cxy/article/details/117629686
C++模板进阶:https://blog.csdn.net/chenlong_cxy/article/details/120284967
五、C++的IO流
 C++的IO流:https://blog.csdn.net/chenlong_cxy/article/details/120338757
C++的IO流:https://blog.csdn.net/chenlong_cxy/article/details/120338757
六、继承
 C++继承:https://blog.csdn.net/chenlong_cxy/article/details/120444215
C++继承:https://blog.csdn.net/chenlong_cxy/article/details/120444215
七、多态
 C++多态:https://blog.csdn.net/chenlong_cxy/article/details/120796570
C++多态:https://blog.csdn.net/chenlong_cxy/article/details/120796570
八、C++11
 C++11入门基础:https://blog.csdn.net/chenlong_cxy/article/details/126690586
C++11右值引用和移动语义:https://blog.csdn.net/chenlong_cxy/article/details/126747523
C++11类的新功能:https://blog.csdn.net/chenlong_cxy/article/details/126780535
C++11可变参数模板:https://blog.csdn.net/chenlong_cxy/article/details/126807356
C++11lambda表达式:https://blog.csdn.net/chenlong_cxy/article/details/126857091
C++11包装器:https://blog.csdn.net/chenlong_cxy/article/details/126916023
C++11线程库:https://blog.csdn.net/chenlong_cxy/article/details/126976346
C++11入门基础:https://blog.csdn.net/chenlong_cxy/article/details/126690586
C++11右值引用和移动语义:https://blog.csdn.net/chenlong_cxy/article/details/126747523
C++11类的新功能:https://blog.csdn.net/chenlong_cxy/article/details/126780535
C++11可变参数模板:https://blog.csdn.net/chenlong_cxy/article/details/126807356
C++11lambda表达式:https://blog.csdn.net/chenlong_cxy/article/details/126857091
C++11包装器:https://blog.csdn.net/chenlong_cxy/article/details/126916023
C++11线程库:https://blog.csdn.net/chenlong_cxy/article/details/126976346
九、异常
 C++异常:https://blog.csdn.net/chenlong_cxy/article/details/127028110
C++异常:https://blog.csdn.net/chenlong_cxy/article/details/127028110
十、智能指针
 C++智能指针:https://blog.csdn.net/chenlong_cxy/article/details/127100528
C++智能指针:https://blog.csdn.net/chenlong_cxy/article/details/127100528
十一、特殊类设计
 特殊类设计:https://blog.csdn.net/chenlong_cxy/article/details/126603597
特殊类设计:https://blog.csdn.net/chenlong_cxy/article/details/126603597
十二、C++的类型转换
 C++的类型转换:https://blog.csdn.net/chenlong_cxy/article/details/127144522
C++的类型转换:https://blog.csdn.net/chenlong_cxy/article/details/127144522
十三、STL
 STL —— string的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/117885098
STL —— string的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/118932318
STL —— vector的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/119212349
STL —— vector的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/119254954
STL —— list的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/119455963
STL —— list的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/119541500
STL —— stack和queue的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/120077784
STL —— stack和queue的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/120216105
STL —— priority_queue的使用及模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/120267391
STL —— map/set和multimap/multiset的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/121544974
STL —— map和set的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/121763649
STL —— unordered_map和unordered_set的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/122277348
STL —— unordered_map和unordered_set的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/122508621
STL —— bitset的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/122508805
STL —— bitset的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/122508813
STL —— string的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/117885098
STL —— string的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/118932318
STL —— vector的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/119212349
STL —— vector的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/119254954
STL —— list的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/119455963
STL —— list的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/119541500
STL —— stack和queue的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/120077784
STL —— stack和queue的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/120216105
STL —— priority_queue的使用及模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/120267391
STL —— map/set和multimap/multiset的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/121544974
STL —— map和set的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/121763649
STL —— unordered_map和unordered_set的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/122277348
STL —— unordered_map和unordered_set的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/122508621
STL —— bitset的介绍及使用:https://blog.csdn.net/chenlong_cxy/article/details/122508805
STL —— bitset的模拟实现:https://blog.csdn.net/chenlong_cxy/article/details/122508813
STL
STL(Standard Template Library,标准模板库) 现然主要出现在C++中,但在被引入C++之前该技术就已经存在了很长的一段时间。C++标准中,STL被组织为下面的13个头文 件:
<algorithm>、<deque>、<functional>、<iterator>、<vector>、<list>、<map>、<memory>、<numeric>、<queue>、<set>、<stack> 和<utility>
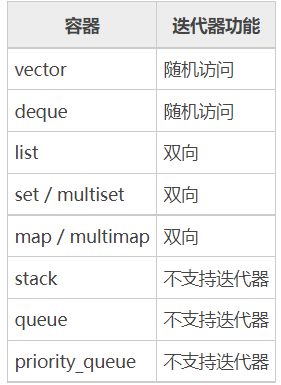
在 C++ 中,不同的数据类型和容器提供了不同的增删插入等操作功能。以下是几种常用的数据类型和容器的整理笔记,涵盖了基本操作的复杂度和使用场景:
STL-iterator
1、为什么需要迭代器
- STL提供了多种容器,每种容器的实现原理各不相同,如果没有迭代器我们需要记住每一种容器中对象的访问方法,很显然这样会变得非常麻烦。
- STL提供的许多容器中都实现了一个迭代器用于对容器中对象的访问,虽然每个容器中的迭代器的实现方式不一样,但是对于用户来说操作方法是一致的,也就说通过迭代器统一了对所有容器的访问方式。例如:访问当前元素的下一个元素我们可以通过迭代器自增进行访问。
2、迭代器的本质
-
迭代器是容器类中专门实现的一个访问容器中数据的内嵌类(类中类)

-
为了统一每个容器中对于迭代器的操作,在容器类中会使用typedef将迭代器类进行别名定义,别名为:iterator

-
迭代器类对容器中元素的访问方式:指针

-
迭代器类的具体实现:为了隐藏每个容器中迭代器的具体实现,也为了统一用户对于每个容器中迭代器的访问方式,用户可以把迭代器当成一个指针对容器中的元素进行访问。但是因为迭代器不是指针,因此在迭代器类中我们需要对 * 、->、前置++/--、后置++/--等操作符进行重载。
T &operator*() const {} node<T>*operator->() const {} list_iterator &operator++() {} list_iterator operator++(int) {} bool operator==(const list_iterator &t) const {} bool operator!=(const list_iterator &t) const {}
3、不同容器迭代器举例
每种容器类型都定义了自己的迭代器类型,如vector:
vector<int>::iterator iter; //变量名为iter。
vector容器的迭代器属于“随机访问迭代器”:迭代器一次可以移动多个位置
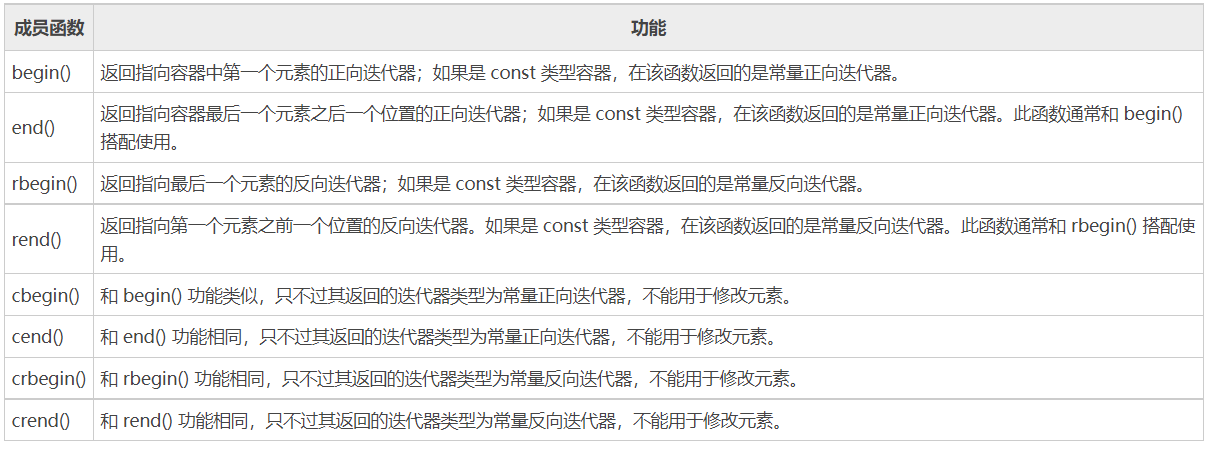
3.1、begin和end操作
每种容器都定义了一队命名为begin和end的函数,用于返回迭代器。如果容器中有元素的话,由begin返回的元素指向第一个元素。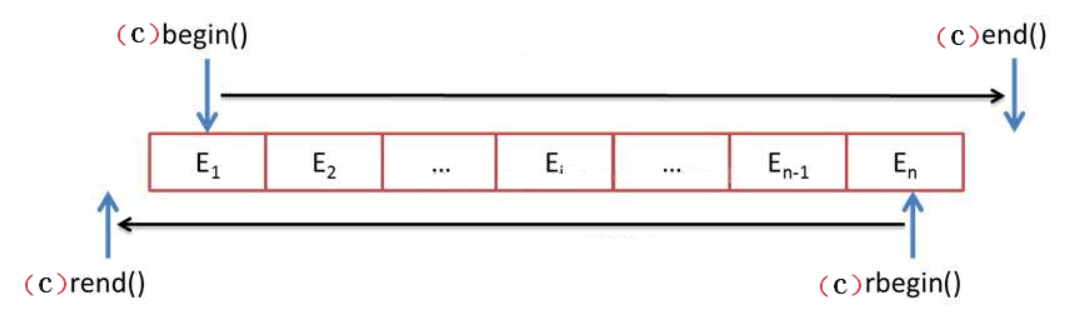
vector<int>::iterator iter=v.begin(); //若v不为空,iter指向v[0]。
由end返回的迭代器指向最后一个元素的下一个, 若v为空,begin和end返回的相同。
3.2、it++、it--、it+5、it-2
- ++iter;//使迭代器自增指向下一个元素
- ==和!=操作符来比较两个迭代器,若两个迭代器指向同一个元素,则它们相等,否则不想等。
但是只有随机访问迭代器才可以任意加减it+5,it-2,双向迭代器只能自增自减
for(vector<int>::iterator iter=v.begin();iter!=v.end();iter++)
*iter=0; //将vector中的元素全部赋值为0;
3.3、迭代器的算术操作
- iter+n; //迭代器iter加上n,指在当前迭代器所在的位置i(如在vector第一个元素位置)之前加上n个元素后的位置。
- iter-n; //迭代器iter减去n,指在当前迭代器的所在位置之后减n个元素的位置
3.4、迭代器失效
比如:(不是每种container的iteritor都有)
-
插入元素导致迭代器失效
-
删除元素导致迭代器失效
STL-Container
1. array (C风格数组)
C++中的原生数组,大小固定,无法动态调整。
- 插入:不支持直接插入,只能修改现有元素。
- 删除:不支持删除操作。
- 访问:O(1) 时间复杂度,直接通过下标访问。
- 应用场景:适用于大小固定的情况。
int arr[10]; // 创建一个大小为10的int数组
2. std::vector (动态数组)
2.1、vector对象的构造
vector采用模板类实现,vector对象的默认构造形式
vector<T> vecT;
class CA{};
vector<CA*> vecpCA; //用于存放CA对象的指针的vector容器。
vector<CA> vecCA; //用于存放CA对象的vector容器。由于容器元素的存放是按值复制的方式进行的,
//所以此时CA必须提供CA的拷贝构造函数,以保证CA对象间拷贝正常。
vector对象的带参数构造
vector(beg,end); //构造函数将[beg, end)区间中的元素拷贝给本身。注意该区间是左闭右开的区间。
vector(n,elem); //构造函数将n个elem拷贝给本身。
vector(const vector &vec); //拷贝构造函数
vector的赋值
vector.assign(beg,end); //将[beg, end)区间中的数据拷贝赋值给本身。注意该区间是左闭右开的区间。
vector.assign(n,elem); //将n个elem拷贝赋值给本身。
vector& operator=(const vector &vec); //重载等号操作符
vector.swap(vec); // 将vec与本身的元素互换。
2.2、vector的大小与访问
vector.size(); //当前 vector 容器已经存有多少个元素
vector.empty();
vector.capacity(); //当前 vector 容器总共可以容纳多少个元素
vector.resize(num); //若变长则默认值填充;变短则超出部分删除。
vector.resize(num, elem); //elem填充
vector.reserve(num); //强制 vector 容器的容量至少为 n。注意,如果 n 比当前 vector 容器的容量小,则该方法什么也不会做;反之如果 n 比当前 vector 容器的容量大,则 vector 容器就会扩容。
vec.at(idx); //返回索引idx所指的数据,如果idx越界,抛出out_of_range异常。
vec[idx]; //返回索引idx所指的数据,越界时,运行直接报错
vector.front();
vector.back();
2.3、vector插入与删除
vec.push_back(1); //在容器尾部加入一个元素
vec.pop_back(); //删除末尾元素
//注意:在insert时,vector可能需要进行扩容,而扩容的本质是new一块新的空间,再将数据迁移过去。
//insert函数提供了返回值,这个返回值是指向插入之后的val的迭代器
vector.insert(pos,elem); //在pos位置插入一个elem元素的拷贝,返回新数据的位置。
vector.insert(pos,n,elem); //在pos位置插入n个elem数据,无返回值。
vector.insert(pos,beg,end); //在pos位置插入[beg,end)区间的数据,无返回值
vector.clear(); //移除容器的所有数据
// erase函数也提供了返回值,返回下一个有效的iterator
vec.erase(beg,end); //删除[beg,end)区间的数据,返回下一个数据的位置。
vec.erase(pos); //删除pos位置的数据,返回下一个数据的位置。
2.4、vector迭代器
- vector容器的迭代器属于“随机访问迭代器”:迭代器一次可以移动多个位置
vector<int>::iterator iter; //变量名为iter。
- 迭代器:
迭代器使用举例:
for(vector<int>::iterator iter=v.begin();iter!=v.end();iter++)
*iter=0; //将vector中的元素全部赋值为0;
迭代器失效问题:
- 插入元素导致迭代器失效
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);//v有三个元素 1,2,3,4
vector<int>::iterator it1 = v.begin() + 3;
v.insert(it1, 8);//插入一个8
cout << *it1 << endl;//输出it位置的元素
return 0;
}
运行上面这段代码,我们会发现输出的结果并不是8,甚至有可能会导致程序崩溃。
因为在insert时,vector可能需要进行扩容,而扩容的本质是new一块新的空间,再将数据迁移过去。而我们知道,迭代器的内部是通过指针访问容器中的元素的,而插入后,若vector扩容,则原有的数据被释放,指向原有数据的迭代器就成了野指针,所以迭代器失效了。
而解决的办法很简单,insert函数提供了返回值,这个返回值是指向插入之后的val的迭代器。我们只需要保存返回的迭代器,并使用这个新的迭代器即可。
int main()
{
vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);//v有三个元素 1,2,3,4
vector<int>::iterator it1 = v.begin() + 3;
it1 = v.insert(it1, 8);//插入一个8
cout << *it1 << endl;//输出it位置的元素
return 0;
}
- 删除元素导致迭代器失效
vector<int> cont ={1,2,3,3,3,4,5,5,5,6};
for (iter = cont.begin(); iter != cont.end();iter++)
{
if (*iter == 3)
cont.erase(iter);
}
对于序列式容器(如vector,deque),序列式容器就是数组式容器,删除当前的iterator会使后面所有元素的iterator都失效。这是因为vetor,deque使用了连续分配的内存,删除一个元素导致后面所有的元素会向前移动一个位置。所以不能使用erase(iter++)的方式,还好erase方法可以返回下一个有效的iterator。
vector<int> cont ={1,2,3,3,3,4,5,5,5,6};
for (iter = cont.begin(); iter != cont.end();)
{
if (*iter == 3)
iter = cont.erase(iter);
else
iter++;
}
适合需要频繁在末尾添加元素、偶尔插入和删除的场景。
3. std::deque (双端队列)
3.1、deque用法
-
deque是双端数组,而vector是单端的。
-
deque与vector在操作上几乎一样,deque多两个函数:
deque.push_front(elem); //在容器头部插入一个数据
deque.pop_front(); //删除容器第一个数据
-
插入:在头/尾插入:O(1)(
push_front()和push_back())。 -
删除:删除头/尾元素:O(1)(
pop_front()和pop_back())。 -
访问:O(1) 通过下标访问。
3.2、应用场景
适合需要频繁在两端操作元素的场景。
std::deque<int> dq;
dq.push_back(1); // O(1)
dq.push_front(2); // O(1)
dq.pop_back(); // O(1)
dq.pop_front(); // O(1)
4. std::list (双向链表)
-
双向链表,支持快速的插入和删除操作,但访问效率较低。
-
list不可以随机存取元素,所以不支持at.(pos)函数与[]操作符。
-
list迭代器是双向的,但不是随机的,支持自增自减It++(ok),不支持任意加减 it+5(err)
4.1、list对象的构造
list<int> lstInt; //定义一个存放int的list容器。
list<float> lstFloat; //定义一个存放float的list容器。
list<string> lstString; //定义一个存放string的list容器。
list对象的带参数构造
list(n,elem); //构造函数将n个elem拷贝给本身。
list(beg,end); //构造函数将[beg,end]区间中的元素拷贝给本身
list(const list &lst); //拷贝构造函数。
list的赋值
list.assign(beg,end); //将[beg, end)区间中的数据拷贝赋值给本身。注意该区间是左闭右开的区间。
list.assign(n,elem); //将n个elem拷贝赋值给本身。
list& operator=(const list &lst); //重载等号操作符
list.swap(lst); // 将lst与本身的元素互换。
4.2、list的大小与访问
list.size(); //返回容器中元素的个数
list.empty(); //判断容器是否为空
list.resize(num);
list.resize(num, elem);
//注意:vec支持at.(pos)函数与[]操作符
vec.at(idx); //返回索引idx所指的数据,如果idx越界,抛出out_of_range异常。
vec[idx]; //返回索引idx所指的数据,越界时,运行直接报错
//注意:list不支持at.(pos)函数与[]操作符
list.front(); //返回第一个元素。
list.back(); //返回最后一个元素。
4.3、list插入与删除
list.push_back(elem); //在容器尾部加入一个元素
list.pop_back(); //删除容器中最后一个元素
list.push_front(elem); //在容器开头插入一个元素
list.pop_front(); //从容器开头移除第一个元素
emplace_front():在链表头部直接构造元素(避免拷贝)。
emplace_back():在链表末尾直接构造元素(避免拷贝)。
//注意:在insert时,vector可能需要进行扩容,而扩容的本质是new一块新的空间,再将数据迁移过去。
//insert函数提供了返回值,这个返回值是指向插入之后的val的迭代器
list.insert(pos,elem); //在pos位置插入一个elem元素的拷贝,返回新数据的位置。
list.insert(pos,n,elem); //在pos位置插入n个elem数据,无返回值。
list.insert(pos,beg,end); //在pos位置插入[beg,end)区间的数据,无返回值。
list.clear(); //移除容器的所有数据
list.erase(beg,end); //删除[beg,end)区间的数据,返回下一个数据的位置。
list.erase(pos); //删除pos位置的数据,返回下一个数据的位置。
lst.remove(elem); //删除容器中所有与elem值匹配的元素。
unique():删除所有连续的相等元素,保留其中一个。
unique(BinaryPredicate pred):根据谓词 pred 删除所有连续的满足谓词条件的元素。
4.4、 list的排列移动相关函数
sort():对链表进行升序排序。
sort(Compare comp):根据自定义比较器 comp 对链表进行排序。
lst.reverse(); //反转链表,比如lst包含1,3,5元素,运行此方法后,lst就包含5,3,1元素。
swap(list& other):交换两个链表的内容。
merge(list& other):将 other 链表合并到当前链表,假设两个链表都是升序排列。
merge(list& other, Compare comp):根据自定义比较器 comp 合并两个链表。
// 使用splice移动链表元素
lst2.splice(lst2.begin(), lst1, it); // 将 lst1中位置it的元素移动到 lst2 的开头
lst2.splice(lst2.end(), lst1, first, last); // 将lst1中位置first-last的元素序列移动到lst2的末尾
lst2.splice(lst2.end(), lst1); // 将 lst1 的所有元素移到 lst2 的末尾
4.5、list迭代器
- list迭代器是双向的,但不是随机的,支持自增自减It++(ok),不支持任意加减 it+5(err)
//删除结点导致迭代器失效
for(list<int>::iterator it=lstInt.being(); it!=lstInt.end(); ) //小括号里不需写 ++it
{
if(*it == 3)
{
lstInt.erase(it); //以迭代器为参数,删除元素3,并把数据删除后的下一个元素位置返回给迭代器。
}
}
4.6、应用场景
适合需要频繁在中间插入或删除的场景,但不适合频繁访问元素。
5.std::stack (栈)
-
stack是堆栈容器,是一种“先进后出”的容器,只允许在栈顶进行操作。
-
stack是简单地装饰deque容器而成为另外的一种容器。
5.1、stack对象的构造
stack <int> stkInt; //一个存放int的stack容器。
- stack(const stack &stk); //拷贝构造函数
stack<int> stkIntB(stkIntA); //拷贝构造
- stack& operator=(const stack &stk); //重载等号操作符
stkIntC = stkIntA; //赋值
5.2、stack的大小与访问
stack.empty(); //判断堆栈是否为空
stack.size(); //返回堆栈的大小\
stack.top(); //返回最后一个压入栈元素
5.3、stack的push()与pop()方法
stack.push(elem); //往栈头添加元素
stack.pop(); //从栈头移除第一个元素
5.4、应用场景
适用于需要后进先出操作的场景,如深度优先搜索、递归问题的模拟等。
6. std::queue (队列)
- queue是队列容器,是一种“先进先出”的容器,操作只能在两端进行。
6.1、queue对象的构造
queue<int> queInt; //一个存放int的queue容器。
- queue(const queue &que); //拷贝构造函数
queue<int> queIntB(queIntA); //拷贝构造
- queue& operator=(const queue &que); //重载等号操作符
queIntC = queIntA; //赋值
6.2、queue的大小与访问
queue.empty(); //判断队列是否为空
queue.size(); //返回队列的大小
queue.back(); //返回最后一个元素
queue.front(); //返回第一个元素
6.3、queue的push()与pop()方法
queue.push(elem); //往队尾添加元素
queue.pop(); //从队头移除第一个元素
6.4、应用场景
适用于需要先进先出操作的场景,如广度优先搜索、任务调度等。
7. std::priority_queue (优先级队列)
priority_queue 是一种特殊的队列,元素会按优先级自动排序,默认是大顶堆(最大元素在队头),也可以定义为小顶堆。
- 插入:O(log n) 时间复杂度,使用
push()方法将元素插入优先队列。 - 删除:O(log n) 时间复杂度,使用
pop()方法移除队列中优先级最高的元素。 - 访问:O(1) 时间复杂度,使用
top()方法访问优先级最高的元素,但不删除。 - 检查是否为空:O(1) 时间复杂度,使用
empty()。 - 获取大小:O(1) 时间复杂度,使用
size()方法获取优先队列的元素个数。 - 自定义优先级:可以通过自定义比较器来构造小顶堆(最小优先级队列)。
- 应用场景:适用于需要动态获取最小值或最大值的场景,如任务调度、Dijkstra 算法等。
std::priority_queue<int> pq; // 默认是大顶堆
pq.push(10); // O(log n)
pq.push(5); // O(log n)
pq.push(20); // O(log n)
pq.top(); // O(1), 返回优先级最高的元素
pq.pop(); // O(log n), 删除优先级最高的元素
bool isEmpty = pq.empty(); // O(1), 检查队列是否为空
int size = pq.size(); // O(1), 获取队列的大小
小顶堆的实现:
要实现小顶堆,可以使用 greater<> 比较器或自定义比较器。
// 小顶堆
std::priority_queue<int, std::vector<int>, std::greater<int>> minHeap;
minHeap.push(10);
minHeap.push(5);
minHeap.push(20);
std::cout << minHeap.top(); // 输出最小的元素 5
自定义优先级比较器:
可以通过结构体或者 lambda 表达式来自定义优先级队列的比较规则。
struct Compare {
bool operator()(int a, int b) {
return a > b; // 小顶堆,优先级由小到大
}
};
std::priority_queue<int, std::vector<int>, Compare> customPQ;
customPQ.push(10);
customPQ.push(5);
customPQ.push(20);
std::cout << customPQ.top(); // 输出最小的元素 5
8. std::set (集合) Set和multiset容器
-
set是一个集合容器,其中所包含的元素是唯一的,集合中的元素按一定的顺序排列。元素插入过程是按排序规则插入,所以不能指定插入位置。
-
set采用红黑树变体的数据结构实现,红黑树属于平衡二叉树。在插入操作和删除操作上比vector快。
-
set不可以直接存取元素。(不可以使用at.(pos)与[]操作符)。
-
multiset与set的区别:set支持唯一键值,每个元素值只能出现一次;而multiset中同一值可以出现多次。
-
不可以直接修改set或multiset容器中的元素值,因为该类容器是自动排序的。如果希望修改一个元素值,必须先删除原有的元素,再插入新的元素。
8.1、set/multiset对象的构造
set<int> setInt; //一个存放int的set容器。
set<float> setFloat; //一个存放float的set容器。
set<string> setString; //一个存放string的set容器。
multiset<int> mulsetInt; //一个存放int的multi set容器。
multi set<float> multisetFloat; //一个存放float的multi set容器。
multi set<string> multisetString; //一个存放string的multi set容器。
- set(const set &st); //拷贝构造函数
set<int> setIntB(setIntA); //1 3 5 7 9 //拷贝构造
- set& operator=(const set &st);//重载等号操作符
setIntC = setIntA; //赋值
- set.swap(st); //交换两个集合容器
setIntC.swap(setIntA); //交换
8.2、set的大小与访问
set.size(); //返回容器中元素的数目
set.empty();//判断容器是否为空
8.3、set的插入与删除
set.insert(elem); //在容器中插入元素。
set.clear(); //清除所有元素
set.erase(pos); //删除pos迭代器所指的元素,返回下一个元素的迭代器。
set.erase(beg,end); //删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。
set.erase(elem); //删除容器中值为elem的元素。
8.4、set的查找
set.find(elem); //查找elem元素,返回指向elem元素的迭代器。
set.count(elem); //返回容器中值为elem的元素个数。对set来说,要么是0,要么是1。对multiset来说,值可能大于1。
set.lower_bound(elem); //返回第一个 >=elem元素的迭代器。
set.upper_bound(elem); // 返回第一个>elem元素的迭代器。
8.5、set集合的元素排序

8.6、应用场景
适合需要有序存储、不允许重复元素且需要快速查找的场景。
9. std::unordered_set (无序集合)
unordered_set 是基于哈希表实现的无序集合。
- 插入:O(1) 平均时间复杂度(
insert())。 - 删除:O(1) 平均时间复杂度(
erase())。 - 访问:O(1) 平均时间复杂度查找(
find())。 - 应用场景:适合需要快速查找但不要求有序的场景。
cpp复制代码std::unordered_set<int> us;
us.insert(1); // O(1)
us.insert(2); // O(1)
us.erase(1); // O(1)
us.find(2); // O(1)
10. std::map (有序映射)
-
map是标准的关联式容器,一个map是一个键值对序列,即(key,value)对。它提供基于key的快速检索能力。
-
map中key值是唯一的。集合中的元素按一定的顺序排列。元素插入过程是按排序规则插入,所以不能指定插入位置。
-
map的具体实现采用红黑树变体的平衡二叉树的数据结构。在插入操作和删除操作上比vector快。
-
map可以直接存取key所对应的value,支持[]操作符,如map[key]=value(将key键所对应的值修改为value)
-
multimap与map的区别:map支持唯一键值,每个键只能出现一次;而multimap中相同键可以出现多次。multimap不支持[]操作符。
10.1、map/multimap对象的构造
map/multimap采用模板类实现,对象的默认构造形式:
map<T1,T2> mapTT;
multimap<T1,T2> multimapTT;
如:
map<int, char> mapA;
map<string,float> mapB;
//其中T1,T2还可以用各种指针类型或自定义类型
- map(const map &mp); //拷贝构造函数
map<int ,string> mapB(mapA); //拷贝构造
- map& operator=(const map &mp); //重载等号操作符
mapC = mapA; //赋值
- map.swap(mp); //交换两个集合容器
mapC.swap(mapA); //交换
10.2、map的大小与键值对访问
map.size(); //返回容器中元素的数目
map.empty();//判断容器是否为空
// 方法一:使用[]
//方法二:使用find()函数:成功返回对应的迭代器,失败返回end()的返回值
//方法三:使用at()函数,如果键值对不存在会抛出“out_of_range 异常”
10.3、map的插入与删除
map.insert(...); //往容器插入元素,返回pair
// 插入元素的三种方式
mapStu.insert(pair(3,"小张") );
mapStu.insert( map<int,string>::value_type(1,"小李") );
mapStu[3] = “小刘";
map.clear(); //删除所有元素
map.erase(pos); //删除pos迭代器所指的元素,返回下一个元素的迭代器。
map.erase(beg,end); //删除区间[beg,end)的所有元素 ,返回下一个元素的迭代器。
map.erase(keyElem); //删除容器中key为keyElem的对组。
10.4、map的查找
map.find(key); 查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回map.end();
map.count(keyElem); //返回容器中key为keyElem的对组个数。
map.lower_bound(elem); //返回第一个>=elem元素的迭代器。
map.upper_bound(elem); // 返回第一个>elem元素的迭代器。
map.equal_range(elem); //返回容器中与elem相等的上下限的两个迭代器。上限是闭区间,下限是开区间,如[beg,end)。
10.5、map根据key元素排序
//默认是升序排列
map<int, string> myMap = {{3, "three"}, {1, "one"}, {2, "two"}};
//按照降序排列
map<int, string, greater<int>> myMap = {{3, "three"}, {1, "one"}, {2, "two"}};
//若想根据value排列,可以将map的内容转存到vector后,设计算法进行排序
8.6、应用场景
适合需要键值映射且需要有序的场景。
11. std::unordered_map (无序映射)
unordered_map 是基于哈希表实现的键值对容器。
- 插入:O(1) 平均时间复杂度(
insert()或operator[])。 - 删除:O(1) 平均时间复杂度(
erase())。 - 访问:O(1) 平均时间复杂度查找(
find()或operator[])。 - 应用场景:适合需要键值映射且不需要有序的场景。
cpp复制代码
std::unordered_map<int, int> ump;
ump[1] = 2; // O(1)
ump.insert({2, 3}); // O(1)
ump.erase(1); // O(1)
ump.find(2); // O(1)
12、总结
特点对比:
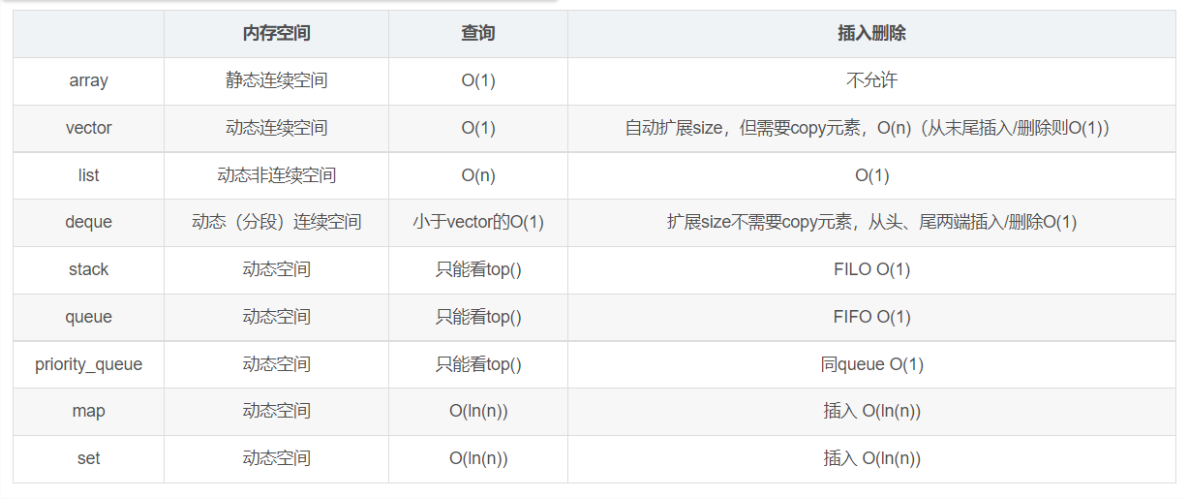
底层实现:
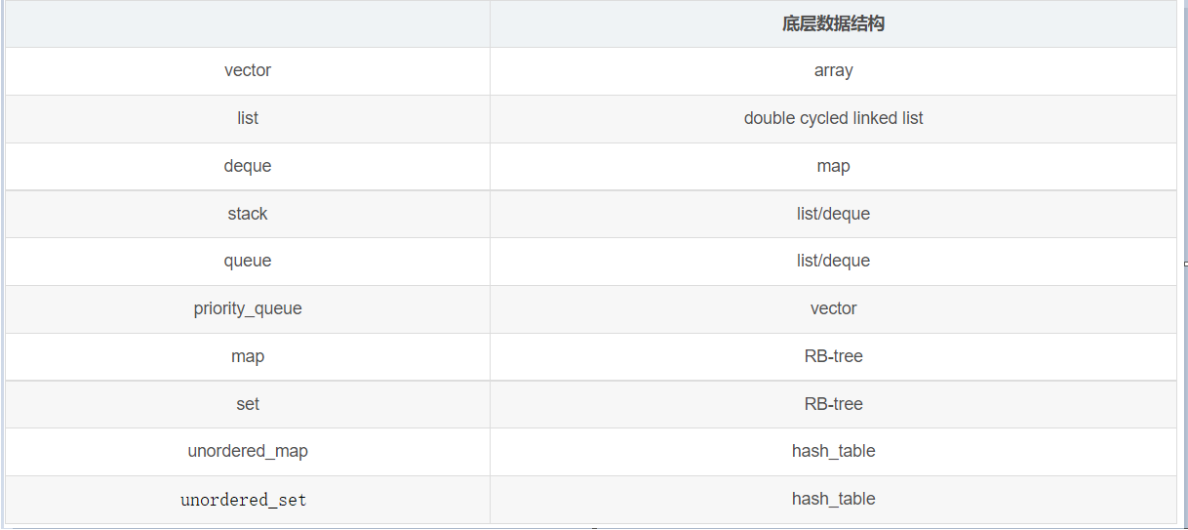
prompt:将上述问题整理,给出array vector stack queue deque list set unordered_set map unorsered_map priority_queue 等,按照查询是否空、插入、删除、访问、应用场景、使其他特殊用法、用时注意的点、所有用法的代码示例。整理一份详细的知识点笔记
STL-algorithm
1 copy 函数:
-
copy是一个 STL 算法,用于将元素从一个范围复制到另一个范围。 -
在这里,它从
vec的起始位置(cbegin)到结束位置(cend)复制元素,并将它们写入ostream_iterator,即打印到cout,同时在每两个元素之间添加一个空格。 -
ostream_iterator是一个输出迭代器,用于将数据写入输出流(在这里是标准输出流cout)。cout是标准输出流对象,用于打印到控制台。" "是一个分隔符,指定在打印每个元素之间插入一个空格。
copy(vec.cbegin(), vec.cend(), ostream_iterator<int>(cout, " "));
2、排序算法
2.1、sort() 排序函数
-
sort() 函数是基于快速排序实现的
-
sort() 只对 vector、deque 这 2个容器提供支持
-
如果对容器中指定区域的元素做默认升序排序,则元素类型必须支持<小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符
-
sort() 函数在实现排序时,需要交换容器中元素的存储位置。这种情况下,如果容器中存储的是自定义的类对象,则该类的内部必须拷贝构造函数和赋值运算符的重载。
-
sort() 排序是不稳定的
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
using namespace std;
//以普通函数的方式实现自定义排序规则
bool mycomp(int i, int j) {
return (i < j);
}
//以函数对象的方式实现自定义排序规则
class mycomp2 {
public:
bool operator() (int i, int j) {
return (i < j);
}
};
int main() {
int a[] = { 32, 71, 12, 45, 26, 80, 53, 33 };
vector<int> myvector(a, a+8);
//调用第一种语法格式,对 32、71、12、45 进行排序
sort(myvector.begin(), myvector.begin() + 4); //(12 32 45 71) 26 80 53 33
//调用第二种语法格式,利用STL标准库提供的其它比较规则(比如 greater<T>)进行排序
sort(myvector.begin(), myvector.begin() + 4, greater<int>()); //(71 45 32 12) 26 80 53 33
//调用第二种语法格式,通过自定义比较规则进行排序
sort(myvector.begin(), myvector.end(), mycomp2());//12 26 32 33 45 53 71 80
//输出 myvector 容器中的元素
for (vector<int>::iterator it = myvector.begin(); it != myvector.end(); ++it) {
cout << *it << ' ';
}
return 0;
}
2.2、stable_sort()排序算法
-
stable_sort() 函数是基于归并排序实现的
-
stable_sort() 是稳定的排序算法
-
stable_sort()函数与sort()函数的使用方法相同。
2.3、partial_sort() (部分排序)
-
partial_sort() 函数只适用于 array、vector、deque 这 3 个容器。
-
当选用默认的升序排序规则时,容器中存储的元素类型必须支持 <小于运算符;同样,如果选用标准库提供的其它排序规则,元素类型也必须支持该规则底层实现所用的比较运算符;
-
partial_sort() 函数在实现过程中,需要交换某些元素的存储位置。因此,如果容器中存储的是自定义的类对象,则该类的内部必须提供移动构造函数和移动赋值运算符
//按照默认的升序排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last);
//按照 comp 排序规则,对 [first, last) 范围的数据进行筛选并排序
void partial_sort (RandomAccessIterator first,
RandomAccessIterator middle,
RandomAccessIterator last,
Compare comp);
/*
其中,first、middle 和 last 都是随机访问迭代器,comp 参数用于自定义排序规则。
partial_sort() 函数会以交换元素存储位置的方式实现部分排序的。
具体来说,partial_sort() 会将 [first, last) 范围内最小(或最大)的 middle-first 个元素移动到
[first, middle) 区域中,并对这部分元素做升序(或降序)排序。
*/
//以默认的升序排序作为排序规则,将 myvector 中最小的 4 个元素移动到开头位置并排好序
partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end());
// 以指定的 mycomp2 作为排序规则,将 myvector 中最大的 4 个元素移动到开头位置并排好序
partial_sort(myvector.begin(), myvector.begin() + 4, myvector.end(), mycomp2());
2.4、merge()函数 (合并排序)
- 功能:将两个已经排好序的序列合并为一个有序的序列
默认排序规则:
//以默认的升序排序作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result);
//以自定义的 comp 规则作为排序规则
OutputIterator merge (InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result, Compare comp);
/*
* firs1t为第一个容器的首迭代器,last1为第一个容器的末迭代器;
* first2为第二个容器的首迭代器,last2为容器的末迭代器;
* result为存放结果的容器,comapre为比较函数(可略写,默认为合并为一个升序序列)。
*/
注意:使用的时候result,如果用的vector,必须先使用resize扩容
2.5、revrese()函数 (反转函数)
注意:
- string和vector和deque只能使用模板库算法里的反转函数
- list可以使用算法里的和list类的reverse
- stack和queue没有迭代器,自然不能使用算法里的reverse,其类也没有提供反转的成员函数
- set和map的元素是按照键值排序的,不能修改键值,不可反转.
3、查找算法
3.1、adjacent_find()
功能:在iterator对标识元素范围内,查找一对相邻重复元素,找到则返回指向这对元素的第一个元素的迭代器。
vector<int> vecInt;
vecInt.push_back(1);
vecInt.push_back(2);
vecInt.push_back(2);
vecInt.push_back(4);
vecInt.push_back(5);
vecInt.push_back(5);
vector<int>::iterator it = adjacent_find(vecInt.begin(), vecInt.end()); //*it == 2
3.2、binary_search()
功能:二分查找法,在有序序列中查找value,找到则返回true。
set<int> setInt;
setInt.insert(3);
setInt.insert(1);
setInt.insert(7);
setInt.insert(5);
setInt.insert(9);
bool bFind = binary_search(setInt.begin(),setInt.end(),5);
3.3、count()
功能:利用等于操作符,把标志范围内的元素与输入值比较,返回相等的个数。
vector<int> vecInt;
vecInt.push_back(1);
vecInt.push_back(2);
vecInt.push_back(2);
vecInt.push_back(4);
vecInt.push_back(2);
vecInt.push_back(5);
int iCount = count(vecInt.begin(),vecInt.end(),2); //iCount==3
3.4、find()
- 功能:find() 函数用于在指定范围内查找和目标元素值相等的第一个元素。
函数的语法格式:
InputIterator find (InputIterator first, InputIterator last, const T& val);
//first 和 last 为输入迭代器,[first, last) 用于指定该函数的查找范围;val 为要查找的目标元素。
正因为 first 和 last 的类型为输入迭代器,因此该函数适用于所有的序列式容器。
该函数会返回一个输入迭代器,当 find() 函数查找成功时,其指向的是在 [first, last) 区域内查找到的第一个目标元素;如果查找失败,则该迭代器的指向和 last 相同。
3.5、find_if()
-
功能:和 find() 函数相同,find_if() 函数也用于在指定区域内执行查找操作。
-
不同的是:前者需要明确指定要查找的元素的值,而后者则允许自定义查找规则。
//以函数对象的形式定义一个 find_if() 函数的查找规则
class mycomp2 {
public:
bool operator()(const int& i) {
return ((i % 2) == 1);
}
};
int main() {
vector<int> myvector{ 4,2,3,1,5 };
//调用 find_if() 函数
vector<int>::iterator it = find_if(myvector.begin(), myvector.end(), mycomp2());
cout << "*it = " << *it;
return 0;
}
3.6、search()
- 功能:search()函数用于在序列 A 中查找序列 B 第一次出现的位置。
//查找 [first1, last1) 范围内第一个 [first2, last2) 子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2);
//查找 [first1, last1) 范围内,和 [first2, last2) 序列满足 pred 规则的第一个子序列
ForwardIterator search (ForwardIterator first1, ForwardIterator last1,
ForwardIterator first2, ForwardIterator last2,
BinaryPredicate pred);
- first1、last1:都为正向迭代器,其组合 [first1, last1) 用于指定查找范围(也就是上面例子中的序列 A);
- first2、last2:都为正向迭代器,其组合 [first2, last2) 用于指定要查找的序列(也就是上面例子中的序列 B);
- pred:用于自定义查找规则。该规则实际上是一个包含 2 个参数且返回值类型为 bool 的函数(第一个参数接收 [first1, last1) 范围内的元素,第二个参数接收 [first2, last2) 范围内的元素)。函数定义的形式可以是普通函数,也可以是函数对象。
search() 函数会返回一个正向迭代器,当函数查找成功时,该迭代器指向查找到的子序列中的第一个元素;反之,如果查找失败,则该迭代器的指向和 last1 迭代器相同。
//以普通函数的形式定义一个匹配规则
bool mycomp1(int i, int j) {
return (i%j == 0);
}
//以函数对象的形式定义一个匹配规则
class mycomp2 {
public:
bool operator()(const int& i, const int& j) {
return (i%j == 0);
}
};
int main() {
vector<int> myvector{ 1,2,3,4,8,12,18,1,2,3 };
int myarr[] = { 1,2,3 };
//调用第一种语法格式
vector<int>::iterator it = search(myvector.begin(), myvector.end(),
myarr, myarr + 3);
if (it != myvector.end()) {
cout << "第一个{1,2,3}的起始位置为:" << it - myvector.begin() << ",*it = " << *it << endl;
}
int myarr2[] = { 2,4,6 };
//调用第二种语法格式
it = search(myvector.begin(), myvector.end(),
myarr2, myarr2 + 3, mycomp2());
if (it != myvector.end()) {
cout << "第一个{2,3,4}的起始位置为:" << it - myvector.begin() << ",*it = " << *it;
}
return 0;
}
程序执行结果为:

3.7、lower_bound()
前提是有序的情况下,lower_bound 返回指向第一个值不小于 val 的位置,也就是返回第一个大于等于val值的位置。(通过二分查找)。使用自定义函数:找到第一个使比较函数返回 false 的位置。
- 如果找到了与给定值相等的元素,返回该元素的迭代器。
- 如果没有找到相等的元素,它将返回第一个大于给定值的元素的迭代器。
- 如果给定值大于容器中的所有元素,返回指向容器末尾的迭代器(即
container.end())。
template <class ForwardIterator, class T, class Compare>
ForwardIterator lower_bound (ForwardIterator first, ForwardIterator last, const T& val, Compare comp);
- ForwardIterator就是一个迭代器,vector< int > v,v数组的首元素就是 v.begin()
- T&val , 就是一个T类型的变量
- Compare 就是一个比较器,可以传仿函数对象,也可以传函数指针 即得到第一个使得compare为false的值的指针。
3.8、upper_bound()
用法和上面类似。只是把lower_bound的 【大于等于】 换成 【大于】 。仿函数等等全是相同的用法。 使用自定义函数:找到第一个使比较函数返回 true 的位置。
- 如果找到了大于给定值的元素,返回该元素的迭代器。
- 如果没有找到大于给定值的元素(即给定值大于或等于容器中的所有元素),返回指向容器末尾的迭代器(即
container.end())
这两个函数是二分法返回迭代器,binary_search()是二分法返回bool值。
C++11特性
目录:
- 稳定性和兼容性 原始字面量 超长整形 long long 类成员的快速初始化 final 和 override 模板的优化 数值类型和字符串之间的转换 静态断言 static_assert noexcept
- 易学和易用性 自动类型推导 基于范围的for循环 指针空值类型 - nullptr lambda表达式
- 通用性能的提升 常量表达式修饰符 - constexpr 委托构造函数和继承构造函数 右值引用 转移和完美转发 列表初始化 using的使用 可调用对象包装器、绑定器 POD类型 默认函数控制 =default 与 =delete 扩展的friend语法 强类型枚举 非受限联合体
- 安全性 共享智能指针
独占智能指针
弱引用智能指针
- 多线程 处理日期和时间的chrono库
C++线程类 thread
线程命名空间 this_thread
call_once函数
线程同步之互斥锁 mutex
线程同步之条件变量
线程同步之原子变量 atomic
线程异步
异步线程池
R “xxx(原始字符串)xxx”
原始字面量R可以直接表示字符串的实际含义,而不需要额外对字符串做转义或连接等操作。
constexpr修饰常量表达式
在C++11之前只有const关键字,从功能上来说这个关键字有双重语义:变量只读,修饰常量
在使用中建议将 const 和 constexpr 的功能区分开,即凡是表达“只读”语义的场景都使用 const,表达“常量”语义的场景都使用 constexpr。
auto & decltype
decltype 是“declare type”的缩写,意思是“声明类型”。decltype的推导是在编译期完成的,它只是用于表达式类型的推导,并不会计算表达式的值。来看一组简单的例子:
int a = 10;
decltype(a) b = 99; // b -> int
decltype(a+3.14) c = 52.13; // c -> double
decltype(a+b*c) d = 520.1314; // d -> double
可以看到decltype推导的表达式可简单可复杂,在这一点上auto是做不到的,auto只能推导已初始化的变量类型。
-
表达式为普通变量或者普通表达式或者类表达式,在这种情况下,使用decltype推导出的类型和表达式的类型是一致的。
-
表达式是函数调用,使用decltype推导出的类型和函数返回值一致。
-
表达式是一个左值,或者被括号( )包围,使用 decltype推导出的是表达式类型的引用(如果有const、volatile限定符不能忽略)。
返回值类型后置
在C++11中增加了返回类型后置语法,说明白一点就是将decltype和auto结合起来完成返回类型的推导。其语法格式如下:
// 符号 -> 后边跟随的是函数返回值的类型
auto func(参数1, 参数2, ...) -> decltype(参数表达式)
// 返回类型后置语法
template <typename T, typename U>
auto add(T t, U u) -> decltype(t+u) {
return t + u;
}
通过对上述返回类型后置语法代码的分析,得到结论:auto 会追踪 decltype() 推导出的类型
final & override
final关键字限制某个类不能被继承,或者某个虚函数不能被重写。(写在后面)
-
如果使用final修饰函数,只能修饰虚函数(子类中的),这样就能阻止子类重写父类的这个函数了
-
使用final关键字修饰过的类是不允许被继承的,也就是说这个类不能有派生类。
override关键字确保在派生类中声明的重写函数与基类的虚函数有相同的签名,同时也明确表明将会重写基类的虚函数,这样就可以保证重写的虚函数的正确性,也提高了代码的可读性。(相当于声明一下这个函数是重写的虚函数,碰见打错编译器会提示错误)
using & typedef
//typedef 旧的类型名 新的类型名;
typedef unsigned int uint_t;
//using 新的类型 = 旧的类型;
using uint_t = int;
// 使用typedef定义函数指针
typedef int(*func_ptr)(int, double);
// 使用using定义函数指针
using func_ptr1 = int(*)(int, double);
typedef重定义类似很方便,但无法重定义一个模板。
template <typename T>
typedef map<int, T> type; // error, 语法错误
// 需要定义外敷类,利用外类::type来定义
template <typename T>
struct MyMap
{
typedef map<int, T> type;
};
// 而using就方便很多
template <typename T>
using mymap = map<int, T>;
最后在强调一点:using语法和typedef一样,并不会创建出新的类型,它们只是给某些类型定义了新的别名。using相较于typedef的优势在于定义函数指针别名时看起来更加直观,并且可以给模板定义别名。
建议直接用using
委托构造和继承构造函数
// 通过一个构造函数调用其他的构造函数用来进行类成员的初始化,优化代码,代码精简
class Test
{
public:
Test() {};
Test(int max) {
this->m_max = max > 0 ? max : 100;
}
Test(int max, int min):Test(max) {
this->m_min = min > 0 && min < max ? min : 1;
}
Test(int max, int min, int mid):Test(max, min) {
this->m_middle = mid < max && mid > min ? mid : 50;
}
-
这种链式的构造函数调用不能形成一个闭环(死循环),否则会在运行期抛异常。
-
如果要进行多层构造函数的链式调用,建议将构造函数的调用的写在初始列表中而不是函数体内部,否则编译器会提示形参的重复定义。
-
在初始化列表中调用了代理构造函数初始化某个类成员变量之后,就不能在初始化列表中再次初始化这个变量了。(不能重复初始化)
继承构造函数可以让派生类直接使用基类的构造函数,而无需自己再写构造函数
class Base
{
public:
Base(int i) :m_i(i) {}
Base(int i, double j) :m_i(i), m_j(j) {}
Base(int i, double j, string k) :m_i(i), m_j(j), m_k(k) {}
int m_i;
double m_j;
string m_k;
};
class Child : public Base
{
public:
using Base::Base;
};
class Base
{
public:
Base(int i) :m_i(i) {}
Base(int i, double j) :m_i(i), m_j(j) {}
Base(int i, double j, string k) :m_i(i), m_j(j), m_k(k) {}
void func(int i) {
cout << "base class: i = " << i << endl;
}
void func(int i, string str) {
cout << "base class: i = " << i << ", str = " << str << endl;
}
int m_i;
double m_j;
string m_k;
};
class Child : public Base
{
public:
using Base::Base;
using Base::func;
void func() {
cout << "child class: i'am luffy!!!" << endl;
}
};
//子类中的func()函数隐藏了基类中的两个func()因此默认情况下通过子类对象只能调用无参的func(),在上面的子类代码中添加了using Base::func;之后,就可以通过子类对象直接调用父类中被隐藏的带参func()函数了。
初始化列表
... = {,,,};
std::initializer_list
operator
c++ 中的operator()有两大主要作用:
- Overloading------重载()操作符;
class A
{
public:
mutable int var;
int operator() (int value) //重载()运算符,传入int的参数,operator()可以传入无限制的参数
{
return value > var ? value : var-value;
}
};
2.Casting------实现对象类型转化。
在c++中可以用operator Type()的形式定义类型转换函数,将类对象转换为Type类型
class A
{
public:
mutable int var;
void setVar(int a)
{
var = a;
}
operator int()//将类A对象隐式转化为int类型
{
return var;
}
};
int main()
{
A func;
func.setVar(10);
std::cout << func << std::endl;//实际上调用的是func.operator int()这个函数
return 0;
}
深拷贝与浅拷贝详解
浅拷贝(Shallow Copy)
- 浅拷贝是指创建一个新的对象,但新的对象中的属性仍然引用原对象的内存地址。也就是说,新的对象和原对象共享同一块内存中的数据。
- 如果原对象的某个属性是一个引用类型(如指针、列表、字典等),那么浅拷贝后的对象对这个属性的修改会影响到原对象,因为它们指向同一块内存。
#include <iostream>
#include <vector>
using namespace std;
class MyClass {
public:
vector<int> data;
MyClass(const vector<int>& vec) : data(vec) {}
};
int main() {
MyClass obj1({1, 2, 3});
MyClass obj2 = obj1; // 浅拷贝
obj2.data[0] = 100; // 修改 obj2 的 data
cout << obj1.data[0] << endl; // 输出 100,说明 obj1.data 也被修改了
return 0;
}
深拷贝(Deep Copy)
- 深拷贝是指创建一个新的对象,并且新对象中的所有属性(即使是引用类型)也都会复制一份。这样,原对象和新对象之间完全独立,修改一个不会影响另一个。
- 深拷贝需要显式地分配内存并复制数据。
#include <iostream>
#include <vector>
using namespace std;
class MyClass {
public:
vector<int> data;
MyClass(const vector<int>& vec) : data(vec) {}
// 深拷贝构造函数
MyClass(const MyClass& other) : data(other.data) {} // 注意:这实际上是浅拷贝
// 定义深拷贝的方法
MyClass deepCopy() const {
MyClass newObj({});
newObj.data = vector<int>(data.begin(), data.end()); // 深拷贝
return newObj;
}
};
int main() {
MyClass obj1({1, 2, 3});
MyClass obj2 = obj1.deepCopy(); // 深拷贝
obj2.data[0] = 100; // 修改 obj2 的 data
cout << obj1.data[0] << endl; // 输出 1,说明 obj1.data 没有被修改
return 0;
}
可调用对象包装器function、绑定器bind
可调用对象:
-
是一个函数指针
-
是一个具有operator()成员函数的类对象(仿函数)
-
是一个可被转换为函数指针的类对象
-
是一个类成员函数指针或者类成员指针
可调用对象的包装器function
绑定器bind
Lambda表达式
//capture是捕获列表,params是参数列表,opt是函数选项,ret是返回值类型,body是函数体。
[capture](params) opt -> ret {body;};
auto f = [](){return 1;} // 没有参数, 参数列表为空
auto f = []{return 1;} // 没有参数, 参数列表省略不写
int a = 0;
auto f1 = [=] {return a++; }; // error, 按值捕获外部变量, a是只读的
auto f2 = [=]()mutable {return a++; }; // ok,修改拷贝,而不是值本身
opt 选项:不需要可以省略
-
mutable: 可以修改按值传递进来的拷贝(注意是能 修改拷贝,而不是值本身)
-
exception: 指定函数抛出的异常,如抛出整数类型的异常,可以使用throw();
返回值类型:
-
在C++11中,lambda表达式的返回值是通过返回值后置语法来定义的。
-
但需要注意的是labmda表达式不能通过列表初始化自动推导出返回值类型。
函数体:函数的实现,这部分不能省略,但函数体可以为空,即{}。
捕获列表[]可以捕获一定范围内的变量,具体使用方式如下:
- [] - 不捕捉任何变量
- [&] - 捕获外部作用域中所有变量, 并作为引用在函数体内使用 (按引用捕获)
- [=] - 捕获外部作用域中所有变量, 并作为副本在函数体内使用 (按const值捕获)
- 拷贝的副本在匿名函数体内部是只读的
- [=, &foo] - 按值捕获外部作用域中所有变量, 并按照引用捕获外部变量 foo
- [bar] - 按值捕获 bar 变量, 同时不捕获其他变量
- [&bar] - 按引用捕获 bar 变量, 同时不捕获其他变量
- [this] - 捕获当前类中的this指针
- 让lambda表达式拥有和当前类成员函数同样的访问权限
- 如果已经使用了 & 或者 =, 默认添加此选项
class Test {
public:
void output(int x, int y)
{
auto x1 = [] {return m_number; }; //错误,没有捕获外部变量,不能使用类成员 m_number
auto x2 = [=] {return m_number + x + y; }; // 正确,以值拷贝的方式捕获所有外部变量
auto x3 = [&] {return m_number + x + y; }; // 正确,以引用的方式捕获所有外部变量
auto x4 = [this] {return m_number; }; // 正确,捕获this指针,可访问对象内部成员
auto x5 = [this] {return m_number + x + y; }; // 错误,捕获this指针,可访问类内部成员,没有捕获到变量x,y,因此不能访问。
auto x6 = [this, x, y] {return m_number + x + y; }; // 正确,捕获this指针,x,y
auto x7 = [this] {return m_number++; }; // 正确,捕获this指针,并且可以修改对象内部变量的值
}
int m_number = 100;
};
int main(void) {
int a = 10, b = 20;
auto f1 = [] {return a; }; //错误,没有捕获外部变量,因此无法访问变量 a
auto f2 = [&] {return a++; }; //正确,使用引用的方式捕获外部变量,可读写
auto f3 = [=] {return a; }; //正确,使用值拷贝的方式捕获外部变量,可读
auto f4 = [=] {return a++; }; //错误,使用值拷贝的方式捕获外部变量,可读不能写
auto f5 = [a] {return a + b; }; //错误,使用拷贝的方式捕获了外部变量a,没有捕获外部变量b,因此无法访问变量b
auto f6 = [a, &b] {return a + (b++); }; //正确,使用拷贝的方式捕获了外部变量a只读,使用引用的方式捕获外部变量b可读写
auto f7 = [=, &b] {return a + (b++); }; //正确,使用值拷贝的方式捕获所有外部变量以及b的引用,b可读写,其他只读
return 0;
}
【函数指针、仿函数(重载=的类)、可以转换为函数指针的对象、类里的成员函数+成员变量】
lambda表达式的类型在C++11中会被看做是一个带operator()的类,即本质是仿函数,但没捕获参数时可以当做函数指针。 因此可以使用std::function和std::bind来存储和操作lambda表达式:
#include <iostream>
#include <functional>
using namespace std;
int main(void) {
// 包装可调用函数
std::function<int(int)> f1 = [](int a) {return a; };
// 绑定可调用函数
std::function<int(int)> f2 = bind([](int a) {return a; }, placeholders::_1); // 包装器包装得到的是包装器对象
auto f2 = bind([](int a) {return a; }, placeholders::_1); // 得到的是仿函数,包装器可以包装这个仿函数,所以有上面的语句
// 函数调用
cout << f1(100) << endl;
cout << f2(200) << endl;
return 0;
}
对于没有捕获任何变量的lambda表达式,还可以转换成一个普通的函数指针:
using func_ptr = int(*)(int);
// 没有捕获任何外部变量的匿名函数
func_ptr f = [](int a) {
return a;
};
// 函数调用
f(1314);
右值引用
拷贝构造函数一般为了实现深拷贝
返回值是右值引用的拷贝构造函数叫移动构造函数
为实现浅拷贝,转移堆内存资源
stastic静态字面量:

(1)static关键字修饰局部变量不改变作用域,但是生命周期变长。
(2)本质上,static关键字修饰局部变量,改变了局部变量的存储位置,因为存储位置的差异,使得执行效果不一样。普通的局部变量放在栈区,这种局部变量进入作用域创建,出作用域释放。局部变量被static修饰后成为静态局部变量,这种变量放在静态区,创建好后,直到程序结束后才释放。
(3)static的另一个作用是默认初始化为0。其实全局变量也具备这一属性,因为全局变量也存储在静态数据区。在静态数据区,内存中所有的字节默认值都是0x00,某些时候这一特点可以减少程序员的工作量。
在全局和/或命名空间范围 (在单个文件范围内声明变量或函数时) *static 关键字指定变量或函数为内部链接*,即外部文件无法引用该变量或函数。
现代Cpp构建 CMAKE3.21+
C++ 程序从编写完毕到执行分为四个阶段:预处理、 编译、汇编和链接4个阶段,得到可执行程序之后就可以运行了。
| 阶段 | 工具类型 | 常见工具 |
|---|---|---|
| 预处理 | 预处理器 | cpp(gcc 和 clang 都包含) |
| 编译 | 编译器 | gcc、g++、clang、clang++、MSVC |
| 汇编 | 汇编器 | as(GNU assembler)、NASM、clang 汇编器 |
| 链接 | 链接器 | ld、gold、lld、MSVC linker |
预处理阶段:处理源代码中的宏定义(#define),头文件包含(#include),条件编译(#ifdef、#ifndef 等),删除注释;
编译阶段:将预处理后的代码(.i 文件)转换为对应的汇编代码(.s 文件),语法检查,进行优化(如循环展开、常量折叠等);
汇编阶段:将编译器生成的汇编代码(.s 文件)转化为机器代码(目标文件,扩展名 .o 或 .obj),汇编器会将汇编指令翻译成二进制的机器指令,但这些指令还无法直接执行,直到下一步的链接;
;链接阶段:将多个目标文件(.o 或 .obj 文件)和所需的库文件(如标准库、第三方库)结合,生成最终的可执行文件,处理外部符号的解析和重定位,合并不同模块中的符号,消除多余的重定义。
Conan
【柯南】
1. 安装 Conan 与初始化
pip install conan
确认安装版本:
conan --version
根据当前的操作系统和安装的工具猜测Conan配置文件:
conan profile detect --force
得到:
Detected profile:
[settings]
arch=x86_64
build_type=Release
compiler=gcc
compiler.cppstd=gnu17
compiler.libcxx=libstdc++11
compiler.version=11
os=Linux
2. Conan库管理
包保存的位置举例:
选择包的版本时,你可以搜索已经存在的包,看看它们是否已经存在于某个远程仓库中:
conan search boost
或者指定远程仓库:
conan search boost --remote=conancenter
安装依赖: conan install .
创建包: conan create . user/channel
上传包: conan upload <package> --all -r=remote
搜索包: conan search <package>
远程仓库管理: conan remote add <name> <url>
删除包:conan remove opencv/3.4.12
3. 使用conanfile安装库
3.1 创建 conanfile.txt /.py
conanfile.txt 文件描述了项目的依赖关系:
[requires]
opencv/4.5.5
cryptopp/8.6.0
[options]
opencv/4.5.5:shared=True # 如果需要动态库则设置为 True
opencv/4.5.5:dnn=True # 启用深度学习模块
opencv/4.5.5:highgui=True # 启用高GUI模块
opencv/4.5.5:imgproc=True # 启用图像处理模块
[generators]
CMakeDeps
CMakeToolchain
这意味着我们需要 cryptopp 库的 8.6.0 版本,并且我们使用 CMake 生成器来集成到 CMake 项目中。
- [requires] 部分是我们在 project,在本例中为 opencv/4.5.3。
- [generators] 部分告诉 Conan 生成编译器或 构建系统将用于查找依赖项并构建项目。在这种情况下, 由于我们的项目基于 CMake,我们将使用 CMakeDeps 来 生成有关 opencv 库文件安装位置的信息,并使用 CMakeToolchain 文件将构建信息传递给 CMake。
3.2 使用conanfile安装库
conan install . --output-folder=conan --build=missing
conan install . -c tools.system.package_manager:mode=install --output-folder=conan --build=missing
#在conan中
conan install ../ --output-folder=. --build=missing # 即可
.:表示当前目录有conanfile.txt文件。--build=missing:如果没有预编译的二进制包,则构建该库。- --output-folder=conan :输出文件在conan目录下。
- -c:表示conan可以自动安装系统库,tools.system.package_manager:mode有check和install两模式。默认check,若系统库缺失,安装过程将会失败,提示用户手动安装。Install模式下,Conan 会尝试自动安装缺失的系统库。
4. 与CMake配合
示例 CMakeLists.txt:
# 可选 指明最低cmake版本
cmake_minimum_required(VERSION 3.10.1)
# 描述项目
project(PalmLocalDemo VERSION 1.0
DESCRIPTION "It is a local palm project demo"
LANGUAGES CXX)
# 设置C++14编译,以及其他设置
set(CMAKE_CXX_STANDARD 14)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -pthread") # 多线程
set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -gdwarf-4") # 设置编译选项为DWARF 4
# clangd确保有这行
set(CMAKE_EXPORT_COMPILE_COMMANDS True)
# conan需要的命令
include(${CMAKE_SOURCE_DIR}/conan/conan_toolchain.cmake)
# 变量添加
set(EXECUTABLE_NAME test)
set(EXECUTABLE_OUTPUT_PATH ${CMAKE_SOURCE_DIR}/bin)
# 打包所有源文件 下面两种方式都可以
# aux_source_directory(${CMAKE_SOURCE_DIR}/src SOURCES)
file(GLOB SOURCES ${CMAKE_SOURCE_DIR}/src/*.cpp)
file(GLOB HEADERS ${CMAKE_SOURCE_DIR}/include/PalmDemo/*.h)
# 设置外部库头文件变量
set(EIGEN3_INCLUDE_DIRS ${CMAKE_SOURCE_DIR}/include/Eigen)
find_package(cryptopp REQUIRED)
find_package(OpenCV 4.5.5 REQUIRED)
add_executable(${EXECUTABLE_NAME} ${CMAKE_SOURCE_DIR}/main/main.cpp ${SOURCES})
# 设置链接库和包含目录,使用一次性调用来减少重复代码
target_link_libraries(${EXECUTABLE_NAME}
PUBLIC
${OpenCV_LIBS}
# opencv::opencv
cryptopp::cryptopp
)
# 设置包含头文件的目录
target_include_directories(${EXECUTABLE_NAME}
PUBLIC
${OpenCV_INCLUDE_DIRS}
${cryptopp_INCLUDE_DIRS}
${EIGEN3_INCLUDE_DIRS}
${CMAKE_SOURCE_DIR}/include # 自定义头文件目录
)
message(STATUS "OPencv Include Dirs: ${OpenCV_INCLUDE_DIRS}")
message(STATUS "OpenCV libraries: ${OpenCV_LIBS}")
message(STATUS "OpenCV version: ${OpenCV_VERSION}")
message(STATUS "Eigen include path: ${EIGEN3_INCLUDE_DIRS}")
5. 编译和运行项目
Conan2开始完全不需要修改 CMakeLists.txt 即可使用 Conan 包:
# Conan安装库示例
conan install . --output-folder=conan --build=missing -s build_type=Debug // 很重要的参数
source conan/conanbuild.sh # 相当于激活环境,将库添加到环境变量
# Cmake构建项目
cmake -B build -S . -DCMAKE_BUILD_TYPE=Debug
(-DCMAKE_TOOLCHAIN_FILE=conan/conan_toolchain.cmake可选,可以在cmakelist中写)
cmake --build build -jN #多核编译
./bin/可执行文件
#恢复到原来环境
source conan/deactivate_conanbuild.sh
-B 构建到build目录;
-S 使用.目录的CMakelists.txt文件;S是scource意思;
--build 编译构建到build
-j 使用多核编译 N可选核心数量
VSCode+clangd+lldb+cmake配置C/C++开发环境指南
依赖的软件包,基本上就是LLVM全家桶+cmake:
clang:我们使用的编译器,拥有更加人性化的报错clangd:一个C/C++的Language Sever后端,薄纱C/C++ Toolslldb:调试工具,一家人就要整整齐齐cmake:构造工具,因为clangd需要读取compile_commands.json才能提供服务
Ubuntu使用下面的指令进行安装,homebrew或者pacman同理(这也要教?)
sudo apt install clang clangd lldb cmake

