
后台管理+内容平台+商城通用版项目万字长文解析
牛客的markdown解析器有点一般,大家需要的话还是找我要语雀链接吧,纯开源
vue 版
- 负责 axios 请求的二次封装,添加请求拦截器与响应拦截器,对全局的请求与错误处理进行统一
- 针对商品首页的长列表数据渲染,采用图片懒加载+无限加载+虚拟列表的终极方案优化大数据场景下页面的渲染时间;同时观测 performance,确定页面渲染过程中耗时过长的长任务,并将此分割为多个短任务
- 使用 keep-alive 对整个页面进行缓存,支持多级嵌套页面
- 平台迭代过程中负责将 Pinia 对 Vuex 进行替代
- 使用 Pinia 进行全局全局状态管理,并结合 LocalStorage 持久化存储用户数据,管理用户菜单数据、角色权限等信息
- 使用vue-router 实现路由守卫,基于用户角色动态注册路由,并结合按钮权限控制页面访问,实现 RBAC(基于角色的访问控制)权限管理
- 通过 echarts 实现对内容流量数据和内容分析数据的可视化展示,负责主题化(暗黑模式)切换及持久化保持设置
- 设计双 Token 方案,自动管理 access token 和 refresh token 的生命周期,实现无感登录
- 独立负责表单上传等完整需求,使用断点续传、切片上传等技术保障大文件上传的稳定性;使用 canvas 对大图片进行压缩,提供上传速度
针对这个项目系统整理了几篇专题,有兴趣可以详细看看:
怎么对 axios 进行二次封装的,请求拦截器和响应拦截器分别做了什么
大概从以下几方面进行作答:
- 请求拦截器
* 对 Get、Post、Put、Delete 请求进行封装
* 请求头统一配置
* 如果登录方案使用 token,还需要将 token 放在请求头下面的 authorization 中
- 响应拦截器
* 对 http 错误码进行拦截,比如说`401 403 404`等
* 简化返回信息,什么意思呢,比如后端初始返回的结构如下:
{
data: {
code: 200,
data: {
}
}
}
而我们只需要if (data.code) === 200,就直接将data.data进行resolve
Get 请求和 Post 请求的区别
因为上述在 axios 封装中提到了这些请求,所以这些问题也需要详细准备一下
- 缓存:Get 请求有缓存,Post 没有
- 参数:Get 参数直接添加到 URL 后面,Post 请求放在请求体中
- 幂等:Get 无论请求多少次,所得的资源都是相同的
- 编码:Get 只能进行 URL 编码,Post 没有限制
Get、Post、Put、Delete 请求的含义
- Get:请求资源
- Post:创建资源
- Put:更新资源
- Delete:删除资源
HTTP 常见的状态码有哪些
- 2XX
* 200:表示请求成功,数据放在响应体中
* 201:表示在服务器中创建了新资源。比如创建一个新的用户
* 202:表示服务器端已经收到了请求,但是还没有处理
* 204:表示资源请求成功,但是响应体中没有数据
- 3XX
* 301:永久重定向
* 302:暂时重定向
* 304:可以使用协商缓存
- 4XX
* 400:笼统的错误码,表示资源请求错误
* 401:表示需要认证后才能访问的资源
* 403:表示服务器直接拒绝 http 请求,一般用来针对非法请求
* 404:未找到资源
* 409:表示请求的资源与当前服务器的状态发生冲突
* 429:请求过多
- 5XX
* 500:笼统的错误码,表示服务器发生错误
* 501:表示请求的功能还未支持,类似于敬请期待
* 502:访问后端服务器发生了错误
* 503:表示服务器很忙
HTTP 和 HTTPS 的区别
https = https + 加密 + 认证 + 完整性保护
具体来说,分为以下四点:
- HTTP 是超文本传输协议,信息是明文传输,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输
- HTTP 连接建立相对简单,TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输
- 两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的
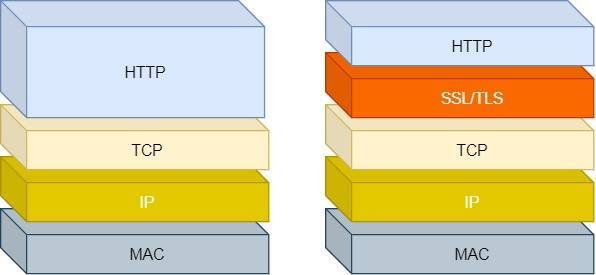
可以看出, HTTPS 相比于 HTTP,多了一层 SSL/TLS 协议,并且针对于 http 的问题,提出了相应的解决方式
| 窃听风险 | 实现信息加密:采用混合加密的方式实现信息的机密性 |
| 篡改风险 | 实现校验机制:通过摘要算法来实现完整性,它能够为数据生成独一无二的指纹从而来校验数据的完整性 |
| 冒充风险 | 身份证书:通过第三方认证机构来对身份进行鉴定,即将服务器公钥放在了数字证书中,解决了冒充的风险 |
HTTPS 的加密方式及其过程
HTTPS 采用的是对称加密和非对称加密结合的混合加密的方式
对称加密
含义:解密和加密都使用的相同的密钥
过程:
- 浏览器发送所支持的加密套件列表和一个随机数
client-random - 服务器从加密套件列表中选取一个加密套件,然后生成一个随机数
service-random,并将这个随机数和加密套件列表返回给浏览器 - 最后浏览器和服务器分别返回确认信息
- 然后两者混合生成密钥 master-secret,这样就可以进行数据的加密传输了
缺陷:传输是明文的,通过可能被监听到从而可以获得密钥
非对称加密
含义:公钥是每个人都可以获取到的,存储在浏览器中,私钥只有服务器才知道,不对任何人公开
- 公钥:服务器会将公钥以明文的形式发送给客户端
- 私钥:必须由服务器管理,不可以泄露,两个密钥可以双向加解密
过程:
- 浏览器发送加密套件列表给服务器
- 然后服务器会选择一个加密套件,不过与对称加密不同的是:非对称加密中服务器会存在用户浏览器加密的公钥和服务器解密 HTTP 数据的私钥
- 由于公钥是给浏览器使用的,所以服务器会将加密套件和公钥一同发送给浏览器
- 最后浏览器和服务器返回确认信息
缺点:
- 非对称加密的效率太低,处理大数据低效
- 无法保证服务器发送给浏览器的数据安全:虽然浏览器可以使用公钥来加密,但是服务器只能使用私钥来加密,私钥加密只有公钥能解密,但黑客也是可以获取到公钥的,这样就不能保证服务器端的数据安全
混合加密
含义:在传输数据阶段使用对称加密,但是对称加密的密钥使用非对称加密来传输
具体流程:
- 首先浏览器向服务器发送对称加密套件列表,非对称加密套件列表和随机数 client-random
- 服务器保存随机数 client-random,向浏览器发送选择的加密套件、service-random 和公钥
- 浏览器保存公钥,并生成随机数 pre-master,利用公钥对 pre-master 加密,并向服务器发送加密后的数据
- 最后服务器拿出自己的私钥,解密出 pre-master 数据,并返回确认信息
- 然后服务器和浏览器会使用三组随机数生成对称密钥
缺点: 被 DNS 劫持替换 IP 地址在自己服务器上实现公钥和私钥,将使用 ca 证书来解决
CA 认证和摘要算法
在上述已经说过,https = http + 加密 + 认证 + 完整性保护
我们已经详细讲过加密这一小节了,接下来讲讲认证和完整性保护(摘要算法+数字签名)
CA 认证
CA 认证解决的是什么问题呢,混合加密的缺陷我们已经知道,可能被伪造假的公钥和私钥,从而造成数据泄露。
那么这时候,我们就需要一家权威的机构来验证身份是否合法,这家权威的机构就是 CA(数字证书认证机构),将服务器公钥放在数字证书中(由数字证书认证机构颁发),只要证书是可信的,公钥就是可信的
摘要算法 + 数字签名
通过摘要算法+数字签名来确保数据的完整性
简单来说,就是为了保证传输的内容不受到篡改,我们需要对内容计算出一个【指纹】,然后同内容一同传输给对方。对方收到也会先对内容计算出一个【指纹】,然后与传输过来的指纹进行对比,如果一致,则说明内容并没有被篡改。
那么,在计算机中,会使用摘要算法(哈希算法)来计算出内容的哈希值,这个哈希值是唯一的,且无法通过哈希值推导出内容。
通过摘要算法,我们可以确保内容无法被篡改,但是无法确保【内容+哈希值】不会被中间人所替换,因为这里缺乏对客户端收到的消息是否来自服务端的认证。
为了解决这个问题,计算机中会采用非对称加密的方法来解决,跟之前讲的一样,非对称加密会有两个密钥:
- 公钥:存储在客户端中,可以公开给所有人
- 私钥:存储在服务端中,不可泄露
这两个密钥可以双向加解密:
- 公钥加密,私钥解密:这个目的是为了保证内容传输
- 私钥加密,公钥解密:
因为非对称加密是比较耗时的,所以我们一般不会使用非对称加密来加密时机传输的内容,而只是对内容的哈希值进行加密
所以非对称加密的用途主要通过私钥加密,公钥解密的方式来确认消息的身份,我们常说的数字签名算法,就是使用的这种方式。
私钥是由服务端保管,然后服务端会向客户端颁发对应的公钥。如果客户端收到的信息,能被公钥解密,那说明该消息是由服务器推送的
HTTPS 建立连接的全流程
也就是 TLS 的握手过程:
- 客户端发起请求
首先,由客户端向服务器发起加密通信请求,也就是 ClientHello 请求。
在这一步,客户端主要向服务器发送以下信息:
1. 客户端支持的 TLS 协议版本,如 TLS 1.2 版本。
2. 客户端生产的随机数(`Client Random`),后面用于生成「会话秘钥」条件之一。
3. 客户端支持的密码套件列表,如 RSA 加密算法。
2.服务器响应
服务器收到客户端请求后,向客户端发出响应,也就是 SeverHello。服务器回应的内容有如下内容:
1. 确认 TLS 协议版本,如果浏览器不支持,则关闭加密通信
2. 服务器生产的随机数(`Server Random`),也是后面用于生产「会话秘钥」条件之一。
3. 确认的密码套件列表,如 RSA 加密算法
4. 服务器的数字证书。
3.验证证书
客户端收到服务器的回应之后,首先通过浏览器或者操作系统中的 CA 公钥,确认服务器的数字证书的真实性。
如果证书没有问题,客户端会从数字证书中取出服务器的公钥,然后使用它加密报文,向服务器发送如下信息:
1. 一个随机数(`pre-master key`)。该随机数会被服务器公钥加密。
2. 加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信。
3. 客户端握手结束通知,表示客户端的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供服务端校验。
上面第一项的随机数是整个握手阶段的第三个随机数,会发给服务端,所以这个随机数客户端和服务端都是一样的
服务器和客户端有了这三个随机数(Client Random、Server Random、pre-master key),接着就用双方协商的加密算法,各自生成本次通信的「会话秘钥」。
- 服务器的最后回应
服务器收到客户端的第三个随机数(pre-master key)之后,通过协商的加密算法,计算出本次通信的「会话秘钥」。
然后,向客户端发送最后的信息:
1. 加密通信算法改变通知,表示随后的信息都将用「会话秘钥」加密通信
2. 服务器握手结束通知,表示服务器的握手阶段已经结束。这一项同时把之前所有内容的发生的数据做个摘要,用来供客户端校验
至此,整个 TLS 的握手阶段全部结束。接下来,客户端与服务器进入加密通信,就完全是使用普通的 HTTP 协议,只不过用「会话秘钥」加密内容
HTTP2.0 做了哪些改进
简单来说有以下五点:
- 多路复用:将 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP 2 最重要的一项增强。事实上,这个机制会在整个网络技术栈中引发一系列连锁反应,从而带来巨大的性能提升
- 头部压缩:利用霍夫曼编码,可以在传输时对各个值进行压缩,而利用之前传输值的索引列表,我们可以通过传输索引值的方式对重复值进行编码,索引值可用于有效查询和重构完整的标头键值对
- 新的二进制格式:HTTP/2 将 HTTP 协议通信分解为二进制编码帧的交换,这些帧对应着特定数据流中的消息。所有这些都在一个 TCP 连接内复用。 这是 HTTP/2 协议所有其他功能和性能优化的基础
- 服务端推送(Server Push)
- 数据流
图片懒加载是怎么做的:
大致有两种方案:
1. 给图片加上 lazy 属性,但是这种方式属于是浏览器新特性,不一定全部的浏览器都可以支持
2. 使用 JS 判断图片是否到达可视区域,当图片出现在可视区域时,用图片的`data-src`属性给图片的 `src`属性赋值
所以难点就是怎么判断图片有没有到达可视区域
怎么判断元素有没有到达可视区域
方法也是有两种的:
1. 使用`IntersectionObserver`
2. 使用`scrollTop`进行高度判断:这个方法需要我们确认以下三个指标:
* `window.innerHeight`:浏览器可视区域的高度
* `document.body.scrollTop`:浏览器滚动了的距离,即浏览器可视区域顶部到文档顶部的距离
* `imgs.offsetTop`:元素至文档顶部的距离
在知晓了上述三个指标的值之后,如果imgs.offetTop < window.innerHeight + document.body.scrollTop即在可视区域内。这里的指标跟无限加载利用滚动高度判断是否触底的场景的指标有些细微不同的,需要注意一下
无限加载是怎么做的,怎么判断触底了呢
第 10 个问题——第 12 点问题都可参考博主之前写的专题文章:怎么解决长列表的渲染问题
无限加载指的用户滑动到页面底部再去请求下一屏数据,所以核心便是怎么判断用户是否滑动到底部,这里有两种方法:
IntersectionObserver
const io = new IntersectionObserver(callback, option);
**介绍:**上述代码中, IntersectionObserver 接受两个参数:callback 是可见性变化时的回调函数,option 是一个可选的配置项。构造函数的返回值是一个观察器实例。实例的 observe 方法可以指定观察哪个 DOM 节点
**做法:**设定某个哨兵元素(通常是 DIV)放置在列表底部,当监听到它进入视口时,就触发下一屏数据的加载
const observer = new IntersectionObserver((entries) => {
if (entries[0].isIntersecting) {
loadMoreData(); // 加载下一页数据
}
});
observer.observe(document.getElementById("sentinel"));
监听 ScrollTop + 容器高度
**介绍: **
document.body.scrollTop; // 浏览器滚动了的距离
ele.scrollHeight; // 元素内容总高度
ele.clientHeight; // 元素可视区域高度
用法:通过手动监听滚动事件,根据scrollTop + clientHeight >= scrollHeight判断是否到底。这里的ele呢,指的是包裹整个列表元素的根节点,所以跟之前单个图片元素的判断指标略显不同,不过大致的原理还是一样的。
const list = document.getElementById("list");
list.addEventListener("scroll", () => {
if (list.scrollTop + list.clientHeight >= list.scrollHeight - 10) {
// 根据情况,可以加buffer,这里加了10px
loadMoreData(); // 加载下一页数据
}
});
需要注意的是,由于会频繁触发scroll事件,所以需要对 scroll 的回调函数添加节流处理
// 节流函数,确保在 delay 毫秒内只执行一次
function throttle(fn, delay) {
let mark = null;
return function (...args) {
if (!mark) {
mark = setTimeOut(() => {
fn.call(this, args);
mark = null;
}, delay);
}
};
}
const list = document.getElementById("list");
function handleScroll() {
if (list.scrollTop + list.clientHeight >= list.scrollHeight - 10) {
loadMoreData(); // 加载下一页数据
}
}
// 加上节流,100ms 执行一次
list.addEventListener("scroll", throttle(handleScroll, 100));
对比
监听 scroll 事件虽然可行,但是其加了节流,仍会多次触发滚动事件,造成性能上的低劣。
优化
当然,在实际使用中,我们可以在用户真正滑到“底部”之前,提前一段距离触发数据加载,让下一页数据在用户到达时已经准备好,避免加载等待,做到“无感下滑”
const observer = new IntersectionObserver(
(entries) => {
if (entries[0].isIntersecting) {
loadMoreData();
}
},
{
root: list, // 滚动容器
rootMargin: "0px 0px 300px 0px", // 提前 300px 触发
}
);
observer.observe(document.getElementById("sentinel"));
虚拟列表的实现方案呢
当页面需要一次性加载渲染大量数据时,虚拟列表无疑是最好的方案。其是一种只渲染可视窗口内的元素而其余元素不进行渲染的技术,从而极大程度上减少 DOM 数量,提升渲染性能
listItem 定高
原理:
虚拟列表主要依赖两个核心进行计算:
- 当前滚动位置
- 列表项的高度
通过滚动的位置+每一项的高度,我们就可以推断出当前应该渲染的列表项的起始 Index,并将容器下方和容器上方顶起来,这样就形成了一个简单的虚拟列表,示意图如下:
+------------------------------------+
| [ 顶部占位高度 (paddingTop) ] |
| [ 可视区域:只渲染可见的几项 ] |
| [ 底部占位高度 (paddingBottom) ] |
+------------------------------------+
实现:
基于此,我们可以用代码简单的实现一下:
import React, { useRef, useState, useEffect } from "react";
const VirtualList = ({
height = 400, // 容器高度
itemHeight = 40, // 单项高度
data = [], // 列表数据
renderItem, // 渲染函数
buffer = 5, // 额外缓冲项数量
}) => {
const containerRef = useRef(null);
const [scrollTop, setScrollTop] = useState(0);
const totalCount = data.length;
const visibleCount = Math.ceil(height / itemHeight) + buffer;
const startIndex = Math.floor(scrollTop / itemHeight);
const endIndex = Math.min(startIndex + visibleCount, totalCount);
const offsetTop = startIndex * itemHeight;
const visibleData = data.slice(startIndex, endIndex);
const handleScroll = (e) => {
setScrollTop(e.target.scrollTop);
};
return (
<div
ref={containerRef}
style={{ height, overflowY: "auto", border: "1px solid #ccc" }}
onScroll={handleScroll}
>
<div style={{ height: totalCount * itemHeight, position: "relative" }}>
<div style={{ paddingTop: offsetTop }}>
{visibleData.map((item, index) => (
<div
key={startIndex + index}
style={{ height: itemHeight, borderBottom: "1px solid #eee" }}
>
{renderItem(item, startIndex + index)}
</div>
))}
</div>
</div>
</div>
);
};
export default VirtualList;
有没有考虑过不定高的做法
listItem 不定高
那么,不定高的虚拟列表的难点在哪里呢,简单来说,其难点有两个:
- 首先外部容器的总长不确定
- 其次无法通过 scrollTop / 元素高度 获得初识索引值
对应的解决措施可以归纳为:
- 针对难点 1,可以初始假定一个足够元素长度,因为精确地计算出容器总高度的意义不是很大,之后在每次滚动时,累加计算已经滚动过的元素高度,加上剩余元素的假定高度,实时更新容器的最终高度,但是 pc 端会出现拖拽滑轮滚动比不一致情况
- 针对难点 2,根据视口高度累加展示的元素高度和,如果滑动到的高度高于已经累加过的元素高度和,则再进行累加,直到满足高度。但是需要一个 map 用来存储已经滑动过的元素高度信息,包括元素自身的高度和它之前的总高度 => 双链表+哈希
可参考代码如下:
import React, { useRef, useState, useEffect } from "react";
const VirtualListDynamic = ({
data = [],
estimatedHeight = 100,
containerHeight = 400,
overscan = 5,
renderItem,
}) => {
const containerRef = useRef(null);
const itemRefs = useRef({});
const heightMap = useRef(new Map()); // index => { height, offsetTop }
const [scrollTop, setScrollTop] = useState(0);
const [totalHeight, setTotalHeight] = useState(data.length * estimatedHeight);
// 计算 offsetMap 用于累加高度定位起始项
const buildOffsetMap = () => {
let offset = 0;
const map = new Map();
for (let i = 0; i < data.length; i++) {
const height = heightMap.current.get(i)?.height ?? estimatedHeight;
map.set(i, { height, offsetTop: offset });
offset += height;
}
setTotalHeight(offset);
return map;
};
const offsetMap = buildOffsetMap();
// 找到可视区域的起始 index
const getStartIndex = () => {
let i = 0;
while (i < data.length) {
const { offsetTop, height } = offsetMap.get(i);
if (offsetTop + height > scrollTop) break;
i++;
}
return Math.max(0, i);
};
const startIndex = getStartIndex();
const endIndex = Math.min(data.length, startIndex + overscan + 20);
const topPadding = offsetMap.get(startIndex)?.offsetTop ?? 0;
const bottomPadding =
totalHeight - (offsetMap.get(endIndex)?.offsetTop ?? totalHeight);
// 监听滚动
const onScroll = (e) => {
setScrollTop(e.target.scrollTop);
};
// 渲染后记录真实高度
useEffect(() => {
const updated = new Map(heightMap.current);
let changed = false;
for (let i = startIndex; i < endIndex; i++) {
const el = itemRefs.current[i];
if (el) {
const height = el.getBoundingClientRect().height;
if (!updated.has(i) || updated.get(i).height !== height) {
updated.set(i, { height, offsetTop: 0 }); // offsetTop 会在 buildOffsetMap 中更新
changed = true;
}
}
}
if (changed) {
heightMap.current = updated;
}
}, [startIndex, endIndex]);
return (
<div
ref={containerRef}
style={{
height: containerHeight,
overflowY: "auto",
border: "1px solid #ccc",
}}
onScroll={onScroll}
>
<div style={{ height: totalHeight, position: "relative" }}>
<div style={{ paddingTop: topPadding, paddingBottom: bottomPadding }}>
{data.slice(startIndex, endIndex).map((item, i) => {
const index = startIndex + i;
return (
<div
key={index}
ref={(el) => (itemRefs.current[index] = el)}
style={{ marginBottom: 4 }}
>
{renderItem(item, index)}
</div>
);
})}
</div>
</div>
</div>
);
};
export default VirtualListDynamic;
无限加载+虚拟列表
但是在实际的场景应用中,即便我们使用的无限加载,但是当用户多刷几屏之后,当前页面需要维护的 DOM 元素也变得多了起来,那么根据上述所讲的内容,我们就需要给页面加上虚拟列表的功能。
所以综合来说,对于长列表渲染的问题,使用无限加载+虚拟列表才是优化长列表渲染的终极方案
说说你是怎么去观测 performance 的吧,主要去观测哪些具体的指标
先贴一张 performance 中的指标详细图吧:
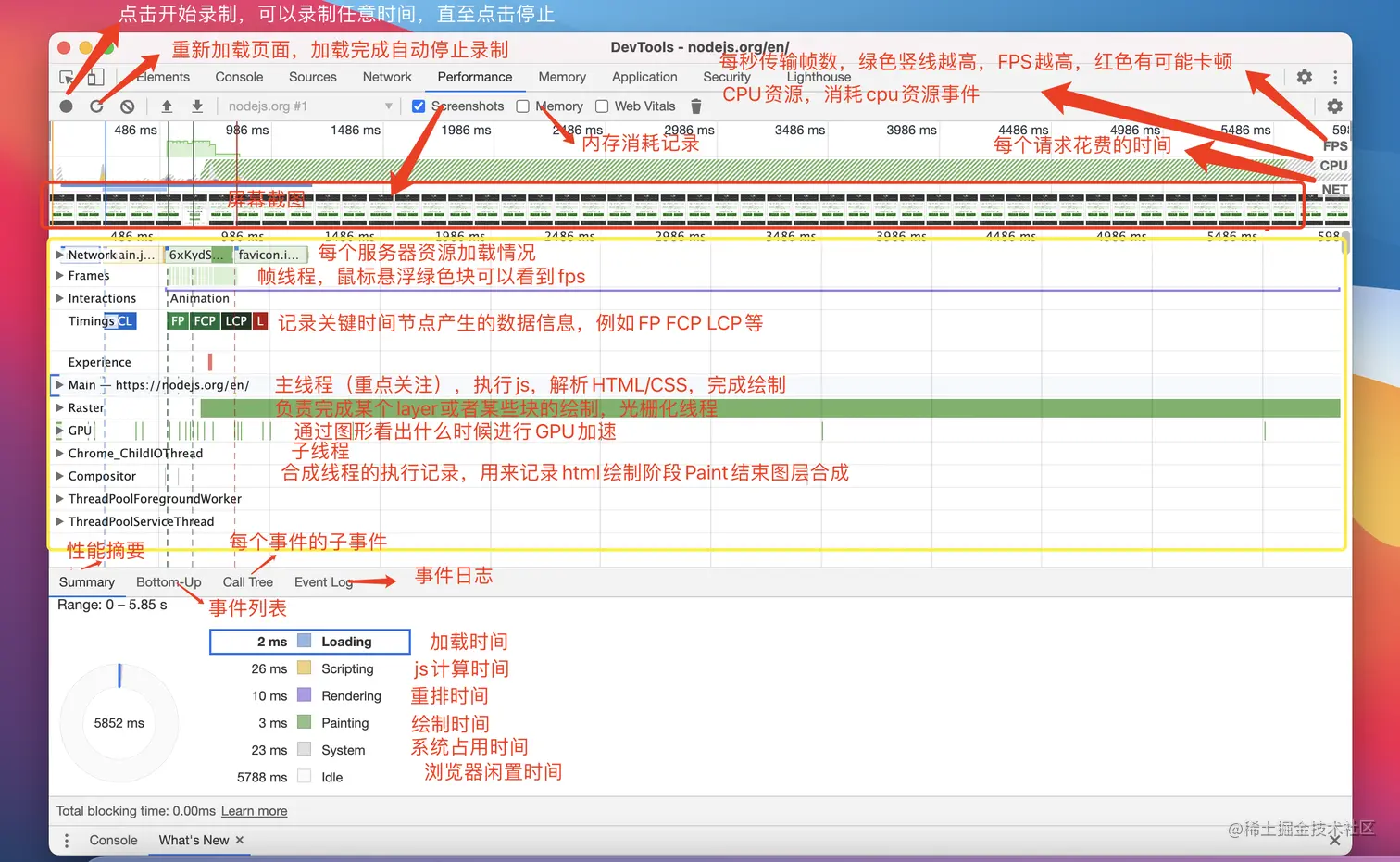
这张图相当重要,是浏览器综合运行开销分析的利器,最上面分为 4 个部分:
- FPS:每秒帧数,绿色竖线越高表示 FPS 越高,出现红线则表示出现了卡顿。
- CPU:CPU 资源,用面积图展示消耗 CPU 资源的事件。
- NET:网络消耗,每条横杠表示一种资源的加载。
- HEAP:内存水位,由于短时间内看不出来是否会内存溢出,一般只用来简单看看内存消耗是否符合预期,对于内存溢出的检测需要用持续监控上报的方式
下面会有一张 Network 详细图解,比如这张图:
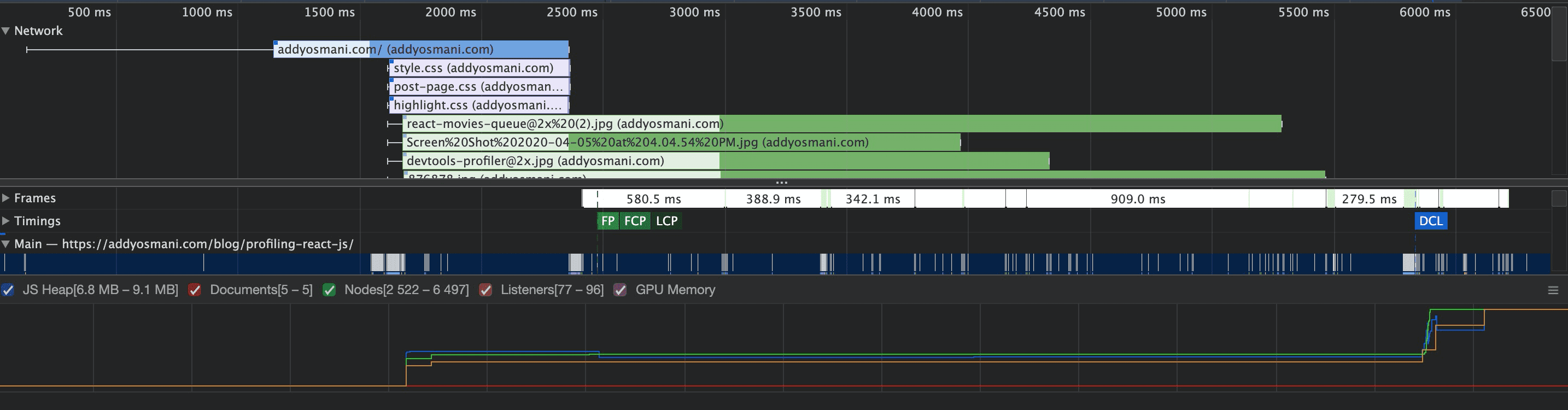
细线表示等待的时间,粗线表示实际加载的情况,其中浅色部分表示服务器等待时间,即从发送下载请求到服务器响应第一个字节的时间。这部分可以看出资源并行加载阻塞情况以及资源服务器响应时间是否存在问题。
Timings 展示了几个重要时间节点,这里列举一部分:
- FP:First Paint,第一次绘制。
- FCP:First Contentful Paint,第一次内容绘制。
- LCP:Largest Contentful Paint,最大内容绘制。
- DCL:Document Content Loaded,DOM 内容加载完毕。
再下面是 JS 计算消耗,用了一张火焰图,火焰图是性能分析的常用可视化工具。以下面这张图为例:
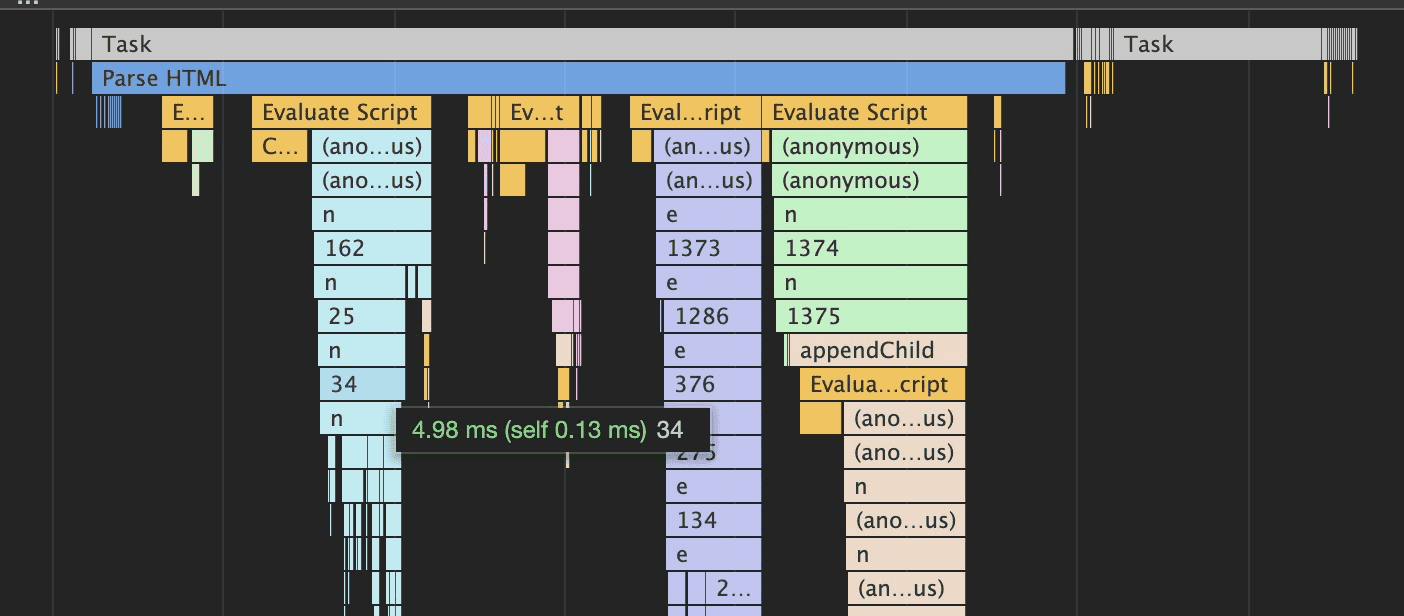
看火焰图首先看跨度最长的函数,也就是最长的那条线,这是最耗时的部分,从左到右是浏览器脚本的调用顺序,从上到下是函数嵌套的顺序。
我们可以看到鼠标位置的 34 这个函数虽然长,但并不是性能瓶颈,因为下面执行的 n 函数长度和它一样,表示 34 函数的性能几乎无损耗,其性能由其调用的 n 函数决定。
我们可以利用这种方式一步步排查到叶子结点,找到对性能影响最大的元子函数
长任务是什么呢
浏览器的主线程一次只能处理一个任务,任何用户超过 50ms 的任务都是长任务
你一般怎么将长任务分割为短任务
setTimeout:
通过 setTimeout 短暂中断工作让出主线程,适合于需要按照顺序执行的一系列函数,比如:
function saveSettings() {
// 优先处理用户可见的关键任务
validateForm();
showSpinner();
updateUI();
// 将对用户不可见的工作延后到单独的任务中执行
setTimeout(() => {
saveToDatabase();
sendAnalytics();
}, 0);
}
schedule.yield:
由于 setTimeout 是宏任务,所以当我们使用其让出主线程以让任务推迟到后续任务中运行时,该任务会添加到队列的末尾。如果此时有其它任务正在等待,它们将在延迟执行的代码之前运行。
这时候,我们可以就需要用到 schedule.yield(),一个专门为让出浏览器主线程而设计的 API。在上述情况中,如果我们使用该 API,函数将会从上述停止的位置继续执行:
async function saveSettings() {
// 优先处理用户可见的关键任务
validateForm();
showSpinner();
updateUI();
// 让出主线程
await scheduler.yield();
// 将对用户不可见的工作延后到单独的任务中执行
saveToDatabase();
sendAnalytics();
}
web worker:
老生常谈的一个概念了,可以将一些同步的耗时操作放在 worker 中进行执行,以免阻塞主线程
一次性渲染从后端传来的大量数据,你除了上述的虚拟列表以及无限加载还有哪些方式来进行优化吗
一次性渲染是为了解决卡顿问题,本质上就是去解决数据一次性渲染到页面中造成的长任务,所以这个场景题就是要问我们:怎么将长任务优化为短任务?
可参考上一个问题:《你一般怎么将长任务切割为短任务》
简单讲一讲 keep-alive 的原理吧
基本原理
- 缓存机制 :keep-alive 不会生成真实 DOM 节点,它是一个抽象组件。它通过自身的 render 函数,将内部包裹的组件实例缓存到内存中,而不是销毁它们。
- 生命周期钩子 :当组件被 keep-alive 缓存时,会触发特殊的生命周期钩子:
- activated :当缓存的组件被激活时触发
- deactivated :当缓存的组件被停用时触发
- 缓存策略 :keep-alive 组件内部维护了一个缓存对象(cache)和一个缓存组件的键数组(keys),通过 LRU 算法来管理缓存。
实现细节
- 缓存存储 :keep-alive 内部通过一个 JavaScript 对象来存储缓存的组件实例。
- 缓存控制 :keep-alive 提供了三个属性来控制缓存行为:
- include :字符串或正则表达式,只有名称匹配的组件会被缓存
- exclude :字符串或正则表达式,任何名称匹配的组件都不会被缓存
- max :数字,最多可以缓存多少组件实例
- 缓存更新 :当缓存的组件数量超过 max 设置值时,会优先删除最久未使用的组件。
说一说 vue 中组件进行通信的方式
组件通信的方式如下:
(1) props / $emit
父组件通过props向子组件传递数据,子组件通过$emit和父组件通信
父组件向子组件传值
props只能是父组件向子组件进行传值,props使得父子组件之间形成了一个单向下行绑定。子组件的数据会随着父组件不断更新。props可以显示定义一个或一个以上的数据,对于接收的数据,可以是各种数据类型,同样也可以传递一个函数。props属性名规则:若在props中使用驼峰形式,模板中需要使用短横线的形式
// 父组件
<template>
<div id="father">
<son :msg="msgData" :fn="myFunction"></son>
</div>
</template>
<script>
import son from "./son.vue";
export default {
name: father,
data() {
msgData: "父组件数据";
},
methods: {
myFunction() {
console.log("vue");
}
},
components: {
son
}
};
</script>
// 子组件
<template>
<div id="son">
<p>{{msg}}</p>
<button @click="fn">按钮</button>
</div>
</template>
<script>
export default {
name: "son",
props: ["msg", "fn"]
};
</script>
子组件向父组件传值
$emit绑定一个自定义事件,当这个事件被执行的时就会将参数传递给父组件,而父组件通过v-on监听并接收参数。
// 父组件
<template>
<div class="section">
<com-article :articles="articleList" @onEmitIndex="onEmitIndex"></com-article>
<p>{{currentIndex}}</p>
</div>
</template>
<script>
import comArticle from './test/article.vue'
export default {
name: 'comArticle',
components: { comArticle },
data() {
return {
currentIndex: -1,
articleList: ['红楼梦', '西游记', '三国演义']
}
},
methods: {
onEmitIndex(idx) {
this.currentIndex = idx
}
}
}
</script>
//子组件
<template>
<div>
<div v-for="(item, index) in articles" :key="index" @click="emitIndex(index)">{{item}}</div>
</div>
</template>
<script>
export default {
props: ['articles'],
methods: {
emitIndex(index) {
this.$emit('onEmitIndex', index) // 触发父组件的方法,并传递参数index
}
}
}
</script>
(2)eventBus 事件总线( on)
on)
eventBus事件总线适用于父子组件、非父子组件等之间的通信,使用步骤如下:
(1)创建事件中心管理组件之间的通信
// event-bus.js
import Vue from "vue";
export const EventBus = new Vue();
(2)发送事件
假设有两个兄弟组件firstCom和secondCom:
<template>
<div>
<first-com></first-com>
<second-com></second-com>
</div>
</template>
<script>
import firstCom from './firstCom.vue'
import secondCom from './secondCom.vue'
export default {
components: { firstCom, secondCom }
}
</script>
在firstCom组件中发送事件:
<template>
<div>
<button @click="add">加法</button>
</div>
</template>
<script>
import {EventBus} from './event-bus.js' // 引入事件中心
export default {
data(){
return{
num:0
}
},
methods:{
add(){
EventBus.$emit('addition', {
num:this.num++
})
}
}
}
</script>
(3)接收事件
在secondCom组件中发送事件:
<template>
<div>求和: {{count}}</div>
</template>
<script>
import { EventBus } from './event-bus.js'
export default {
data() {
return {
count: 0
}
},
mounted() {
EventBus.$on('addition', param => {
this.count = this.count + param.num;
})
}
}
</script>
在上述代码中,这就相当于将num值存贮在了事件总线中,在其他组件中可以直接访问。事件总线就相当于一个桥梁,不用组件通过它来通信。
虽然看起来比较简单,但是这种方法也有不变之处,如果项目过大,使用这种方式进行通信,后期维护起来会很困难。
(3)依赖注入(provide/ inject)
这种方式就是 Vue 中的依赖注入,该方法用于父子组件之间的通信。当然这里所说的父子不一定是真正的父子,也可以是祖孙组件,在层数很深的情况下,可以使用这种方法来进行传值。就不用一层一层的传递了。
provide / inject是 Vue 提供的两个钩子,和data、methods是同级的。并且provide的书写形式和data一样。
provide钩子用来发送数据或方法inject钩子用来接收数据或方法
在父组件中:
provide() {
return {
num: this.num
};
}
在子组件中:
inject: ["num"];
还可以这样写,这样写就可以访问父组件中的所有属性:
provide() {
return {
app: this
};
}
data() {
return {
num: 1
};
}
inject: ['app']
console.log(this.app.num)
注意: 依赖注入所提供的属性是非响应式的。
(3)ref / $refs
这种方式也是实现父子组件之间的通信。
ref: 这个属性用在子组件上,它的引用就指向了子组件的实例。可以通过实例来访问组件的数据和方法。
在子组件中:
export default {
data() {
return {
name: "JavaScript",
};
},
methods: {
sayHello() {
console.log("hello");
},
},
};
在父组件中:
<template>
<child ref="child"></component-a>
</template>
<script>
import child from './child.vue'
export default {
components: { child },
mounted () {
console.log(this.$refs.child.name); // JavaScript
this.$refs.child.sayHello(); // hello
}
}
</script>
(4) children
children
- 使用
$parent可以让组件访问父组件的实例(访问的是上一级父组件的属性和方法) - 使用
$children可以让组件访问子组件的实例,但是,$children并不能保证顺序,并且访问的数据也不是响应式的。
在子组件中:
<template>
<div>
<span>{{message}}</span>
<p>获取父组件的值为: {{parentVal}}</p>
</div>
</template>
<script>
export default {
data() {
return {
message: 'Vue'
}
},
computed:{
parentVal(){
return this.$parent.msg;
}
}
}
</script>
在父组件中:
// 父组件中
<template>
<div class="hello_world">
<div>{{msg}}</div>
<child></child>
<button @click="change">点击改变子组件值</button>
</div>
</template>
<script>
import child from './child.vue'
export default {
components: { child },
data() {
return {
msg: 'Welcome'
}
},
methods: {
change() {
// 获取到子组件
this.$children[0].message = 'JavaScript'
}
}
}
</script>
在上面的代码中,子组件获取到了父组件的parentVal值,父组件改变了子组件中message的值。
需要注意:
- 通过
$parent访问到的是上一级父组件的实例,可以使用$root来访问根组件的实例 - 在组件中使用
$children拿到的是所有的子组件的实例,它是一个数组,并且是无序的 - 在根组件
#app上拿$parent得到的是new Vue()的实例,在这实例上再拿$parent得到的是undefined,而在最底层的子组件拿$children是个空数组 $children的值是数组,而$parent是个对象
(5) listeners
listeners
考虑一种场景,如果 A 是 B 组件的父组件,B 是 C 组件的父组件。如果想要组件 A 给组件 C 传递数据,这种隔代的数据,该使用哪种方式呢?
如果是用props/$emit来一级一级的传递,确实可以完成,但是比较复杂;如果使用事件总线,在多人开发或者项目较大的时候,维护起来很麻烦;如果使用 Vuex,的确也可以,但是如果仅仅是传递数据,那可能就有点浪费了。
针对上述情况,Vue 引入了$attrs / $listeners,实现组件之间的跨代通信。
先来看一下inheritAttrs,它的默认值 true,继承所有的父组件属性除props之外的所有属性;inheritAttrs:false 只继承 class 属性 。
$attrs:继承所有的父组件属性(除了 prop 传递的属性、class 和 style ),一般用在子组件的子元素上$listeners:该属性是一个对象,里面包含了作用在这个组件上的所有监听器,可以配合v-on="$listeners"将所有的事件监听器指向这个组件的某个特定的子元素。(相当于子组件继承父组件的事件)
A 组件(APP.vue):
<template>
<div id="app">
//此处监听了两个事件,可以在B组件或者C组件中直接触发
<child1 :p-child1="child1" :p-child2="child2" @test1="onTest1" @test2="onTest2"></child1>
</div>
</template>
<script>
import Child1 from './Child1.vue';
export default {
components: { Child1 },
methods: {
onTest1() {
console.log('test1 running');
},
onTest2() {
console.log('test2 running');
}
}
};
</script>
B 组件(Child1.vue):
<template>
<div class="child-1">
<p>props: {{pChild1}}</p>
<p>$attrs: {{$attrs}}</p>
<child2 v-bind="$attrs" v-on="$listeners"></child2>
</div>
</template>
<script>
import Child2 from './Child2.vue';
export default {
props: ['pChild1'],
components: { Child2 },
inheritAttrs: false,
mounted() {
this.$emit('test1'); // 触发APP.vue中的test1方法
}
};
</script>
C 组件 (Child2.vue):
<template>
<div class="child-2">
<p>props: {{pChild2}}</p>
<p>$attrs: {{$attrs}}</p>
</div>
</template>
<script>
export default {
props: ['pChild2'],
inheritAttrs: false,
mounted() {
this.$emit('test2');// 触发APP.vue中的test2方法
}
};
</script>
在上述代码中:
- C 组件中能直接触发 test 的原因在于 B 组件调用 C 组件时 使用 v-on 绑定了
$listeners属性 - 在 B 组件中通过 v-bind 绑定
$attrs属性,C 组件可以直接获取到 A 组件中传递下来的 props(除了 B 组件中 props 声明的)
(6)总结
(1)父子组件间通信
- 子组件通过 props 属性来接受父组件的数据,然后父组件在子组件上注册监听事件,子组件通过 emit 触发事件来向父组件发送数据。
- 通过 ref 属性给子组件设置一个名字。父组件通过
parent 获得父组件,这样也可以实现通信。
- 使用 provide/inject,在父组件中通过 provide 提供变量,在子组件中通过 inject 来将变量注入到组件中。不论子组件有多深,只要调用了 inject 那么就可以注入 provide 中的数据。
(2)兄弟组件间通信
- 使用 eventBus 的方法,它的本质是通过创建一个空的 Vue 实例来作为消息传递的对象,通信的组件引入这个实例,通信的组件通过在这个实例上监听和触发事件,来实现消息的传递。
- 通过
refs 来获取到兄弟组件,也可以进行通信。
(3)任意组件之间
- 使用 eventBus ,其实就是创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。
状态管理库解决了什么问题呢,其好处是什么
如果业务逻辑复杂,很多组件之间需要同时处理一些公共的数据,这个时候采用传统组件通信的方法可能不利于项目的维护。这个时候可以使用 状态管理库 ,状态管理库 的思想就是将这一些公共的数据抽离出来,将它作为一个全局的变量来管理,然后其他组件就可以对这个公共数据进行读写操作,这样达到了解耦的目的
Pinia 和 Vuex 的区别是什么,为什么要在开发过程中选择替代呢
- Pinia 的模板编写更少
- Pinia 更适合 TS,可以自动推导类型,无需额外模板代码(在开发过程选择替代的原因)
- Pinia 使用组合式 API,更加贴合 Vue3 的编程范式
状态管理库的原理你知道是什么吗
Pinia 和 Vuex 的原理都没有去了解过,但是状态管理库都有一个通用的原理可以答,就是:订阅发布机制
什么意思呢,任何状态管理库都有两个核心:一个是 state,一个是 action。
比如在写一个最基础的计数器,用户在点击按钮的时候,会触发increment()事件(发布事件);然后 count 就被更新了(事件更新),所有依赖于 count 的组件也会自动感知变化并刷新(订阅者被通知)
那你知道订阅模式和观察者模式的区别吗
通常我们会这么回答:
- 在观察者模式中,观察者是知道 Subject 的,Subject 一直保持对观察者进行记录。然而,在发布订阅模式中,发布者和订阅者不知道对方的存在。它们只有通过消息代理进行通信。
- 在发布订阅模式中,组件是松散耦合的,正好和观察者模式相反。
- 观察者模式大多数时候是同步的,比如当事件触发,Subject 就会去调用观察者的方法。而发布-订阅模式大多数时候是异步的(使用消息队列)
但是这么回答显得干巴巴的,所以一般我们还会实际举一个例子来具体展示观察者模式和发布订阅模式到底不同在哪:
比如有一家报纸社每天发送报纸,有多个用户想订阅报纸。
- 观察者模式就是用户直接在报纸社等级姓名和地址,报纸社有一份用户列表(观察者列表),那么每当报纸出版的时候,报纸社都回去主动通知所有在名单上的用户,比如送上门或者打电话通知
- 发布订阅模式就是有一个类似于邮局的中间人,报纸社将报纸发给邮局,不关心是谁订阅了;用户也去邮局等级对哪份报纸感兴趣,到报社发布新报纸,邮局负责转发给所有订阅该报纸的用户
LocalStorage 和 SessionStorage 和 Cookie 的区别是什么呢
LocalStorage 和 SessionStorage 的不同
- 生命周期:
- sessionStorage**:**
- 存储的数据仅在当前会话期间有效。会话期间指的是浏览器窗口或标签页处于打开状态。
- 关闭窗口或标签页时,sessionStorage 中的数据将被清除。
- localStorage**:**
- 存储的数据在浏览器关闭后仍然有效,并且在同一个浏览器窗口或标签页重新打开时仍然可以访问。
- 数据只能通过 JavaScript 删除或由用户清除浏览器缓存来清除。
- 存储大小:
- sessionStorage**:**
- 存储容量较小,通常在 5MB 到 10MB 之间。
- 存储数据仅对当前会话有效,因此相对较小的容量通常足够使用。
- localStorage**:**
- 存储容量较大,通常在 5MB 到 10MB 之间。
- 存储数据会一直存在,除非用户清除浏览器缓存或通过 JavaScript 删除。
- 数据共享:
- sessionStorage**:**
- 存储在 sessionStorage 中的数据只能在同一窗口或标签页之间共享。
- localStorage**:**
- 存储在 localStorage 中的数据可以在同一浏览器的不同窗口或标签页之间共享。
- 使用场景:
- sessionStorage**:**
- 适用于需要在浏览器窗口或标签页之间传递数据,但数据在会话结束时不再需要的情况。
- localStorage**:**
- 适用于长期存储,即使用户关闭浏览器窗口或标签页,数据仍然需要保留的情况,例如用户首选项、本地缓存等。
Cookie 和 Storage 的不同
- 存储容量:Cookie 的存储容量较小,一般为 4kb 左右,而 localStorage 的存储容量通常比较大,一般为 5MB 或更多
- 与服务器通信:Cookie 在每次 HTTP 请求中都会被发送到服务器,因此用户在客户端和服务器之间传递数据。而 localStorage 则完全在客户端存储,不会自动发送到服务器
- 过期时间:Cookie 可以设置一个过期时间(通过 expires 属性或者 max-age 属性),使得数据在指定的时间后生效,除非手动删除或清楚浏览器缓存
hash 路由和 history 路由的区别是什么
- url 结构:Hash 是 URL 中以 # 符号开始的部分,例如 example.com/#section1。而 history 则是使用 HTML5 的 History API 来修改 URL 的路径,例如 example.com/section1。
- 对服务器的请求:Hash 部分的变化不会触发浏览器向服务器发送请求,因为 hash 部分的变化只会触发页面内的锚点跳转。而 history 的变化可能会触发浏览器向服务器发送请求,因为它可以修改 URL 的路径
- 浏览器历史记录:使用 history API 修改 URL 的路径时,浏览器会添加一条新的历史记录,因此用户可以通过浏览器的后退和前进按钮来导航页面。而修改 URL 的 hash 部分不会添加新的历史记录,只会修改当前的 URL
- 前端路由:基于 hash 的 URL 可以用于实现前端路由,因为 hash 的变化可以被浏览器检测到,并触发相应的路由处理逻辑,例如单页应用中的路由切换。而基于 history API 的 URL 可以更加自然地模拟传统的 URL 结构,但需要服务器端的支持
路由守卫是怎么封装的呢,全流程简单讲一下吧
- 第一步,需要在路由配置中添加权限相关信息;对于特定路由,需要表明可以访问此路由的角色
// ... existing code ...
const routes = [
{
path: "/",
name: "Home",
component: Home,
meta: { requiresAuth: false }, // 不需要权限的页面
},
{
path: "/login",
name: "Login",
component: Login,
meta: { requiresAuth: false }, // 不需要权限的页面
},
{
path: "/admin",
name: "Admin",
component: Admin,
meta: {
requiresAuth: true, // 需要权限
roles: ["admin"], // 需要admin角色才能访问
},
},
{
path: "/user",
name: "User",
component: User,
meta: {
requiresAuth: true, // 需要权限
roles: ["admin", "user"], // admin和user角色都可以访问
},
},
];
- 第二步,设置全局前置守卫:拦截路由跳转并进行权限判断;
to中的权限表的数据通常由后端返回,也叫做菜单表
// ... existing code ...
router.beforeEach((to, from, next) => {
// 判断该路由是否需要登录权限
if (to.meta.requiresAuth) {
// 获取用户信息,通常从Vuex或localStorage获取
const userInfo =
store.getters.userInfo || JSON.parse(localStorage.getItem("userInfo"));
// 如果用户已登录
if (userInfo && userInfo.token) {
// 判断用户角色是否有权限访问
if (to.meta.roles && to.meta.roles.length > 0) {
// 判断用户角色是否在允许的角色列表中
if (to.meta.roles.includes(userInfo.role)) {
next(); // 有权限,允许访问
} else {
next("/403"); // 无权限,跳转到403页面
}
} else {
next(); // 该页面没有设置角色限制,允许访问
}
} else {
// 未登录,跳转到登录页
next({
path: "/login",
query: { redirect: to.fullPath }, // 将要访问的路径作为参数,以便登录后重定向
});
}
} else {
// 不需要登录权限的页面,直接访问
next();
}
});
- 动态路由的实现:根据用户权限动态添加路由
import router from "./router";
import store from "./store";
import { getToken } from "@/utils/auth";
// 静态路由,所有用户都可以访问
const constantRoutes = [
{
path: "/login",
component: () => import("@/views/login/index"),
meta: { requiresAuth: false },
},
{
path: "/404",
component: () => import("@/views/error-page/404"),
meta: { requiresAuth: false },
},
];
// 动态路由,根据用户角色动态添加
const asyncRoutes = [
{
path: "/admin",
component: Layout,
meta: { roles: ["admin"] },
children: [
{
path: "dashboard",
component: () => import("@/views/dashboard/index"),
meta: { title: "仪表盘", roles: ["admin"] },
},
],
},
{
path: "/user",
component: Layout,
meta: { roles: ["admin", "user"] },
children: [
{
path: "profile",
component: () => import("@/views/profile/index"),
meta: { title: "个人信息", roles: ["admin", "user"] },
},
],
},
];
// 白名单,不需要重定向到登录页的路由
const whiteList = ["/login", "/auth-redirect"];
router.beforeEach(async (to, from, next) => {
// 获取token
const hasToken = getToken();
if (hasToken) {
if (to.path === "/login") {
// 已登录,重定向到首页
next({ path: "/" });
} else {
// 确定用户是否已获取角色信息
const hasRoles = store.getters.roles && store.getters.roles.length > 0;
if (hasRoles) {
next();
} else {
try {
// 获取用户信息
const { roles } = await store.dispatch("user/getInfo");
// 根据角色生成可访问的路由
const accessRoutes = await store.dispatch(
"permission/generateRoutes",
roles
);
// 动态添加可访问路由
router.addRoutes(accessRoutes);
// 确保addRoutes完成
next({ ...to, replace: true });
} catch (error) {
// 移除token并跳转到登录页
await store.dispatch("user/resetToken");
next(`/login?redirect=${to.path}`);
}
}
}
} else {
// 没有token
if (whiteList.indexOf(to.path) !== -1) {
// 在免登录白名单中,直接进入
next();
} else {
// 其他没有访问权限的页面将重定向到登录页面
next(`/login?redirect=${to.path}`);
}
}
});
怎么去动态注册路由呢
在这种情况下,后端在登录后需要返回用户的角色以及可访问的路由数据
如果使用的 Vuex:
- 首先需要封装一个专门的 Vuex 模块来管理权限和路由,这个模块包含了生成路由的方法
- 接下来在路由守卫中使用
router.addRoute添加根据权限生成的路由即可
简单讲一讲你是怎么控制用户与页面之间的权限关系的
两种方案:
- 如果后端只返回角色信息
这个问题也比较简单,在路由配置中,我们在 meta 信息中会配置两个字段,分别是:
- requiresAuth: boolean;表明此路由页面是否需要权限
- roles: string[]:表明拥有此页面权限的角色有哪些
然后根据登录后用户的角色就可以控制该用户对于哪些页面才有权限了
- 如果后端返回角色信息和角色对应的权限列表
动态路由,参考上面路由守卫的第三步
假如我需要将权限精确到 Button 级别,你应该怎么做呢
说一说权限管理的方案有哪些吧,基于角色(RBAC)和基于用户(UBAC)这两种方式有什么区别吗
权限分配方式:
- RBAC:基于角色,用户通过角色获得权限
- UBAC:直接为用户分配权限
管理复杂度:
- RBAC:便于集中管理和维护权限,特别是在用户量大的时候
- UBAC:更适合精细化的权限控制,但用户多时管理复杂
灵活性:
- RBAC:权限管理是通过角色实现,较为标准化,但不如 UBAC 灵活
- UBAC:可以精确到每个用户的权限,灵活度高
主题化是怎么做的,简单说一下
CSS 变量(核心) + 媒体查询 prefers-color-scheme 兜底 + window.matchMedi('prefers-color-scheme') 逻辑兜底
持久化保持设置是什么,怎么实现的
双 token 方案有什么好处吗,简单讲一下它的流程
关于 登录相关问题,可以详细看看我这篇文章:登录问题相关详解
作用:保证活跃用户能不过多地重复登录,且提升了非活跃用户的安全性
**流程:**双 token 指的是有两个 token 用来进行身份验证,分别为 access_token 和 refresh_token,正常访问接口时优先带上 access_token,当 access_token 过期后(401),再用 refresh_token 刷新 access_token
当 JWT 过期时,浏览器会发起一个新的请求来刷新 token。如果此时多个请求同时发起,那么每个请求都会触发一次 token 刷新,就会导致多次请求刷新的问题,你该怎么进行解决呢
解决措施:维护一个 task queue 和 isRefresh 的标识,如果处于正在刷新 token 的阶段,之后发出的多个请求保存在一个队列中,等 token 刷新完后再请求(避免多次刷新 token)
JWT 的原理是什么
JWT 的原理可以参考阮一峰的这篇文章:JWT 原理,需要核心掌握的就是 JWT 的结构以及 Base64Url 算法(后面会提到)
JWT 分为三个部分
- Header(头部):以 JSON 对象的形式描述 JWT 的元数据,包括签名的算法以及 token 的类型。最后,将上述的 JSON 通过 Base64Url 算法转成字符串
- Payload(负载):用来存放实际需要传递的数据,也通过 Base64Url 算法转为字符串
- Signature(签名):对前两部分的签名,防止数据被篡改
Base64Url 算法:
JWT 作为一个令牌(token),有些场合可能会放到 URL(比如 api.example.com/?token=xxx)。Base64 有三个字符+、/和=,在 URL 里面有特殊含义,所以要被替换掉:=被省略、+替换成-,/替换成_ 。这就是 Base64URL 算法
你还知道其他什么登录方式么,能不能说一下这些方式和 JWT 方案的区别
Session
Session 是在用户登录成功后,由服务器自动生成的唯一标识
使用过程
浏览器 ⇄ 服务器
---------- -------------------------
输入账号密码 验证成功 → 生成 Session
↓ ↓
发送 POST /login Set-Cookie: sessionid=xxx
↓ ↓
保存 Cookie 服务器内存保存 sessionid → userInfo
↓
后续请求自动带 Cookie
↓
服务器根据 sessionid 查找用户信息
也就是说,当浏览器接收到服务器返回的 sessionID 之后,会先将此信息存入 cookie,同时 cookie 记录此 sessionID 属于哪个域名;在后续请求的时候,cookie 信息会被自动发送给服务端,服务端也会从 cookie 中获取 sessionID,再根据 ID 寻找响应的 session 信息
适用场景
适合于同源 Web 应用,且无需跨域
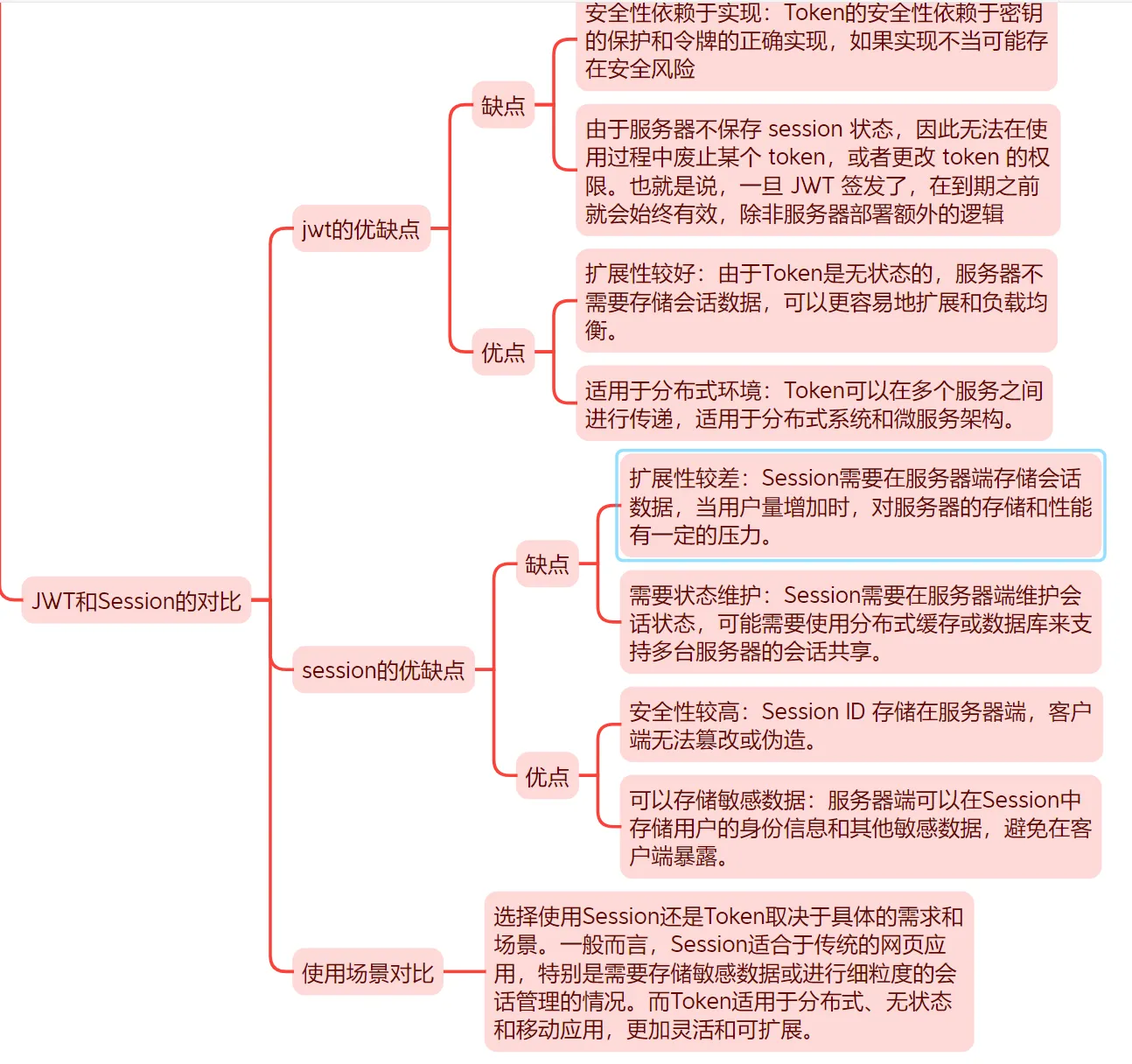
Session 和 Token 的区别
| 存储位置 | 存储在服务端(如内存或 Redis) | 存储在客户端(如 Cookie 或 LocalStorage) |
| 状态管理 | 有状态(需要服务器存储用户会话) | 无状态(不需要服务器存储用户信息) |
| 跨域支持 | 不支持跨域(需要特殊配置或共享存储) | 支持跨域(特别是 JWT) |
| 安全性 | 相对安全,易于控制(服务器存储) | 需要注意防止 XSS 攻击,存储需小心 |
怎么对大图片进行压缩的
还有其他什么对图片进行优化的方案吗,不仅限于上传的场景
具体可以参考这篇文章,这里先简单说一下:图片优化详解
图片压缩
图片压缩最好的办法是在上传的时候进行压缩,压缩后如果可以选择 webp 格式的图片就更好了
加载体验
- 图片尺寸
这是个比较常见的问题, 业务场景上展示可能只有 6060 的一个空间, 但是用的却是一个 10001000 以上分辨率的图片, 增加了网络消耗甚至某些设备对于过大的图片还会有性能问题。
- 图片格式
根据 Google 较早的测试,WebP 的无损压缩比网络上找到的 PNG 档少了 45%的文件大小,即使这些 PNG 档在使用 pngcrush 和 PNGOUT 处理过,WebP 还是可以减少 28%的文件大小。所以最好还是使用 webp 格式的图片
- 懒加载
对页面加载速度影响最大的就是图片,一张普通的图片可以达到几 M 的大小,而代码也许就只有几十 KB。对于图片过多的页面,为了加速页面加载速度,所以很多时候我们需要将页面内未出现在可视区域内的图片先不做加载, 等到滚动到可视区域后再去加载。这样子对于页面加载性能上会有很大的提升,也提高了用户体验。具体有两种实现方案:
* 一是可以在 img 标签上加上 lazy 属性,不过有些浏览器并不支持,需要做好降级处理
* 二是使用 js,当滚动到可视区域后再将对应的 img 标签加上 src 属性(参考上面的图片懒加载小节)
- 占位
比较简单了, 在图片加载完成之前要有一个灰色的背景。
- 渐进式加载
图片渐进式加载需要先展示一个模糊的图片, 让用户有个预期, 再等待完整的图片下载完成后替换成完整的图片, 对用户体验有很大的提升
可以参考:图片渐进加载优化
Webp 格式和 png、jpg 格式的区别是什么
这个就是纯八股的问题了,这里说几点比较核心的不同:
- 文件大小:
- WebP 文件通常比 JPG 小 25%-35%,比 PNG 小 26% 到 50%。
- 这意味着在不太影响质量的情况下,WebP 更省带宽和存储
- 浏览器支持:
- 老旧软件或者设备对于 Webp 的兼容性差一些
- jpg/png 几乎所有平台都没有问题
cdn 的原理是什么呢
也是一道较为常规的八股题目,为什么会问这个呢,因为图片一般都不放在本地,都是通过 cdn 进行分发。
可以先简单概括一下原理: CDN 的原理就是**把网站内容提前复制到离用户更近的服务器上,让访问更快、更稳定 **
CDN 是什么
CDN 是由遍布全球的边缘节点服务器组成的网络,主要作用是:
- 缓存网站的静态资源(如图片、JS、CSS、视频等)
- 智能调度,让用户就近访问这些资源
- 减轻原服务器的压力,提高网站的加载速度和可用性
CDN 相关知识
原理过程
用户访问页面(如 https://yourdomain.com/image.png)
↓
DNS 查询:CDN 解析你的域名
↓
智能调度:CDN 根据用户 IP、网络情况,选择最近的节点
↓
缓存命中?
→ 是:直接从 CDN 节点返回资源,速度快
→ 否:向源服务器请求内容,CDN 缓存后返回
下面有几个重点需要掌握:
- DNS 查询:解析域名
- 缓存机制:也就是上述所讲的缓存命中
- 负载均衡:CDN 需要进行智能调度从而来选择距离用户最近的节点
DNS 查询(解析)
服务器排序:根域名服务器——顶级域名服务器——权威域名服务器——本地域名服务器
DNS 查询主要分为两步,分别是获取 IP 与获取端口
- 获取 ip:
- 首先查看缓存里有没有,没有的话再检查本地 host 文件
- 然后将请求发给本地的服务器,然后在本地缓存表格中进行查找,查找到了直接返回 ip
- 本地域名向根域名服务器发起请求询问 IP,但是根域名不用于解析 url,而是指明一条道路,会将包含该后缀的根域名服务器的地址发给本地
- 再去询问顶级域名服务器,会返回执行权威域名的服务器地址
- 再去询问权威域名服务器,会将对应的 ip 地址发送给本地服务器
- 最后 DNS 将 ip 地址发送给客户端,客户端和目标建立连接
- 获取端口:等等待 TCP 队列——建立 tcp 连接——发送 http 请求——服务器解析 http 请求流程——重定向 location 字段——响应数据类型——tcp 断连
缓存机制
CDN 的关键功能之一是缓存。边缘节点会缓存静态资源(如图片、CSS 文件、JavaScript 文件等),以便更快地响应用户请求。当用户请求访问某个资源时,CDN 首先检查边缘节点中是否已经缓存了该资源。如果有缓存,边缘节点直接返回缓存的资源;如果没有缓存,边缘节点会从源服务器获取资源,并将其缓存起来,以便后续的请求
负载均衡
CDN 可以通过负载均衡技术来分配用户请求到最优的边缘节点。负载均衡算法可以根据节点的负载情况、地理位置和网络状况等因素,选择最佳的节点来处理用户请求,从而提供更好的性能和可靠性
你知道为什么可以实现预加载吗
浏览器一般在加载网页时会按需请求资源,比如说 CSS、JS、图片等。但是某些关键资源如果等到需要的时候才去请求,那么就会导致页面白屏、闪烁或者卡顿。而通过preload,我们可以告诉浏览器这个资源的优先级是很高的,可以让浏览器先去下载它,并保存到缓存当中
用法:
<link rel="preload" href="/style.css" as="style">
<link rel="preload" href="/script.js" as="script">
<link rel="preload" href="/font.woff2" as="font" type="font/woff2" crossorigin="anonymous">
在使用 preload之时,必须手动指定 as属性,否则资源可能不会被缓存或复用
大文件上传
如果将大文件一次性上传,会发生什么?想必都遇到过在一个大文件上传、转等操作时,由于要上传大量的数据,导致整个上传过程耗时漫长。而且如果这时候中断上传,后续又得重新进行上传,所有优化大文件上传,乃是业务开发中的一个重点,所以接下来我们将会探究一系列解决方案
切片上传
切片上传指的是将一个大文件,按照固定的切法划分为若干个小文件。首先我们需要了解,为什么需要切片上传?在实际使用场景下,ta 有如下几个好处:
- **避免大文件上传失败**:传统上传方式假如网络中断了,整个文件上传就失败了。而切片上传只需要上传失败的那一部分
- **支持多线程加速**:多个切片可以并行上传,提高速度
- **支持断点续传**:即使用户中断了,也可以从还未上传的部分继续上传
那接下来我们就来详细讲一讲切片上传的实现
怎么切
首先就是切片,这里我们使用 File 对象自带的 slice 方法进行切片:
// 将文件切片
const createFileChunks = (file: File, chunkSize = CHUNK_SIZE) => {
const chunks = [];
let cur = 0;
while (cur < file.size) {
chunks.push(file.slice(cur, cur + chunkSize));
cur += chunkSize;
}
return chunks;
};
但是文件的 slice 与数组的 slice 的差异还是挺大的。使用 File.prototype.slice 进行切片后,返回的是一个 blob 类型的数据,也就是说,这里 return 的 chunks,其类型是 blob[]。可能有很多同学只见过 Blob,但是对这个数据类型的具体含义却很陌生,所以这里详细讲一讲:Blob 是 Javascript 中用于表示不可变的原始二进制数据的对象,简单理解的话就是一段二进制数据的容器,里面可以存储任意内容,比如文本、图片、PDF、Word 文件等。
还可以扩展继续讲一讲,一般支持文件上传的系统,都会有一个支持文件下载的功能,那么这个功能是怎么实现的呢,没错,也是利用的 Blob。当我们点击下载按钮时,后端给我们返回的,就是一段 Blob 数据,然后我们就可以创建 Blob URL 再去创建 a 标签从而去触发浏览器快速下载 Blob
const url = URL.createObjectURL(blob);
const link = document.createElement("a");
link.href = url;
link.download = "test.txt";
link.click();
怎么传
在切完之后,我们就需要将文件依次上传了,代码如下,就是比较简单的上传过程,需要注意的是,在上传过程中需要上传索引,以便后端进行文件的合并:
// 上传切片
const uploadChunk = (chunk: Blob, index: number, fileName: string) => {
const formData = new FormData();
formData.append("chunk", chunk);
formData.append("index", index.toString());
formData.append("fileName", fileName);
return fetch("http://localhost:3000/upload", {
method: "POST",
body: formData,
}).then((response) => {
if (!response.ok) {
throw new Error(`切片 ${index} 上传失败`);
}
return response.json();
});
};
但是又有个问题噢,如果说是一个十分巨大的文件,切片之后统计到文件共有两百份,那么这时你会选择使用 promise.all(AllFile)进行上传吗,这会带来什么问题呢
- 首先,浏览器在 Http1.x 版本中,每个请求都需要一个独立的 TCP 连接,但是浏览器最多同时支持六个 TCP 连接,也就是说,最多同时并发六个请求。
那么,有同学可能又有疑惑——就算我使用 Promise.all 包裹所有的文件上传请求,但是浏览器不仍然同一时间只执行六个吗,这有什么关系呢,后续请求还是会排队进行请求呀。
是的,浏览器网络层确实会限制请求并发数,但是 JS 引擎并不会去进行限制。
举个简单的例子就是:比如你开了一个饭店(浏览器),门口一次只能让六个顾客进来(连接数),但是你让 1000 个人同时在门口排队登记填表抢椅子(创建请求对象、绑定事件、挂到事件循环),这时候哪怕饭店还没开始营业,但前厅就已经爆了。
也就是说,即使请求不会发出去,但这些 Promise 依然已经开始运行了,它们会去占用 JS 内存、异步调度队列以及 File/Blob 等资源,从而造成浏览器主线程或内存压力过大而崩溃
- 也是一个比较主要的原因,
Promise.all包裹之后,当某一个上传出错之后,会直接返回错误的结果,而不会去等其他文件上传的结果,容错太低
SO,这时候我们该怎么做呢?—— 使用并发池,也就是并发限制,我们会限制池子的最大上传数,当一个请求上传成功后,就会从池子外再扔一个请求到池子中,动态保持最大请求数的平衡。
talk is easy,show me code,并发池作为面试手撕经常被考到的一道题,还是很有必要看看是怎么实现的:
function promiseAllLimit(tasks, maxConcurrency = 5, maxRetry = 3) {
return new Promise((resolve, reject) => {
const results = [];
let index = 0; // 当前任务下标
let activeCount = 0; // 当前正在执行的任务数量
const retry = async (fn, retries) => {
try {
return await fn();
} catch (err) {
if (retries > 0) {
retry(fn, retries--);
} else {
throw err;
}
}
};
function next() {
if (index >= tasks.length && activeCount === 0) {
return resolve(results); // 所有任务完成
}
while (activeCount < maxConcurrency && index < tasks.length) {
const currentIndex = index;
const task = tasks[currentIndex];
index++;
activeCount++;
retry(task, maxRetry)
.then((res) => {
results[currentIndex] = res;
})
.catch((err) => {
results[currentIndex] = err; // 最终失败也保留数据
})
.finally(() => {
activeCount--;
next(); // 继续处理下一个任务
});
}
}
next(); // 启动执行
});
}
如上,我们就简单实现了一个 PromiseAllLimit 外加失败重试机制
传完之后呢
传完之后当然是通知后端可以开始合并了!!
// 通知服务器合并切片
const mergeChunks = (fileName: string, totalChunks: number) => {
return fetch("http://localhost:3000/merge", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
fileName,
totalChunks,
}),
}).then((response) => {
if (!response.ok) {
throw new Error("文件合并失败");
}
return response.json();
});
};
在上传完毕后通过后端可以进行合并啦!
但是,你真的确保文件完整地被传输过去了吗?如果在传输过程中 TCP 断开连接或者数据包丢失或者被人为篡改,即使后端返回一切正常,但是并不能确保文件数据被完整无误地传输了过去。那我们应该怎么做呢,还记得在 详谈 HTTPS 这篇文章我们怎么确保传输的内容不受篡改吗 —— 我们需要对每个文件切片做完整性校验,使用 md5 计算每个切片文件的哈希并传给后端,后端接受到哈希值和文件之后,也会对文件进行哈希,如果相等,则说明内容完整。
当然,如果你使用的 md5 且切片文件巨大,那么由于 md5 是同步对内容进行哈希处理,耗时时间长,又因为 JS 为单线程,所以就会引起程序阻塞。
那又该怎么处理呢,解决方法就是将 md5 的哈希计算放在 worker 线程中 —— 我们可以将一些耗时的同步操作放在 worker 线程中,以避免引起浏览器主线程的阻塞。同时将 worker 中的返回结果通过 PostMessage 传给主线程
断点续传
断点续传相对来说就简单很多了,只需要在重新上传时检查有哪些已经被上传过了文件切片就行啦:
// 检查已上传的切片
const checkUploadedChunks = async (fileName: string, fileHash: string) => {
try {
const response = await fetch(
`http://localhost:3000/check?fileName=${encodeURIComponent(
fileName
)}&fileHash=${fileHash}`,
{
method: "GET",
}
);
if (!response.ok) {
return [];
}
const data = await response.json();
return data.uploadedChunks || [];
} catch (error) {
console.error("检查已上传切片失败:", error);
return [];
}
};
然后跳过已上传的文件切片,从未上传的切片开始上传就好了
#前端##秋招##面试#
 查看18道真题和解析
查看18道真题和解析