
RAG:AI 落地的过渡方案,还是未来标配?
理想:RAG 的完美愿景
在大语言模型(LLM)的浪潮中,检索增强生成(Retrieval-Augmented Generation, RAG)被寄予厚望,作为 LLM 应用落地的关键技术范式之一,它的核心思想很简单:
“让大模型在生成答案时,先检索外部知识库,确保回答既准确又新鲜。”
理论上,RAG 能解决大语言模型(LLM)的三大痛点:
- 知识固化:LLM 依赖训练数据,无法自动更新知识(如 GPT-4 不知道 2024 年后的新闻),导致时效性差、专业领域知识不足,而 RAG 通过连接外部知识库,可以随时引入新信息。
- 幻觉问题:LLM 可能编造虚假信息,而 RAG 为回答提供证据、增强生成的可信度,能够减少“一本正经胡说八道”的情况。
- 实际应用成本较高:LLM 针对特定场景做训练或微调都需要充足的资源和专业的水平,而 RAG 仅需轻量级的检索系统即可扩展知识边界。
期望的应用场景:
| 智能客服 | 查询产品手册、政策文件、FAQ | 实时响应、减少人工成本、提升客户满意度 |
| 教育问答 | 解析教材内容、论文知识、习题解答 | 提供权威答案、辅助个性化学习 |
| 医疗咨询 | 查询医学文献、指南、药品说明、病例库 | 提高诊断参考准确性、避免幻觉、辅助医生决策 |
| 金融分析 | 集成财经新闻、市场数据、分析报告 | 生成时效性强的投资建议、动态风险提示 |
| 创作辅助 | 检索文学作品、创意素材、风格样例 | 启发写作思路、自动补全文案 |
| … |
在理想情况下,RAG 能让 AI 的回答既像专家一样专业,又像搜索引擎一样实时。
然而,现实中的 RAG 远远没有预想的那么完美。
现实:从“两步走”到复杂工程
RAG 的核心流程正如其名——检索增强生成,只有简单的两步:
- 检索(Retrieval):根据用户输入的 Query,从外部知识库(如向量数据库)召回相关文档。
- 生成(Generation):将检索到的文档与 Query 一起输入 LLM,生成最终回答。
由此演变出来的链路与架构却是千变万化——在实际应用中为提升最终回答效果,往往会在检索前后会加入各种辅助优化步骤,比如在检索前进行 Query 处理,检索后进行重排序和上下文压缩。
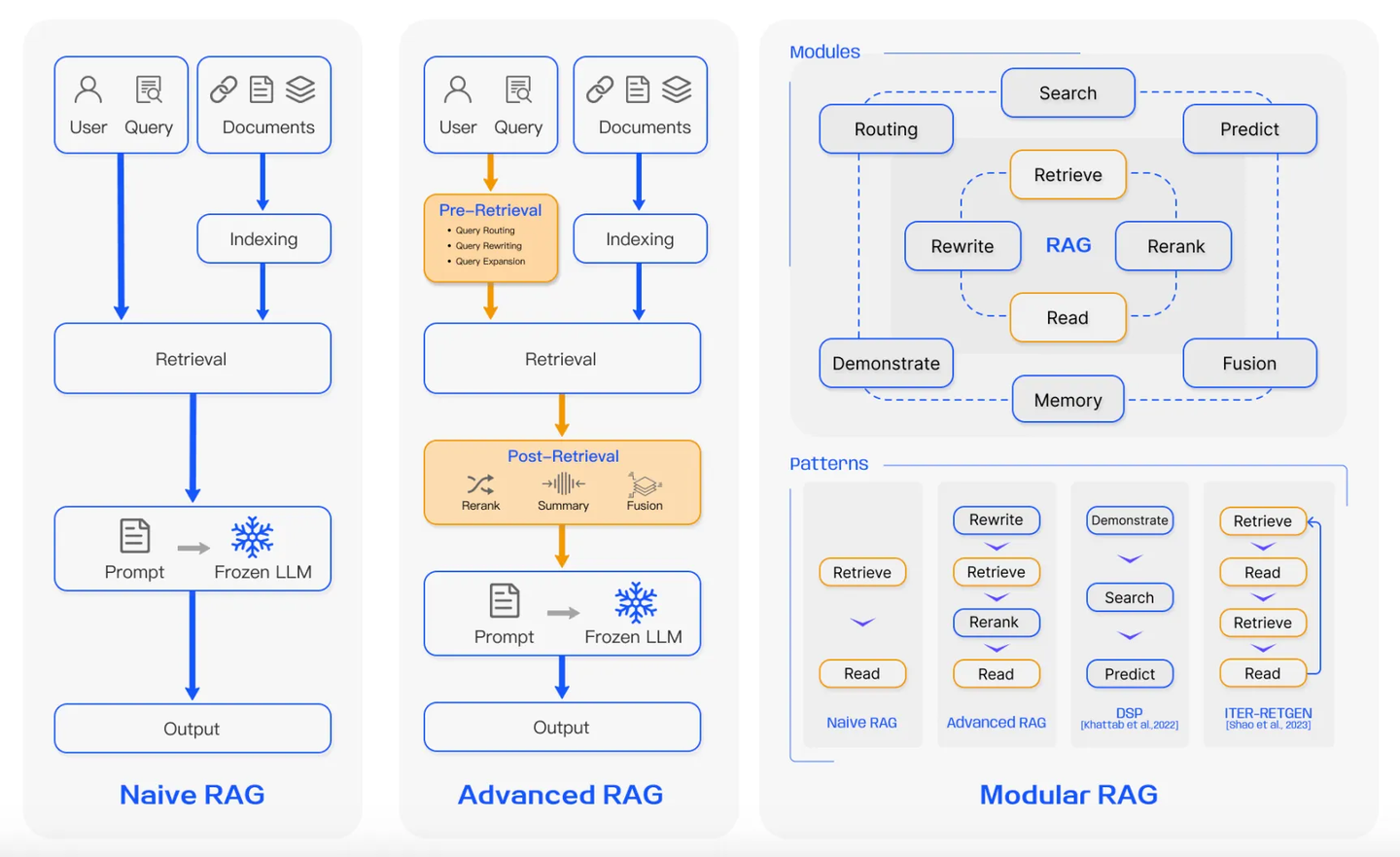
系统架构与产品形态
从架构上看,一个完整的 RAG 系统必定会划分为在线和离线两个部分:
为了能进行实时的在线检索,需要预先在离线状态下为知识(文档、图片等)构建索引。
离线是为在线服务的,在线需要什么样的能力,就要通过离线阶段完成准备工作。
可以将其类比为图书馆的管理工作,为了方便读者能在图书馆快速查阅到需要的资料,图书管理员会提前整理好书架,将书籍按照某种合理的顺序摆放。
在线是直接与用户进行交互的部分:想知道如何实现这部分,首先要思考产品形态应当是什么样的。
将 RAG 技术投入应用,可以构建出丰富多样的产品,而当下主流的 RAG 产品可以归纳为三类:
- 搜索为主:LLM 用于对搜索结果进行总结 → 基于原有的搜索技术,没有充分发挥 LLM 的能力
- 对话为主:用可靠知识作为辅助输入 LLM → 通过意图判断,在需要时使用检索能力,将外部知识作为 Prompt(LLM + PE),当下通用 RAG 范式
- Agent:LLM 充当大脑,知识库作为工具;用户输入最终目的,由 Agent 规划和执行 → 工程复杂度高,实用性和通用性有待提升,如 LangChain/LlamaIndex 中的 Agent 实现、OpenAI 的 DeepResearch
这三类产品形态代表了 RAG 技术应用从简单到复杂的演进方向,背后的工程实现也相应地从模块集成走向了更深度、更智能的系统整合。
检索的脉络:用工程思维走向最优
在 RAG 中,信息流动的路径可以简化为 4 个步骤:
Query → Doc → Prompt → Answer
事实上,RAG 知识库中存储的往往是经过切分后的文档片段(Chunk),而非完整文档,在此遵循信息检索领域的惯例,统一用文档(Doc)表示。
聚焦于检索阶段,即 Query → Doc,这一阶段的终极目标是寻求一个最优解——在知识库中找到”最能回答问题“的文档。
然而,在实际工程中,衡量“是否能回答问题”本身就是一项艰难的任务。因此,多数系统退而求其次,转而以相似度作为替代指标。
在传统搜索中,基于相似度进行召回,就是从海量候选集中找到与 Query 相似度最高的 Doc:
- 文本相似:全文关键词检索(BM25),适合短 Query(关键词明确)
- 语义相似:向量检索(Embedding-based Retrieval),适合长 Query / 复杂问题(向量嵌入更能捕捉深层语义)
- Query 改写:用于处理拼写错误、多义词、模糊表达等,扩大召回数量,提升鲁棒性
但使用上述方法,存在两种问题难以解决:
- 相似性 ≠ 相关性:高相似度的文档并不总能准确回答问题 → 无法根据直接根据与 Query 的相似度检索到需要的 Doc
- 知识缺位:知识库中缺乏可以直接问题的文档,在以下类型中尤为显著:
- 复杂总结类(e.g. “总结某人观点”)
- 多跳推理类(e.g. “A 与 B 导致 C 吗?”)
- 因果归纳类(e.g. “为什么会发生 X 现象?”)
(其他复杂场景还包括:多模态数据(如视频、图文混合)、严格约束下搜索(如 NL2SQL)等。)
为了克服传统搜索的局限,趋近最优解,业界逐步引入一系列优化策略:
- 意图识别(Intent Recognition):将 Query 分类,对不同情形采用对应策略处理,比如垂类搜索、识别时效/地域意图。
- 以旅游咨询为例,若用户询问 “近期北京有哪些好玩的景点”,系统可识别出 “近期” 这一时效意图和 “北京” 这一地域意图,精准筛选相关信息。
- 复杂 Ranking:在初步召回的大量候选文档中,利用深度语义理解模型(二阶段排序)进一步筛选,提高相关性判断精度。
- RAG:即使 Doc 不能直接回答问题,LLM 仍可基于其内容进行归纳总结,生成间接答案。
- Graph RAG:通过图结构建模知识间的关系,更好地支持多跳/推理型 Query。
- Agentic RAG:系统自动识别复杂 Query 的意图并拆分成多个子查询,逐一检索和回答,再通过反思、重搜与整合推理,解决复杂性与知识缺位问题的双重挑战。
检索在现实场景中的复杂性,决定了它难有通用解法。面对多样需求与动态环境,唯有以工程思维进行系统权衡与场景适配,尽可能精准地拟合最优解。
生成的挑战:LLM 的能力与边界
在 RAG 系统中,生成阶段的效果高度依赖于 LLM 的能力。
许多研究为 LLM 的能力提供了理论支撑:
- Scaling Law:LLM 的性能提升通常遵循“Scaling Law”,即模型的性能随着参数数量、训练数据量和计算资源的增加而提升,并呈幂律关系。
- 涌现:大模型在某些任务上会突然出现“小模型没有—大模型才有”的“跳变”能力,例如多步算术推理和逻辑组合。不过,也有研究指出,这种“涌现”可能是评测度量选择不当导致的错觉。
相比之下,传统自然语言处理(NLP)方法在效率和资源消耗方面具有优势,但在处理复杂任务时的泛化和推理能力方面已被全面超越。
通过实践也发现,提示工程(Prompt Engineering)是一条“逼近上限”的捷径。适当设计示例与指令,可显著改善特定任务效果:
- ICL(In-Context Learning):通过在上下文中提供示例,模型能够学习并泛化到类似任务。
- CoT(Chain-of-Thought):引导模型进行多步骤推理,提升复杂问题的解答能力。
- ReAct(Reasoning and Acting):结合推理与动作决策,使模型能够与外部环境互动,增强其实用性。
RAG 的原理正是通过将检索到的相关信息融入提示中,辅助 LLM 生成回答。
在理想状态下,如果 LLM 足够智能,只需提供充分的信息,它就能够自主筛选并生成答案,无需精细干预。
然而,现阶段的 LLM 尚未具备这种类人的认知能力,其“记忆”依赖于上下文(Prompt)形式输入,过长或杂乱的上下文不仅难以处理,还可能导致信息干扰与生成偏差。
因此,必须通过精准信息选取来辅助生成,这恰是搜索与推荐系统长期以来擅长解决的问题。如今,LLM 本身也可作为预筛工具参与这一过程。
本质上,这是一场围绕“信息选取粒度与模型生成能力”的工程权衡问题。
在提升 LLM 实用性方面,一个朴素的思路是:在与 LLM 交互之前,先调用当下主流搜索引擎进行检索,这种方式的优势在于:
- 复用现有能力:搜索引擎具备覆盖广泛、时效性强的网页索引能力,将其作为一种类似数据库的外部工具进行信息补充;
- 适用于通用知识查询:如事实性问题、新闻时事、公众观点等;
- 背后依赖爬虫抓取网页,由开放互联网支撑数据来源。
流程上,系统可调用搜索引擎获取相关链接,再抓取网页正文内容作为 LLM 输入。这种方式简单有效,但也存在一个重大的局限——内容供给限制。
许多核心信息并不会公开发布到互联网上,例如:
- 企业内部文档与知识库
- 医疗、金融等行业中的非公开数据
- 实时对话、用户个性化数据
这些数据根本无法通过传统搜索引擎获取,仅靠搜索引擎 + LLM 难以覆盖许多高价值场景。
这便是 RAG 系统存在的价值,提供一种更灵活的信息接入机制,包括:
- 外挂知识接入:可对接企业私有数据库、本地文档、FAQ、知识图谱等数据;
- 记忆系统支持:
- 支持构建长期用户记忆,如通过“聊天记录”唤起上下文;
- 弥补 LLM 无法动态更新知识的限制,实现“可控记忆更新”。
在此情形下,数据无疑是核心资产,如何更好地利用各类数据便是 RAG 系统构建的一大核心:
- 结构复杂的数据(如表格、图谱、多模态信息);
- 实时更新的数据流(如传感器输入、用户行为日志);
- 封闭环境中的数据资源(如企业 SaaS 平台、私有知识库);
最终,问题的关键在于构建数据供给与流动机制。
因此,在笔者看来,RAG 不只是技术框架,更是一种让数据更好流动、支持智能生成的中间层系统设计理念。
LLM 生成阶段还面临一些核心问题:
- 算力成本 → 随着技术的进步,算力越来越强,推理成本逐步下降,Token 会越来越便宜
- 耗时问题 → 迭代、反思、深度思考,都属于用时间换效果,在耗时不重要的情形,每一步都可以引入大/小 LLM 进行处理
- 概率模型 → 无法达到规则系统的严格性?LLM 回答依赖采样,效果不稳定,出错概率不低
- 幻觉存在 → 自由发挥、强行编造难以完全避免?模型会越来越聪明,对指令的遵循能力提高,可以缓解幻觉
- 知识局限 → LLM 难以回答出对特定行业领域的深入理解,因为此类数据见得少,回答的往往还是平均水平;主要靠用户引导激发,模型自主推理天花板高,但也可能跑偏(如 DeepSeek R1 幻觉现象明显)
- 数据依赖 → 垃圾进,垃圾出(Garbage in, garbage out):LLM 的输出质量高度依赖于输入数据的质量。若知识库中存在过时、错误或不完整的信息,或者检索返回的文档与问题不匹配、包含大量无关内容,都将影响输出结果
当下,尽管基础模型的能力不断提升,但距离“通用智能”仍有不小的差距。
对于应用层而言,能做的主要是借助工程手段来弥补模型不足,最终构建出一个真正实用的系统。
未来:RAG 是过渡技术,还是智能时代的标配?
RAG 系统的演进,将依赖于整个技术链条的协同优化:
信息检索的精准度与效率
- Embedding 技术: 如何生成更准确、更具语义区分度的向量表示,是提升检索相关性的基础。
- 向量检索与排序: 如何在海量数据中快速找到最相关的 K 个文档片段,并进行有效排序,直接影响最终生成质量。这涉及到索引构建、检索算法(如 HNSW)和重排(Re-ranking)模型的优化。
- 知识图谱融合: 结合结构化的知识图谱,可以为 RAG 提供更精确的关系信息和实体链接,提升对复杂问题的理解能力。
- 多模态信息处理: 随着信息形式的多样化,RAG 需要具备处理和检索图像、音频、视频等多模态信息的能力。
LLM 的整合与增强
- 训练与微调: 如何通过微调使 LLM 更好地理解检索到的上下文,并将其有效融入生成过程,减少生硬拼接感。
- 推理优化: 在结合检索信息后,如何保持 LLM 高效的推理速度,满足实时交互需求。
- 强化学习(RLHF/RLAIF): 利用反馈来优化 RAG 系统的检索策略和生成效果,使其更符合用户意图和偏好。
工程实现的复杂性与成本
- 大数据处理: 高效处理海量、异构、实时更新的知识源(包括实时流式数据)是 RAG 系统稳定运行的基础。
- 文档解析与分片: 如何智能地将原始文档切割成最优大小和内容的片段,以适应 Embedding 和检索的需求,是一大工程难点。
- 知识库维护与更新: 持续维护和更新知识库,确保信息的时效性和准确性,涉及复杂的工程流程和显著的维护成本。
目前的 RAG 技术处于“能用但不完美”的阶段,它既不是银弹,也不会很快被淘汰,而是会随着 LLM 和检索技术的进步持续演进。
- 短期内,RAG 仍是 LLM 落地的主流方案,尤其在专业领域(如医疗、金融、法律)具备不可替代性。
- 长期看,RAG 的最终命运与 LLM 自身能力的发展紧密相连。
- 一种可能是: 如果未来 LLM (或其他智能模型)能够发展出高效、低成本的内生动态知识更新机制,并且能够在大规模参数中有效存储和调用近乎无限的知识,那么对外部检索的依赖可能会显著降低。届时,RAG 可能会演变成一种针对特定场景(如私有数据访问、强制事实核查)的辅助技术,甚至像曾经的专家系统一样,其核心思想被更先进的模型架构所吸收。
- 另一种可能是: 外部世界的知识是无限且动态变化的,完全依赖模型内部更新可能永远存在成本、效率和时效性的瓶颈。在这种情况下,RAG(或其演化形态)将作为智能体连接现实世界信息流的标准接口,成为智能系统不可分割的一部分,是实现通用人工智能的“标配”组件。
RAG 的理想固然美好,希望让 LLM 成为“知识无界”的智能体,但现实中的挑战在于,其能否持续支撑智能系统走向更广泛、更复杂的真实场景。
对于从业者而言,理解 RAG 的算法本质与工程权衡(trade-off),比盲目追求“终极方案”更为重要。
#牛客创作赏金赛##聊聊我眼中的AI#
 查看8道真题和解析
查看8道真题和解析