
AI-Compass 强化学习模块:理论到实战完整RL技术生态,涵盖10+主流框架、多智能体算法
AI-Compass 强化学习模块:理论到实战完整RL技术生态,涵盖10+主流框架、多智能体算法、游戏AI与金融量化应用
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
强化学习模块构建了从理论学习到项目实战的完整RL技术生态,为强化学习研究者和工程师提供系统化的智能决策解决方案。该模块系统性地整理了蘑菇书、深度强化学习原理与实践等经典理论教材,以及Google Dopamine、Facebook ReAgent、Ray、DI-ENGINE、ElegantRL、MARL库、SLM Lab、Spinning Up in Deep RL、Stable Baselines3、Tianshou等10+个主流强化学习框架和工具库。技术栈涵盖了Unity ML-Agents强化学习环境、Gymnasium案例合集等实验平台,深入介绍了Rainbow、SAC、TD3、DDPG、A2C、PPO等单智能体算法,以及MADDPG、QMIX等多智能体算法的实现原理和应用场景。
模块详细解析了价值函数逼近、策略梯度方法、深度强化学习、多智能体协作等核心技术,以及探索与利用平衡、样本效率优化、训练稳定性等关键技术挑战的解决方案。内容包括环境建模、奖励设计、网络架构、超参数调优等完整的RL开发流程,以及分布式训练、模型部署、性能评估等工程化实践技术。此外,还提供了斗地主AI、王者荣耀AI、股票量化交易、五子棋AI、扑克AI等丰富的项目案例,涵盖游戏AI、金融量化、策略博弈等多个应用领域,帮助开发者掌握从算法研究到产业应用的完整强化学习技术栈,实现复杂决策问题的智能化解决方案。
强化学习库推荐

- 强化学习库合集
- google/dopamine: Dopamine is a research framework for fast prototyping of reinforcement learning algorithms.
- facebookresearch/ReAgent: A platform for Reasoning systems (Reinforcement Learning, Contextual Bandits, etc.)
- alex-petrenko/sample-factory: High throughput synchronous and asynchronous reinforcement learning
- astooke/rlpyt: Reinforcement Learning in PyTorch
- tensorlayer/TensorLayer: Deep Learning and Reinforcement Learning Library for Scientists and Engineers
- pfnet/pfrl: PFRL: a PyTorch-based deep reinforcement learning library
- rail-berkeley/rlkit: Collection of reinforcement learning algorithms
0.Pearl
简介
Pearl是Meta(原Facebook Research)开源的一个生产就绪的强化学习(RL)AI代理库,旨在帮助研究人员和开发者构建强化学习AI代理。它专注于长期累积反馈而非短期反馈,并能适应数据有限的环境,强调其在实际生产环境中的可用性和高效性。
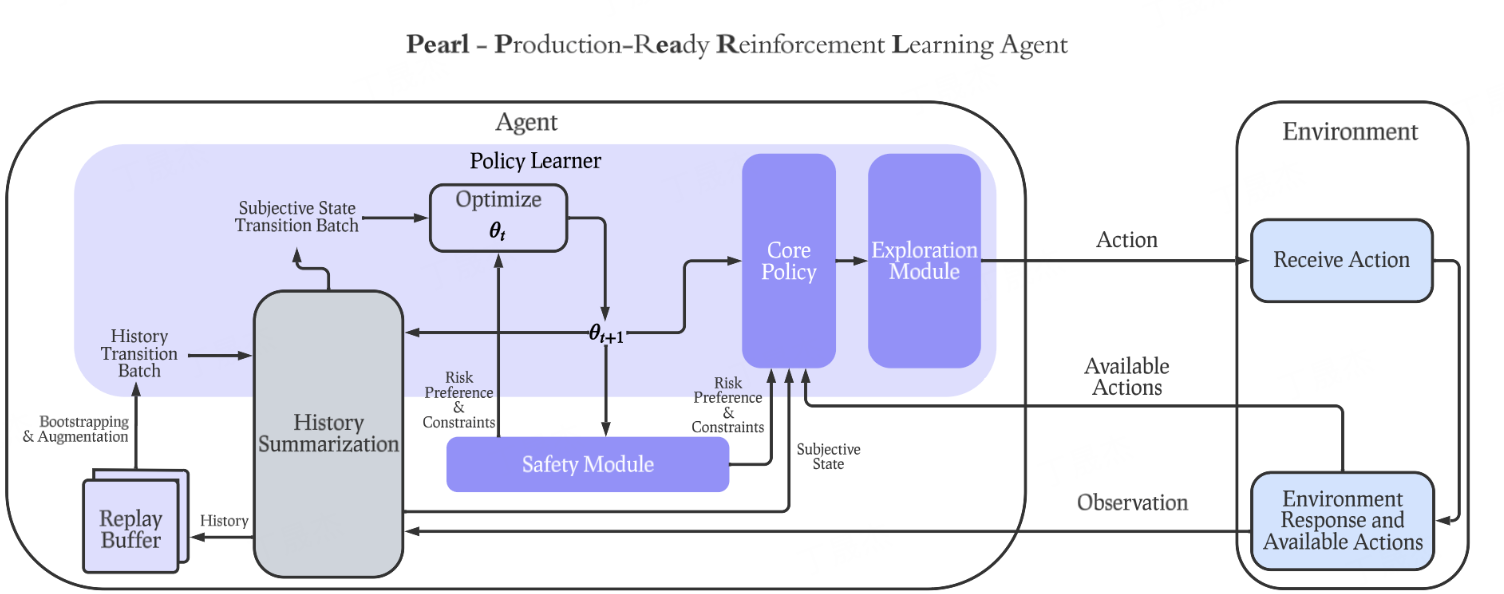
核心功能
- 强化学习AI代理开发与部署: 提供构建和在生产环境中部署强化学习AI代理的能力。
- 生产环境适用性: 设计用于应对实际生产挑战,具备高稳定性、模块化和可扩展性。
- 长期反馈优化: 代理能够优先考虑长期累积奖励,以实现更全局和最优的决策。
- 有限数据环境适应: 能够在数据稀疏或不充分的环境中有效学习和适应。
技术原理
Pearl的核心技术原理在于构建能通过与环境持续交互来自主学习最优行为策略的智能体。这涉及:
- 马尔可夫决策过程(MDP)建模: 将现实问题抽象为MDP,定义状态、动作、奖励和转移概率。
- 深度强化学习算法: 可能包含Q-learning、SARSA、Actor-Critic、PPO、DQN等多种先进的深度强化学习算法实现,通过神经网络逼近值函数或策略函数。
- 离策略与在策略学习: 支持智能体从旧数据或探索行为中学习,以及从当前策略的交互中学习。
- 模块化与可插拔架构: 采用高度模块化的设计,允许研究人员和工程师轻松插入自定义组件,如不同的神经网络架构、优化器、经验回放机制等。
- 高效的数据管道与并行计算: 为满足生产环境的高吞吐量和低延迟需求,可能包含优化的数据处理流程、分布式训练和推理能力。
- 基准测试与性能优化: 提供基准测试工具和优化实践,以确保代理在真实世界场景中的性能和鲁棒性。
应用场景
- 广告投放与个性化推荐: 优化广告展示策略和商品推荐,以最大化用户长期价值和平台收益。
- 金融科技: 开发智能交易系统、风险管理策略和个性化金融产品推荐。
- 资源管理与调度: 在云计算、通信网络或物流系统中优化资源分配和任务调度。
- 工业自动化与控制: 实现智能制造、机器人控制和工业过程优化。
- 自动驾驶与机器人: 在复杂动态环境中进行决策规划和行为控制。
- 内容创作与个性化内容分发: 优化内容推荐算法,提升用户参与度和满意度。
0.RAY
简介
Ray 是一个开源的统一框架,旨在简化大规模人工智能(AI)和 Python 应用的开发与部署。它提供了一个计算层,用于处理并行计算,使开发者无需成为分布式系统专家,即可将应用从单机扩展到集群。Ray 通过抽象复杂的分布式计算细节,帮助用户高效地构建和运行分布式机器学习工作流。
核心功能
- 分布式扩展: 提供简单、通用的API,支持将Python和AI应用从笔记本电脑扩展到大型集群。
- 简化并行编程: 引入任务(Tasks)和Actor等可扩展的计算原语,实现无痛的并行编程。
- AI库生态: 包含一系列专门为加速机器学习工作负载设计的AI库,例如用于强化学习的RLlib。
- 统一框架: 将分布式运行时与AI库集成,提供端到端的机器学习工作流支持。
技术原理
Ray 的核心是一个分布式运行时(Distributed Runtime),它管理着集群中的计算资源和任务调度。其主要技术原理包括:
- 任务(Tasks): 允许用户将Python函数转换为异步执行的远程任务,由Ray自动分配到集群中的工作节点并行执行。
- Actor: 提供了一种创建有状态的分布式对象的方式,Actor实例可以在集群中的不同节点上运行,并通过方法调用进行通信。这使得复杂的分布式状态管理和并发编程变得更加容易。
- 对象存储: 内部使用了一个分布式对象存储系统,高效地在任务和Actor之间传输大型数据对象,避免不必要的数据序列化和反序列化开销。
- 调度器: 智能调度器负责将任务和Actor放置到最佳的计算资源上,并处理容错机制。
- 统一API: 通过提供一套统一且易于使用的Python API,抽象了底层分布式系统的复杂性,降低了开发门槛。
应用场景
- 大规模机器学习: 用于训练大型深度学习模型、进行超参数调优、运行强化学习实验等。
- 数据处理和ETL: 处理大规模数据集的并行计算和数据转换。
- 分布式Python应用: 任何需要将Python代码并行化并在多核或多节点上运行的场景。
- 模型服务和部署: 构建可扩展的机器学习模型推理服务。
- 模拟和优化: 运行大规模的并行模拟或优化算法。
- RAY入门指南 — Ray 2.1.0
- Ray is a unified framework for scaling AI and Python applications. Ray consists of a core distributed runtime and a toolkit of libraries (Ray AIR) for accelerating ML workloads.
DI-ENGINE
简介
DI-engine(Decision Intelligence Engine)是一个通用的决策智能引擎,专为PyTorch和JAX设计。它由OpenDILab开发,旨在通过结合数据科学、社会科学、决策理论和管理科学的理论,促进决策智能(Decision Intelligence)领域的发展。DI-engine提供了Python优先和异步原生的任务与中间件抽象,并模块化地集成了环境(Env)、策略(Policy)和模型(Model)等核心决策概念。
核心功能
DI-engine的核心功能包括:
- 通用决策智能引擎: 提供一个统一的框架,支持在多种决策智能任务中进行开发和研究。
- PyTorch和JAX兼容: 支持两种主流的深度学习框架,为用户提供灵活性。
- 异步原生任务与中间件抽象: 实现高效的异步操作和灵活的中间件集成。
- 模块化组件集成: 有机地整合环境(Env)、策略(Policy)和模型(Model)等关键决策概念。
- 强化学习支持: 作为OpenDILab的重要组成部分,支持深度强化学习(Deep Reinforcement Learning)相关的研究和应用。
- 文档与教程: 提供详细的中文和英文文档、教程以及用户指南,便于学习和使用。
技术原理
DI-engine的技术原理主要基于以下几个方面:
- 深度学习框架集成: 建立在PyTorch和JAX之上,利用这些框架的张量计算能力和自动微分机制,实现高效的模型训练和推理。
- 模块化设计: 采用高度模块化的架构,将决策过程分解为环境(Environment)、策略(Policy)和模型(Model)等独立且可插拔的组件,便于组合和扩展。
- 异步编程范式: 采用异步原生的设计,可能利用
asyncio或其他异步库,以提高系统吞吐量和资源利用率,特别是在处理复杂的环境交互时。 - 决策智能(Decision Intelligence)理念: 将决策智能作为核心指导思想,通过算法、数据和人类知识的结合,优化决策过程。这可能涉及强化学习、决策树、行为建模等多种AI技术。
- TreeTensor库支持: 可能利用其内部或关联的TreeTensor库,以高效处理树状结构的数据或模型,特别是在某些分层或基于树的决策算法中。
应用场景
DI-engine可广泛应用于多种决策智能和强化学习相关的场景,包括但不限于:
- 游戏AI开发: 用于训练玩各种游戏的AI代理,如在复杂策略游戏(如星际争霸II)中进行决策。
- 自动驾驶系统: 在自动驾驶平台中进行决策优化,如路径规划、环境感知和行为控制。
- 智能交通管理: 如交通路口信号控制的决策智能平台,优化交通流量。
- 机器人控制: 训练机器人进行复杂的动作和决策,以完成特定任务。
- 工业自动化: 在工业流程中实现自动化决策和优化生产效率。
- 金融领域决策: 用于量化交易、风险管理等方面的智能决策支持。
- 多智能体系统: 协同多个AI代理在复杂环境中进行合作或竞争。
- 科研与教育: 作为研究和学习决策智能与强化学习的通用平台。
- 欢迎来到 DI-engine 中文文档 — DI-engine 0.1.0 文档
- DI-engine-docs/index.rst at main · opendilab/DI-engine-docs
- opendilab/DI-engine: OpenDILab Decision AI Engine
ElegantRL “小雅”
简介
ElegantRL是一个基于PyTorch实现的开源深度强化学习(DRL)库,旨在提供一个轻量级、高效且稳定的下一代DRL框架。它通过整合大规模并行模拟、集成方法和基于种群的训练等前沿技术,致力于推动DRL领域的研究与应用,并具备强大的可扩展性。
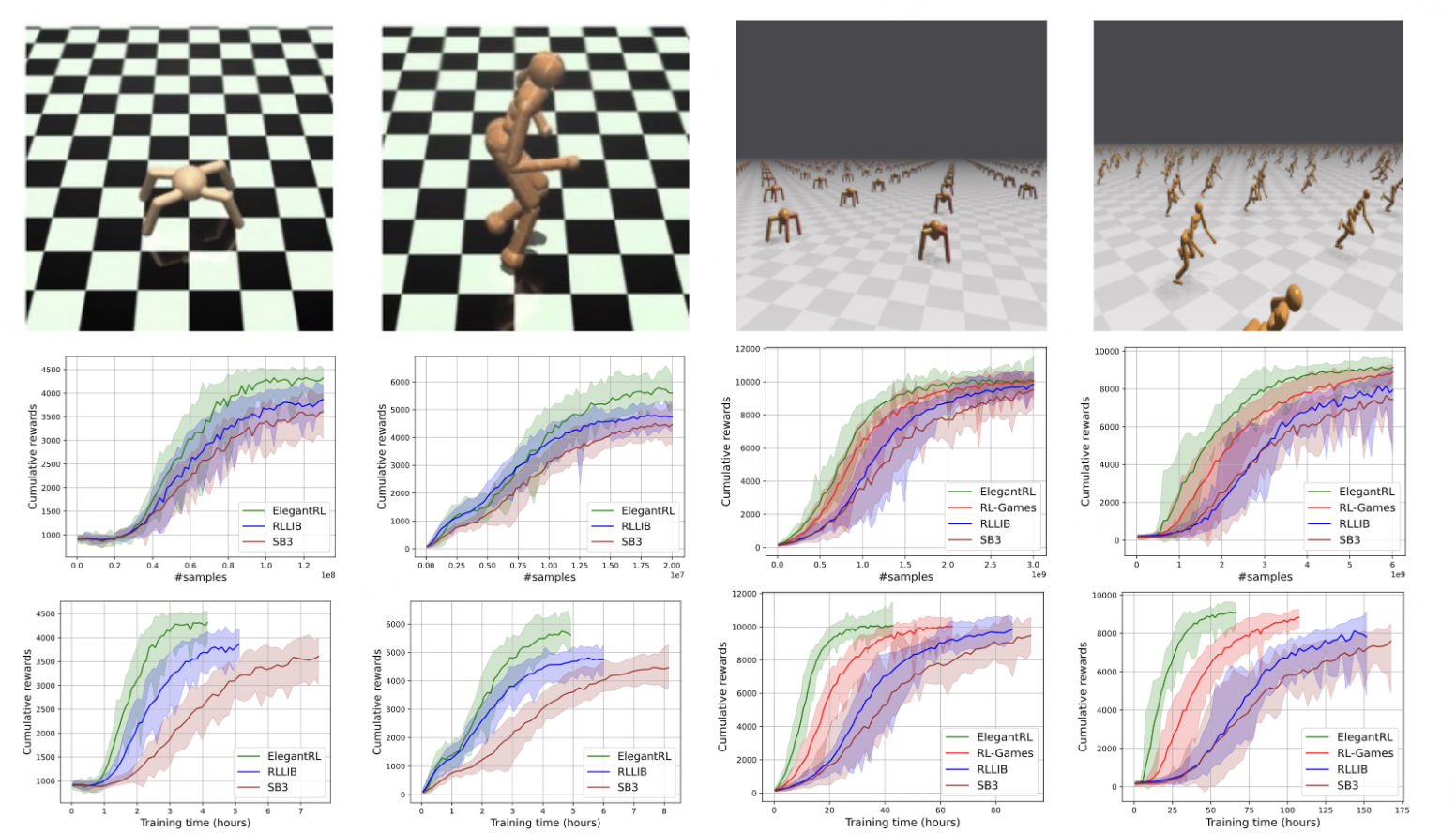
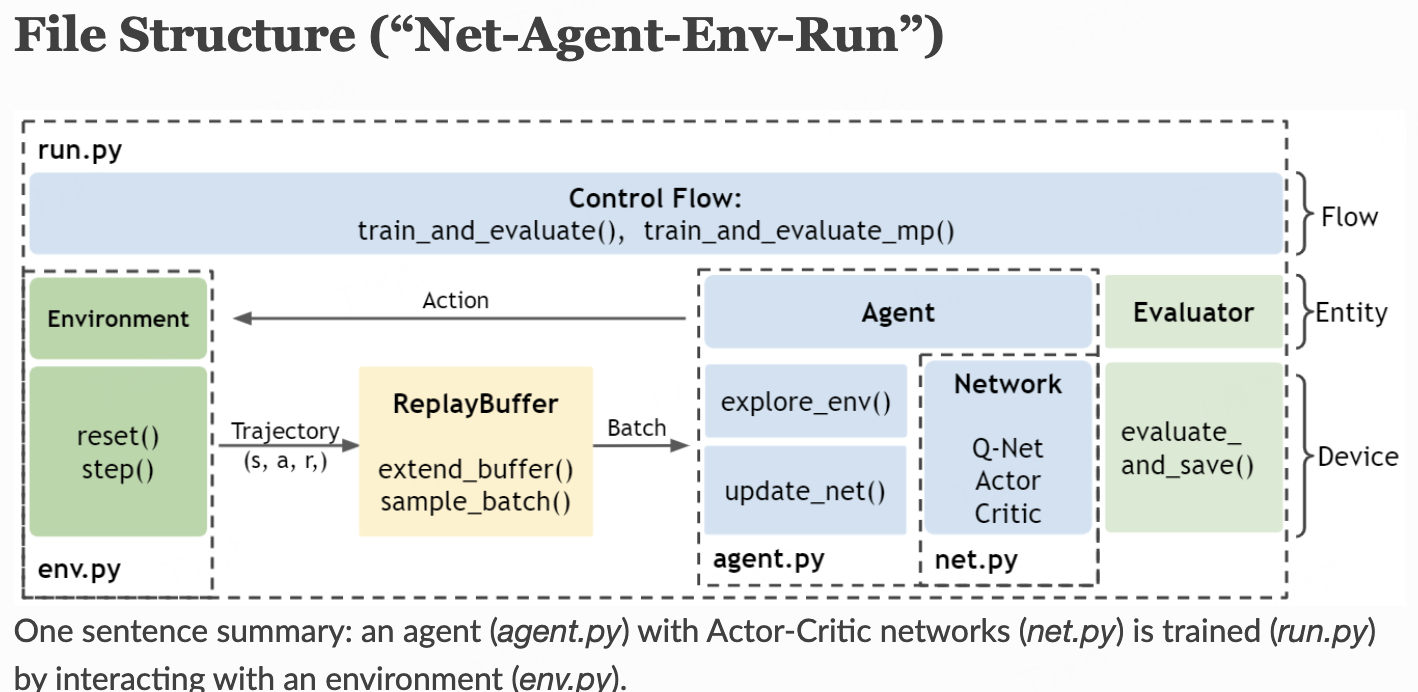
核心功能
- 大规模并行训练:支持对DRL算法进行高效、大规模的并行模拟与训练。
- 多种DRL算法实现:集成了多种经典的深度强化学习算法。
- 模块化框架:提供清晰的“网络-智能体-环境-运行”文件结构(Net-Agent-Env-Run),方便用户理解和构建DRL实验。
- 前沿技术融合:利用集成方法(Ensemble Methods)和基于种群的训练(Population-Based Training, PBT)等技术来优化训练过程和性能。
- 易于上手:通过“Hello World”等教程,帮助用户快速理解并实践DRL。
技术原理
ElegantRL的核心技术原理建立在现代深度强化学习范式之上,并着重于效率和可扩展性:
- 深度强化学习(DRL):结合深度神经网络的强大表示能力与强化学习的决策优化框架。
- PyTorch实现:利用PyTorch的动态计算图和GPU加速能力,实现灵活的模型构建和高效的训练。
- 大规模并行化:通过多进程或多线程机制实现环境模拟与智能体训练的并行化,显著加速数据收集和学习过程。
- Actor-Critic架构:常用的DRL算法,通过独立的策略网络(Actor)和价值网络(Critic)协同学习最优行为策略。
- 基于种群的训练(PBT):一种超参数优化和模型训练技术,通过同时训练多个智能体,并根据性能动态调整超参数或共享模型权重,以发现更好的解决方案。
- 环境-智能体交互机制:遵循标准的强化学习循环,智能体在环境中执行动作、接收观测和奖励,并通过这些反馈来更新策略。
应用场景
- 学术研究与实验:为深度强化学习算法的开发、测试和性能评估提供高效的平台。
- 金融科技:AI4Finance Foundation背景,表明其在金融领域的潜在应用,如量化交易策略、资产配置、风险管理等。
- 大规模仿真与决策优化:适用于需要大量交互和并行计算才能解决的复杂决策问题,例如供应链优化、资源调度。
- 教育与初学者入门:提供易于理解的模块化代码和教程,帮助初学者快速掌握深度强化学习。
- 机器人控制与自动化:在模拟环境中训练智能体,以学习复杂的机器人操作或自动化任务。
MARL库推荐
简介
主要介绍了多智能体强化学习(Multi-Agent Reinforcement Learning, MARL)领域的多个前沿算法和开源实现,包括针对异构智能体的强化学习算法HARL、基于Transformer架构的多智能体学习模型MAT,以及流行的多智能体PPO变体MAPPO。这些项目旨在解决复杂多智能体环境中的协作与学习问题。
核心功能
- HARL系列算法: 实现了一系列针对异构智能体的强化学习算法(如HAPPO, HATRPO等),能够在不依赖参数共享的前提下,有效实现多智能体协作,并显著提升性能。
- Multi-Agent Transformer (MAT): 将合作型MARL问题转化为序列建模问题,通过Transformer模型实现多智能体学习,提供优秀的性能和泛化能力。
- MAPPO: 作为PPO算法的多智能体变体,在合作型多智能体游戏中表现出卓越的有效性,并提供在多种环境下的实现。
技术原理
- HARL: 采用异构智能体强化学习(Heterogeneous-Agent Reinforcement Learning)范式,通过理论支持实现针对不同智能体的独立策略学习,避免了传统参数共享的限制。基于PyTorch实现,并引入了序列更新机制。
- Multi-Agent Transformer (MAT): 核心是基于Encoder-Decoder架构的Transformer网络。它将多智能体学习过程视为序列建模,并利用多智能体优势分解定理(Multi-Agent Advantage Decomposition Theorem)来确保线性时间复杂度和性能的单调提升。
- MAPPO: 是一种基于策略梯度方法的On-Policy算法,作为近端策略优化(Proximal Policy Optimization, PPO)在多智能体环境中的扩展,通过共享经验或集中式训练分布式执行的方式进行优化。
应用场景
- 复杂多智能体协作环境: 适用于需要多个智能体协同完成任务的场景。
- 异构智能体系统: 特别适用于智能体具有不同能力、目标或状态表示的复杂系统。
- 合作型博弈: 在星际争霸II(StarCraftII)、多智能体MuJoCo、灵巧手操作(Dexterous Hands Manipulation)以及谷歌研究足球(Google Research Football)等基准测试环境中表现优异。
- 大规模多智能体问题: MAT的序列建模和高效复杂度特性使其适用于大型合作MARL问题。
- PKU-MARL/HARL: Official implementation of HARL algorithms based on PyTorch.
- PKU-MARL/Model-Based-MARL
- PKU-MARL/Multi-Agent-Transformer
- zoeyuchao/mappo: This is the official implementation of Multi-Agent PPO.
- 多智能体强化学习应该如何学习?包括框架选择,代码修改等? - 知乎
SLM Lab
简介
SLM Lab是一个基于PyTorch的模块化深度强化学习(RL)框架。它旨在为可复现的RL研究提供一个软件平台,通过模块化组件和基于文件的配置,简化RL算法的开发、实验、超参数搜索、结果分析和基准测试。它也是《深度强化学习基础》一书的配套库。
核心功能
- 模块化算法开发: 实现了大多数主流的RL算法,并允许研究人员通过模块化方式方便地构建和修改算法。
- 可复现性研究: 强调代码的可复现性,确保不同算法间的性能比较更具说服力,避免因实现差异导致的结果混淆。
- 灵活的实验配置: 支持通过配置文件进行灵活的实验设置和超参数管理。
- 结果分析与基准测试: 提供工具和结构,便于对实验结果进行分析并进行算法性能的基准测试。
技术原理
SLM Lab的核心技术原理在于其模块化设计和对PyTorch深度学习框架的依赖。
- 模块化架构: 将强化学习算法的不同组成部分(如代理、环境、内存、网络、优化器等)分解为独立的、可互换的模块。这种设计使得研究人员可以轻松地组合、修改或替换特定组件,而无需重写整个算法,从而极大地提高了开发效率和实验的灵活性。
- PyTorch后端: 利用PyTorch的动态计算图特性,为深度学习模型(如策略网络和价值网络)的实现提供了强大的支持,便于快速原型开发和调试。
- 统一接口: 通过定义清晰的接口,确保不同模块之间能够无缝协作,即使算法存在细微差异,也能在统一的框架下进行比较,从而提升了研究的严谨性。
- 文件配置系统: 采用基于文件的配置来管理实验参数和模型结构,实现了实验设置的便捷化和可追溯性。
应用场景
- 深度强化学习研究: 作为研究人员开发、测试和比较不同RL算法的平台。
- 算法原型验证: 快速实现和验证新的RL算法或算法变体。
- 教育与学习: 作为《深度强化学习基础》等教材的配套工具,辅助学生理解和实践RL概念。
- 性能基准测试: 对不同RL算法在特定任务上的性能进行标准化评估和对比。
- 复现现有成果: 帮助研究人员复现和验证已发表的RL研究成果。
- SLM Lab - SLM Lab
- kengz/SLM-Lab: Modular Deep Reinforcement Learning framework in PyTorch. Companion library of the book "Foundations of Deep Reinforcement Learning".
Spinning Up in Deep RL
简介
OpenAI Spinning Up in Deep RL 是由 OpenAI 发布的一套深度强化学习(Deep Reinforcement Learning, RL)教育资源。它旨在帮助广大学习者和研究人员掌握深度强化学习的核心概念、算法和实践技能,从而培养出合格的深度强化学习从业者和研究员。
核心功能
- 强化学习理论与术语介绍: 提供对强化学习基本概念、术语和理论的清晰阐释。
- 关键算法代码实现: 包含一系列设计精良、易于理解和独立的核心深度强化学习算法的Python实现。
- 研究路线图与方法论: 提供成为深度强化学习研究员的指导,包括学习路径、研究方法和实践建议。
- 精选论文集: 整理和分类了重要的深度强化学习学术论文,便于学习者深入研究。
- 实践练习与基准测试: 提供练习题目帮助巩固知识,并对算法实现进行了基准测试(例如在MuJoCo Gym环境如HalfCheetah, Hopper等中)。
技术原理
Spinning Up的核心技术原理围绕深度强化学习展开。它涵盖了多种RL范式和算法实现,包括但不限于:
- 无模型强化学习(Model-Free RL): 例如策略梯度方法 (Policy Gradients)、Q-学习 (Q-learning)、Actor-Critic算法等。
- 基于模型强化学习(Model-Based RL): 涉及构建环境模型来辅助决策或规划。
- 探索(Exploration): 处理在未知环境中有效探索的策略和机制。
- 多任务与迁移学习(Transfer and Multitask RL): 探讨如何将在一个任务中学到的知识迁移到另一个任务或同时学习多个任务。
- 元强化学习(Meta-RL): 使智能体能够快速适应新任务的学习方法。
- 分层强化学习(Hierarchy)与记忆(Memory): 涉及复杂行为的分解和对过去经验的利用。
- 模仿学习(Imitation Learning): 从专家示范中学习行为。 所有这些算法实现都利用深度神经网络作为函数逼近器,以处理高维状态和动作空间。
应用场景
- 深度强化学习教学与培训: 作为入门和进阶深度强化学习的优质教材和实践平台。
- AI研究与开发: 为研究人员提供标准化的算法实现和基准测试环境,加速新算法的验证与迭代。
- 机器人控制: 智能体在MuJoCo等物理仿真环境中进行训练和测试,可应用于机器人动作控制和任务规划。
- 决策系统构建: 适用于需要智能体通过与环境交互学习最优决策的各类场景,如游戏AI、自动驾驶策略制定、资源调度等。
- 学术研究与论文复现: 为学术界提供可信赖的开源代码,便于复现和比较不同算法的性能。
- Welcome to Spinning Up in Deep RL! — Spinning Up documentation
- spinningup/readme.md at master · openai/spinningup
Stable Baselines3
简介
Stable Baselines3 (SB3) 是一个基于 PyTorch 的强化学习 (Reinforcement Learning, RL) 算法的可靠实现集合。它是 Stable Baselines 的下一代主要版本,旨在为强化学习研究和应用提供一个稳定、易用且高性能的框架。SB3 不仅包含多种主流的RL算法,还提供了训练、评估和调优RL智能体的工具。
核心功能
- 多算法实现: 提供了A2C、DDPG、DQN、HER、PPO、SAC、TD3等多种常用且可靠的强化学习算法实现。
- PyTorch支持: 所有算法均基于PyTorch框架实现,方便进行深度学习模型的集成和开发。
- 训练与评估工具: 提供用于训练、评估强化学习智能体,以及超参数调优的脚本和工具。
- 结果可视化: 支持绘制训练结果图表和录制智能体行为视频。
- 预训练模型与超参数: RL Baselines3 Zoo提供了针对常见环境的预调优超参数和预训练智能体。
- 环境兼容性: 支持与Gymnasium (原Gym) 环境无缝集成,便于RL任务的定义和执行。
- 模块化设计: 结构清晰,便于用户理解、修改和扩展。
技术原理
Stable Baselines3 的核心技术原理在于其对强化学习算法的深度学习实现。它利用 PyTorch 这一流行的深度学习框架来构建和训练RL智能体所需的神经网络模型。
- 基于模型的算法 (Model-based vs. Model-free): SB3 主要聚焦于免模型 (model-free) 强化学习算法,这些算法直接从与环境的交互中学习最优策略,而无需建立环境的动力学模型。
- 策略优化: 包含了策略梯度方法 (如A2C, PPO) 和基于值函数的方法 (如DQN) 的实现。
- Actor-Critic 架构: 许多算法(如A2C, SAC, TD3)采用Actor-Critic架构,其中一个网络(Actor)负责学习策略,另一个网络(Critic)负责评估策略。
- 经验回放 (Experience Replay): 部分离策略 (off-policy) 算法(如DQN, SAC, TD3)利用经验回放机制存储交互数据,并从中采样进行训练,以打破数据之间的相关性,提高训练效率和稳定性。
- 向量化环境 (Vectorized Environments): 通过
make_vec_env等工具支持同时运行多个环境副本,并行收集经验,从而显著加速数据收集和训练过程。
应用场景
- 学术研究与实验: 为强化学习算法的研究、验证和新算法的开发提供一个稳定的基准和实验平台。
- 机器人控制: 用于训练机器人完成各种任务,如导航、抓取、操作等。
- 游戏AI开发: 构建能够自主学习并在复杂游戏环境中表现出智能行为的游戏AI。
- 自动化决策系统: 应用于需要通过试错学习进行序贯决策的场景,例如资源调度、智能交通管理、金融交易策略优化等。
- 教育与学习: 作为学习和实践强化学习概念和算法的工具,其清晰的代码结构和详尽的文档有助于初学者理解。
- 仿真环境测试: 在各种仿真环境中快速部署和测试RL智能体,评估其性能和鲁棒性。
- Stable Baselines3
- Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations — Stable Baselines3 1.7.0a5 documentation
天授tianshou
简介
Tianshou(天授)是一个基于纯 PyTorch 和 Gymnasium 构建的强化学习(RL)库。它旨在提供一个高性能、模块化、用户友好的框架,以便用最少的代码行构建深度强化学习智能体。Tianshou 克服了现有RL库可能存在的复杂代码库、不友好API或低速等问题,通过与环境的持续交互,实现智能体的自主学习。
核心功能
- 纯PyTorch与Gymnasium集成: 完全基于PyTorch开发,并支持Gymnasium环境接口。
- 模块化框架: 提供高度模块化的组件,如Batch、Replay Buffer、Vectorized Environment、Policy、Collector和Trainer,便于用户灵活组合和定制。
- 高效率与快速: 针对深度强化学习任务优化,提供快速的执行速度。
- Pythonic API: 提供简洁直观的API,降低学习曲线。
- 内置算法支持: 支持多种经典和前沿的深度强化学习算法。
- 实验评估工具: 引入
evaluation包,用于实验的运行和评估,包括性能比较和可视化。 - 分布式训练支持: 具备多GPU训练能力。
- 严格的代码质量: 包含全面的单元测试、功能检查、文档检查、PEP8代码风格检查和类型检查。
技术原理
Tianshou的核心技术原理在于其模块化设计和对PyTorch张量操作的深度利用。
- Batch 数据结构: 内部广泛使用Batch数据结构,用于存储和操作分层的命名张量,是数据流转和处理的基础。
- 组件化构建: 将RL训练流程解耦为L0: Overview, L1: Batch, L2: Replay Buffer, L3: Vectorized Environment, L4: Policy, L5: Collector, L6: Trainer等独立且可协作的模块,使得用户可以根据需求灵活地组合和替换这些组件。
- 向量化环境: 支持向量化环境,允许同时与多个环境进行交互,从而提高数据收集效率和训练速度。
- 统一的API设计: 针对不同RL组件(如策略、收集器)提供统一的接口,简化了集成和开发过程。
- 强化学习算法实现: 基于PyTorch实现各种RL算法的策略(Policy),并通过Collector与环境进行交互收集数据,Replay Buffer存储经验,最终由Trainer进行模型更新。
- 性能优化: 通过底层C++优化和高效的PyTorch操作,确保数据处理和模型训练的高效性。
应用场景
- 深度强化学习研究与开发: 为研究人员和开发者提供一个灵活、高效的平台,用于实现、测试和比较各种深度强化学习算法。
- 机器人控制: 用于训练机器人完成复杂的运动控制、导航和操作任务。
- 游戏AI: 开发能够自主学习并超越人类表现的游戏智能体。
- 自动化决策系统: 在需要序列决策的领域,如资源调度、交通信号控制、金融交易策略等,构建智能决策模型。
- 学术教学: 作为强化学习课程的实践工具,帮助学生理解并实现RL算法。
- 工业控制与优化: 应用于工业生产线的优化、设备故障诊断和预测性维护等领域。
- thu-ml/tianshou: An elegant PyTorch deep reinforcement learning library.
- Get Started with Jupyter Notebook — Tianshou 0.4.10 documentation
强化学习库
简介
这四个GitHub仓库都专注于深度强化学习(Deep Reinforcement Learning, DRL),提供了用于研究、开发和应用RL算法的框架和库。它们旨在简化DRL的实现、测试和原型设计过程,使得研究人员和开发者能够更高效地进行实验和构建智能体。这些项目涵盖了从课程材料到Google和TensorForce等机构的开源框架,共同推动了深度强化学习领域的发展。
核心功能
- 算法实现与教程: 提供深度强化学习算法的实现代码和教程,例如Udacity的项目专注于教学和算法实现。
- 快速原型设计: 作为研究框架,支持快速原型设计和实验新颖的强化学习算法。
- 模块化与灵活性: 强调模块化的设计理念,以实现灵活的库结构和易用性。
- 强化学习算法库: 包含一系列预构建的强化学习算法,如DQN、PPO等,方便用户直接使用或在此基础上进行修改。
- 环境集成与交互: 支持与各种强化学习环境(如Unity ML-Agents,或Arcade Learning Environment)进行交互和训练,也支持自定义环境。
- 性能评估与基准测试: 提供工具和协议用于评估算法性能和进行基准测试。
- 日志与检查点: 支持实验过程中的数据记录、日志输出和模型检查点保存。
技术原理
这些框架主要基于以下技术原理和工具:
- 深度学习框架: 大部分项目底层依赖于流行的深度学习框架,如Google的TensorFlow(Dopamine, TensorForce, TF-Agents)和PyTorch(Udacity)。这些框架提供了构建和训练神经网络所需的计算图、自动微分等核心功能。
- 强化学习核心概念: 实现了强化学习中的关键概念,包括:
- 智能体(Agent): 负责感知环境、做出决策并学习优化行为的实体。
- 环境(Environment): 智能体与之交互的系统,提供状态、奖励并响应智能体的动作。
- 策略(Policy): 定义了智能体在给定状态下如何选择动作的规则。
- 奖励信号(Reward Signal): 环境对智能体行为的反馈,用于指导学习过程。
- 价值函数(Value Function): 估计在特定状态或状态-动作对下未来预期累积奖励。
- 算法实现: 封装了多种经典及前沿的深度强化学习算法,例如基于价值的方法(如Q-learning的深度变体DQN)和基于策略的方法(如策略梯度、A2C、PPO)等。
- 经验回放(Replay Buffer): 常用的一种技术,用于存储智能体与环境交互的经验(状态、动作、奖励、下一状态),并从中随机采样批次数据进行训练,以打破数据相关性,提高训练稳定性。
- 分布式与并行训练: 部分框架(如Dopamine)可能支持分布式或并行计算,以加速大规模实验的训练过程。
应用场景
- 学术研究与教学: 作为深度强化学习课程(如Udacity的深度强化学习纳米学位)的教学材料和实验平台,以及学术界进行新算法研究和验证的工具。
- 智能体开发与优化: 用于开发和优化在复杂环境(如游戏、机器人控制、自动驾驶模拟)中执行任务的智能体。
- 基准测试与比较: 提供标准化的协议和环境,用于对不同强化学习算法的性能进行公平的基准测试和比较。
- 实际问题解决方案: 将深度强化学习应用于解决实际世界中的决策制定问题,例如资源调度、推荐系统、金融交易策略等。
- 工业应用原型: 为工业界在需要智能决策的场景下(如自动化、流程优化)进行概念验证和原型开发提供支持。
- udacity/deep-reinforcement-learning: Repo for the Deep Reinforcement Learning Nanodegree program
- google/dopamine: Dopamine is a research framework for fast prototyping of reinforcement learning algorithms.
- tensorforce/tensorforce: Tensorforce: a TensorFlow library for applied reinforcement learning
- TF-Agents: A reliable, scalable and easy to use TensorFlow library for Contextual Bandits and Reinforcement Learning.
强化学习环境
简介
本总结综合了Unity ML-Agents工具包与强化学习Discord社区维基。Unity ML-Agents是一个开源项目,旨在利用Unity游戏和模拟环境,通过深度强化学习和模仿学习来训练智能体。强化学习Discord维基则是一个汇集强化学习学习资源和社区讨论的平台,为RL爱好者提供知识共享和交流的场所。
核心功能
- Unity ML-Agents:
- 将Unity场景转换为可用于机器学习训练的环境。
- 支持使用深度强化学习和模仿学习算法训练智能体。
- 能够将训练好的智能体行为嵌入回Unity场景中以控制角色。
- 提供C# SDK以方便开发者集成。
- 强化学习Discord维基:
- 作为强化学习的学习资源库,提供各类相关资料。
- 促进RL社区成员之间的知识共享和交流。
技术原理
Unity ML-Agents的核心技术原理在于利用Unity引擎的强大模拟能力,构建出复杂的虚拟环境。通过深度强化学习(Deep Reinforcement Learning, DRL),智能体在这些环境中与世界交互,接收奖励或惩罚信号,并通过神经网络学习最优策略。同时,也支持模仿学习(Imitation Learning),即智能体通过观察人类或其他智能体的行为数据来学习。该工具包提供了连接Unity环境与Python训练算法的接口,实现数据的高效传输与模型训练。强化学习Discord维基则不涉及特定的技术原理,其本质是一个基于互联网的协作式知识管理系统。
应用场景
- 游戏开发: 训练游戏中的NPC(非玩家角色)行为,使其更智能、更具挑战性。
- 机器人模拟与控制: 在虚拟环境中模拟机器人行为,进行控制策略的训练和验证,降低真实世界的试验成本。
- 科学研究: 为AI研究人员提供一个灵活的平台,用于开发和测试新的强化学习算法。
- 教育与学习: 作为强化学习的实践平台和学习资源,帮助学生和爱好者理解并应用RL概念。
- 社区交流: 强化学习Discord维基为全球的强化学习学习者和研究者提供了一个便捷的交流、问答和资源分享平台。
- Unity-Technologies/ml-agents: The Unity Machine Learning Agents Toolkit (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents using deep reinforcement learning and imitation learning.
- 主页 · andyljones/reinforcement-learning-discord-wiki Wiki
0.强化学习gym案例合集--简单调用即可
简介
Gymnasium是一个开源Python库,作为强化学习(RL)环境的标准API,旨在促进RL算法的开发与比较。它是OpenAI Gym库的维护性分支,提供了一系列符合API标准的环境。RLcycle则是一个基于PyTorch、Ray和Hydra的强化学习智能体框架,专注于提供即用型智能体和可复用组件,以简化RL实验和原型开发。这两个项目共同为RL研究人员和开发者提供了从环境交互到算法实现的完整工具链。
核心功能
- Gymnasium:
- 提供单一智能体强化学习环境的标准API接口。
- 包含多样化的参考环境集,如经典控制、Box2D、MuJoCo等。
- 兼容旧版OpenAI Gym环境,确保现有代码的平滑过渡。
- 通过简单、Pythonic的
Env类封装环境动态,支持环境重置(reset)和步进(step)操作。
- RLcycle:
- 提供大量即用型强化学习智能体(agents),方便快速启动项目。
- 提供可复用的组件,支持用户快速构建和修改RL算法。
- 利用Ray实现并行化处理,提升训练效率。
- 集成Hydra用于灵活的实验配置和参数管理。
技术原理
- Gymnasium:
- 基于Python语言实现,通过定义
gymnasium.Env抽象基类构建环境,强制规范了强化学习环境的状态观测(observation)、动作(action)、奖励(reward)、终止(terminated/truncated)和信息(info)的交互接口。 - 核心机制是
step()函数,用于模拟智能体在环境中执行一步动作后的状态转移,以及reset()函数用于环境的初始化。 - 通过API标准化,解耦了RL算法与具体环境,使得算法可以在不同环境中通用。
- 基于Python语言实现,通过定义
- RLcycle:
- 底层深度学习框架采用PyTorch,用于构建和训练强化学习智能体的神经网络模型。
- 利用Ray分布式计算框架实现算法的并行化训练,加速数据收集和模型更新过程,尤其适用于大规模实验。
- 采用Hydra配置管理工具,支持动态配置文件的加载和覆盖,使得实验参数的调整和管理变得高效和模块化。
应用场景
- 强化学习算法研究与开发: 研究人员可以利用Gymnasium提供的标准环境测试和比较不同的RL算法性能;RLcycle则加速了新算法的原型开发和实验验证。
- RL算法教学与学习: 作为学习和理解强化学习基本概念和算法实现的平台,方便学生和初学者上手实践。
- 智能控制系统开发: 在模拟环境中训练智能体解决各种控制问题,如机器人控制、游戏AI开发等。
- 跨领域RL应用探索: 结合特定领域的环境(例如自定义环境),利用这些工具开发和部署应用于金融、医疗、物流等领域的智能决策系统。
- 大规模强化学习实验: RLcycle的并行化能力使其适用于需要大量数据或计算资源的复杂RL任务。
- Farama-Foundation/Gymnasium: A standard API for single-agent reinforcement learning environments, with popular reference environments and related utilities (formerly Gym)
- Gymnasium Documentation
- RLcycle: A library for ready-made reinforcement learning agents and reusable components for neat prototyping
智能体算法
简介
这些GitHub存储库主要围绕多智能体强化学习(MARL)领域。openai/multiagent-particle-envs 和 dingidng/multiagent-particle-envs 提供了一个轻量级、可定制的2D多智能体粒子仿真环境(MPE),用于研究多智能体系统中的协作、竞争和混合任务。而 marlbenchmark/on-policy 则是一个多智能体强化学习算法的基准测试平台,包含了如多智能体近端策略优化(MAPPO)等流行算法的实现。
核心功能
- 多智能体环境仿真: 提供2D粒子世界,支持多智能体在连续观察空间和离散动作空间中进行交互。
- 任务场景多样化: 包含多种预设场景,如合作导航、物理欺骗和通信任务等,用于模拟不同类型的多智能体互动。
- MARL算法实现与基准测试: 提供了包括MAPPO在内的多种On-Policy多智能体强化学习算法的官方实现,并可作为算法性能评估的基准。
- 研究与开发平台: 为研究人员提供了一个测试、开发和比较多智能体学习算法的灵活框架。
技术原理
- 基于物理的2D仿真: MPE环境构建在一个具有简单物理规则的二维世界中,智能体以粒子的形式存在,能够移动、通信并与地标交互。
- 连续观察空间与离散动作空间: 智能体感知连续的环境信息(如位置、速度),并执行离散的动作。
- 强化学习范式: 遵循马尔可夫决策过程(MDP)框架,智能体通过与环境交互学习最优策略以最大化累积奖励。
- On-Policy算法:
marlbenchmark/on-policy专注于On-Policy强化学习算法,例如MAPPO,它基于PPO(Proximal Policy Optimization)并扩展到多智能体设置,通过限制策略更新幅度来提高训练稳定性。 - 分布式RL与深度RL: 相关实现可能涉及分布式强化学习和深度强化学习技术,利用神经网络来近似策略和价值函数。
应用场景
- 多智能体强化学习算法研究: 开发和验证新的MARL算法,探索协作、竞争和混合策略学习。
- 群体智能与协调控制: 模拟和研究多智能体系统在复杂任务中的协同行为和分布式决策。
- 机器人与无人机协同: 为多机器人或多无人机协同控制、路径规划等场景提供仿真测试环境。
- 人工智能教育与实验: 作为教学和实践多智能体强化学习概念与算法的平台。
- 基准测试与性能评估: 用于对比和评估不同MARL算法的性能和效率。
- openai/multiagent-particle-envs: Code for a multi-agent particle environment used in the paper "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments"
- Multi-Agent PPO (MAPPO).
- multiagent-particle-envs: Code for a multi-agent particle environment used in the paper "Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments"
单智能体算法
- Rainbow:整合DQN六种改进的深度强化学习方法! - 简书
- 最前沿:深度解读Soft Actor-Critic 算法 - 知乎
- SAC论文解读以及简易代码复现 - 知乎
- 浅谈TD3:从算法原理到代码实现 - 知乎
- 【深度强化学习】TD3算法:DDPG的进化_chy的博客-CSDN博客
- TD3:双延迟深度确定性策略梯度算法_布谷AI的专栏-CSDN博客_td3算法
- Deep Reinforcement Learning - 1. DDPG原理和算法_kenneth_yu的博客-CSDN博客_ddpg
- Policy Gradient之A2C算法 - 飞桨AI Studio - 人工智能学习实训社区
- 深度强化学习 -- 进击的 Actor-Critic(A2C 和A3C) - 知乎
- 强化学习算法TD3论文的翻译与解读 - 知乎
- 论文笔记之SAC提升算法_Ton的博客-CSDN博客_sac算法
- A2C、ppo,sac td3等
- A2C、ppo,sac td3等 算法选择篇 - 知乎
多智能体算法
简介
本内容综合介绍了多智能体强化学习(MARL)领域的两种主要算法:多智能体深度确定性策略梯度(MADDPG)和QMIX算法。MADDPG作为DDPG在多智能体环境中的扩展,旨在解决混合合作-竞争环境下的强化学习挑战。QMIX则是一种基于值函数的多智能体强化学习算法,采用中心化学习、分布式执行的模式。此外,内容也提及了百度飞桨AI Studio这一人工智能学习与实训平台,为深度学习项目提供开发环境和算力支持。
核心功能
- 多智能体决策与协作: MADDPG和QMIX算法的核心在于使多个智能体能在复杂的多智能体环境中进行有效决策,包括处理合作与竞争并存的任务。
- 策略优化: 两种算法都致力于优化智能体的行为策略,以最大化团队或个体在多智能体环境中的累积奖励。
- 问题解决能力: MADDPG通过增强Critic网络的输入信息,解决了多智能体环境中的非平稳性问题,并能处理部分可观测环境。QMIX通过值函数分解,解决了团队合作中的信用分配问题。
- 开发与实训环境: 百度飞桨AI Studio提供了一个集AI教程、代码环境、算法算力(包括免费GPU)和数据集于一体的在线开发与实训平台,支持深度学习项目开发、模型训练与测试。
技术原理
- MADDPG (Multi-Agent Deep Deterministic Policy Gradient): 借鉴了DDPG(深度确定性策略梯度)的思想,但将其扩展到多智能体场景。其核心采用“集中式训练、分布式执行”(Centralized Training, Decentralized Execution, CTDE)框架。
- Actor-Critic结构: 每个智能体都有一个独立的Actor网络用于输出动作策略,以及一个独立的Critic网络用于评估动作价值。
- 集中式Critic: 在训练阶段,每个智能体的Critic网络可以接收所有智能体的观测(或状态)和所有智能体的动作作为输入,从而能够更准确地评估联合动作的Q值,解决了非平稳性问题。
- 分布式Actor: 在执行阶段,每个智能体的Actor网络只依赖于自己的局部观测来选择动作,实现分布式执行。
- 策略梯度: Actor网络的更新基于策略梯度,利用Critic的评估来指导策略的优化方向。
- QMIX (Q-Mixer): 是一种基于值函数分解的多智能体强化学习算法,同样遵循CTDE范式。
- 个体Q值网络: 每个智能体学习一个局部Q值网络,输出该智能体在局部观测下的动作Q值。
- 混合网络 (Mixing Network): 引入一个单调性混合网络,将所有智能体的局部Q值组合成一个全局Q值,确保全局最优动作对应的局部动作组合也构成局部最优。这种单调性约束保证了全局最优化等价于每个智能体选择各自局部最优动作。
- 信用分配: 通过混合网络,QMIX能有效地解决多智能体合作中的信用分配问题,即如何将团队的总体奖励合理地分配给每个智能体的贡献。
- AI Studio平台技术: 基于百度深度学习开源平台飞桨(PaddlePaddle),提供云端GPU算力、Jupyter Notebook等开发工具,支持Python编程环境,预置常用工具包和数据集,方便用户进行深度学习模型的开发、训练和部署。
应用场景
- 多智能体系统控制: 机器人协作、无人机编队、自动驾驶车队管理等。
- 游戏AI: 复杂的多人在线游戏、策略游戏中的智能体行为决策。
- 资源调度与管理: 交通信号灯控制、电力系统优化、物流配送优化等。
- 工业自动化: 多机器人协同生产、智能仓储系统。
- 仿真环境: 模拟复杂系统中的智能体交互与决策过程,进行策略验证。
- 人工智能教育与研究: 作为深度学习、强化学习的实践与教学平台,支持科研项目开发和实验验证。
- 详细介绍了MADDPG环境信息以及提供码源
- 【QMIX】一种基于Value-Based多智能体算法 - 知乎
- 多智能体强化学习入门(四)——MADDPG算法 - 知乎
- MADDPG分析及其更新策略见解_流年已逝的博客-CSDN博客
- 多智能体深度学习算法MADDPG的PARL实践 - 飞桨AI Studio - 人工智能学习实训社区
- 从代码到论文理解并复现MADDPG算法(PARL) - 飞桨AI Studio - 人工智能学习实训社区
5. RL项目案例
简介
本总结基于斗地主AI框架DouZero、通用游戏研究平台OpenSpiel以及卡牌游戏强化学习工具包RLCard。这三个项目共同关注使用强化学习技术开发和研究游戏AI,特别是针对信息不完全的卡牌类游戏。它们旨在为AI在复杂游戏环境中的决策、学习和策略生成提供解决方案和研究平台。
核心功能
- DouZero: 专注于斗地主游戏的AI训练与对弈,提供高效的强化学习框架以实现人类水平甚至超越人类表现的AI玩家。
- OpenSpiel: 作为一个综合性游戏研究工具集,支持多种类型的游戏环境,包括但不限于棋盘游戏、卡牌游戏和博弈论游戏。它提供了用于实现和测试通用强化学习、搜索和规划算法的接口,并支持多智能体设置。
- RLCard: 专门为卡牌游戏设计,提供了一系列易于使用的API和预设环境(如21点、德州扑克、斗地主、麻将、UNO等),方便研究者快速构建和评估卡牌游戏AI,尤其关注不完美信息博弈。
技术原理
这些项目主要利用深度强化学习(Deep Reinforcement Learning, DRL)和博弈论(Game Theory)的原理。
- 深度强化学习: 通过让AI智能体与游戏环境进行大量交互(自博弈),利用深度神经网络学习最优策略。例如,DouZero结合了传统蒙特卡洛方法、深度神经网络、动作编码和并行Actor来提升学习效率和效果。
- 不完美信息博弈: 针对卡牌游戏等信息不完全的场景,采用特定的算法和表示方法来处理隐藏信息,如OpenSpiel和RLCard均致力于弥合强化学习与不完美信息游戏之间的鸿沟。这可能涉及信息集、反事实遗憾最小化(CFR)及其变体、神经网络近似策略等技术。
- 并行计算与分布式训练: 为了加速学习过程,通常会采用并行化和分布式训练架构,使多个智能体或多个训练环境能够同时运行,从而高效地探索策略空间。
应用场景
- 游戏AI开发: 用于创建高性能的棋牌游戏AI,例如斗地主AI、德州扑克AI等,可应用于游戏产品或娱乐平台。
- 强化学习研究: 为研究人员提供标准化的环境和工具,以探索新的强化学习算法、多智能体学习方法以及不完美信息博弈中的AI策略。
- 博弈论分析: 作为博弈论算法的实验平台,用于分析和理解复杂多智能体交互中的策略和行为。
- 教育与教学: 可作为教学工具,帮助学生和研究者理解强化学习和博弈论在实际游戏中的应用。
- DouZero: 从零开始通过自我博弈强化学习来学打斗地主
- deepmind/open_spiel: OpenSpiel is a collection of environments and algorithms for research in general reinforcement learning and search/planning in games.
- datamllab/rlcard:纸牌(扑克)游戏中的强化学习/AI 机器人 - Blackjack、Leduc、Texas、DouDizhu、Mahjong、UNO。
- coupon精准营销
- DataFunTalk强化学习在调度任务流量监控应用
AI玩王者荣耀
简介
本内容综合介绍了三个与腾讯热门MOBA游戏《王者荣耀》AI相关的开源项目。Hok_env是腾讯AI Lab推出的《王者荣耀》AI开放环境,旨在提供一个标准化的强化学习训练平台。另两个项目ResnetGPT和WZCQ则是由个人开发者基于PyTorch框架,利用深度学习和强化学习技术,尝试构建能玩《王者荣耀》的AI模型。这些项目共同展示了利用人工智能技术训练游戏AI的可能性,并提供了相应的开发与训练环境或实现方案。
核心功能
- Hok_env:
- 提供《王者荣耀》AI开放环境,支持AI模型与游戏核心进行交互。
- 包含Hok_env SDK,用于程序化控制游戏。
- 提供强化学习训练框架,支持PPO等算法的实现。
- ResnetGPT:
- 基于PyTorch,利用ResNet101和GPT模型构建《王者荣耀》游戏AI。
- 实现游戏数据的截取与AI决策的输出。
- 支持在Windows环境下结合手机调试工具进行训练和运行。
- WZCQ:
- 运用基于策略梯度的强化学习方法训练AI玩《王者荣耀》。
- 在原有AI项目基础上进行改进,增加判断回报状态的神经网络。
- 专注于通过强化学习提升AI的游戏表现。
技术原理
- Hok_env: 采用Client-Server架构,通过Hok_env SDK与封装的Gamecore Server进行网络通信实现游戏交互。核心训练算法基于PPO (Proximal Policy Optimization) 强化学习算法。
- ResnetGPT: 视觉感知部分采用ResNet101预训练模型提取游戏画面特征。决策生成部分借鉴Transformer架构的解码器(类GPT结构)处理序列信息并输出操作。项目基于PyTorch深度学习框架,并利用scrcpy进行手机屏幕镜像与控制,pyminitouch进行精确触摸操作。
- WZCQ: 核心采用策略梯度 (Policy Gradient) 强化学习方法,通过优化策略网络直接输出动作概率来学习游戏策略。引入了额外的神经网络来判断和处理回报状态,以提升学习效率和效果。
应用场景
- 游戏AI研究与开发: 为《王者荣耀》等复杂MOBA游戏提供AI训练和测试平台,推动游戏AI技术的发展。
- 强化学习算法验证: 作为实际应用场景,验证和改进新的强化学习算法的有效性。
- 人机对抗及电竞训练: 训练出具备一定水平的AI玩家,用于人机对战、辅助玩家训练、分析游戏策略等。
- 自动化游戏测试: 利用AI进行游戏功能和性能的自动化测试。
- AI教育与实践: 为对游戏AI感兴趣的开发者和研究人员提供学习和实践的开源代码及环境。
- 腾讯强化学习开源王者荣耀
- FengQuanLi/ResnetGPT: 用Resnet101+GPT搭建一个玩王者荣耀的AI
- FengQuanLi/WZCQ: 用基于策略梯度得强化学习方法训练AI玩王者荣耀
基于DDPG算法的股票量化交易
简介
本项目是一个基于深度确定性策略梯度(DDPG)强化学习算法的股票量化交易实践,是教育部产学合作协同育人项目的成果之一。它利用飞桨(PaddlePaddle)深度学习框架实现DDPG算法,旨在通过机器学习方法模拟和优化股票交易策略,以应对股票市场复杂的连续决策问题。项目提供了相关数据集和代码示例,方便学习者理解和实践深度强化学习在金融领域的应用。
核心功能
- 强化学习算法实现:核心在于实现和应用DDPG算法,解决了传统DQN算法在连续动作空间中的局限性。
- 股票交易策略优化:通过DDPG智能体学习市场状态并优化交易策略,生成最优的股票买卖决策。
- 连续动作空间处理:允许交易策略在连续的动作空间(如投资比例或持仓量)中进行精细化决策,而非离散选择。
- 数据驱动的决策:利用历史股票市场数据进行训练,使模型能够从市场交互中学习并适应市场变化。
- 飞桨框架支持:整个项目基于百度飞桨深度学习框架构建,提供高效的开发和运行环境。
技术原理
该项目采用深度确定性策略梯度(DDPG)算法,这是一种基于Actor-Critic架构的离策略(off-policy)强化学习算法,专为连续动作空间设计。
- Actor网络(策略网络):直接输出确定性动作,即股票交易的具体操作(如买入/卖出量、资金分配比例),以最大化长期累积奖励。
- Critic网络(价值网络):评估Actor网络所生成动作的价值,通过估算Q值来指导Actor网络的更新方向。
- 目标网络(Target Networks):为了提高训练稳定性,DDPG引入了Actor和Critic的目标网络,用于计算目标Q值,以减少训练过程中的震荡。
- 经验回放(Replay Buffer):存储智能体与环境交互的经验(状态、动作、奖励、下一状态),并从中随机采样进行训练,以打破数据间的相关性,提高训练效率和稳定性。
- 噪声探索:在Actor网络的输出中加入高斯噪声,以促进智能体在连续动作空间中的探索,防止陷入局部最优。
应用场景
- 股票量化交易:应用于股票市场的自动化交易决策,通过智能体学习市场规律,执行买卖操作。
- 资产配置优化:在多资产组合中,DDPG可以学习如何动态调整各类资产的权重,以实现收益最大化和风险最小化。
- 金融风险管理:通过强化学习对市场波动进行建模,帮助投资者进行风险评估和对冲策略制定。
- 个性化投资建议:根据用户的风险偏好和投资目标,生成定制化的投资策略。
- 智能投顾系统:构建自动化的投资顾问系统,提供实时的交易信号和投资组合管理。
强化学习下五子棋
核心功能
- 五子棋对弈系统: 实现完整的五子棋游戏逻辑,支持棋盘显示、落子判断、胜负判定等基本功能。
- 深度强化学习AI: 包含一个通过深度强化学习训练而成的AI对手,能够与玩家进行对弈。
- AI训练模块: 提供训练AI模型的代码和环境,支持通过自我对弈或其他强化学习方法不断提升AI棋力。
- 服务器部署能力: 项目结构中包含
server和web_server.py等文件,暗示其可能支持将AI部署为可供访问的服务端。
技术原理
该项目的核心技术原理是深度强化学习(Deep Reinforcement Learning, DRL)。具体而言,它很可能结合了以下关键技术:
- 深度神经网络(Deep Neural Networks, DNN): 用于对棋盘状态进行特征提取和价值评估,预测最佳落子位置或棋局胜率。
- 蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS): 结合神经网络的评估,用于在搜索空间巨大的棋类游戏中进行高效的决策探索和选择。MCTS通过模拟对弈和反向传播结果来改进对弈策略。
- 策略网络(Policy Network)与价值网络(Value Network): 典型的DRL棋类AI会使用一个策略网络来指导MCTS的探索方向和选择落子动作,同时使用一个价值网络来评估当前棋局的胜率或优势。
- 自我对弈(Self-Play): AI通过与自身的不断对弈,生成大量的训练数据,并利用这些数据来更新和优化其策略网络和价值网络。
应用场景
- 棋类AI研究与开发: 作为深度强化学习在棋类游戏应用上的一个实践案例,可供研究者和开发者学习、参考和二次开发。
- 智能游戏开发: 可将此AI模块集成到五子棋游戏产品中,为玩家提供强大的AI对手。
- 教学与演示: 用于展示深度强化学习在复杂决策问题上的应用能力,作为人工智能课程的实践项目或演示工具。
- 人机对弈平台: 部署为在线五子棋对弈平台,供用户挑战高水平AI。
强化学习打扑克
简介
DouZero是一个由快手AI平台开发的强化学习框架,旨在掌握中国最流行的三人卡牌游戏——斗地主。该系统通过自我对弈深度强化学习方法,在斗地主这一信息不完整、状态空间巨大、动作空间复杂且需要竞争与协作并存的挑战性领域取得了显著突破,甚至超越了人类顶尖玩家水平。RLCard则是一个更通用的强化学习工具包,专注于提供卡牌游戏的RL环境,支持多种卡牌游戏,并为实现各种强化学习和搜索算法提供了易于使用的接口,旨在连接强化学习与不完美信息博弈。
核心功能
- 斗地主AI系统: DouZero能够作为高性能的斗地主AI,在自我对弈和人机对战中表现卓越。
- 强化学习框架: DouZero提供了一套用于训练和评估斗地主AI的强化学习框架。
- 多游戏支持: RLCard支持包括斗地主、二十一点、德州扑克、麻将、UNO等多种卡牌游戏环境。
- RL算法实现接口: RLCard为研究者和开发者提供了易于使用的接口,以实现和测试各种强化学习和搜索算法。
- 不完美信息博弈研究平台: RLCard为研究和开发不完美信息博弈中的AI代理提供了统一且标准化的环境。
技术原理
DouZero的核心技术原理是深度蒙特卡洛 (Deep Monte-Carlo, DMC) 算法,巧妙结合了传统蒙特卡洛方法的采样探索能力和深度神经网络的函数逼近能力。其关键技术包括:
- 自我对弈 (Self-Play): 通过AI程序之间不断对战来积累经验,无需人类专家数据,从而实现持续学习和性能提升。
- 深度神经网络 (Deep Neural Networks): 用于函数逼近,处理巨大的状态空间和复杂的动作空间。
- 高效动作编码 (Efficient Action Encoding): 将复杂的、变长的合法动作空间映射到固定维度的向量空间,简化了模型学习难度。
- 并行训练 (Parallel Actors): 利用多GPU进行并行化训练,大幅提高训练效率,使得DouZero能在短时间内超越现有AI程序。 RLCard则是一个通用工具包,其原理基于强化学习,提供标准的RL环境(如观测、动作空间、奖励机制),使研究者可以在其上构建和测试各类RL算法,如Q-learning、DQN、A2C、PPO等,以解决不完美信息博弈问题。
应用场景
- 游戏AI开发: DouZero和RLCard可用于开发高度智能的卡牌游戏AI,提升游戏体验或作为游戏测试工具。
- 强化学习研究与教育: RLCard作为RL工具包,为学术界和研究人员提供了一个标准化的平台,用于研究强化学习算法在不完美信息博弈中的表现,进行算法验证与创新。
- 复杂决策系统: DouZero在斗地主领域的成功经验(处理不完美信息、大状态/动作空间、竞争与协作)可为其他类似复杂决策问题(如金融交易、资源调度、自动驾驶)中的AI系统开发提供参考和方法论。
- 多智能体系统研究: 这些框架为研究多智能体协作与竞争机制提供了实践平台。
- 教学与实践: 可作为强化学习、深度学习和人工智能课程的实践项目或演示工具。
- RLcard Showdown斗地主demo展示
- kwai/DouZero: [ICML 2021] DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning | 斗地主AI
- datamllab/rlcard: Reinforcement Learning / AI Bots in Card (Poker) Games - Blackjack, Leduc, Texas, DouDizhu, Mahjong, UNO.
- [2106.06135] DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
量化交易
- AI4Finance Foundation
- AI4Finance-Foundation/FinGPT: Data-Centric FinGPT. Open-source for open finance! Revolutionize 🔥 We release the trained model on HuggingFace.
- AI4Finance-Foundation/RLSolver: Solvers for NP-hard and NP-complete problems with an emphasis on high-performance GPU computing.
- AI4Finance-Foundation/FinRL-Meta: FinRL-Meta: Dynamic datasets and market environments for FinRL.
- AI4Finance-Foundation/FinRL-Trading:用于交易。 请加星标。
- AI4Finance-Foundation/FinRL: FinRL: Financial Reinforcement Learning. 🔥
- 基于深度强化学习的金融交易策略(FinRL+Stable baselines3,以道琼斯30股票为例) - 知乎
- 量化投资的强化学习神器!FinRL 入门指南 - 知乎
- 强化学习(Reinforcement Learning)在量化交易领域如何应用? - 知乎
- 【FinRL】量化交易深度强化学习库-使用 1 - 知乎
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟

