
AI-Compass LLM合集-多模态模块:30+前沿大模型技术生态,涵盖GPT-4V、Gemin
AI-Compass LLM合集-多模态模块:30+前沿大模型技术生态,涵盖GPT-4V、Gemini Vision等国际领先与通义千问VL等国产优秀模型
AI-Compass 致力于构建最全面、最实用、最前沿的AI技术学习和实践生态,通过六大核心模块的系统化组织,为不同层次的学习者和开发者提供从完整学习路径。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟
📋 核心模块架构:
- 🧠 基础知识模块:涵盖AI导航工具、Prompt工程、LLM测评、语言模型、多模态模型等核心理论基础
- ⚙️ 技术框架模块:包含Embedding模型、训练框架、推理部署、评估框架、RLHF等技术栈
- 🚀 应用实践模块:聚焦RAG+workflow、Agent、GraphRAG、MCP+A2A等前沿应用架构
- 🛠️ 产品与工具模块:整合AI应用、AI产品、竞赛资源等实战内容
- 🏢 企业开源模块:汇集华为、腾讯、阿里、百度飞桨、Datawhale等企业级开源资源
- 🌐 社区与平台模块:提供学习平台、技术文章、社区论坛等生态资源
📚 适用人群:
- AI初学者:提供系统化的学习路径和基础知识体系,快速建立AI技术认知框架
- 技术开发者:深度技术资源和工程实践指南,提升AI项目开发和部署能力
- 产品经理:AI产品设计方法论和市场案例分析,掌握AI产品化策略
- 研究人员:前沿技术趋势和学术资源,拓展AI应用研究边界
- 企业团队:完整的AI技术选型和落地方案,加速企业AI转型进程
- 求职者:全面的面试准备资源和项目实战经验,提升AI领域竞争力
LLM合集-多模态模块构建了涵盖30+个前沿多模态大模型的完整技术生态,专注于视觉-语言、音频-语言等跨模态AI技术的创新应用。该模块系统性地整理了OpenAI GPT-4V、Google Gemini Vision、Anthropic Claude 3、Meta LLaVA系列等国际领先的视觉语言模型,以及阿里通义千问VL、百度文心一言4.0、腾讯混元多模态、字节豆包视觉版、智谱GLM-4V、月之暗面Kimi视觉等国产优秀多模态模型。技术特色涵盖了图像理解、视频分析、音频处理、3D感知等多维度感知能力,详细解析了Vision Transformer、CLIP、DALL-E、Stable Diffusion等核心技术架构,以及视觉编码器、跨模态注意力、多模态融合等关键技术机制。
模块深入介绍了图像描述生成、视觉问答、图文检索、视频理解、音频转录、语音合成等典型应用场景,以及多模态数据预处理、模型训练策略、推理优化、部署方案等工程化实践。内容还包括多模态评测基准(VQA、COCO Caption、BLIP)、开源项目生态(LLaVA、MiniGPT-4、InstructBLIP)、商业API服务、性能对比分析等实用资源,以及最新技术突破、应用创新、发展趋势等前沿洞察,帮助开发者构建具备丰富感知能力的下一代AI应用,实现文本、图像、音频、视频等多模态信息的智能理解和生成。
目录
- 1.Nexus-Gen魔塔文生图
- 1.Seed1.5-VL字节
- 2.Matrix-Game空间大模型-昆仑万维
- 2.Step1X-3D 阶跃星辰 3D生成模型
- 2.bytedance ContentV文生视频
- 2.字节BAGEL多模态模型
- 2.谷歌系列
- 2.谷歌系列/Graphiti-AI动态知识图谱
- 2.通义万相-开源视频模型
- 3.MoviiGen 1.1
- 3.meta-vjepa世界模型
- 4.3D生成模型Partcrafter
- 4.MAGREF多主体视频生成框架-字节
- 4.OmniAudio空间音频生成
- 4.PlayDiffusion音频编辑
- 4.SeedVR2-字节视频修复
- 4.美团-肖像生成llia
- 5.多人对话视频框架
- 5.趣丸科技-人脸动画生成
- Kwai Keye VL 快手
- OmniAvatar浙大阿里视频生成
1.Nexus-Gen魔塔文生图
简介
Nexus - Gen是一个统一模型,将大语言模型(LLM)的语言推理能力与扩散模型的图像合成能力相结合,通过双阶段对齐训练过程,使模型具备处理图像理解、生成和编辑任务的综合能力。2025年5月27日使用BLIP - 3o - 60k数据集微调后,提升了图像生成对文本提示的鲁棒性。
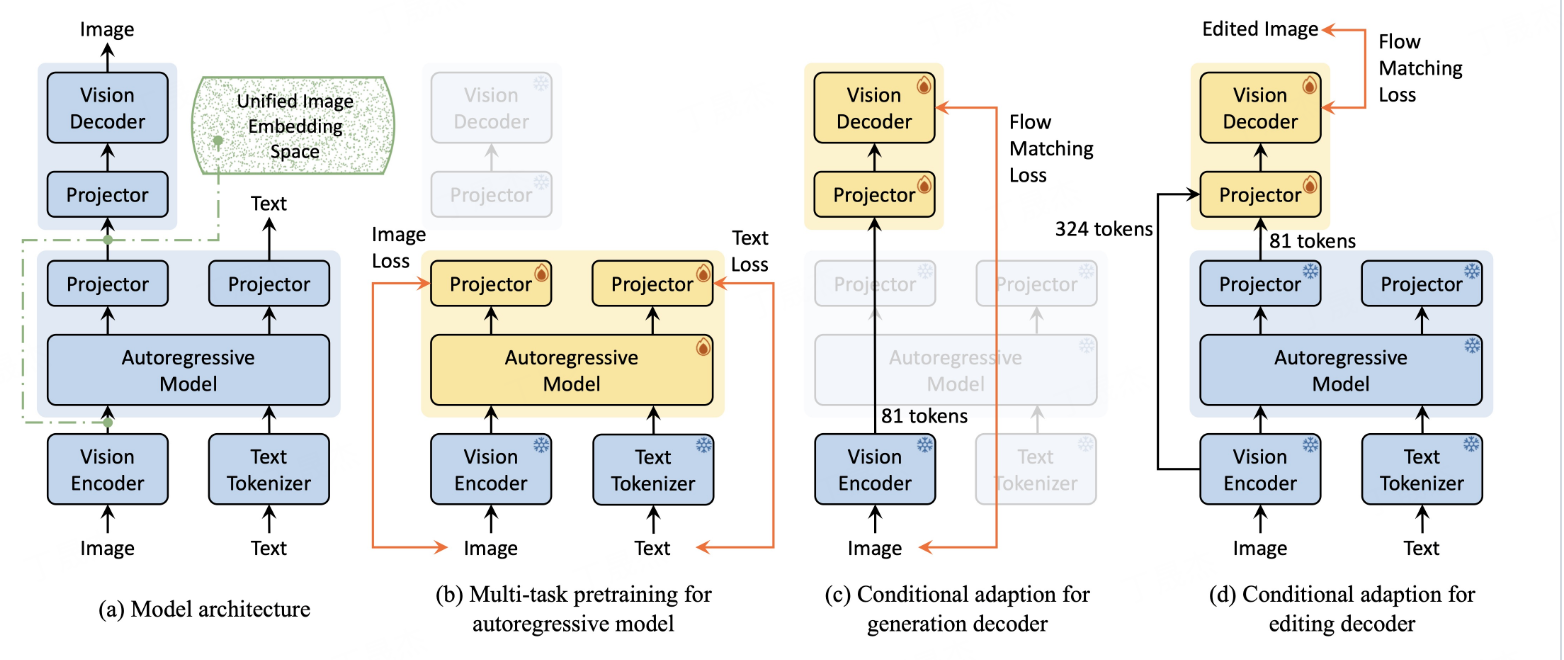
核心功能
- 图像理解:能对图像进行理解分析。
- 图像生成:依据文本提示生成高保真图像,可使用预填充自回归策略提升生成质量,还支持使用较少显存生成图像。
- 图像编辑:对已有图像进行编辑处理。
技术原理
通过双阶段对齐训练过程,使大语言模型和扩散模型的嵌入空间对齐。一是自回归大语言模型学习基于多模态输入预测图像嵌入;二是视觉解码器训练从这些嵌入中重建高保真图像。训练大语言模型时,引入预填充自回归策略避免连续嵌入空间中误差积累导致的生成质量下降问题。
应用场景
-
图像创作:根据文字描述生成艺术作品、设计素材等。
-
图像编辑:对照片、设计图等进行修改完善。
-
图像分析:辅助理解图像内容,如智能图像标注等。
1.Seed1.5-VL字节
简介
Seed1.5-VL 是由字节跳动发布的一款视觉 - 语言基础模型,专注于提升多模态理解与推理能力。它采用 5.32 亿参数的视觉编码器和 200 亿激活参数的混合专家(MoE)大语言模型,在 60 项公开评测基准中的 38 项取得 SOTA 表现。
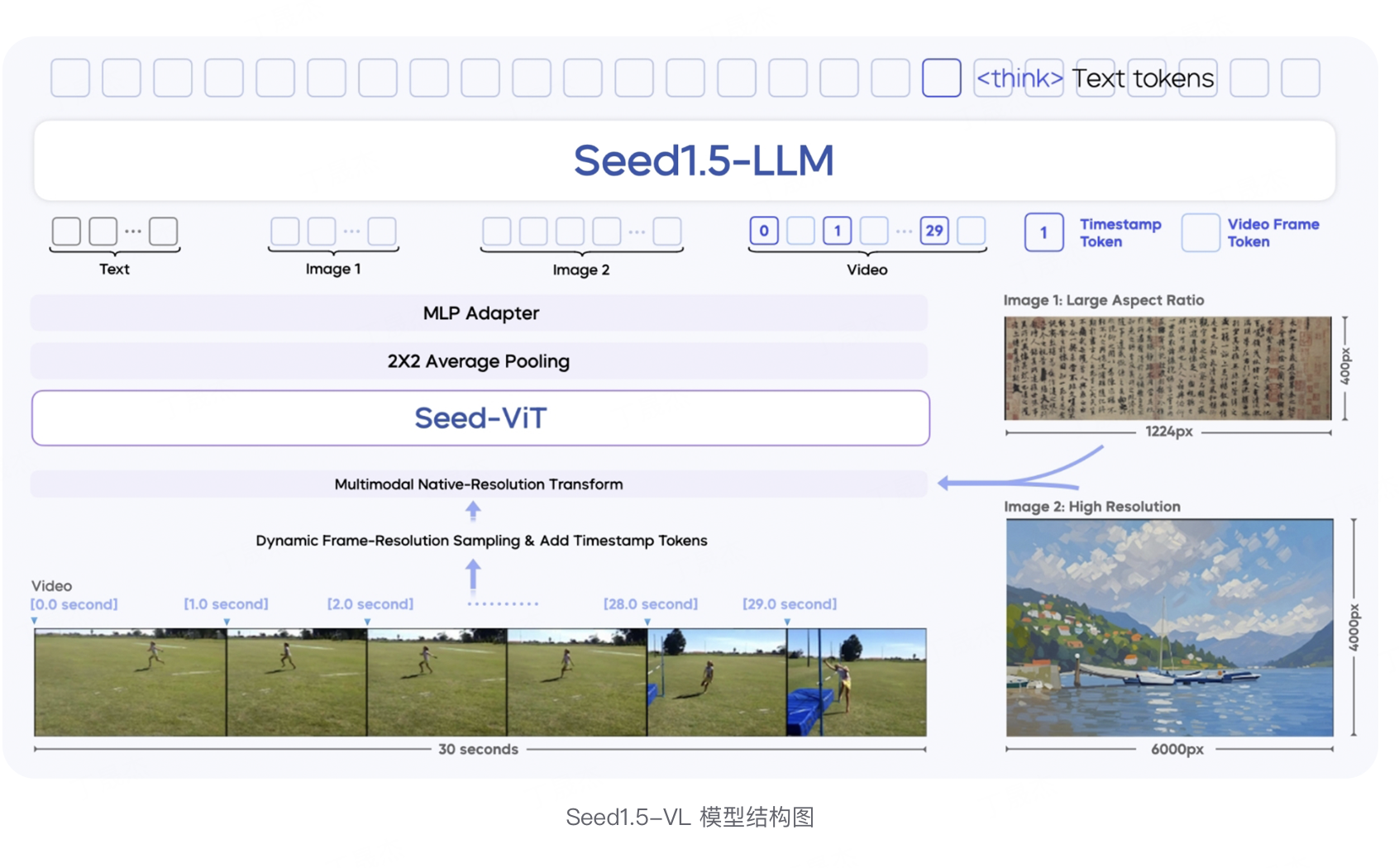
核心功能
- 多模态理解:支持图像、视频等多模态输入,能处理复杂推理、OCR、图表理解、视觉定位等任务。
- 智能体交互:在 GUI 控制、游戏玩法等交互式智能体任务中表现出色。
- 格式转换:可将 txt 文件转换为 epub 格式。
技术原理
- 模型架构:由 SeedViT 编码图像和视频、MLP 适配器投射视觉特征、大语言模型处理多模态输入并推理。
- 图像与视频处理:支持多分辨率图像输入,用原生分辨率变换保留细节;视频处理采用动态帧分辨率采样策略,引入时间戳标记增强时间信息感知。
- 预训练:使用 3 万亿源标记的预训练语料库,多数子类数据训练损失与训练标记数遵循幂律关系。
- 后训练:结合拒绝采样和在线强化学习迭代更新,监督信号仅作用于最终输出结果。
应用场景
-
内容识别:识别图片中的地点、物体等。
-
视觉谜题解答:根据表情符号等视觉元素联想电影等。
-
文件格式转换:将 txt 文件转换为 epub 格式。
-
智能体操作:进行 GUI 智能体任务,如设置软件全局热键等。
2.谷歌系列
简介
Imagen图像生成模型,它是目前最佳的图像生成模型,可生成具有逼真细节、清晰画质、改进拼写和排版的图像,涵盖风景、人物、动物、漫画、包装等多种场景,能将用户的想象快速转化为生动的视觉呈现。谷歌DeepMind推出的视频生成模型Veo,包括最新的Veo 3及Veo 2的新创意功能。Veo 3具有更高的真实感、更好的指令遵循能力,能原生生成音频;Veo 2在控制、一致性和创造性方面有新提升,还具备参考图像生成视频、匹配风格等功能。该模型在视频生成领域表现出色,但在自然连贯的语音音频方面仍在发展。此外,还介绍了其在影视、游戏等行业的应用案例。
核心功能
- 图像生成:依据用户输入的文本描述,生成具有高度真实感的图像,包括不同场景、生物、物品等。
- 细节捕捉:能够捕捉极端特写,呈现丰富的颜色、纹理和渐变,使图像具有可触摸感。
- 拼写排版优化:在漫画、包装和收藏品等方面,实现改进的拼写、更长的文本字符串以及新的布局和样式。
- 视频生成:根据文本描述生成具有高真实感和细节的视频,涵盖多种场景和风格。
- 音频生成:Veo 3可原生生成音效、环境噪音和对话等音频。
- 视频编辑:包括相机控制、添加或移除物体、角色控制、运动控制、外绘画、首末帧过渡等功能。
应用场景
-
艺术创作:帮助艺术家、设计师快速将创意转化为图像,用于绘画、插画、漫画等创作。
-
商业设计:如产品包装设计、广告宣传海报、品牌形象设计等。
-
娱乐行业:为游戏、影视制作生成场景、角色、道具等概念图。
-
影视制作:从脚本到故事板制作,提升电影制作流程效率。
-
游戏开发:为游戏提供视觉体验,如在地下城爬行游戏中充当主持人、引导者和互动角色。
-
创意工具开发:开发者可将Veo与其他生成媒体技术结合,创造新型创意工具。
Graphiti-AI动态知识图谱
简介
Graphiti是一个用于构建和查询时态感知知识图谱的框架,专为动态环境中的AI智能体设计。它能将用户交互、企业数据和外部信息整合到可查询的图谱中,支持增量数据更新、高效检索和精确历史查询,适用于开发交互式、上下文感知的AI应用。
核心功能
- 数据整合:集成和维护动态用户交互与业务数据。
- 推理与自动化:促进智能体基于状态的推理和任务自动化。
- 数据查询:支持语义、关键字和基于图的搜索方法,查询复杂且不断演变的数据。
- 管理操作:具备事件管理、实体管理、关系处理、语义和混合搜索、组管理、图维护等功能。
技术原理
- 双时态数据模型:显式跟踪事件发生和摄取时间,实现精确的时间点查询。
- 高效混合检索:结合语义嵌入、关键字(BM25)和图遍历,实现低延迟查询。
- 自定义实体定义:通过Pydantic模型灵活创建本体并支持开发者定义实体。
- 可扩展性:利用并行处理高效管理大型数据集。
应用场景
-
销售与客服:支持智能客服学习用户交互,融合个人知识与业务系统动态数据。
-
医疗健康:辅助医疗智能体执行复杂任务,基于多源动态数据进行推理。
-
金融领域:助力金融智能应用进行长期记忆和基于状态的推理。
-
getzep/graphiti: Build Real-Time Knowledge Graphs for AI Agents
2.通义万相-开源视频模型
简介
该链接指向ModelScope主页,提供模型、数据集、工作室等资源。包含快速入门指引,有本周热门模型、数据集和工作室展示。平台提供Studio用于构建和展示AI应用,还有开源框架辅助模型开发和应用构建,以及评估、训练推理等工具。
核心功能
- 模型与数据集展示:展示行业最新模型和数据集。
- 应用展示空间:Studio提供免费灵活的AI应用展示与构建空间。
- 框架工具支持:有Eval - Scope用于大模型评估,Swift用于大模型训练推理,ModelScope - Agent连接模型与外界。
技术原理
- 统一框架:ModelScope Library作为统一网关,实现高效模型推理、微调与评估。
- 模型托管:ModelHub作为开源中心,托管AI模型和数据集。
- 评估定制:Eval - Scope通过可定制框架进行大模型性能基准测试。
- 多模型支持:Swift支持多种模型和训练方式。
应用场景
-
模型开发:开发者基于平台模型和工具开发新AI模型。
-
应用构建:利用Studio构建和展示不同AI应用。
-
模型评估:使用Eval - Scope评估大模型性能。
-
模型比较:通过CompassArena体验和比较多款主流大模型效果。
2.字节BAGEL多模态模型

简介
BAGEL是字节跳动开源的多模态基础模型,拥有140亿参数(70亿活跃参数)。采用混合变换器专家架构(MoT),通过双编码器分别捕捉图像像素级和语义级特征,经海量多模态标记数据预训练。在多模态理解基准测试中超越部分顶级开源视觉语言模型,具备图像与文本融合理解、视频内容理解、文本到图像生成等多种功能。
核心功能
- 多模态交互:处理图像和文本的混合输入输出,支持对话交流。
- 内容生成:生成高质量图像、视频帧或图文交织内容。
- 图像编辑:进行自由形式的图像编辑,保留视觉细节。
- 风格迁移:转换图像风格。
- 导航功能:在不同环境中进行路径规划和导航。
- 多模态推理:融合多模态数据进行推理,完成复杂任务。
技术原理
- 架构设计:采用混合变换器专家架构(MoT),含两个独立编码器,分别处理图像像素级和语义级特征。
- 专家混合机制:编码器内有多个专家模块,动态选择合适专家组合处理多模态数据。
- 标记化处理:将多模态数据转化为标记,图像分割成小块,文本按单词或子词处理。
- 训练范式:遵循“下一个标记组预测”范式,用海量多模态标记数据预训练。
应用场景
- 内容创作:生成图像、视频,进行创意广告制作。
- 教育领域:可视化复杂概念,辅助学习。
- 电商平台:生成产品3D模型和虚拟展示,提升购物体验。
- 智能交互:支持图像和文本混合的对话交流。
- ByteDance-Seed/BAGEL-7B-MoT · Hugging Face
- ByteDance-Seed/Bagel
- BAGEL: The Open-Source Unified Multimodal Model
2.bytedance ContentV文生视频
简介
ContentV 是字节跳动推出的一个高效视频生成模型框架,其 8B 开源模型基于 Stable Diffusion 3.5 Large 和 Wan - VAE,在 256×64GB NPUs 上仅训练 4 周就在 VBench 测试中取得 85.14 的成绩。它通过创新架构、训练策略和反馈框架,能根据文本提示生成多分辨率、多时长的高质量视频。
核心功能
- 文本到视频生成:依据文本提示生成多样化、高质量视频。
- 保证视频质量:确保生成视频具有高时间一致性和视觉质量。
- 内容多样:可生成涵盖人类、动物、场景等多类别的视频。
技术原理
- 架构设计:采用简约架构,最大程度复用预训练图像生成模型进行视频合成。
- 训练策略:运用基于流匹配的系统多阶段训练策略,提升训练效率。
- 反馈框架:采用具成本效益的基于人类反馈的强化学习框架,在无需额外人工标注的情况下提高生成质量。
应用场景
-
影视制作:为影视创作提供视频素材和创意灵感。
-
广告宣传:快速生成各类产品宣传视频。
-
教育领域:制作教学视频,丰富教学内容。
-
ContentV: Efficient Training of Video Generation Models with Limited Compute
2.Matrix-Game空间大模型-昆仑万维
简介
Matrix - Game是一个拥有170亿参数的交互式世界基础模型,用于可控的游戏世界生成。它采用两阶段训练流程,先进行无标签预训练理解环境,再进行有动作标签的微调以实现交互式视频生成。配套有含细粒度动作注释的大规模Minecraft数据集Matrix - Game - MC。通过GameWorld Score基准评估,在多个指标上优于先前的开源Minecraft世界模型。
核心功能
- 交互式生成:基于扩散的图像到世界模型,根据键盘和鼠标输入生成高质量视频,实现细粒度控制和动态场景演变。
- 游戏世界评估:GameWorld Score基准,从视觉质量、时间质量、动作可控性和物理规则理解四个关键维度评估Minecraft世界模型。
- 支持大规模训练:Matrix - Game数据集支持交互式和基于物理的世界建模的可扩展训练。
- 精准控制:能精确控制角色动作和相机移动,保持高视觉质量和时间连贯性。
技术原理
Matrix - Game采用图像到世界的生成范式,以单张参考图像作为世界理解和视频生成的主要先验。使用自回归策略保持片段间的局部时间一致性,实现长时间视频生成。模型训练分两阶段,先无标签预训练理解环境,后有动作标签微调实现交互式视频生成。
应用场景
- 游戏开发:用于生成多样化Minecraft场景及其他虚幻引擎构建的游戏场景的高质量交互式视频。
- 游戏测试:通过评估模型的可控性和物理合理性,辅助测试游戏的操作体验和物理规则表现。
- SkyworkAI/Matrix-Game: Matrix-Game: Interactive World Foundation Model
- Matrix-Game: Interactive World Foundation Model
2.Step1X-3D 阶跃星辰 3D生成模型
简介
Step1X-3D 是一个专注于高质量、可控生成带纹理三维资产的开源框架。它旨在解决当前三维生成领域数据稀缺、算法局限性以及生态系统碎片化等挑战,通过先进的技术实现高保真几何和多样化纹理贴图的生成,并确保几何与纹理之间的高度对齐。
核心功能
- 高保真3D资产生成: 能够从单张图像生成具有高精细几何和多样纹理贴图的3D模型。
- 可控的几何与纹理: 支持对生成的3D模型进行控制,例如调整对称性、边缘类型(尖锐、普通、平滑)以及纹理风格(卡通、素描、照片级真实感)。
- 纹理与几何对齐: 确保生成的纹理与模型几何形状精确匹配,避免错位或不协调。
- 开放框架: 提供完整的模型、训练代码和适配模块,促进3D生成领域的开放研究和复现性。
技术原理
Step1X-3D 采用两阶段3D原生架构:
- 几何生成阶段: 使用混合3D VAE-DiT(变分自编码器-扩散Transformer)扩散模型生成截断有符号距离函数 (TSDF),随后通过行进立方体算法将其网格化,以构建高质量的3D几何。
- 纹理合成阶段: 利用经过微调的 SD-XL(Stable Diffusion XL)多视图生成器。该生成器以生成的几何和输入图像为条件,产生视图一致的纹理,并烘焙到3D模型上。 此外,该框架还包括一个严格的数据整理管道,处理并筛选出高质量的3D资产数据集,以支持模型训练。
应用场景
-
游戏开发: 快速生成游戏角色、道具和环境的3D模型,提高开发效率。
-
虚拟现实 (VR) / 增强现实 (AR): 创建沉浸式VR/AR体验所需的丰富3D内容。
-
数字艺术与设计: 为艺术家和设计师提供强大的工具,快速实现3D创意构想。
-
元宇宙构建: 自动化生成元宇宙中的各类数字资产。
-
工业设计与原型: 辅助产品设计与原型制作,实现快速迭代。
3.MoviiGen 1.1
简介
MoviiGen 1.1 是基于 Wan2.1 的尖端视频生成模型,在电影美学和视觉质量上表现出色。经专业人士评估,它在氛围营造、镜头运动和物体细节保留等关键电影维度表现卓越,能生成清晰度和真实感高的视频,适用于专业视频制作和创意应用。
核心功能
- 高质量视频生成:生成具有出色清晰度和细节的 720P、1080P 视频,保持视觉质量一致。
- 专业电影美学呈现:在氛围营造、镜头运动和物体细节保留方面表现优异。
- 支持提示扩展推理:可使用提示扩展模型优化生成效果。
技术原理
- 训练框架:基于 FastVideo,采用序列并行优化内存使用和训练效率,通过自定义实现将时间维度分配到多个 GPU,减少单设备内存需求。
- 数据处理:将视频和文本提示缓存为潜在变量和文本嵌入,减少训练阶段计算开销。
- 混合精度训练:支持 BF16/FP16 训练加速计算。
应用场景
-
专业影视制作:用于创作具有电影质感的视频内容。
-
创意设计领域:辅助设计师实现高保真的视觉创意。
-
虚拟现实和游戏:生成高质量的场景和角色动画。
-
ZulutionAI/MoviiGen1.1: MoviiGen 1.1: Towards Cinematic-Quality Video Generative Models
4.3D生成模型Partcrafter
简介
PartCrafter是首个结构化3D生成模型,可从单张RGB图像联合合成多个语义有意义且几何不同的3D网格。它基于预训练的3D网格扩散变压器,引入组合潜在空间和分层注意力机制,无需预分割输入,能同时对多个3D部分去噪,实现端到端的部件感知生成。研究还整理了新数据集支持部件级监督,实验表明其在生成可分解3D网格方面优于现有方法。
核心功能
- 多部件3D网格生成:从单张RGB图像一次性联合生成多个语义和几何不同的3D网格,可用于生成单个物体或复杂多物体场景。
- 端到端部件感知生成:无需图像分割输入,同时对多个3D部分去噪,实现端到端的部件感知生成。
- 支持不可见部件生成:能够自动推断输入图像中不可见的3D结构。
技术原理
- 基于预训练模型:构建于在完整物体上训练的预训练3D网格扩散变压器(DiT),继承预训练权重、编码器和解码器。
- 组合潜在空间:每个3D部分由一组解纠缠的潜在令牌表示,添加可学习的部件身份嵌入区分不同部件。
- 分层注意力机制:包括局部注意力和全局注意力,局部注意力捕获每个部件内的局部特征,全局注意力实现所有部件间的信息流动,确保生成过程中的全局一致性和部件级细节。
- 训练目标:通过整流流匹配训练,将噪声高斯分布映射到数据分布。
应用场景
-
3D建模与设计:辅助设计师快速从2D图像生成具有多个部件的3D模型,提高设计效率。
-
游戏与动画制作:用于生成游戏和动画中的3D场景和物体,丰富场景内容和物体细节。
-
机器人训练:提供准确和部件感知的3D表示,帮助机器人更好地理解和与环境交互。
-
虚拟和增强现实:为VR/AR应用生成高质量的3D场景和物体,提升用户体验。
-
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
4.OmniAudio空间音频生成
简介
OmniAudio是一个用于从360度视频生成一阶Ambisonics(FOA)空间音频的框架。论文作者提出了360V2SA新任务,构建了大规模数据集Sphere360,采用自监督预训练和双分支架构,在客观和主观指标上均达到了最先进的性能。项目网站提供相关信息,GitHub仓库提供代码。
核心功能
- 空间音频生成:从360度视频中生成FOA格式的空间音频,准确捕捉声音的方向和空间信息。
- 数据处理:构建并清理Sphere360数据集,包含103,000个真实世界的视频片段,涵盖288种音频事件。
- 模型训练:采用自监督的粗到细预训练策略,结合非空间和空间音频数据进行预训练,然后进行视频引导的微调。
技术原理
- 条件流匹配:使用时间相关的速度向量场,通过最小化目标函数来训练模型,生成从噪声到数据的概率路径。
- 变分自编码器(VAE):对FOA音频进行编码和解码,通过修改Stable Audio框架,适应四通道FOA音频。
- 双分支视频表示:利用冻结的预训练MetaCLIP - Huge图像编码器,分别处理全景视频和透视视频,融合两种表示以捕捉局部和全局信息。
应用场景
-
虚拟现实和增强现实:为VR/AR体验提供更真实的音频环境,增强沉浸感。
-
内容创作:帮助创作者轻松为视频添加音效、背景音乐或旁白。
-
教育和培训:为教育视频自动生成音频解释,使学习体验更具吸引力。
-
历史保护:为无声的历史镜头添加生成的音频,重现历史场景。
4.PlayDiffusion音频编辑
简介
PlayDiffusion是Play.AI推出的一款基于扩散模型的音频编辑模型,已开源。它解决了传统自回归模型在音频编辑时的局限性,能实现高质量、连贯的音频编辑,还可作为高效的文本转语音系统。
核心功能
- 音频编辑:对音频特定部分进行修改、替换,且能保持音频连贯性和自然度。
- 文本转语音:在全音频波形被掩码的极端情况下,可作为高效的TTS系统。
技术原理
- 编码与掩码:将音频序列编码为离散空间的令牌,修改时掩码相应部分。
- 扩散模型去噪:以更新后的文本为条件,用扩散模型对掩码区域去噪。
- 解码转换:通过BigVGAN解码器将输出令牌序列转换为语音波形。
- 训练优化:采用非因果掩码、自定义分词器和嵌入缩减、说话人条件等技术训练模型。
应用场景
-
音频内容创作:对已有音频进行精细修改和调整。
-
有声读物制作:将文本高效转换为语音。
-
语音交互系统:优化语音合成的质量和效率。
5.多人对话视频框架
简介
MultiTalk是用于音频驱动的多人对话视频生成的开源框架。输入多流音频、参考图像和提示词,可生成包含符合提示的互动且嘴唇动作与音频一致的视频。它支持单人和多人视频生成、交互式角色控制、卡通角色和唱歌视频生成,具有分辨率灵活、可生成长达15秒视频等特点。
核心功能
- 生成对话视频:支持单人和多人对话视频生成,实现嘴唇动作与音频同步。
- 角色交互控制:通过提示词直接控制虚拟人物动作。
- 泛化性能佳:支持卡通角色和唱歌视频生成。
- 灵活分辨率:可输出480p和720p任意宽高比视频。
- 长视频生成:支持长达15秒视频生成。
技术原理
- 基础架构:采用基于DiT的视频扩散模型,结合3D变分自编码器(VAE),利用文本编码器生成文本条件输入,通过解耦交叉注意力将CLIP图像编码器提取的全局上下文注入DiT模型。
- 音频嵌入提取:使用Wav2Vec提取声学音频嵌入,并将当前帧附近的音频嵌入拼接。
- 音频适配压缩:在音频交叉注意力层,通过音频适配器对音频进行压缩,使视频潜在帧长度与音频嵌入匹配。
- 多流音频注入:提出四种注入方案,引入自适应人物定位方法和L - RoPE方法解决音频与人物绑定问题。
- 训练策略:采用两阶段训练、部分参数训练和多任务训练,保留基础模型的指令跟随能力。
- 长视频生成:采用基于自回归的方法,将先前生成视频的最后5帧作为额外条件进行推理。
应用场景
- 影视制作:用于制作多角色电影场景。
- 电商直播:生成主播与观众互动的视频。
- 动画创作:创作卡通角色对话、唱歌的动画视频。
- MeiGen-AI/MultiTalk: Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
- MeiGen-AI/MeiGen-MultiTalk · Hugging Face
- arxiv.org/pdf/2505.22647
- multi-talk官网
5.趣丸科技-人脸动画生成
简介
Playmate 是一个通过3D隐式空间引导扩散模型实现人像动画灵活控制的框架。它旨在解决现有口型同步、头部姿态不准确以及缺乏精细表情控制等挑战,从而生成高质量、可控的逼真说话人脸视频。
核心功能
- 逼真说话人脸生成: 能够根据音频输入生成高度逼真的说话人脸视频。
- 精准唇形同步: 显著提高视频中人物唇部动作与语音的同步准确性。
- 灵活头部姿态控制: 允许用户对生成视频中的头部姿态进行精确调整和控制。
- 精细情感表达控制: 通过情感控制模块,实现对生成视频中人物情感的细粒度控制。
- 两阶段训练框架: 采用分阶段训练方法,优化属性解耦和运动序列生成。
技术原理
Playmate 采用一个两阶段训练框架,核心是3D隐式空间引导扩散模型。
- 第一阶段: 利用**运动解耦模块(motion-decoupled module)增强属性解耦的准确性,并训练一个扩散变换器(diffusion transformer)**直接从音频线索生成运动序列。这一阶段专注于运动的生成和解耦。
- 第二阶段: 引入一个情感控制模块(emotion-control module),将情感控制信息编码到潜在空间中。这使得系统能够对表情进行精细控制,从而生成具有所需情感的说话视频。整个过程结合了扩散模型的强大生成能力与3D隐式空间的精细表征能力,以实现高度可控的视频合成。
应用场景
-
虚拟数字人/AI主播: 创建具有高度表现力和情感的虚拟数字人形象,用于新闻播报、直播、客户服务等。
-
影视动画制作: 辅助电影、电视或游戏中的角色口型动画和表情生成,提高制作效率和真实感。
-
个性化内容创作: 用户可以根据需求,生成特定人物、声音和情感的个性化视频内容。
-
教育培训: 制作生动形象的教育讲解视频,提升学习体验。
-
语音助手/虚拟客服: 为语音助手或虚拟客服系统提供更加拟人化的视觉交互体验。
Kwai Keye VL 快手
简介
Kwai-Keye专注于多模态大语言模型的前沿探索与创新,致力于推动视频理解、多模态大语言模型等领域的发展。其Keye-VL-8B模型基于Qwen3 - 8B语言模型和SigLIP视觉编码器,在视频理解、复杂逻辑推理等方面表现出色。此外,团队还有多项研究成果,如MM - RLHF、VLM as Policy等。
核心功能
- 多模态交互:支持图像、视频和文本的交互,能对图像和视频进行描述等操作。
- 视频理解:在多个视频基准测试中超越同规模顶级模型。
- 复杂推理:在需要复杂逻辑推理和数学问题解决的评估集中有良好表现。
- 内容审核:如提出的KuaiMod框架可用于短视频平台内容审核。
技术原理
- 模型架构:基于Qwen3 - 8B语言模型,结合从开源SigLIP初始化的视觉编码器,采用3D RoPE统一处理文本、图像和视频信息。
- 预训练:采用四阶段渐进策略,包括图像 - 文本匹配、ViT - LLM对齐、多任务预训练和模型合并退火。
- 后训练:分两个阶段五个步骤,引入混合思维链(CoT)和多思维模式强化学习(RL)机制。
应用场景
-
智能客服:处理包含图像和视频的用户咨询。
-
视频平台:视频内容理解、审核和推荐。
-
教育领域:辅助解决复杂的数学和科学问题。
-
内容创作:根据图像和视频生成描述和创意内容。
OmniAvatar浙大阿里视频生成
简介
OmniAvatar是一种创新的音频驱动全身视频生成模型,旨在解决现有音频驱动人类动画方法在创建自然同步、流畅的全身动画以及精确提示控制方面的挑战。它引入像素级多层次音频嵌入策略,结合基于LoRA的训练方法,提高了唇同步准确性和身体动作的自然度,在面部和半身视频生成方面超越现有模型,可用于播客、人类交互、动态场景和唱歌等多种领域。
核心功能
- 高质量视频生成:根据单张参考图像、音频和提示,生成具有自适应和自然身体动画的逼真会说话的头像视频。
- 精准唇同步:通过像素级多层次音频嵌入策略,实现音频与唇部动作的精确同步。
- 文本控制:支持精确的基于文本的控制,可控制角色的动作、表情、背景等。
- 身份和时间一致性:利用参考图像嵌入策略保持身份一致,使用潜在重叠策略确保长时间视频生成的时间连续性。
技术原理
- 扩散模型:采用潜在扩散模型(LDM)进行高效视频生成,在潜在空间中逆转扩散过程,将噪声逐步转化为数据。
- 音频嵌入:提出像素级音频嵌入策略,使用Wav2Vec2提取音频特征,通过音频包模块将音频特征映射到潜在空间,并在像素级别嵌入到视频潜在空间。
- LoRA训练:对DiT模型的层应用基于LoRA的训练,在保留基础模型强大功能的同时,有效结合音频作为新条件。
- 长视频生成:利用帧重叠和参考图像嵌入策略,保持长视频生成的一致性和时间连续性。
应用场景
- 播客制作:生成主播的视频内容,提升播客的视觉效果。
- 虚拟社交:用于虚拟人物的交互视频,增强社交体验。
- 动态场景模拟:如游戏、影视等领域,生成角色的动画视频。
- 音乐表演:生成歌手唱歌的视频,实现音频与动作的同步。
- 项目链接:
OmniGen2 智源研究院
简介
OmniGen2 是一款多功能开源生成模型,旨在为文本到图像、图像编辑和上下文生成等多种生成任务提供统一解决方案。它具有两条不同的文本和图像模态解码路径,采用非共享参数和分离的图像分词器。研究团队开发了全面的数据构建管道,引入了用于图像生成任务的反射机制和专门的反射数据集。此外,还推出了 OmniContext 基准测试,用于评估模型的上下文生成能力。
核心功能
- 多模态生成:支持文本到图像生成、图像编辑和上下文生成等多种任务。
- 反射机制:能够对生成的图像进行反思,识别不足并迭代优化输出。
- 数据构建:开发了用于图像编辑和上下文生成的数据构建管道,生成高质量数据集。
- 基准测试:引入 OmniContext 基准测试,评估模型在上下文图像生成中的一致性。
技术原理
- 架构设计:采用独立的自回归和扩散变压器架构,使用 ViT 和 VAE 两种不同的图像编码器。
- 位置嵌入:引入 Omni - RoPE 多模态旋转位置嵌入,分解为序列和模态标识符、2D 空间高度和宽度坐标三个组件。
- 训练策略:MLLM 大部分参数冻结,仅更新特殊令牌;扩散模型从头开始训练,采用混合任务训练策略。
- 数据处理:使用多种开源图像数据集进行训练,通过视频数据构建上下文生成和图像编辑数据集。
应用场景
- 创意设计:根据文本描述生成图像,为设计师提供灵感和素材。
- 图像编辑:对现有图像进行修改,如改变背景、移除对象、调整风格等。
- 虚拟现实/增强现实:生成与上下文相关的图像,用于 VR/AR 场景的内容创建。
- 智能客服:根据用户描述生成图像,更直观地回答问题。
FairyGen 动画生成
简介
FairyGen是一个用于从单个儿童手绘角色生成动画故事视频的新颖框架。它借助多模态大语言模型进行故事规划,通过风格传播适配器确保视觉一致性,利用3D代理生成物理上合理的运动序列,并采用两阶段运动定制适配器实现多样化和连贯的视频场景渲染,在风格、叙事和运动方面表现出色。
核心功能
- 故事与分镜规划:利用MLLM从给定角色草图推断结构化分镜,进行时空分镜规划。
- 风格一致背景合成:通过定制风格传播模块,将角色的审美特征传播到背景,生成风格一致的背景。
- 3D代理角色视频序列生成:从2D角色图像重建3D代理,导出物理上合理的运动序列,用于微调图像到视频的扩散模型。
- 两阶段运动定制:第一阶段从无序帧学习外观特征,分离身份和运动;第二阶段使用时间步移策略建模时间动态,生成多样化和连贯的视频场景。
技术原理
- 故事规划:使用MLLM生成结构化分镜,包含全局叙事概述和详细的分镜描述。
- 风格传播:基于预训练的文本到图像扩散模型,采用基于传播的定制策略,在训练时学习角色视觉风格,推理时将其传播到背景。
- 3D重建:从2D草图重建角色的3D代理,导出运动序列,作为训练数据微调MMDiT-based图像到视频扩散模型。
- 两阶段运动定制:第一阶段去除时间偏置,学习空间特征;第二阶段使用时间步移采样策略,增加采样高噪声训练步骤的概率,学习鲁棒的运动表示。
应用场景
-
教育领域:将儿童绘画转化为动画故事,激发儿童想象力和创造力。
-
数字艺术治疗:帮助患者通过绘画和动画表达情感和想法。
-
个性化内容创作:为用户生成个性化的动画故事视频。
-
互动娱乐:为游戏、动漫等娱乐产业提供创意内容。
-
论文:FairyGen: Storied Cartoon Video from a Single Child-Drawn Character
HumanOmniV2-阿里
简介
HumanOmniV2 是阿里通义实验室开源的多模态推理模型,解决了多模态推理中全局上下文理解不足和推理路径简单的问题。它能在生成答案前分析视觉、听觉和语言信号,构建场景背景,精准捕捉隐藏逻辑和深层意图。该模型在 IntentBench 等基准测试中表现出色,现已开源。
核心功能
- 全面理解多模态信息:综合分析图像、视频、音频等多模态输入,捕捉隐藏信息和深层逻辑。
- 精准推理人类意图:基于上下文背景,准确理解对话或场景中的真实意图。
- 生成结构化推理路径:输出详细的上下文总结和推理步骤,确保推理可解释。
- 应对复杂社交场景:识别理解人物情绪、动机及社会关系,提供符合人类认知的判断。
技术原理
- 强制上下文总结机制:输出 标签内的上下文概括,构建完整场景背景。
- 大模型驱动的多维度奖励体系:包含上下文、格式、准确性和逻辑奖励,激励模型准确推理。
- 基于 GRPO 的优化训练方法:引入词元级损失,移除问题级归一化项,应用动态 KL 散度机制。
- 高质量的全模态推理训练数据集:包含图像、视频和音频任务,附带详细标注。
- 全新的评测基准 IntentBench:评估模型对人类行为动机、情感状态和社会互动的理解能力。
应用场景
- 视频内容理解与推荐:为视频平台提供精准推荐。
- 智能客服与客户体验优化:帮助客服人员应对客户问题。
- 情感识别与心理健康支持:辅助心理健康应用提供情绪支持。
- 社交互动分析与优化:优化社交推荐和用户互动体验。
- 教育与个性化学习:为在线教育平台提供个性化学习建议。
- github地址:AI-Compass👈:https://github.com/tingaicompass/AI-Compass
- gitee地址:AI-Compass👈:https://gitee.com/tingaicompass/ai-compass
🌟 如果本项目对您有所帮助,请为我们点亮一颗星!🌟

