
一文搞懂前端监控
公众号:程序员白特,欢迎一起交流学习~
原文:一文搞懂前端监控 - 掘金 (juejin.cn)
前端监控在项目维护过程中至关重要。监控的核心目标包括及时发现问题和快速定位问题所在。尽管各公司所用的前端监控工具和服务可能各有不同,但从业务开发者角度来看,它们都具有一些共通之处。
一个完善的前端上报服务工具应该包含以下功能:
- 累积量上报:每次上报触发都对计数器进行累加。
- 日志上报:将详细的埋点信息上报到服务端,可以分为全量上报和本地缓存上报。
- 错误上报:捕获 JavaScript 错误并将错误信息进行收集上报到服务端,通常使用 window.onerror 实现。
- 耗时上报:对关键阶段的耗时进行收集上报,用于性能分析。
告警策略是及时发现问题的重要手段,一个完善的前端上报服务工具应该包含以下告警策略:
- 有则告警:一旦有上报就会触发告警,适用于一些重要异常上报。
- 阈值告警:当一段时间内(如每分钟)的上报量达到设定的阈值时触发告警,比如关键后台接口失败量的最大值上报。阈值可以根据数量或者百分比来设定。阈值上报可分为最小值阈值和最大值阈值。
- 波动告警:用于监控指标的变化和波动情况。当指标超出正常范围时,快速发现问题并采取相应措施。
PV/UV上报
PV(页面访问量)指的是页面被浏览的次数,而UV(独立访客数)表示访问网站的实际用户数量。这两种上报可以使用累积量上报。
PV上报除了用于业务分析外,还可以设置告警来及时发现问题。
- PV波动告警:当PV的波动轨迹出现异于正常的波动时触发告警,这适用于波动变化具有一定规律性的页面。
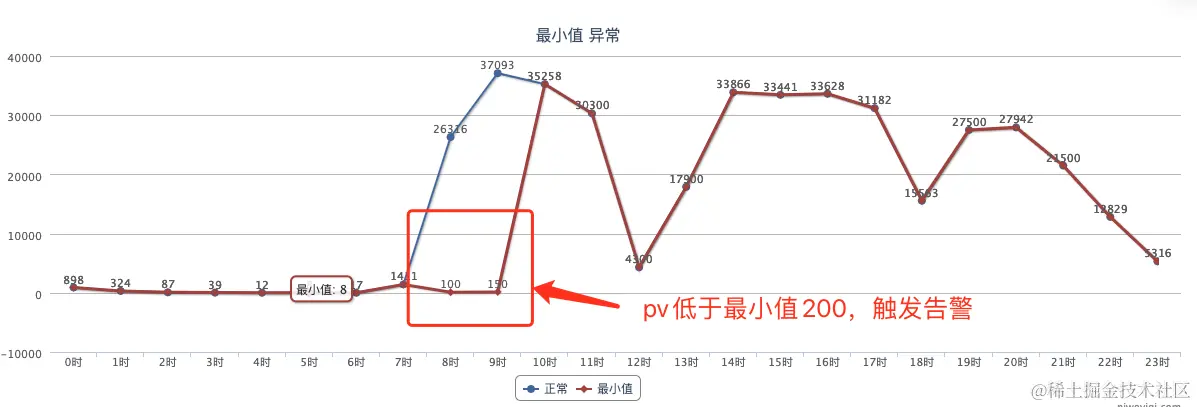
- PV最小值阈值告警:当PV值低于某个阈值时触发告警。
举例来说,对于这样的B端页面,在配置波动告警时,可以作如下考量:由于用户通常会在工作日使用该页面,因此可以通过比较每天的PV数据与相应的上周同一工作日的数据,来触发波动告警。
例如,如果今天是周四,可与上周同一天(也是周四)的PV数据进行对比,以便在异常波动出现时触发告警:
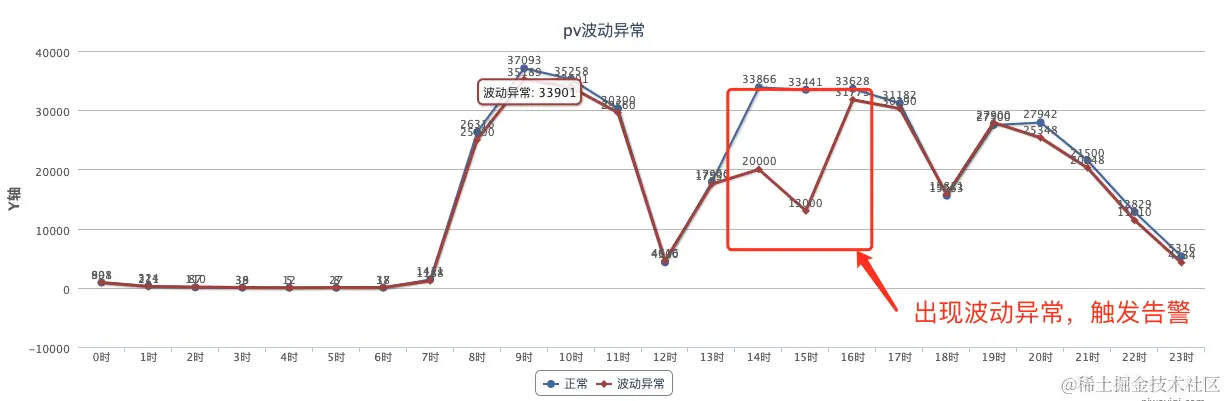
另外一种告警是最小值阈值告警,告警策略配置了每天8点以后pv低于200时告警:
JS错误上报
JS错误经常是导致页面无法访问的主要原因。通过使用 window.onerror、document.addEventlistener(error)、XMLHttpRequest status 等方式,可以捕获并上报JS错误,以便获取页面的错误信息及错误堆栈。大多数前端上报工具的SDK都已内置了上报错误的功能,因此这里不再赘述。
在JS错误上报过程中,通常会配合使用sourcemap,这有助于我们找到错误发生的确切位置。
另一个问题是错误上报产生的噪音。噪音指的是诸如不会影响页面正常使用的报错。错误上报的噪音并不能完全消除,通常采用忽略这些错误的方式来处理。
日志上报
日志上报对于快速定位问题而言至关重要。通常情况下,业务开发者需要自行进行日志上报。在哪些区域进行日志上报能够很好地考验一个前端开发者的经验与能力。
链路日志上报
其中一种思路是根据首屏加载链路,对各个阶段添加 info 级别的日志。例如:
- html 开始加载成功
- css 加载成功
- index.js 加载成功
- 后台接口请求成功
- 图片请求成功
- 各种点击事件
当页面出现问题时,例如白屏问题,可以查看上述链路的日志,检查是否有日志阻塞,结合错误上报进行排查,可以大致定位到错误的位置。
异常日志上报
有一些错误信息,如 WebSocket API 的 onerror 事件,或某些第三方 NPM 包自行使用 try-catch 后暴露的 error 事件,是无法被 window.onerror 等方法拦截到的。对于这些异常信息,需要进行手动上报,例如:
import logger from 'your_logger_package';
const ws = new WebSocket("wss://mywebsocket.com");
ws.onerror = function(error) {
logger.error(`websocket连接失败: ${error}`)
};
这些错误可以根据需要添加"有则告警"或"阈值告警"等告警策略。
白屏上报
白屏上报是一种非常特殊且普遍的异常上报方式。白屏指的是用户在访问页面时,页面长时间保持空白(白屏)状态的问题。这种情况会给用户带来非常糟糕的体验,因此及时让开发人员了解并做出响应至关重要。
"白屏"的判断方法可以参考文章 前端白屏的检测方案,让你知道自己的页面白了 中关于采样对比的方案。它的大致思路是在页面中间选取17个样本点形成十字形排列,在一段时间后判断这些采样点的最上层元素是否是容器元素,如['html', 'body', '#app', '#root']。如果所有采样点的最上层元素都是容器元素,则可以确定页面出现了白屏。
白屏上报有许多不同的时机策略,其中一种是每隔一秒钟轮询判断是否白屏并上报,这种策略相对消耗页面性能。另一种策略是选择几个时间点,例如10秒后的若干时间点,在这些有限的时间点进行上报。
// 判断是否白屏
const whiteScreen = () => {
// 该代码请参考 "前端白屏的检测方案,让你知道自己的页面白了" 文章
// 此时不再重复
};
window.addEventListener("load", () => {
// 白屏上报时机是10秒、15秒、20秒
const intervals = [10, 15, 20];
// 白屏上报的时间间隔,如果遇到一个非白屏的时间点,则不再上报
const runTime = (index) => {
const frontSecond = intervals[index - 1] || 0;
const curSecond = intervals[index];
const diffSecond = curSecond - frontSecond;
if (diffSecond > 0) {
setTimeout(() => {
// 如果是白屏则上报,且进入下个时间点的白屏上报
if (isWhiteScreen(containerSelectors)) {
logger.error(`白屏${curSecond}秒`);
runTime(index + 1);
}
}, diffSecond * 1000);
}
};
runTime(0);
});
同样地,白屏上报也可以配置“有则告警”或“阈值告警”的告警策略。
日志存储方案
对于日志存储,有两种主要方案:
- 服务器存储:所有日志直接以全量上报的方式存储到日志服务器。当页面 PV 较大时,将上报的日志量较多,可能会给日志服务带来较大压力。
- 本地存储:大部分日志存储到浏览器本地,通常使用 IndexDB 作为缓存存储。在用户出现问题时,给用户标记,并等用户下次请求时将日志尽数上报到服务器。
随着日志量的增长,存储服务的成本也会越高。出于成本控制与效率提升的目的,我个人更倾向于采用本地存储的上报方式,因为大部分日志并非都是有用的。在用户出现问题时标记用户再进行日志收集,通常已经足够应对问题。
性能上报
作为程序员,最令人担忧的情况之一就是用户能够重现问题,但自己却无法重现。性能问题也是类似,本来在自己的设备上表现良好,但用户却可能遇到页面加载缓慢的情况。在这种时候,性能上报就成了重要的救命工具。
web vitals 上报
性能上报最简单的方式是使用谷歌推出的核心 Web 体验指标(Core Web Vitals),只需使用 Web Vitals 的 NPM 包即可实现。需要特别关注的指标包括:
- LCP(Largest Contentful Paint):表示页面上最大的内容块(如文本块或图像)渲染完成并出现在用户视野中的时间,衡量页面的视觉加载速度。
- FID(First Input Delay):指页面首次交互的延迟时间,即用户首次与页面交互到浏览器实际能够响应的时间。
- CLS(Cumulative Layout Shift):反映页面元素的不稳定性,衡量用户在浏览页面时遇到的视觉布局变化的程度。
- FCP(First Contentful Paint):指浏览器将第一个 DOM 渲染到屏幕的时间,可以是任何文本、图像、SVG 等内容的时间。
Web Vitals 的上报可以通过耗时上报来实现。
链路耗时上报
Web Vitals 能够帮助我们了解性能出现问题的情况,然而要知道具体出现了什么问题则相对困难。在这种情况下,我们需要对页面的各个阶段进行细化,并对每个阶段进行耗时上报,以缩小问题出现的范围。可以通过 Chrome 的性能工具分析页面的大致加载链路,进而了解页面整个加载过程中各个阶段的性能情况。

抽象出这种性能链路后,可以基于业务需求自定义关注的各个阶段,并统计这些阶段的耗时。例如,对于上述的单页面应用链路,可以上报以下信息:
- 前置JS资源请求耗时
- 页面JS请求耗时
- 后台接口耗时
- 图片加载耗时
通过细化各个阶段的耗时后,一旦页面变慢,可以提取这些耗时数据,以查看哪个阶段出现了问题,进而确定性能瓶颈所在。
链路耗时上报的另一个用途在于防劣化:一轮性能优化后,后续的需求更新可能会对性能产生影响。因此,对各个环节的耗时设置最大阈值告警,一旦超过阈值,便能够立即追踪是哪次更新导致的问题,然后及时进行修复。
其他上报
除了上述提到的上报方式,根据业务需求还有其他方式可以进行上报:
- 后台接口异常上报
- 卡顿上报:使用 PerformanceObserver 判断页面是否出现卡顿现象。
- 资源错误上报
- 资源被篡改上报:通过 script 标签的 integrity 属性,判断页面资源是否被篡改,以确定资源是否遭到劫持。
总结
项目上线后,等真正有用户的反馈故障时实际上已经为时已晚了,这时前端监控显示出了它真正的价值。前端监控需要配合公司中现有的上报服务来实现,无需将监控做到尽善尽美,而是可以根据不同的情况做出取舍。
#前端##如果可以选,你最想去哪家公司##我的实习求职记录##实习,投递多份简历没人回复怎么办##我的求职思考#