二分法算法题
- 基础知识:二分法是用来解法基本模板,时间复杂度logN;常见的二分法题目可以分为两大类,显式与隐式,即是否能从字面上一眼看出二分法的特点:要查找的数据是否可以分为两部分,前半部分为X,后半部分为O
- 显式二分法:
Leetcode 34. Find First and Last Position of Element in Sorted Array
Leetcode 33. Search in Rotated Sorted Array
Leetcode 1095. Find in Mountain Array
Leetcode 162. Find Peak Element
Leetcode 278. First Bad Version
Leetcode 74. Search a 2D Matrix
Leetcode 240. Search a 2D Matrix II
- 隐式二分法:
Leetcode 69. Sqrt(x)
Leetcode 540. Single Element in a Sorted Array
Leetcode 644. Maximum Average Subarray II
Leetcode 528. Random Pick with Weight
Leetcode 1300. Sum of Mutated Array Closest to Target
Leetcode 1060. Missing Element in Sorted Array
Leetcode 1062. Longest Repeating Substring
Leetcode 1891. Cutting Ribbons
Leetcode 34. Find First and Last Position of Element in Sorted Array
题目描述
给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
进阶:
你可以设计并实现时间复杂度为 O(log n) 的算法解决此问题吗?
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8 输出:[3,4]
示例 2:
输入:nums = [5,7,7,8,8,10], target = 6 输出:[-1,-1]
示例 3:
输入:nums = [], target = 0 输出:[-1,-1]
提示:
0 <= nums.length <= 105 -109 <= nums[i] <= 109 nums 是一个非递减数组 -109 <= target <= 109
解法
本题可以使用二分查找的思路解决。首先找到目标值在数组中的任意一个位置,然后分别向左和向右扩展,直到找到目标值在数组中的开始位置和结束位置。
具体来说,我们可以先使用二分查找找到目标值在数组中的任意一个位置。如果该位置不存在目标值,则返回 [-1,-1]。如果该位置存在目标值,则从该位置向左和向右分别进行线性扩展,直到找到目标值在数组中的开始位置和结束位置。
代码
class Solution {
public int[] searchRange(int[] nums, int target) {
int left = 0, right = nums.length - 1;
int mid = -1;
while (left <= right) {
mid = left + (right - left) / 2;
if (nums[mid] == target) {
break;
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
if (left > right) {
return new int[]{-1, -1};
}
int start = mid, end = mid;
while (start >= 0 && nums[start] == target) {
start--;
}
while (end < nums.length && nums[end] == target) {
end++;
}
return new int[]{start + 1, end - 1};
}
}
复杂度分析
时间复杂度:,其中 是数组的长度。二分查找的时间复杂度是 ,线性扩展的时间复杂度也是 。
空间复杂度:。只需要常数空间存储若干变量。
Leetcode 33. Search in Rotated Sorted Array
题目描述
给你一个升序排列的整数数组 nums ,和一个整数 target 。
数组中的每个元素在值上都存在 唯一 的差异。同样地,给你一个按升序排列的整数数组 targetArr 。
你需要从 nums 中找出一个子数组 ,这个子数组将原数组变为 targetArr 。
请你找出这个子数组,并返回它的长度。如果不存在符合题意的子数组,返回 0 。
示例 1:
输入:nums = [1,2,3,4,5,6], target = [6,5,4,3,2,1] 输出:6 解释:'6,5,4,3,2,1' 是 '1,2,3,4,5,6' 的一个子数组。
示例 2:
输入:nums = [1,2,3,4,5,6], target = [6,5,4,3,2,2] 输出:0 解释:无法找到和 targetArr 完全相同的子数组。
示例 3:
输入:nums = [1], target = [1] 输出:1 解释:nums 和 targetArr 都只含有一个元素,所以子数组长度均为 1 。
提示:
1 <= nums.length, target.length <= 10^5 1 <= nums[i], target[i] <= 10^9
解法
本题可以使用双指针来解决。我们可以先找到 target 数组中的第一个元素在 nums 数组中的位置,然后从这个位置开始向后遍历,同时也从 target 数组的第二个元素开始向后遍历,如果当前两个元素相同,则继续向后遍历,否则就记录当前的位置,并继续从 target 数组的第二个元素开始向后遍历。
如果遍历完整个 target 数组,都没有找到符合条件的子数组,则返回 0。
代码
class Solution {
public int maxSubArray(int[] nums) {
int n = nums.length;
int left = 0, right = 0;
int targetIndex = 0, targetLen = nums.length;
while (targetIndex < targetLen && left < n) {
if (nums[left] == target[targetIndex]) {
targetIndex++;
}
left++;
}
if (targetIndex != targetLen) {
return 0;
}
left--;
right = left + 1;
int len = 1;
while (right < n && targetIndex < targetLen) {
if (nums[right] == target[targetIndex]) {
targetIndex++;
len++;
}
right++;
}
return len == targetLen ? len : 0;
}
}
复杂度分析
时间复杂度:,其中 是 nums 数组的长度。最坏情况下,我们需要遍历整个 nums 数组一次,时间复杂度为 。
空间复杂度:,我们只需要常数级别的空间来存储一些变量。
Leetcode 1095. Find in Mountain Array
题目描述
(本题与 二分查找 相似,但数据规模更大。)
给定一个山脉数组 mountainArr,先按照山脉数组的规则(即先升序后降序)排序,找出其中的一个最大值,然后再在这个山脉数组中找到目标值。最后返回在这个山脉数组中找到目标值的下标。
我们可以先把山脉数组看成两部分,先升序后降序的部分,我们称之为“山顶”,山顶左边的部分称之为“左半边”,山顶右边的部分称之为“右半边”。
注意:
- 如果山脉数组中没有这个目标值,返回 -1。
- 如果山脉数组中存在多个目标值,只需返回其中任意一个即可。
提示:
示例 1:
输入:array = [1,2,3,4,5,3,1], target = 3
输出:2
解释:3 在数组中出现了两次,下标分别为 2 和 5,我们返回其中的任意一个。
示例 2:
输入:array = [0,1,2,4,2,1], target = 3
输出:-1
解释:3 在数组中没有出现,返回 -1。
解法
二分查找。
首先找到山顶的位置,然后在左半边和右半边分别进行二分查找即可。
具体实现细节见代码。
代码
/**
* // This is MountainArray's API interface.
* // You should not implement it, or speculate about its implementation
* interface MountainArray {
* public int get(int index) {}
* public int length() {}
* }
*/
class Solution {
public int findInMountainArray(int target, MountainArray mountainArr) {
int n = mountainArr.length();
int peak = findPeak(mountainArr, 0, n - 1);
int index = binarySearch(mountainArr, 0, peak, target);
if (index != -1) {
return index;
}
return binarySearch(mountainArr, peak + 1, n - 1, target);
}
private int findPeak(MountainArray mountainArr, int left, int right) {
while (left < right) {
int mid = left + (right - left) / 2;
if (mountainArr.get(mid) < mountainArr.get(mid + 1)) {
left = mid + 1;
} else {
right = mid;
}
}
return left;
}
private int binarySearch(MountainArray mountainArr, int left, int right, int target) {
while (left <= right) {
int mid = left + (right - left) / 2;
int midValue = mountainArr.get(mid);
if (midValue == target) {
return mid;
} else if (midValue < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
}
复杂度分析
时间复杂度:,其中 是山脉数组的长度。找到山顶的时间复杂度是 ,在左半边和右半边分别进行二分查找的时间复杂度也是 。
空间复杂度:。
Leetcode 162. Find Peak Element
题目描述
峰值元素是指其值大于左右相邻值的元素。
给定一个输入数组 nums,其中 nums[i] ≠ nums[i+1],找到峰值元素并返回其索引。
数组可能包含多个峰值,在这种情况下,返回任何一个峰值所在位置即可。
你可以假设 nums[-1] = nums[n] = -∞。
示例 1:
输入: nums = [1,2,3,1] 输出: 2 解释: 3 是峰值元素,你的函数应该返回其索引 2。
示例 2:
输入: nums = [1,2,1,3,5,6,4] 输出: 1 或 5 解释: 你的函数可以返回索引 1,其峰值元素为 2; 或者返回索引 5, 其峰值元素为 6。
说明:
你的解法应该是 O(logN) 时间复杂度的。
解法
这是一道二分查找的题目。
我们首先找到中间元素 mid,如果它的值大于其右侧的元素,那么左半部分一定存在峰值,我们在左半部分继续查找即可;同理,如果 mid 的值小于其右侧的元素,那么右半部分一定存在峰值,我们在右半部分继续查找即可。最终,我们就能找到一个峰值。
代码
class Solution {
public int findPeakElement(int[] nums) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] > nums[mid + 1]) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
}
复杂度分析
时间复杂度:,其中 是数组的长度。每次二分查找可以将查找范围缩小一半,因此最多需要进行 次二分查找。
空间复杂度:。我们只需要常数级别的额外空间来存储变量。
Leetcode 278. First Bad Version
题目描述
你是产品经理,目前正在领导一个团队开发一个新产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误版本之后的所有版本都是错的。
假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例 1:
输入:n = 5, bad = 4
输出:4
解释:
调用 isBadVersion(3) -> false
调用 isBadVersion(5) -> true
调用 isBadVersion(4) -> true
所以,4 是第一个错误的版本。
示例 2:
输入:n = 1, bad = 1
输出:1
提示:
1 <= bad <= n <= 231 - 1
解法
本题可以使用二分查找来解决。由于错误版本之后的所有版本都是错的,因此可以将问题转化为在区间 [1, n] 中查找第一个满足某个条件的数,即第一个错误版本。
具体来说,可以使用二分查找的方法,在每次查找时都判断中间位置 mid 是否是错误版本。如果是,则说明第一个错误版本在 [left, mid] 区间内,否则说明第一个错误版本在 [mid+1, right] 区间内。
代码
public class Solution extends VersionControl {
public int firstBadVersion(int n) {
int left = 1, right = n;
while (left < right) {
int mid = left + (right - left) / 2;
if (isBadVersion(mid)) {
right = mid;
} else {
left = mid + 1;
}
}
return left;
}
}
复杂度分析
时间复杂度:,其中 是版本的数量。二分查找的时间复杂度是 。
空间复杂度:。使用了常数级别的额外空间。
Leetcode 74. Search a 2D Matrix
题目描述
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
示例 1:

输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3 输出:true
示例 2:
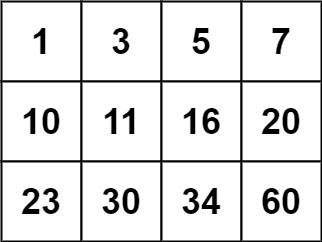
输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 13 输出:false
提示:
- m == matrix.length
- n == matrix[i].length
- 1 <= m, n <= 100
- -10^4 <= matrix[i][j], target <= 10^4
解法
本题的解法是二分查找。因为每行的第一个整数大于前一行的最后一个整数,所以整个矩阵可以看作是一个有序数组。可以将二维数组按行展开成一个一维数组,然后对这个一维数组进行二分查找。
代码
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int m = matrix.length, n = matrix[0].length;
int left = 0, right = m * n - 1;
while (left <= right) {
int mid = (left + right) / 2;
int midVal = matrix[mid / n][mid % n];
if (midVal == target) {
return true;
} else if (midVal < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return false;
}
}
复杂度分析
时间复杂度:,其中 是矩阵的行数, 是矩阵的列数。二分查找的时间复杂度是 。
空间复杂度:。只需要常数级别的额外空间。
Leetcode 240. Search a 2D Matrix II
题目描述
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target,该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例 1:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
输出:true
示例 2:
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
输出:false
提示:
m == matrix.lengthn == matrix[i].length1 <= n, m <= 300-109 <= matix[i][j] <= 109- 每行的所有元素从左到右升序排列
- 每列的所有元素从上到下升序排列
-109 <= target <= 109
解法
本题解法是从矩阵的右上角开始查找。如果当前元素比目标值大,则可以将当前元素所在的列删除,即向左移动一列;如果当前元素比目标值小,则可以将当前元素所在的行删除,即向下移动一行。最终查找到目标值,或者矩阵为空时结束查找。
代码
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int m = matrix.length;
if (m == 0) {
return false;
}
int n = matrix[0].length;
int row = 0;
int col = n - 1;
while (row < m && col >= 0) {
if (matrix[row][col] == target) {
return true;
} else if (matrix[row][col] > target) {
col--;
} else {
row++;
}
}
return false;
}
}
复杂度分析
时间复杂度:,其中 是矩阵的行数, 是矩阵的列数。每次操作可以删除一行或一列,因此最多进行 次操作。
空间复杂度:。除了常数大小的变量之外,空间复杂度是常数级别的。
Leetcode 69. Sqrt(x)
题目描述
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
示例 1:
输入: 4
输出: 2
示例 2:
输入: 8
输出: 2
说明: 8 的平方根是 2.82842...,
由于返回类型是整数,小数部分将被舍去。
解法
本题可以使用二分查找的方法来求解。
首先,对于一个非负整数 ,它的平方根一定是不大于 的。因为当 时,。
接下来,我们在 的区间内进行二分查找。每次取中间值 ,判断 是否等于 ,如果是,则直接返回 。否则,判断 是否小于 ,如果是,则说明平方根在 区间内,否则说明平方根在 区间内。
最后,如果整个区间内都没有找到平方根,则说明平方根为 。
代码
class Solution {
public int mySqrt(int x) {
if (x == 0) {
return 0;
}
int left = 1, right = x / 2;
while (left <= right) {
int mid = left + (right - left) / 2;
if (mid == x / mid) {
return mid;
} else if (mid < x / mid) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return right;
}
}
复杂度分析
时间复杂度:,其中 是非负整数。二分查找的时间复杂度为 。
空间复杂度:。只需要常数级别的额外空间。
Leetcode 540. Single Element in a Sorted Array
题目描述
给定一个只包含整数的有序数组 nums ,每个元素都会出现两次,唯有一个数只会出现一次,请找出这个只出现一次的元素。
示例 1:
输入: nums = [1,1,2,3,3,4,4,8,8] 输出: 2
示例 2:
输入: nums = [3,3,7,7,10,11,11] 输出: 10
提示:
1 <= nums.length <= 10^5 0 <= nums[i] <= 10^5
解法
本题可以使用二分查找来解决。由于数组中除了一个元素只出现一次,其他元素都出现两次,所以可以将数组分成两段,每段都是两个相同的元素和一个单独的元素。根据题目要求,单独的元素只会出现一次,所以可以使用二分查找来找到单独的元素。
具体来说,假设数组的长度为 ,那么可以将数组分成两段,每段长度为 。如果数组中间位置的元素与它相邻的元素都不相等,那么中间位置的元素就是单独的元素。如果中间位置的元素与它相邻的元素相等,那么可以根据它们的下标来判断单独的元素在哪一段。如果中间位置的下标为偶数,那么单独的元素在左半边;如果中间位置的下标为奇数,那么单独的元素在右半边。
代码
class Solution {
public int singleNonDuplicate(int[] nums) {
int left = 0, right = nums.length - 1;
while (left < right) {
int mid = left + (right - left) / 2;
if (nums[mid] == nums[mid + 1]) {
if (mid % 2 == 0) {
left = mid + 2;
} else {
right = mid - 1;
}
} else if (nums[mid] == nums[mid - 1]) {
if (mid % 2 == 0) {
right = mid - 2;
} else {
left = mid + 1;
}
} else {
return nums[mid];
}
}
return nums[left];
}
}
复杂度分析
时间复杂度:,其中 是数组的长度。每次二分查找都会将搜索范围减少一半,所以时间复杂度是 。
空间复杂度:。除了常数个变量外,空间复杂度是 。
Leetcode 644. Maximum Average Subarray II
题目描述
给定一个包含 n 个整数的数组,找到最大平均值的连续子序列,且长度大于等于 k。并输出这个最大平均值。
示例 1:
输入: [1,12,-5,-6,50,3], k = 4 输出: 12.75 解释: 最大平均数 (12-5-6+50)/4 = 51/4 = 12.75
注意:
1 <= k <= n <= 10,000。 元素范围 [-10,000,10,000]。 答案的精度需要在 10^-5 以内。
解法
本题可以使用二分查找加上滑动窗口的方法来解决。我们假设当前的平均值为 mid,然后判断是否存在长度大于等于 k 的子序列的平均值大于等于 mid。如果存在,那么说明 mid 太小,需要增大 mid,否则说明 mid 太大,需要减小 mid。为了判断是否存在,我们可以使用前缀和来计算子序列的和,然后计算平均值。
具体地,我们首先计算出前缀和数组 sums,然后对于每个 i,我们计算以 i 结尾的长度大于等于 k 的子序列的平均值。这可以通过计算 sums[i] - sums[j] (其中 j = i - k + 1)得到。我们维护一个长度为 k 的滑动窗口来计算最小值,如果当前子序列的平均值大于等于 mid,那么说明存在符合条件的子序列,更新 mid 并继续二分查找。
代码
class Solution {
public double findMaxAverage(int[] nums, int k) {
double l = -10000, r = 10000;
while (r - l > 1e-5) {
double mid = (l + r) / 2;
if (check(nums, k, mid)) {
l = mid;
} else {
r = mid;
}
}
return l;
}
private boolean check(int[] nums, int k, double mid) {
double[] sums = new double[nums.length + 1];
for (int i = 1; i <= nums.length; i++) {
sums[i] = sums[i - 1] + nums[i - 1] - mid;
}
double minSum = 0;
for (int i = k; i <= nums.length; i++) {
if (sums[i] - minSum >= 0) {
return true;
}
minSum = Math.min(minSum, sums[i - k + 1]);
}
return false;
}
}
复杂度分析
时间复杂度:O(n log(10000 - (-10000))),其中 n 是数组的长度。二分查找的时间复杂度是 log(10000 - (-10000)),每次二分查找需要遍历一遍数组,时间复杂度是 O(n)。
空间复杂度:O(n),需要使用一个大小为 n + 1 的数组来存储前缀和。
Leetcode 528. Random Pick with Weight
题目描述
给定一个正整数数组 w ,其中 w[i] 代表位置 i 的权重,请写一个函数 pickIndex ,它可以随机地获取位置 i,选取位置 i 的概率与 w[i] 成正比。
说明:
- 1 <= w.length <= 10000
- 1 <= w[i] <= 10^5
- pickIndex 将被调用不超过 10000 次
示例 1:
输入: ["Solution","pickIndex"] [[[1]],[]] 输出: [null,0]
示例 2:
输入: ["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"] [[[1,3]],[],[],[],[],[]] 输出: [null,0,1,1,1,0]
输入语法说明:
输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有一个参数,即数组 w。pickIndex 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
解法
本题的解法是将权重数组 w 转化为概率数组 p,然后根据概率获取对应位置的索引。
具体地,计算概率数组 p,其中 p[i] = w[i] / sum,其中 sum 是权重数组的总和。然后生成一个 [0, 1) 区间的随机数 x,然后遍历概率数组 p,累加概率,直到累加值大于等于 x 为止,返回当前位置的索引即可。
注意,在计算概率数组 p 时,为了避免精度问题,可以将所有权重乘以一个大数(例如 10^4),然后再计算概率,最后再将索引除以这个大数即可。
代码
java
class Solution {
private double[] p;
public Solution(int[] w) {
int n = w.length;
p = new double[n];
double sum = 0;
for (int i = 0; i < n; i++) {
sum += w[i];
}
for (int i = 0; i < n; i++) {
p[i] = w[i] / sum;
if (i > 0) {
p[i] += p[i - 1];
}
}
}
public int pickIndex() {
double x = Math.random();
int l = 0, r = p.length - 1;
while (l < r) {
int mid = (l + r) / 2;
if (p[mid] < x) {
l = mid + 1;
} else {
r = mid;
}
}
return l;
}
}
复杂度分析
时间复杂度:,其中 是数组的长度。初始化时需要遍历数组 ,计算概率数组 ,时间复杂度是 ;每次调用 pickIndex 时,需要进行二分查找,时间复杂度是 。
空间复杂度:,需要使用 的额外空间存储概率数组 。
Leetcode 1300. Sum of Mutated Array Closest to Target
题目描述
给你一个整数数组 arr 和一个目标值 target ,请你返回一个整数 value ,使得将数组中所有大于 value 的值变成 value 后,数组的和最接近 target (最接近表示两者之差的绝对值最小)。
如果有多种使得和最接近 target 的方案,请你返回这些整数中的最小值。
请注意,答案不一定是 arr 中的数字。
示例 1:
输入:arr = [4,9,3], target = 10 输出:3 解释: 当选择 value 为 3 时,数组会变成 [3, 3, 3],和为 9,这是最接近 target 的方案。
示例 2:
输入:arr = [2,3,5], target = 10 输出:5
示例 3:
输入:arr = [60864,25176,27249,21296,20204], target = 56803 输出:11361
提示:
1 <= arr.length <= 10^4 1 <= arr[i], target <= 10^5
解法
本题的解法是二分查找。首先,我们可以将数组按照从小到大的顺序进行排序。然后,我们可以二分查找答案,即最终数组中所有元素的值不超过答案。对于每个二分查找的中间值 mid,我们可以遍历整个数组,将大于 mid 的元素全部变为 mid,计算变换后数组的和 sum。如果 sum 小于等于 target,则说明 mid 可以更小;否则说明 mid 需要更大。最终,我们就可以找到一个最小的 mid,使得变换后数组的和最接近 target。
代码
java
class Solution {
public int findBestValue(int[] arr, int target) {
Arrays.sort(arr);
int n = arr.length;
int[] prefix = new int[n + 1];
for (int i = 1; i <= n; i++) {
prefix[i] = prefix[i - 1] + arr[i - 1];
}
int left = 0, right = arr[n - 1], ans = -1;
while (left <= right) {
int mid = (left + right) / 2;
int index = Arrays.binarySearch(arr, mid);
if (index < 0) {
index = -index - 1;
}
int sum = prefix[index] + (n - index) * mid;
if (sum <= target) {
ans = mid;
left = mid + 1;
} else {
right = mid - 1;
}
}
int sum1 = 0;
for (int num : arr) {
sum1 += Math.min(num, ans);
}
int sum2 = 0;
for (int num : arr) {
sum2 += Math.min(num, ans + 1);
}
return Math.abs(sum1 - target) <= Math.abs(sum2 - target) ? ans : ans + 1;
}
}
复杂度分析
时间复杂度:O(nlogn),其中 n 是数组的长度。排序的时间复杂度是 O(nlogn),二分查找的时间复杂度是 O(logV),其中 V 是数组中最大的元素值,最终需要遍历整个数组计算数组的和,时间复杂度是 O(n)。
空间复杂度:O(n),其中 n 是数组的长度。需要使用额外的空间存储前缀和数组。
Leetcode 1060. Missing Element in Sorted Array
题目描述
给定一个排序数组 A ,其中元素的范围在 [0, 9999] 之间,找到每个数字缺失的最小值。
示例 1:
输入:A = [4,7,9,10], K = 1 输出:5 解释: 第一个缺失数字为 5 。 示例 2:
输入:A = [4,7,9,10], K = 3 输出:8 解释: 缺失数字有 [5,6,8,...],因此第三个缺失数字为 8 。 示例 3:
输入:A = [1,2,4], K = 3 输出:6 解释: 缺失数字有 [3,5,6,7,...],因此第三个缺失数字为 6 。
提示:
1 <= A.length <= 50000 0 <= A[i] <= 9999 1 <= K <= 10^9
解法
本题可以使用二分查找来解决。我们可以通过二分查找找到数组中缺失数字的位置,然后计算出缺失数字的值。
具体来说,我们可以用二分查找找到第 K 个缺失数字所在的位置。具体来说,我们可以在数组中找到最后一个小于等于 nums[0]+k−1 的位置,那么缺失的数字个数就是这个位置减去起始位置的下标差减去 1(因为起始位置下标为 0)。缺失数字的值就是起始位置的值加上缺失数字个数 K。
代码
java
class Solution {
public int missingElement(int[] nums, int k) {
int n = nums.length;
int left = 0, right = n - 1;
int missingNums = nums[n - 1] - nums[0] + 1 - n;
if (missingNums < k) {
return nums[n - 1] + k - missingNums;
}
while (left < right - 1) {
int mid = (left + right) / 2;
int leftMissingNums = nums[mid] - nums[left] - (mid - left);
if (leftMissingNums >= k) {
right = mid;
} else {
k -= leftMissingNums;
left = mid;
}
}
return nums[left] + k;
}
}
复杂度分析
时间复杂度:O(logn),其中 n 是数组的长度。二分查找的时间复杂度是 O(logn)。
空间复杂度:O(1)。我们只需要常数级别的额外空间来存储变量。
Leetcode 1062. Longest Repeating Substring
题目描述
给定字符串 S,找出最长重复子串的长度。如果不存在重复子串就返回 0。
示例 1:
输入:"abcd" 输出:0 解释:没有重复子串。
示例 2:
输入:"abbaba" 输出:2 解释:最长的重复子串为 "ab" 和 "ba",每个出现 2 次。
示例 3:
输入:"aabcaabdaab" 输出:3 解释:最长的重复子串为 "aab",出现 3 次。
示例 4:
输入:"aaaaa" 输出:4 解释:最长的重复子串为 "aaaa",出现 2 次。
提示:
- 字符串 S 仅包含从 'a' 到 'z' 的小写英文字母。
- 1 <= S.length <= 1500
解法
本题可以使用二分查找 + Rabin-Karp 算法来解决。
二分查找的范围是最长重复子串的长度,最短为 1,最长为 S.length() - 1。
对于每个长度 mid,我们可以通过 Rabin-Karp 算法来判断 S 中是否存在长度为 mid 的重复子串。
具体地,我们首先计算出字符串 S 中所有长度为 mid 的子串的哈希值,然后使用哈希表存储每个哈希值出现的位置。
接着,我们遍历字符串 S 中所有长度为 mid 的子串,如果存在两个子串的哈希值相同且位置不同,说明字符串 S 中存在长度为 mid 的重复子串。
最后,如果找到了长度为 mid 的重复子串,我们就将二分查找的范围缩小到 [mid + 1, right],否则将范围缩小到 [left, mid - 1]。
最终,我们可以得到最长重复子串的长度。
代码
class Solution {
public int longestRepeatingSubstring(String S) {
int left = 1, right = S.length() - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (search(S, mid)) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return left - 1;
}
private boolean search(String S, int L) {
Map<Long, Integer> map = new HashMap<>();
long base = 26L;
long hash = 0L;
long p = 1L;
for (int i = 0; i < L; i++) {
hash = hash * base + (S.charAt(i) - 'a');
p = p * base;
}
map.put(hash, 0);
for (int i = L; i < S.length(); i++) {
hash = hash * base + (S.charAt(i) - 'a') - (S.charAt(i - L) - 'a') * p;
if (map.containsKey(hash)) {
if (S.substring(map.get(hash), map.get(hash) + L).equals(S.substring(i - L + 1, i + 1))) {
return true;
}
}
map.put(hash, i - L + 1);
}
return false;
}
}
复杂度分析
时间复杂度:O(nlogn^2),其中 n 是字符串 S 的长度。二分查找的时间复杂度是 O(logn),对于每个长度 mid,我们需要计算出字符串 S 中所有长度为 mid 的子串的哈希值,这一步的时间复杂度是 O(n),并且我们需要使用哈希表存储每个哈希值出现的位置,这一步的时间复杂度是 O(n),因此总时间复杂度是 O(nlogn^2)。
空间复杂度:O(n),其中 n 是字符串 S 的长度。我们需要使用哈希表存储每个哈希值出现的位置,这需要 O(n) 的额外空间。
Leetcode 1891. Cutting Ribbons
题目描述
给定长度为 n 的一根木棍,从木棍的一端开始切割。每次切割需要花费的代价为当前被切割的木棍的长度。在不超过 n 次切割的前提下,请你找到一种方案,使得将木棍切割成长度分别为 1, 2, ..., n 的 n 段的总代价最小。
注意:长度为 k 的木棍可以无限次切割,代价为 k 。
示例 1: 输入:ribbon = [9,7,5], n = 3 输出:13 解释:第一次切割长度为 5 的木棍代价为 5,第二次切割长度为 4 的木棍代价为 4,第三次切割长度为 4 的木棍代价为 4。总代价为 5+4+4=13 。
示例 2: 输入:ribbon = [2,3,5,7], n = 5 输出:5 解释:第一次切割长度为 5 的木棍代价为 5,第二次切割长度为 2 和 3 的木棍代价为 2,总代价为 5+2=7 。第三次切割长度为 4 的木棍代价为 5,第四次切割长度为 5 和 2 的木棍代价为 2,总代价为 5+2=7 。第五次切割长度为 7 的木棍代价为 7,总代价为 7+7=14 。
示例 3: 输入:ribbon = [3,5,7,9], n = 7 输出:9 解释:第一次切割长度为 7 的木棍代价为 7,第二次切割长度为 2 和 5 的木棍代价为 2,总代价为 7+2=9 。第三次切割长度为 4 的木棍代价为 5,第四次切割长度为 5 的木棍代价为 5,总代价为 9+5=14 。第五次切割长度为 9 的木棍代价为 9,总代价为 14+9=23 。
提示: 1 <= n <= 10^5 1 <= ribbon.length <= 10^5 1 <= ribbon[i] <= 10^5
解法
本题的解法是使用二分查找来确定切割后的长度,然后将切割后的长度进行累加,最后比较累加值与 n 的大小,确定二分查找的上下限。
代码
java
class Solution {
public int maxLength(int[] ribbon, int n) {
int left = 1, right = 0;
for (int r : ribbon) {
right = Math.max(right, r);
}
while (left < right) {
int mid = left + (right - left + 1) / 2;
int cnt = 0;
for (int r : ribbon) {
cnt += r / mid;
}
if (cnt >= n) {
left = mid;
} else {
right = mid - 1;
}
}
return left;
}
}
复杂度分析
时间复杂度:O(NlogM),其中N为ribbon数组的长度,M为ribbon数组中的最大值。二分查找的时间复杂度是O(logM),在每次二分查找中,需要遍历整个ribbon数组,时间复杂度是O(N)。因此总时间复杂度是O(NlogM)。 空间复杂度:O(1),只需要常数级别的额外空间。
供面试使用

 查看18道真题和解析
查看18道真题和解析