
初识Kafka
Kafka是什么?
Kafka是一款高吞吐的分布式消息发布订阅系统,支持多分区、多副本
为什么要用它,Kafka牛逼在哪里?
- 高吞吐、低延迟:kakfa 最大的特点就是收发消息非常快,kafka 每秒可以处理几十万条消息,它的最低延迟只有几毫秒。
- 高伸缩性: 每个主题(topic) 包含多个分区(partition),主题中的分区可以分布在不同的主机(broker)中。
- 持久性、可靠性: Kafka 能够允许数据的持久化存储,消息被持久化到磁盘,并支持数据备份防止数据丢失,Kafka 底层的数据存储是基于 Zookeeper 存储的,Zookeeper 我们知道它的数据能够持久存储。
- 容错性: 允许集群中的节点失败,某个节点宕机,Kafka 集群能够正常工作
- 高并发: 支持数千个客户端同时读写
常用概念
消息
Kafka 中的数据单元,也被称为记录,可以把它看作数据库表中某一行的记录。
每条消息记录都包含一个key,消息内容以及时间戳;
批次Batch
指的是一组消息。为了提高效率, 消息会分批次写入 Kafka
⭐️主题Topic
消息的种类,可以说一个Topic代表了一类消息。相当于是对消息进行分类。主题就像是数据库中的表。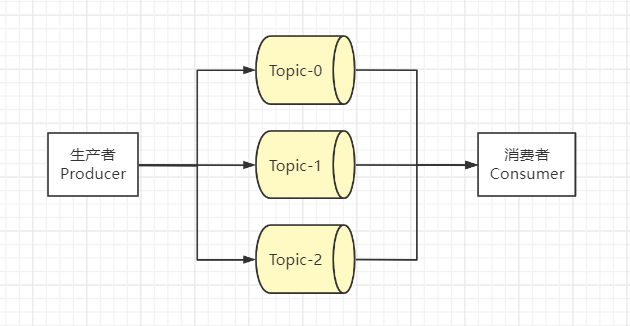
⭐️分区Partition
一个Topic可以被分为若干个Partition,同一个主题中的分区可以不在一个机器上,有可能会部署在多个机器上,由此来实现 kafka 的伸缩性,由此可见kafka是天然分布式的。
单一主题中的分区有序,但是无法保证主题中所有的分区有序。如果想要顺序的处理Topic的所有消息,那就只提供一个分区。
一个分区里,每个消息的偏移量是唯一的。消费者只能顺序读取。
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的。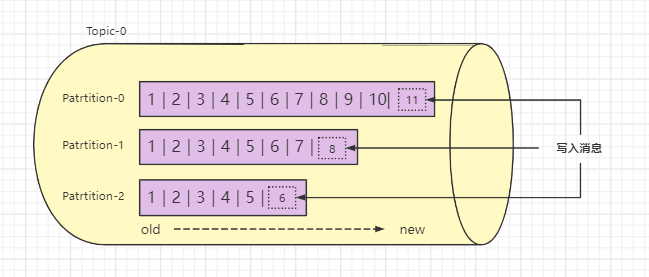
偏移量Offset
是一个不断递增的整数值,用来记录消费者发生重平衡时的位置,以便用来恢复数据。
实际上消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
这种设计对消费者来说操作自如, 一个消费者的操作不会影响其它消费者对此log的处理。
生产者Producer
向Topic发布消息的客户端应用程序称为生产者Producer,生产者用于持续不断的向某个主题发送消息。
若Topic有多个partition,生产者的消息可以指定或者由系统根据算法分配到指定分区。默认轮询算法
消费者Consumer
订阅主题消息的客户端程序称为消费者Consumer,消费者用于处理生产者产生的消息。
消费者根据Offset取数据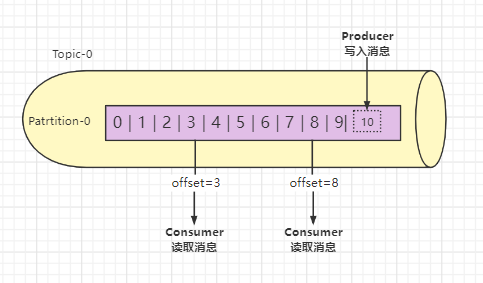
可以看出不同消费者对同一分区的消息读取互不干扰,消费者可以通过设置offset来控制自己想要获取的数据
消费者群组Group
一个生产者产生的消息可以被多个消费者进行消费。消费者群组Consumer Group指的就是由一个或多个消费者组成的群体。
Broker
一个Kafka服务器就被称为 broker,broker 接收来自Producer的消息,为消息设置偏移量Offset,并提交消息到磁盘保存。不同的broker可能存在相同的Topic。
Broker集群
broker 集群由一个或多个 broker 组成,每个集群都有一个 broker 同时充当了集群控制器的角色(自动从集群的活跃成员中选举出来)。
分布式Distribution
分区Partition会被分布到集群中的多个服务器上。每个服务器处理它分到的分区。 根据配置每个分区还可以复制到其它服务器作为备份容错。
每个分区有一个leader,零或多个follower。Leader处理此分区的所有的读写请求而follower被动的复制数据。如果leader当机,其它的一个follower会被推举为新的leader。
一台服务器可能同时是一个分区的leader,另一个分区的follower。 这样可以平衡负载,避免所有的请求都只让一台或者某几台服务器处理。
副本Replica
消息的备份叫做副本Replica。副本的数量是可以配置的,Kafka 定义了两类副本:领导者副本(Leader Replica) 和 追随者副本(Follower Replica),前者对外提供服务,后者只是被动跟随。
重平衡Rebalance
消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
详细说说
集群其中一台broker挂了怎么办?/网络抖动
Partition如何将数据持久化?
消费者如何取数据?消费者组有什么用?offset?
场景
更多请关注
微信公众号:程序员WeiG
个人博客:wggz.top
语雀主页:yuque.com/weig


