Mysql相关 (https: xiaolincoding.com mysql )
1, explain命令的各个字段解释
关键字段:
type 查询方式
- ✅ 优秀: system, const, eq_ref, ref
- ⚠️ 可接受: range, index_merge
- 🔴 需要优化: index(全索引扫描), ALL(全表扫描)
extra 数据处理方式
索引相关
Using index
Using index condition (用到了联合索引的一部分查找,另一部分在索引树上过滤)
Using where (先走索引查找,然后在服务层过滤, 可以通过联合索引优化到Using index condition) ---- 中优先级
排序相关
Using filesort (order by后面的字段需要添加索引) ---- 高优先级
Using temporary (distinct使用覆盖索引优化,避免临时表的产生) ---- 高优先级
连接相关
Using join buffer (Block Nested Loop)(被驱动表的连接字段上创建索引) ----- 中优先级
Using MRR (Multi-Range Read)
其他
Impossible WHERE
Select tables optimized away
Distinct
No tables used
rows 扫描行数
key 实际使用的索引
filtered 引擎返回的数据100条,过滤后剩下的数据的百分比20,即剩下数据为100*20% = 20条,越低表示引擎的过滤效果越差
key_len 可以分辨联合索引是否部分使用到了
2, Innodb和Myslam的区别
事务
行锁/表锁
外键
崩溃恢复
count(*)
聚簇索引和索引数据分离
myslam不支持事务,查询的时候不需要通过mvcc,直接从索引找到数据位置,然后读取数据速度更快
3,mysql架构图
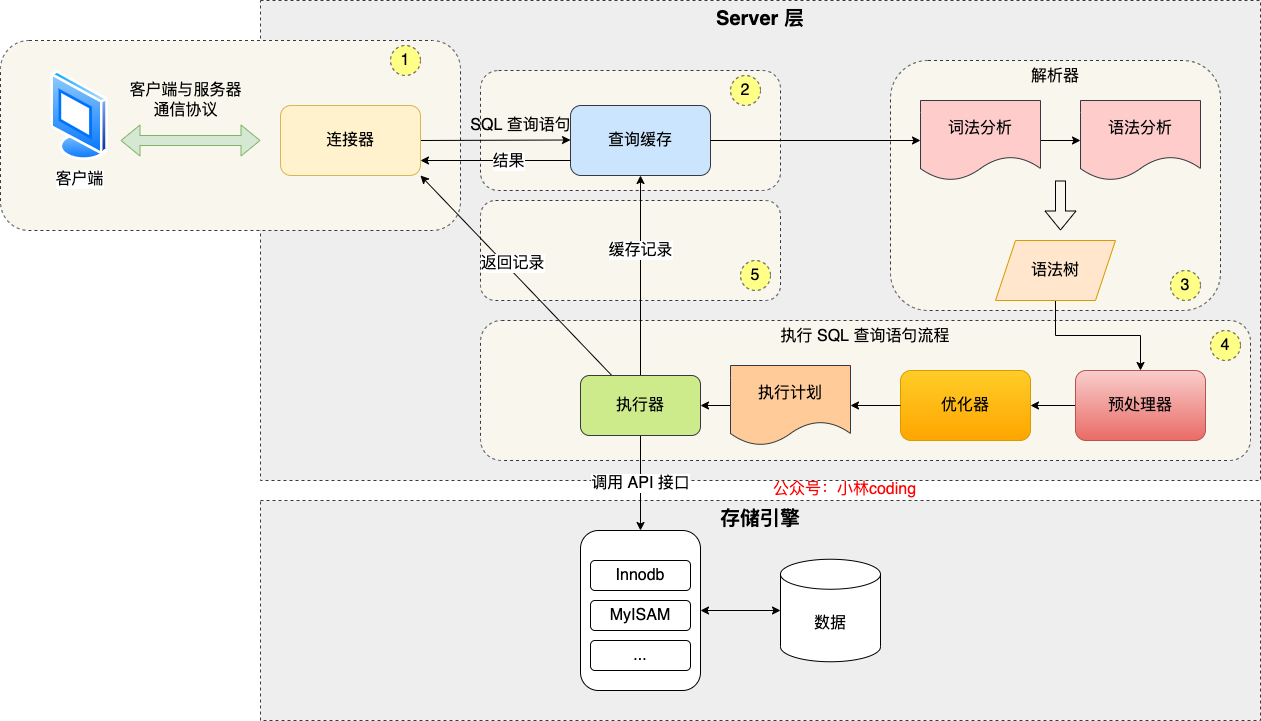
3.1,一条sql的执行
连接器:建立连接,管理连接、校验用户身份;
查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
解析器:解析SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
执行 SQL:执行 SQL 共有三个阶段:
预处理阶段:检查表或字段是否存在;将 select * 中的 * 符号扩展为表上的所有列
优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
4,一行记录的存储
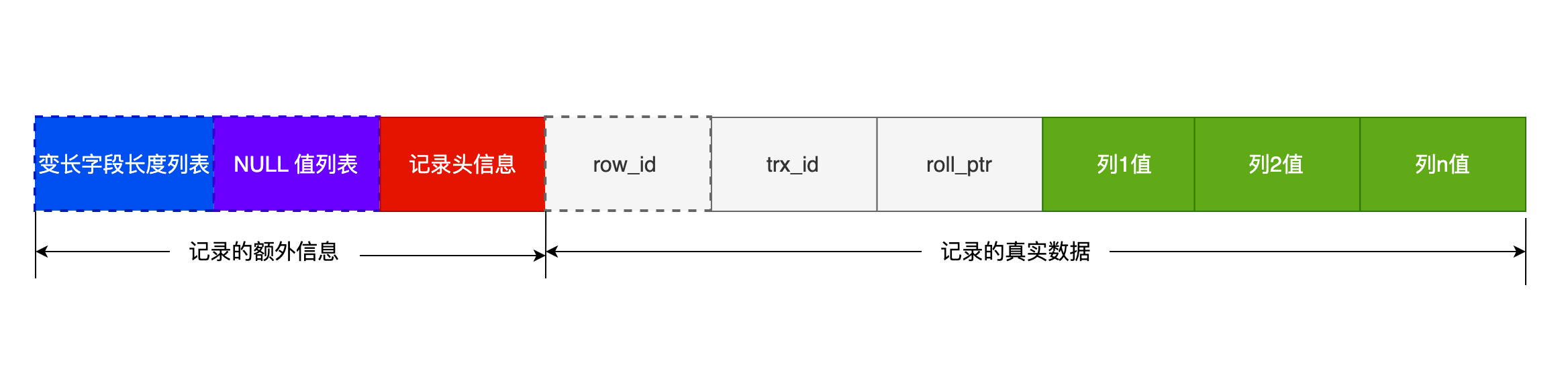
变长列表和NULL列表倒序存放
compact 紧凑排列(页溢出时存放768前缀+指针) dynamic (页溢出直接存放指针20字节) compressed(压缩整个数据页)
记录头信息:delete_mask next_record(单链表 vs 同一层页节点之间是双链表) record_type, deepseek上说是记录头在最前面
5,索引
前缀索引:对字符串的前几个字符建立索引,不需要在整个字段上建立索引,这样可以减少索引占用的存储空间
联合索引:范围查询的情况下,范围查找字段后面的字段无法用到联合索引
(a,b)这个索引,a>1 and b=2 和 a>=1 and b=2的查询方式不同,确定的查询起点可以走联合索引,在页面的索引槽中找到下一个a的起始位置,举例:查找今天已经回放的sql的分片数量。
对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配
1111111111


 查看10道真题和解析
查看10道真题和解析