
xv6(18) 控制台输入输出
控制台输入输出
这一板块来讲述控制台方面的知识,我分为两部分,一部分是本文要讲述的控制台的输入输出,另一部分是交互程序 这在下篇讲述。控制台的输入部分在键盘那儿讲了一点儿,当初说了怎么从键盘获取输入,但是没有讲述怎么处理,本篇来补齐。这个顺序是稍微乱了点,但影响不大,
这个系列也接近尾声了,我后面会查漏补缺好好整理一番。
关于本文控制台输入输出平时可能有这么几个常见扰人的问题:键入一个字符到输出到屏幕这之间的过程是怎样的?为什么文件描述符 表示标准输入输出?为什么
系统调用使用文件描述符
就会将消息打印到屏幕?
函数又是如何实现的?看完本文相信你会找到答案。
首先说说控制台这个概念,我们经常听到控制台,终端,物理终端,虚拟终端这样那样的概念,它们到底什么意思?这里我就不详细解释了,给大家找了一篇很好的文章,解释的很好,珠玉在前,我就不造次了。https://blog.csdn.net/qq_27825451/article/details/101307195?utm_source=app&app_version=4.16.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
总的来说吧,现在对控制台和终端这两个概念比较模糊了, 里一切皆文件,
里面对其也是同样的处理,专门创建了一个控制台文件,分配了一个
,其类型定为设备。所谓的设备文件不要想得那么神秘,在后面我们会看到设备文件和普通文件最主要的区别就是
的类型不同,然后使用的读写函数不同,这后面再细说。
另外 里有两个控制台,一个是
模拟出来的一个窗口,另一个是通过串口连接到的远程控制台,在配置
的时候有个
-serial mon : stdio 的选项,这个选项使得虚拟出来的串口重定向到主机的标准输入输出。这里所说的主机是你自己的“机器”,打上引号是因为通常是在虚拟机里面完成 的实验,那这个主机就表示自己配置的虚拟机,而对运行的
来说
模拟出来的机器才是它的主机。所以关于实验环境要捋清楚,虚拟机运行在真实的物理机器上,
运行在虚拟机上,
运行在
模拟出来的机器上(如果是其他实验环境另论)
回到控制台,因为多了一个串口通信,所以其实控制台的输入有两个来源,一个是键盘输入,另一个来自串口,输出也分为两部分,一部分输出到显示器,另一部分通过串口将数据发出去。
本文就是要把这 个部分讲述清楚,然后来捋捋从键入一个字符比如说 A 到显示到屏幕这之间发生了什么,组合键的特殊功能是如何实现的,以及经常使用的
函数是如何实现的。
键盘
与键盘相关的芯片有两个,一个是键盘编码器 i8048,另一个是键盘控制器 i8042,分别来看。
键盘编码器
键盘编码器位于键盘,它的作用主要是监测键的按下和弹起,然后将两种状态编码,发送给键盘控制器。
上述说的码叫做键盘扫描码,编码方式一共有三种,相应的也就有三套键盘扫描码,各套键盘扫描码具体怎么编码的就不说了,见后面的链接。现今的键盘大多数都是用的第二套键盘扫描码,但也不排除使用第一套和第三套的,所以为了兼容,键盘控制器会统统地转换为第一套扫描码。当然这是默认的情况,具体使用哪一套扫描码,控制器是否转化,还是要看硬件是否支持与具体怎么设置,有兴趣的详见文末链接。
因此第一套键盘扫描码还是得说道说道,一个键有按下就会有弹起,所以每个键会有两个状态,即每个键将会对应两个扫描码,键被按下时的编码叫做通码(),弹起时的编码叫做断码(
)。
大部分键的通码和断码都是 8 位 1 字节,但有些操作控制键如 Ctrl、Alt,附加键如Insert,小键盘区如 / ,方向键等是 2 字节甚至多个字节。有多个字节的扫描码通常都是以 开头。只有
一个键是以
开头。
断码与通码的关系:。
二进制表示为
,所以对于断码和通码可以这样理解,它们由 8 位比特组成,最高位第 7 位表示按键状态,1 表示按下,0 表示弹起。
键盘控制器
键盘控制器(i8042),不在键盘内部,被集成在南桥芯片上。主要接收键盘编码器发来的键盘扫描码,做一些处理(比如第二套扫描码转第一套),然后触发中断通知 CPU 来读取扫描码。
键盘控制器有 4 个 8 bits 寄存器,Status Register 和 Control Register,两者共用一个端口 0x64,读的时候是状态寄存器,写的时候是控制寄存器。Input Buffer 和 Output Buffer,两者共用一个端口 0x60,读的时候是输出缓冲器,写的时候是输入缓冲器。
状态寄存器:
bit0:1 表示输出缓存器满,CPU 读取后清零。从编码器发过来的扫描码就放在这里。
bit1:1 表示输入缓存器满,控制器读取后清零。
控制寄存器:
通过写 0x64 端口来向控制器发送命令,注意是向控制器本身发命令而不是向硬件设备键盘发命令,对于键盘的控制就是通过控制器来间接控制,所以只需要操作键盘就是了。
命令控制器就是将命令字节写入 0x64 端口,一般命令就是一字节,如果有两字节,则将第二个字节写入 0x60 端口。因为要写 0x60 端口表示的缓存区,所以要先判断该缓存区是否为空。
比如进入保护模式设置 时,先判断输入缓存区是否为空,空的话表示控制器已取走数据,可以继续进行,否则不空的话循环等待:
inb $0x64,%al # Wait for not busy 等待i8042缓冲区为空
testb $0x2,%al
jnz seta20.1
再向 0x64 端口写入命令 ,表示准备写
Output 端口,随后写入 0x60 端口的字节将放入 Output 端口。
inb $0x64,%al # Wait for not busy 同上
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al # 0xdf -> port 0x60 向端口0x60写入0xdf,打开A20
outb %al,$0x60
同样的先判断输入缓存区是否为空,然后写入命令第二字节 ,这个字节会被送到
Output 端口,这个端口也是一个控制端口,bit2 控制着 的开关,所以如果是命令字节
表示关闭
。
关于键盘控制器就说这么多,只讲述了与 相关的部分,其他部分同样的感兴趣的见文末的链接。
键盘驱动程序
驱动程序就是硬件物理接口的封装,键盘驱动程序也是如此,它的主要功能就是将读取扫描码转换成计算机所需要的信息,比如说转换成字符,特殊信号等等。xv6 在这方面实现的比较简单,只实现了字符转化,一些功能控制键,我们来看看。
映射表
首先在 头文件中定义了端口号,控制键如
Ctrl,特殊键如 UP,以及最重要的映射表,来看个普通情况下的映射表:
static uchar normalmap[256] =
{
NO, 0x1B, '1', '2', '3', '4', '5', '6', // 0x00
'7', '8', '9', '0', '-', '=', '\b', '\t',
'q', 'w', 'e', 'r', 't', 'y', 'u', 'i', // 0x10
'o', 'p', '[', ']', '\n', NO, 'a', 's',
'd', 'f', 'g', 'h', 'j', 'k', 'l', ';', // 0x20
'\'', '`', NO, '\\', 'z', 'x', 'c', 'v',
'b', 'n', 'm', ',', '.', '/', NO, '*', // 0x30
NO, ' ', NO, NO, NO, NO, NO, NO,
NO, NO, NO, NO, NO, NO, NO, '7', // 0x40
'8', '9', '-', '4', '5', '6', '+', '1',
'2', '3', '0', '.', NO, NO, NO, NO, // 0x50
[0x9C] '\n', // KP_Enter
[0xB5] '/', // KP_Div
[0xC8] KEY_UP, [0xD0] KEY_DN,
[0xC9] KEY_PGUP, [0xD1] KEY_PGDN,
[0xCB] KEY_LF, [0xCD] KEY_RT,
[0x97] KEY_HOME, [0xCF] KEY_END,
[0xD2] KEY_INS, [0xD3] KEY_DEL
};
键盘扫描码是一个键的代表,但不是我们想要的,我们想要的是这个键表示的意义,比如数字键 1 的通码是 ,
显然不是我们想要的,我们想要的是数字 1,所以需要一个映射关系来转换,将所有键的映射关系集合在一起就是上述的映射表。是个大数组,下标就是这个键的扫描码,内容就是所表达的意思。
上述是一般情况,那当然还有非一般的情况,比如有按下 Shift,CapsLock,Ctrl 等控制键,当按下这些控制键后,其他键按下之后表达的意义就不一样了,所以还需要另外的映射表,这里就不列出来了,太多了,可以直接参考代码。举个例子,当按下 Shift 键之后再按下数字键 1,通码 则应该映射成
!而不是 1。
驱动函数
有了这些了解之后来看 里面的源码:
int kbdgetc(void)
{
static uint shift; //shift用bit来记录控制键,比如shift,ctrl
static uchar *charcode[4] = {
normalmap, shiftmap, ctlmap, ctlmap
}; //映射表
uint st, data, c;
st = inb(KBSTATP);
if((st & KBS_DIB) == 0) //输出缓冲区未满,没法用指令in读取
return -1;
data = inb(KBDATAP); //从输出缓冲区读数据
if(data == 0xE0){ //通码以e0开头的键
shift |= E0ESC; //记录e0
return 0;
} else if(data & 0x80){ //断码,表键弹起
// Key released
data = (shift & E0ESC ? data : data & 0x7F);
shift &= ~(shiftcode[data] | E0ESC);
return 0;
} else if(shift & E0ESC){ //紧接着0xE0后的扫描码
// Last character was an E0 escape; or with 0x80
data |= 0x80;
shift &= ~E0ESC;
}
shift |= shiftcode[data]; //记录控制键状态,如Shift,Ctrl,Alt
shift ^= togglecode[data]; //记录控制键状态,如CapsLock,NumLock,ScrollLock
c = charcode[shift & (CTL | SHIFT)][data]; //获取映射表的内容,也就是该键表示的意义
if(shift & CAPSLOCK){
if('a' <= c && c <= 'z')
c += 'A' - 'a';
else if('A' <= c && c <= 'Z')
c += 'a' - 'A';
}
return c;
}
这个程序就可以看作极简的键盘驱动程序,也是键盘中断的服务程序的主体,完成键盘扫描码到所需信息的转化。下面就来仔细分析分析:
前面说过有多张映射表多种映射方式,那怎么知道用哪张?用哪张得看看有没有相应的控制键按下,所以得有个东西来记录控制键的按下与否,这个东西就是变量 ,虽然变量名是
,但不代表只记录
Shift 键的状态,记录的信息有:
#define SHIFT (1<<0)
#define CTL (1<<1)
#define ALT (1<<2)
#define CAPSLOCK (1<<3)
#define NUMLOCK (1<<4)
#define SCROLLLOCK (1<<5)
#define E0ESC (1<<6) //通码断码以E0开头
从这种定义控制键的方式就可以看出使用 来记录控制键的方式应该是使用位运算。
表示一个二维数组,可以看作是映射表的集合,根据
的记录信息来选择映射表,后面用到的时候就明白了。
st = inb(KBSTATP);
if((st & KBS_DIB) == 0) //输出缓冲区为空,没法用指令in读取
return -1;
data = inb(KBDATAP); //从输出缓冲区读数据
这几句用来读取键盘扫描码,从键盘发过来的扫描码就放在输出缓冲区中。要读取扫描码首先从状态寄存器读取当前状态到 ,再做与运算取出第 0 位,表示输出缓冲区的状态,如果为 0 表示输出缓冲区寄存器为空,没法读取返回 -1。如果为 1 表示输出缓冲区寄存器已满有内容,可以读取,所以接着从端口
0x60 输出缓冲区读出扫描码到 。
if(data == 0xE0){ //通码以e0开头的键
shift |= E0ESC; //记录e0
return 0;
}
如果这个扫描码为 ,说明按下的键是特殊键,扫描码不止 8 字节,这种情况在
变量中做好标记就可以直接返回了,等待下一个数据的到来再做具体处理
else if(data & 0x80){ //断码,表键弹起
// Key released
data = (shift & E0ESC ? data : data & 0x7F);
shift &= ~(shiftcode[data] | E0ESC);
return 0;
}
为 1 的话,表示第 7 位为 1,说明此数据为断码,收到断码不需要额外的做什么事,但如果这个断码是某个控制键的断码,则应该将该控制键在
里面的记录信息给清除掉。
所以得知道读出的 表示哪一个控制键,所以有了
映射:
static uchar shiftcode[256] =
{
[0x1D] CTL,
[0x2A] SHIFT,
[0x36] SHIFT,
[0x38] ALT,
[0x9D] CTL,
[0xB8] ALT,
};
私以为这个定义方式很不对头啊,实在不太明白一些控制键用通码,一些用断码,这也就导致了那条使用了条件表达式的 赋值语句必须存在,因为
中映射
Shift 键的时候没有用断码,所以得转换成通码。私以为这么映射很混乱,导致后面 中有些语句意义也不太明确,要么就应该将映射关系给补全,然后可以省掉那句
赋值语句,使后面的语句书写变得更明确一点。当然这不是重点,能理解这过程意思就行,总而言之如果
是个断码,不需要干其他的事,如果是控制键的断码,将记录在
中的控制键信息给清除掉就行。
else if(shift & E0ESC){
// Last character was an E0 escape; or with 0x80
data |= 0x80;
shift &= ~E0ESC;
}
这种情况对应的是紧接着 后面的键盘扫描码,键盘扫描码有多个字节的,都是成对存在也就是
这种形式,每次收到
,都要将
键中记录的
信息给清除掉。至于前面还有一句
还是与
设计的映射表有关,键盘上有着许多相同意义的键,
将一些键的映射关系用断码来映射,比如除号键
/。
shift |= shiftcode[data]; //记录控制键状态,如Shift,Ctrl,Alt
shift ^= togglecode[data]; //记录控制键状态,如CapsLock,NumLock,ScrollLock
这两句来记录控制键的状态,分了两种情况,两种运算方式。应该能看出它们之间的区别吧,实现组合键的时候,Shift,Ctrl,Alt 需要按住不放才能生效,弹起后不再生效。而像 CapsLock 之类的控制键,只需要按下一次即可,即便弹起之后同样生效。所以一个使用或运算,一个使用异或运算,自己模拟一下过程应该很容易明白。
c = charcode[shift & (CTL | SHIFT)][data]; //获取映射表的内容,也就是该键表示的意义
if(shift & CAPSLOCK){ //如果有 CapsLock 存在
if('a' <= c && c <= 'z') //小写变大写
c += 'A' - 'a';
else if('A' <= c && c <= 'Z') //大写变小写
c += 'a' - 'A';
}
根据 中记录的控制键信息,来选取映射表,根据
去获取该键盘扫描码所表示的意义。因为
CapsLock 和 Shift 键的功能有相同之处,所以如果 c 就是个普通 26 个英文字母字符的话,需要额外判断大小写。
关于 xv6 的键盘驱动程序差不多就是这么多,当然还有一些功能没说,比如 Ctrl 组合键功能,键盘的缓冲区等等,这在另一个文件里面涉及到了另外的知识,咱们放在后面再详述吧。
在此再聊聊常见的一些问题,在第一篇键盘里也说过,再来看看:
使用组合键时需要先按下控制键。键盘的中断程序为这些控制键设置了标识()。先按下控制键,程序为控制键设置好按下状态,再处理后到来的键时会检查这些标识,是否有控制键按下,以便做出不同的操作。
组合键按键时有顺序,但弹起无顺序要求。由上面的键处理程序可知,只有通码的键处理程序在做事,而断码的键处理程序除了控制键的标识位需要复位之外其他键都是直接返回的。所以使用键盘控制输入时重要的是按键,而不是键弹起,所以只要按键对了,怎样弹起并不重要。
一直按着某个键时会一直触发键盘中断,若是普通的字符键,电脑屏幕可能会出现一直打印某个字符的现象。若是一些控制键,则驱动程序可能会不停地将这个键设为按下状态。当然,驱动程序是否记录上次按键取决于具体实现,大多是不记录的,xv6 也是如此,触发一次键盘中断就处理一个扫描码。
最后总结一番,键盘驱动程序同样的是封装键盘的物理接口使用,比如读取状态,读取扫描码等等。键盘本身使用的是键盘扫描码,每个键都有自己的键盘扫描码,一个是通码表按下,一个表断码表弹起。这个键盘扫描码只是唯一标识一个键,可以将键盘扫描码看作是一个键的物理意义,但这不是我们想要的,我们想要的是这个键代表的逻辑意义。所以物理意义和逻辑之间需要一个转化,这就是映射表存在的意义。
键盘上有各种各样的键,还能组合使用,它们所代表的意义、具有的功能很多也很杂,xv6 只实现了其中一部分,但也足以让我们明白其中的本质。不论要通过按键实现什么功能,还是就只是简单的使用一个键所代表的逻辑意义,都是要先获取键的扫描码,再通过映射表转化成所需要的信息,后续什么功能再在其上做文章。
显示适配器
输出到显示器那当然和显示适配器相关,也就是常说的显卡。又到了了解硬件的部分,老规矩,对于硬件我们主要是了解它的寄存器,显卡的寄存器有很多,来看看 中涉及到的部分
寄存器
主要就是 寄存器组,包括两个寄存器:
,地址寄存器,映射到端口
,数据寄存器,映射到端口
寄存器组的端口地址不固定,如果
寄存器的
位是
那么端口地址就是
,如果是 1 的话端口地址就是
,默认情况是 1 所以使用
两个端口
这两个寄存器的形式应该很熟悉吧,这明显的是用 或者说
的形式去访问显卡的其他寄存器。用地址寄存器来选择显卡的其他寄存器,再从数据寄存器中读写数据。这在
那一块也是这样操作
的寄存器的
那所谓的其他寄存器有哪些呢?同样的只是来看看需要了解的一部分:
,
,光标位置高 8 位寄存器
,
这两个寄存器就是来指示光标位置的,了解这 个寄存器就已经足够来实现咱们自己的打印函数了。
显存
我们通常所说的物理内存物理地址空间它是指地址线能够寻址到的空间,而不是单指内存条里面的空间。在低 里有一部分区域映射到了显存,显卡有不同的工作模式,不同的工作模式使用的范围也不同:
,用于文本模式
,用于黑白模式
,用于彩色模式
这只是低 对于显存的映射,现在的显存动不动就是几个
,这么点空间肯定是不够用的,可以打开设备管理器双击显示适配器查看显存的映射关系,例如我的电脑如下所示:
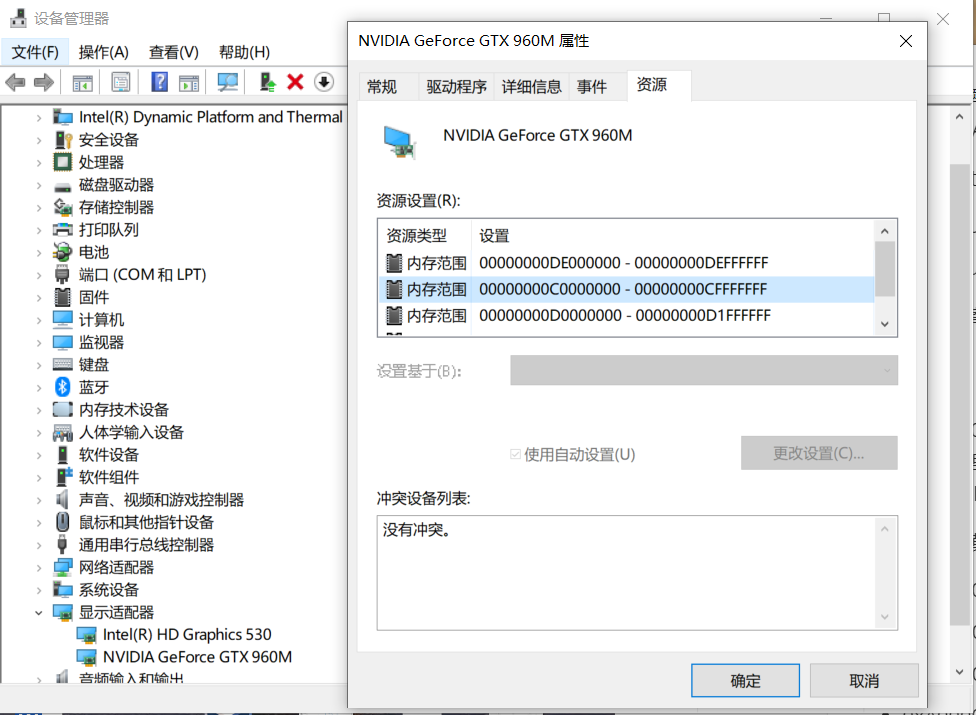
这里看不到 这一项,据一些网友回答来看,这一项在
上是能够看到的,
后看不到了,但不是说
这片空间就没映射了,是映射了的,这是规范定义的。
文本模式
没那么复杂,就是使用显示适配器的文本模式——
这片空间来实现输出,当我们向这片空间写入数据时,就是向显存里面写入数据,然后显卡就会将这些数据输出到显示器。
文本模式也有好几种模式,用 来表示,比如说有
,
等等,但一般默认的就是
,也就是说一屏最多
行,每行最多
个字符。
字符一般就是 码,8 位 1 字节,但是显示器上每个字符占据 2 字节,还有 1 字节的信息用来设置颜色。来看字符及其属性图示:
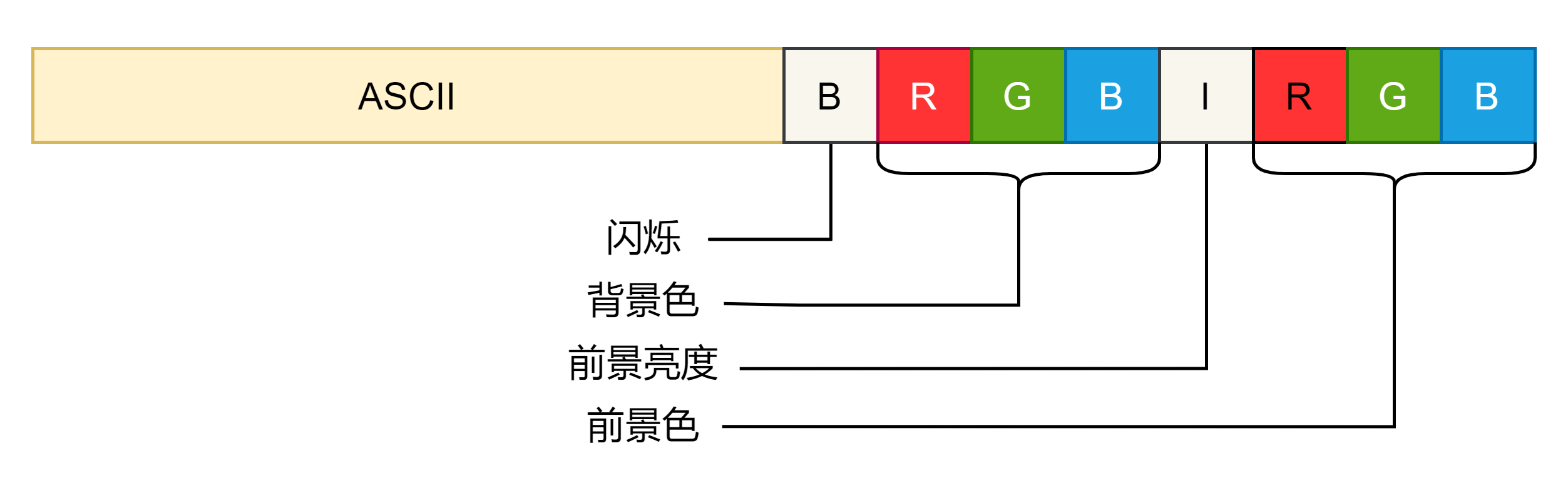
用来表示颜色的就只有 4 位(加上亮度位),所以只支持 16 种颜色。加上 8 位颜色,一个字符就用 2 字节表示,而一屏最多显示 个字符,所以每屏的字符实际上只占用了
字节,可是显存有
之多,完全可以将显存划分多个区域让给多个终端使用而互不干扰。显卡提供了两个寄存器
和
来设置数据在显存中的起始位置。而使用
切换终端
就是变换这两个寄存器中记录的起始地址
底层打印函数/显卡驱动
有了上述的了解,我们来看实际的打印单个字符的函数,这一部分也可以看作显卡的驱动程序,前面说过驱动程序从本质上看就是对硬件接口的封装,这里就是对显卡的硬件接口寄存器编程,代码如下:
static ushort *crt = (ushort*)P2V(0xb8000); //文本模式显存起始地址
void cgaputc(int c){
int pos;
/*****获取光标位置*****/
outb(CRTPORT, 14); //地址寄存器中选择高光标位置寄存器
pos = inb(CRTPORT+1) << 8; //从数据寄存器中获取光标位置高8位
outb(CRTPORT, 15); //地址寄存器中选择低光标位置寄存器
pos |= inb(CRTPORT+1); //从数据寄存器中获取光标位置低8位
这一步获取光标位置,很简单,就是在地址寄存器中选择光标寄存器,然后从数据寄存器中读出光标的位置信息,一个寄存器只有 8 位,位置 16 位,所以分了高低两次,最后将高低位置组合在一起就是光标的位置
要注意光标的位置值不是以字节为单位,而是以 2 字节为单位,加之每个字符需要 2 字节来描述,所以如此定义显存 ,表示每个元素为两字节的一个数组,而光标位置
就相当于这个数组的索引。
if(c == '\n') //换行
pos += 80 - pos%80;
这条 语句处理换行操作,换行就是将光标移动到下一行行首的位置,每行可容纳
个字符,光标的当前位置加上当先行剩余可容纳字符数就是将光标移动到下一行行首了,简单的一个数学加减法,应该没什么问题。
else if(c == BACKSPACE){ //退格
if(pos > 0) --pos;
如果是退格的话就将光标值减 1,当然是在光标值本身大于 1 的情况下操作,光标的位置值是不可能小于 0 的。这个退格的标识是自定义的一个宏,不是 码里面的字符,
里面是有个退格字符
'\b',这在后面还会提到,这里先说一下。
} else
// black on white 前景色设的7表黑色,背景色位0表白色
crt[pos++] = (c&0xff) | 0x0700;
这一步就是打印一个普通的可显示字符的操作,是不是相当简单,就是往这两字节的内存区域写 码和属性码,再将光标向后移动一个字符就完事了,所以打印函数本身没什么神秘的。
// Scroll up. 一屏最多显示25行,这里整除大于等于24就开始滚动了,说明没有用最后一行,实验证明的确如此
if((pos/80) >= 24){
memmove(crt, crt+80, sizeof(crt[0])*23*80); //将中23行上移,第一行被覆盖
pos -= 80; //直接减去80将光标移动到上一行相应位置
memset(crt+pos, 0, sizeof(crt[0])*(24*80 - pos)); //再将最后一行的字符清零
}
这一个 语句块来简单粗暴的处理滚屏操作,一屏最多使用
行,
里面当要写第 24 行的时候就开始执行滚屏操作,最后一行没有使用。要写第
行的时候滚屏,但是实际还没写,只是光标移动到
行了。
滚屏的方式十分粗暴简单,将前 行的数据整体向前移动一行,覆盖第一行,之后再清零第
行就是滚屏操作了,这种滚屏显存中的数据被覆盖后就不存在了。具体操作步骤注释很清楚了,就不再赘述,应该很容易看懂。
outb(CRTPORT, 14);
outb(CRTPORT+1, pos>>8);
outb(CRTPORT, 15);
outb(CRTPORT+1, pos);
crt[pos] = ' ' | 0x0700; //在光标位置打印空白字符
最后就是更改光标寄存器里面的值,前面修改 ,那只是光标在内存里面的值,要同步更改寄存器里面的值,才是真正地更改光标位置。如何操作同前,只是前面是读,这里是写而已,完全的逆操作,不赘述。
这里主要看最后一条语句什么意思,注释里说明了是在光标位置打印空白字符,这主要是用在退格键 ,根据我们平时的使用习惯,按下退格键不仅光标会向前移,相应字符也被删除了,而这条语句就是来执行这个删除操作的,打印一个空格字符就相当于删除了原来的字符。而对于
'\b' 的处理通常只是移动光标不覆盖原来的字符,但也说不准,不同的机器编译器的处理不一样。
另外字符一般是输出到光标的位置,但光标与字符真的有关系吗?它俩本身没有任何关系,是我们人为地将它俩绑定到了一起。 数组的索引表示字符的位置,我们只是把光标值当作它的索引,但没规定光标值一定要是索引。只是按照平时地使用习惯,觉得光标的位置就是下一个字符出现的位置,所以把下一个字符的在屏幕上的位置与光标绑定在一起。
上述就是打印字符的最底层的一个函数,这么一看是不是还挺简单的。从上面我们也了解到键盘上的这些键的名字它就只是个名字而已,实际做什么事是由“我们”自己决定的。完全可以让按键做一件风马牛不相及的事,只是要根据平时的使用习惯,要有一定的意义,否则做了额外功还毫无意义(废话学,主要是觉得加上通顺点?)
串口通信
上述的打印函数 打印出来的字符只会出现在
模拟出来的窗口上面。不会出现到虚拟机的窗口里面,要想同步出现到远程的串口控制台就需要串行通信的技术。
关于串行通信以及涉及到的接口技术,我没有深入了解过,在这里我就只说说 涉及到的一些概念,详细的讲解我找了一本书:清华大学微型计算机技术及其应用,以及后面的链接资料,感兴趣的可以一观。
所谓的串行通信,意思就是说传输数据是一位一位的传输,每一位的数据都占据着一个固定的时间长度,不像并行传输那样一次性就能传输多位数据。
串行通信有好几种工作模式,“都不重要”,通常使用异步通信的模式,所以只是来了解了解异步通信的数据格式
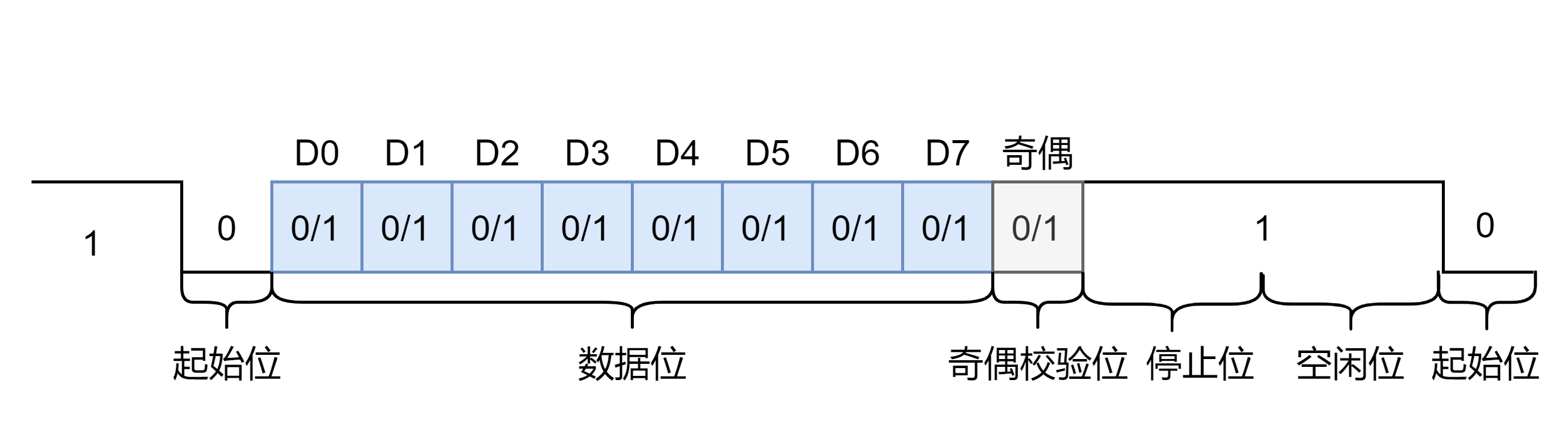
- 传输一个字符前输出线必须处于高电平 1 的状态
- 传输开始的时候,输出线变成低电平 0 状态作为起始位
- 起始位后面是
个数据位,这是串口通信真正有用的信息。具体的位数由通信的双方约定。标准的
码是
,用
位表示,扩展的
,使用
位表示
- 奇偶校验位,可以设置为奇校验,也可设置为偶校验,还可以不设置
- 最后为停止位,可以占据
位,
位,注意这里说的单位位是一个时间长度,所以小数是没问题的
- 空闲位说的就是在传输之前必须处于高电平 1 的状态,然后传输下一位时又先变为低电平 0 作为起始位
串行通信的传输率指的是每秒传输多少位,也叫做波特率
异步通信的方式双方必须约定时钟,发送方需要时钟来决定每一位对应的时间长度,接收方也需要一个时钟来确定每一位的时间长度,前一个叫做发送时钟,后一个叫做接收时钟。两个时钟的频率通常为传输率的 16 倍、32 倍、64 倍,这个倍数叫做波特率因子。
波特率因子在接收方有重要作用,假如波特率因子为 ,当接收方检测到电平由高变低后,时钟便开始计数,当计数到
时对输入的信号采样,如果仍然为低电平,则认为这是一个数据的起始位,而不是干扰信号。随后每隔 16 个时钟脉冲对输入信号进行采样,直到各个信息位以及停止位都输入以后才停止采样。
里串行通信使用的异步串行通信芯片是
,叫做
(通用异步接收发送器),同其他硬件,对其端口寄存器读写来控制编程。端口
用于
串行口,
用于
串行口,来简单了解了解这些端口寄存器
:
,写线路控制寄存器
:
(
)除数锁存访问位,
时,
和
分别表示
,
:1 为偶校验 0 为 奇校验
:1 允许奇偶校验,0 无奇偶校验
:1 表示 1.5 个停止位,0 表示 1 个停止位
:数据位长度,
表 5 个数据位,
表 6 个数据位 ,
表 7 个数据位,
表 8 个数据位
,
,读的时候这个寄存器含有收到的字符,写的时候将要发送的字符写到这个寄存器
,
,含有波特率的低字节
,
,含有波特率的高字节
,
,中断允许寄存器,这个寄存器来控制
什么时候,以及如何触发一个中断
,设置为 1 的话
,也就是说接收到数据之后就触发一个中断
,
,读线路状态寄存器
:为 1 时表示传输保持寄存器为空,可以向其写要发送的数据
的寄存器就了解这么多吧,坦白地讲,这些硬件部分还是需要专业人士来说明,我也只是了解各皮毛应付一下代码阅读。在文末我放置了这一块的详细资料,大家有兴趣的可以看看
下面来看 的初始化:
void uartinit(void)
{
char *p;
outb(COM1+2, 0); //关闭FIFO
outb(COM1+3, 0x80); // DLAB=1
outb(COM1+0, 115200/9600); //设置波特率为9600,低字节
outb(COM1+1, 0); //高字节
还有个
缓存区和
控制寄存器(
端口写时),
强制串口通信的字节按照
的顺序来,合理设置
的控制寄存器能够提高通信性能,但是
将其关闭没有使用
接下来就是设置 位为 1,然后设置波特率为
,低位字节写入
,高位字节写入 0 就是将波特率设置为
,其他波特率的设置详见链接
outb(COM1+3, 0x03); // DLAB=0, 1位停止位,无校验位,8位数据位
outb(COM1+4, 0); // modem控制寄存器,置零忽略
outb(COM1+1, 0x01); // Enable receive interrupts.
这部分设置数据格式,
,即接收到数据时触发中断
if(inb(COM1+5) == 0xFF) //如果读线路状态寄存器读出的值为0xff,则说明UART不存在
return;
这部分检查 是否存在
inb(COM1+2);
inb(COM1+0);
ioapicenable(IRQ_COM1, 0);
这一部分是将中断路由到 ,至于前面两个读取操作就是复位操作,很多硬件都有类似机制,比如在磁盘那一块儿,读取状态寄存器来显示通知中断完成,就是一种复位操作,以此准备下一次操作的环境。
串口输入输出
下面来看如何通过串口发送和接收字符:
void uartputc(int c){
int i;
if(!uart)
return;
for(i = 0; i < 128 && !(inb(COM1+5) & 0x20); i++) //循环等待传输保持寄存器空
microdelay(10);
outb(COM1+0, c); //向传输寄存器写入要发送的字符
}
static int uartgetc(void){
if(!uart)
return -1;
if(!(inb(COM1+5) & 0x01)) //数据好没?
return -1;
return inb(COM1+0); //从传输寄存器获取字符
}
发送和接收的函数很简单,发送时就检查读线路状态寄存器 ,查看传输保持寄存器是否为空,如果为空就向传输保持寄存器写要发送的字符。接收时就检查读线路状态寄存器
,查看数据是否已经准备好,若是就从传输保持寄存器读取字符。
至于前面发送时循环等待,而接收时没有,是因为接收到了数据才会触发中断通知 来读取数据,但现在没有数据可读,前后矛盾那肯定是出错了,所以直接返回
。再者发送时循环
次,每次延时
,没什么特殊意义,就一个等待过程,我看其他对
的编程里,就直接使用的
循环
到此控制台的 4 中输入输出形式已经说明完毕, 将串口输出和显示器输出封装在一个函数里使得两者同步输出:
void consputc(int c){
if(panicked){ //如果panic了,冻住CPU
cli(); //关中断
for(;;) //无限循环来 freeze CPU
;
}
if(c == BACKSPACE){ //如果是退格键
uartputc('\b'); uartputc(' '); uartputc('\b');
} else
uartputc(c); //打印到串口控制台
cgaputc(c); //打印到本地控制台
}
上面这个函数就是将 和
结合起来,只是针对
'\b' 的处理有所区别,一般情况下这两个函数接收的参数都是标准的前 个
码,
前面也说过是自定义的宏,它是来模拟退格键,但是
码里面没有,所以没法
uartputc('\b')
平时使用的退格键有删除的功能是因为移动了光标之后打印了一个空白字符, 里面的
函数就是这样处理退格(
按键和
'\b' 都是这样处理)的,而串口重定向到主机的标准输入输出后对于 '\b' 的处理只是移动光标,所以如果要使用 '\b' 来模拟退格键的效果的话,就要先向前移动光标再打印空白字符,打印一个字符光标后移,所以光标需要再次前移。
控制台中断服务程序
前面讲述的是控制台的输入输出,针对输入控制台需要做出相应的操作,输出只是这相应的操作之一,这一节就来看看控制台针对来自键盘和串口的输入做出如何反应。
缓冲区
首先对于控制台的数据分配了一个缓冲区,不然的话来一个数据就要上层的函数来处理效率十分低下,将输入的数据放进缓冲区,上层的函数再从缓冲区中获取想要的信息。
#define INPUT_BUF 128
struct {
char buf[INPUT_BUF];
uint r; // Read index
uint w; // Write index
uint e; // Edit index
} input;
这是一个环形缓冲区,有 字节,还定义了
种标识索引,
表示上层的函数读取到了哪一个字符,
表示最新到来的字符在哪个位置,
感觉与
不怎么搭边,它标志着
'\n' EOF 这种字符在哪个位置。
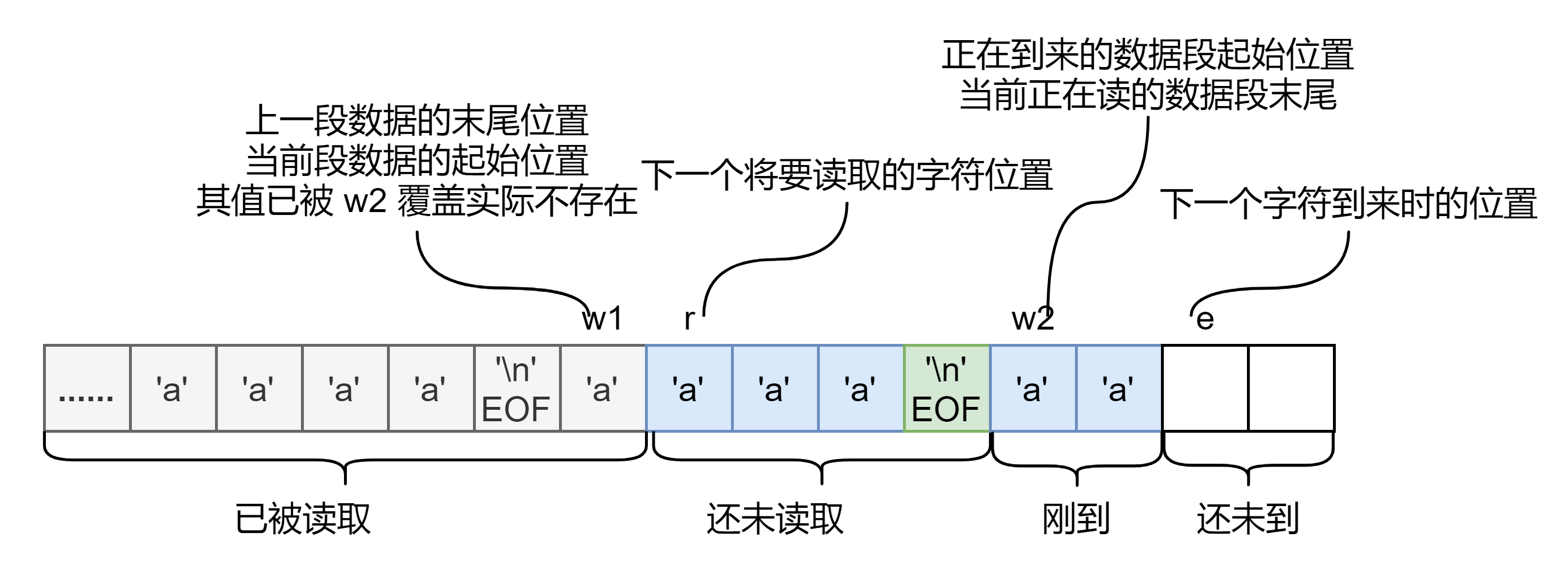
所以 '\n' EOF 将数据分成一段一段的,在后面的函数我们可以看到进行读写操作的时候也是这样一段一段的操作,而不是一个字符一个字符的操作,提高了效率。
中断服务程序
键盘和串口的中断服务程序定义如下:
void kbdintr(void)
{
consoleintr(kbdgetc);
}
void uartintr(void)
{
consoleintr(uartgetc);
}
void consoleintr(int (*getc)(void));
这两者的中断处理程序都是另外调用 ,我且称之为控制台中断服务程序,其参数是一个函数指针,指向从键盘获取字符的函数或者串口获取字符的函数。其函数功能就是针对键盘或者串口的输入做出相应的操作,具体来看:
void consoleintr(int (*getc)(void)){
/*********略*********/
acquire(&cons.lock);
while((c = getc()) >= 0){
这一步获取控制台的锁,同一时刻只能有一个进程在控制台获取输入打印消息。然后调用相应的函数获取输入的字符,是键盘就调用 ,是串口就调用
。先来看看对
组合键的处理
组合键
case C('P'): // Process listing.
doprocdump = 1;
break;
如果是 就打印进程信息和栈帧里面的函数调用链,这个函数就不说明了,就是获取进程表里面进程结构体的信息,而函数调用链是调试用的,这在锁一文中说过
case C('U'): //清空当前行
while(input.e != input.w &&
input.buf[(input.e-1) % INPUT_BUF] != '\n'){
input.e--;
consputc(BACKSPACE);
}
break;
case C('H'): case '\x7f': //退格
if(input.e != input.w){
input.e--;
consputc(BACKSPACE);
}
break;
清空当前的输入行,
是退格,
表示的
删除键,这里通通都是用退格来实现的。退一格,编辑位就向前移动一个字符,如果碰到换行符或者
时就停下来。
default:
if(c != 0 && input.e-input.r < INPUT_BUF){ //普通字符
c = (c == '\r') ? '\n' : c;
input.buf[input.e++ % INPUT_BUF] = c;
consputc(c);
if(c == '\n' || c == C('D') || input.e == input.r+INPUT_BUF){
input.w = input.e;
wakeup(&input.r);
}
}
break;
这部分处理普通字符和一些特殊字符,每从键盘或者串口读入一个字符就将这个字符放进缓冲区,然后将编辑位 ,如果这个字符是换行符或者 EOF 又或者缓存区满了,就使
,使得 w 来标识当前一段数据的末尾和下一段数据的开始。其中
组合键表示一个
字符,若在控制台的
程序使用
会使
退出,这跟
是一样的,具体原因在下一篇
再讲述。
这里还要说明一点:对回车换行的处理:
- 回车
'\r',原意是回到行首 - 换行
'\n',愿意是换到当前位置的下一行,不会回到行首
还有
对
'\n' 的处理是既回车又换行,还记得 里面
pos += 80 - pos\%80; 吗?这就是回车换行了。而 键对应的是什么呢?回车?换行?这个要看什么,这个需要查看按键的映射表,
映射到了
码的
表示回车键,
映射到了字符
'\n',虽然映射到的 字符不一样,但操作是一样的,都对
键做回车换行处理。另外
将
'\r' 也作为 '\n' 字符处理,即回车加换行。
这些回车换行退格,字符,键,处理方式,它们之间有些混乱,最好去实践试一下就清楚了,别管他们如何变换,我们抓住本质就是:
按键具有的各种意义都是我们认为赋予的,每个键都有其对应的键盘扫描码,扫描码值可以看作这个键的物理意义。我们创建了几张映射表,可以将扫描码映射到逻辑意义,比如键 1 扫描码为 ,通过普通映射表将其映射为字符
'1'。
这是普通可显式的字符,还有控制字符,以及转义字符如 '\n',比如 将
键扫描码
映射到字符
'\n',然后在 函数里面检测到这是个特殊字符
'\n',所以做特殊操作,移动光标位置来实现回车换行
还有组合键的实现,比如组合键 ,对于
组合键,有专门的
映射表,比如我按下
,就会去
映射表寻找
对应的逻辑意义,其实就是个数,然后
函数就会根据其值做出相应的操作
键入一个键到显示
我们天天打字,按下一个键屏幕就有相应的显示,如果是特殊键的话还有特殊的操作,这里我们就来捋一捋按下一个可显示字符后到屏幕显示这之间发生了什么,这应该也是很多朋友在学计算机初曾思考过的一个问题,这里我们以键入 A 到输出 A 为例,直接来看图:
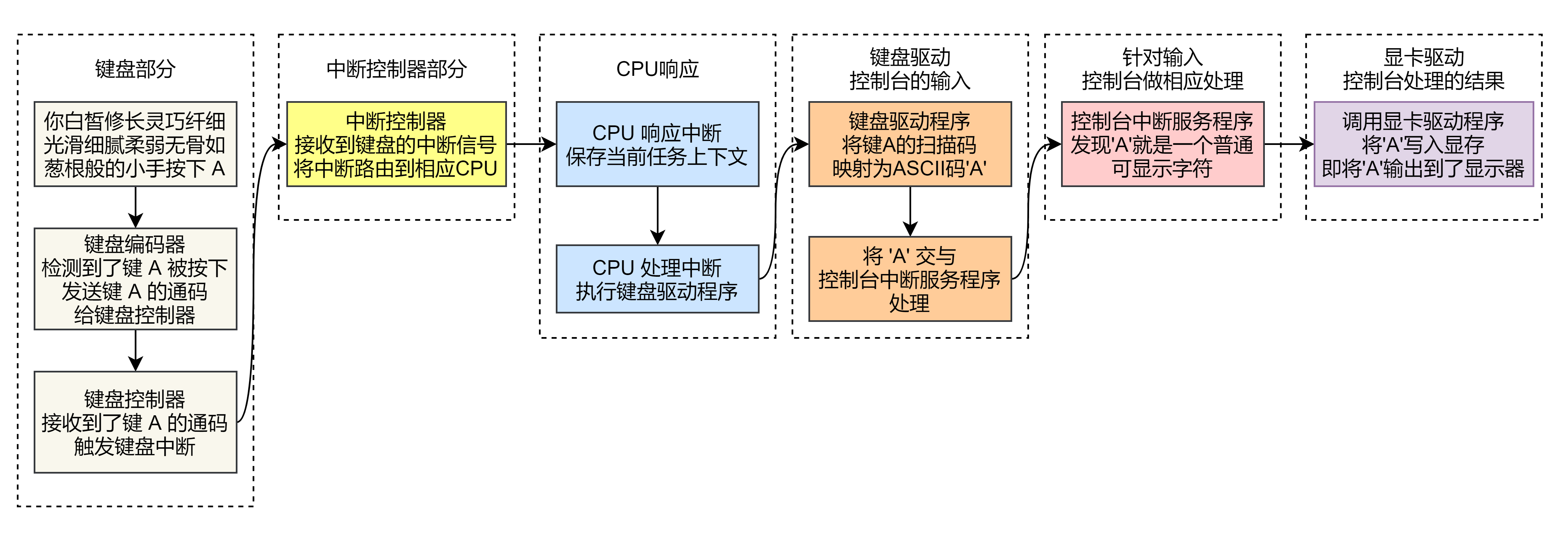
就这一张图应该很清晰了,至于按键部分嗯强迫症晚期患者,想要填充字数来对齐,顺便多积累点词汇以后好夸女朋友。
读写控制台文件
好了关于控制台中断处理程序就说这么多,在 和
眼里,控制台就是个设备文件,下面来看看如何从控制台文件中读写数据,首先读操作:
int consoleread(struct inode *ip, char *dst, int n){
uint target;
int c;
iunlock(ip); //释放inode ip
target = n; //准备要读取的字节数
acquire(&cons.lock); //获取控制台的锁
这部分释放控制台文件的 ,为什么释放呢?控制台本身配了一把锁
,而控制台也是个文件,是文件就对应着一个
,
也是有一把锁的,当我们获取了控制台的锁之后,控制台文件
的锁就可以解放出来了。但在读写控制台操作完成的时候需要重新获取
的锁来保持前后一致性。
while(n > 0){
while(input.r == input.w){ //要读取的数据还没到
if(myproc()->killed){ //如果该进程已经被killed
release(&cons.lock);
ilock(ip);
return -1;
}
sleep(&input.r, &cons.lock); //休眠在缓冲区的r位上
}
这部分一个 循环,目的是读取
个字符,首先判断缓冲区的
位和
位是否相等,
的时候说明想要读取的这段数据数据还没来(完),那么休眠。
c = input.buf[input.r++ % INPUT_BUF]; //缓存区读取标识索引后移
if(c == C('D')){ // EOF
if(n < target){
// Save ^D for next time, to make sure
// caller gets a 0-byte result.
input.r--;
}
break;
}
*dst++ = c; //搬运字符
--n; //还需要读取的字符数减1
if(c == '\n') //如果是换行符
break; //跳出循环准备返回
}
release(&cons.lock); //释放控制台的锁
ilock(ip); //重新获取inode的锁
return target - n; //返回实际读取的字节数
}
这部分就是实际读取缓冲区的字符到目的地 ,主要是换行符和
符的处理可能有点困扰,一段数据以
'\n' 或者 EOF 结尾,碰到这两个字符时就跳出循环退出。而对于 EOF 还要做特殊处理,将 r-- 使得 指向
EOF 字符,这样下次调用 就不会读取到任何数据,返回 0,这是有特殊用处的,比如
程序碰到这种情况就会退出,这我们到
再细说。
关于读取控制台数据可能有些繁琐,但实际不难,讲解这种感觉动图是最好解释的,但动图画的差也难得画挺复杂的,这里就抓住
所表示的意义,自己举些例子模拟一下应该也没什么问题。接着来看控制台读取函数:
int consolewrite(struct inode *ip, char *buf, int n)
{
int i;
iunlock(ip); //释放控制台文件inode的锁
acquire(&cons.lock); //获取控制台的锁
for(i = 0; i < n; i++) //循环n次
consputc(buf[i] & 0xff); //向控制台写字符
release(&cons.lock); //释放控制台的锁
ilock(ip); //重新获取控制台文件inode的锁
return n;
}
向控制台文件写就很简单了,直接看注释,很清晰不多解释
struct devsw {
int (*read)(struct inode*, char*, int);
int (*write)(struct inode*, char*, int);
};
struct devsw devsw[NDEV];
#define NDEV 10 // maximum major device number
#define CONSOLE 1
void consoleinit(void)
{
initlock(&cons.lock, "console");
devsw[CONSOLE].write = consolewrite; // #define CONSOLE 1
devsw[CONSOLE].read = consoleread;
cons.locking = 1;
ioapicenable(IRQ_KBD, 0);
}
结构体 是一类设备的读写函数,两元素都是指向设备的读写函数指针。还定义了一个同名结构体数组
,大小为
,表示支持的设备类型有
种,就是那个主设备号
最大值为 10。
初始化控制台就是将控制台的读写函数写进 ,然后将键盘中断路由到
,所以这里应该就能完全理解文件系统那一块的
和
函数了,其中有个
语句块:
if(ip->type == T_DEV){
if(ip->major < 0 || ip->major >= NDEV || !devsw[ip->major].write)
return -1;
return devsw[ip->major].write(ip, src, n);
}
这就是说如果 指向的类型是个设备文件,那么就调用相应的设备读写函数,应该是很清晰的。到此应该清楚为什么可以把设备也看作是一种文件了吧,它与普通文件在上层并没有多大的区别,只是在实际读写文件的时候调用不同的函数罢了。
这个清楚了之后我们在往前捋一捋,为什么文件描述符 表示标准输入输出,也就输入和输出都来自控制台,在
文件中(
进程执行的程序)创建了控制台文件:
if(open("console", O_RDWR) < 0){
mknod("console", 1, 1); //创建控制台文件,major=1,minor=1
open("console", O_RDWR); //打开控制台文件
}
dup(0); // stdout
dup(0); // stderr
这里调用 创建一个控制台文件,然后打开。所以此时进程的文件表有一个文件结构体,这个结构体文件表示控制台文件,文件描述符表中文件描述符 0 指向这个文件结构体。调用
函数之后,文件描述符 1,2 也指向了文件表中的控制台文件结构体,如下图所示:
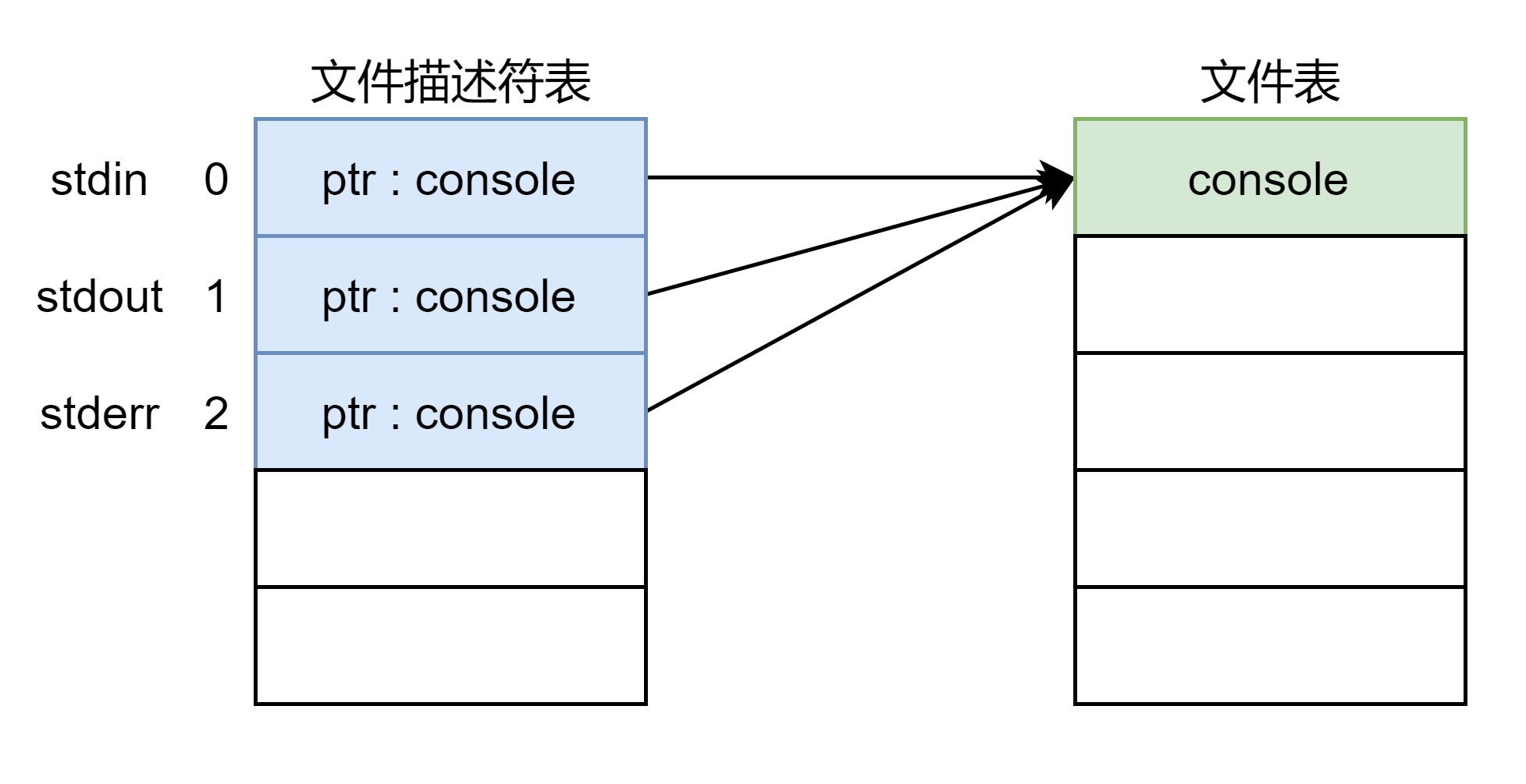
所以说当我们调用 和
系统调用时,指定文件描述符如果为
,则它们指向控制台文件结构体,读写也就是读写的控制台文件,来看流程图:
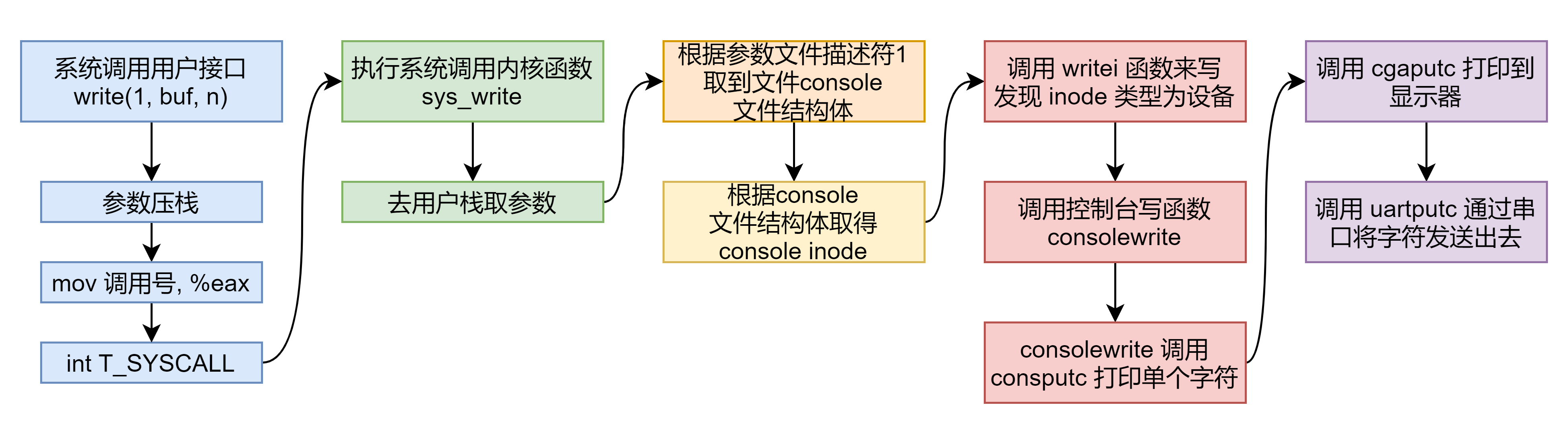
实现  函数
函数
函数有两个,一个是内核使用,一个是用户态使用。内核的
函数可以直接调用
来实现,而用户态下的
通过
系统调用实现,而关于
系统调用如何写控制台文件上面应该解释的很清楚了,这里就直接来看用户态下如何实现
函数,首先打印单个字符的函数:
static void putc(int fd, char c)
{
write(fd, &c, 1);
}
调用
来打印单个字符,而
就是
的封装,因为
支持格式化输出,所以多了对字符串的格式化处理,但本质上就是对
的封装,这种实现形式并不高效,每打印一个字符都要执行一次系统调用。
的函数原型如下:
int printf(const char *fmt, ...);
void printf(int fd, const char *fmt, ...);
第一个 是
里面的标准库函数,第二个是
里面的版本,本质上是差不多的。
与其他函数不同的地方在于有个参数
... ,这就表示支持变长参数,变长参数就是说传参时可以传 “任意” 个参数,但一般正常来说的话,这个参数个数要与格式化字符串里面的 '%' 相匹配,否则就可能出错。
只要对参数在栈里面的布局情况比较清楚,要实现变长参数也不是什么困难的事情。其关键点是至少有一个固定参数且这个固定参数在栈中的位置能够确定下来。在 里面的表现就是有一个固定参数——格式化字符串,它的位置我们是能够确定的,在返回地址的上面。只要找到了这个固定参数的位置那么我们就知道其上是下一个参数位置,依次下去,重复 % 个数那么多次就能够找到所有的参数,这就是实现变长参数的基本原理。
在 里面有三个宏来辅助实现:
typedef char* va_list
#define va_start(ap, v) ap = (va_list)&v
#define va_arg(ap, t) *((t*)(ap += 4))
#define va_end(ap) ap = NULL
使得
指向固定参数,对于
来说就是
,
本身是一个字符串指针,指向它,说明
是个二级指针。至于为什么是二级指针,我们要清楚平常传参字符串都是传的这个字符串的指针,也就是字符串的地址,所以参数是个地址值。实现变长参数需要的是参数的地址,所以就应该是这个地址值的地址,二级指针没问题。
使得
指向下一个参数的地址,做类型转换再解引用返回其值。加 4 是因为一般用到的类型如
、
、指针等等在传参压栈的时候实际上都是占用 4 字节,这涉及到了默认参数提升,
的缺陷和陷进,不细说,后面有相关文章链接。
将
置为
没有使用这三个宏,但也有相应的操作,来看实际代码:
void printf(int fd, const char *fmt, ...){
/*******略*******/
state = 0; //当前字符状态:普通字符还是'%'
ap = (uint*)(void*)&fmt + 1; //第一个可变参数地址
表示初始化当前的状态为 0,因为要对
做特殊处理,所以使用
来记录当前字符是一个普通字符还是 '%'。
接着将 指向第一个可变参数的地址,也就是
后面那个参数的地址
for(i = 0; fmt[i]; i++){ //循环次数为字符串里面的字符数
c = fmt[i] & 0xff; //从字符串里取第i个字符
if(state == 0){ //如果这个字符前面不是%
if(c == '%'){ //如果当前字符是%
state = '%'; //记录状态为%
} else { //如果当前字符不是%
putc(fd, c); //调用putc向fd指向的文件写字符c
}
这部分处理普通的字符,注释很详细不再赘述
} else if(state == '%'){ //如果当前字符前面是一个%说明需要格式化处理
if(c == 'd'){ //如果是%d
printint(fd, *ap, 10, 1); //调用printint打印有符号十进制数
ap++; //参数指针指向下一个参数
} else if(c == 'x' || c == 'p'){ //如果是%x,%p
printint(fd, *ap, 16, 0); //调用printint打印无符号十六进制数
ap++; //参数指针指向下一个参数
} else if(c == 's'){ //如果是%s
s = (char*)*ap; //取这个参数的值,这个参数值就是字符串指针
ap++; //参数指针指向下一个参数
if(s == 0) //如果字符串指针指向0
s = "(null)"; //不出错,而是赋值"(null)"
while(*s != 0){ //while循环打印字符串s
putc(fd, *s);
s++;
}
} else if(c == 'c'){ //如果是%c
putc(fd, *ap); //打印这个字符
ap++; //参数指针指向下一个参数
} else if(c == '%'){ //如果是%%
putc(fd, c); //打印%
} else { //其他不明情况比如%m,那么就打印%m不做处理
// Unknown % sequence. Print it to draw attention.
putc(fd, '%'); //打印%
putc(fd, c); //打印字符
}
state = 0; //state归于0普通状态
}
上述就是 的
函数,注释十分详细,过一遍基本能懂,稍稍注意两个点就行,一是处理
%s 时,二级指针要正确使用,另外如果 字符串指针指向 0,并没有做错误处理,而是打印字符串 (null),在进程那一块我说过,xv6 里面 0 地址是映射了的,可以访问,只是在这之前有一层编译保护,使得访问 0 地址非法,但是如果不优化处理,是能够访问的。
另外 这个函数我没讲述,原型是:
void printint(int fd, int xx, int base, int sgn);
它的作用是将整数 按照相应的进制
有无符号
打印出来,初学计算机的时候应该就碰见过这类编程题,所以不赘述了。
到此 也完事了,其流程图就跟上面
差不多,还是以便准输出为例:

读写这条线
了解了文件系统和控制台之后再来看看前言出现过的读写这条线:
结尾总结
本文主要讲述了控制台的输入输出,涉及到了三种硬件的编程,键盘显卡还有串口,硬件方面还是需要专业人员来讲述,我的水平讲述这些肯定是欠缺的,只是片面的罗列出了一些用到的地方,有困惑的感兴趣的可以参考下面链接。
另外本文最开始所说的几个问题现在应有所答案了吧,键入一个字符到输出到屏幕这之间的过程是怎样的?为什么文件描述符 表示标准输入输出?为什么
系统调用使用文件描述符
就会将消息打印到屏幕?
函数又是如何实现的?对这几个问题都有相应的流程图,私以为把这几条线捋得还是很清楚得。
好了本节就这样吧,有什么问题还请批评指正,也欢迎大家来同我讨论交流学习进步。