
Enhanced LSTM for Natural Language Inference(ESIM)阅读笔记
文章目录
模型介绍
Hybrid Neural Inference Models
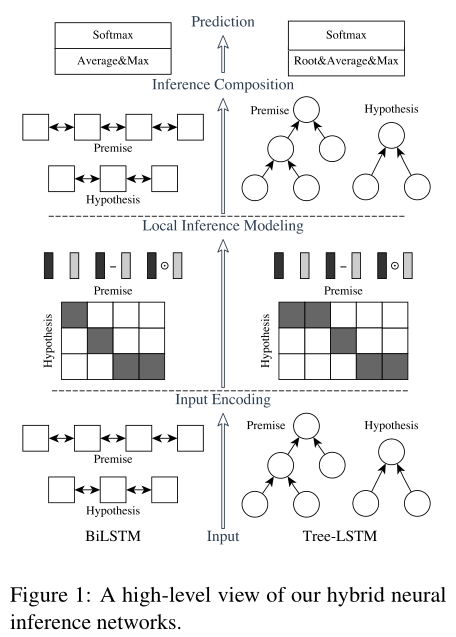
可以用BiLSTM编码, 也可以使用Tree-LSTM.
这里只介绍基于BiLSTM的结构.
1. Input Encoding
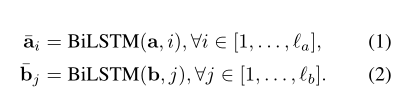
输入两句话分别接embeding + BiLSTM
2. Local Inference Modeling
就是一个计算attention的过程
Locality of inference
首先计算两个句子 word 之间的相似度,得到2维的相似度矩阵.
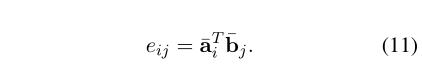
Local inference collected over sequences
利用前面的词相似矩阵, 进行两句话的 local inference. 用之前得到的相似度矩阵,结合 a,b 两句话,互相生成彼此相似性加权后的句子.attention的常规操作,公式如下
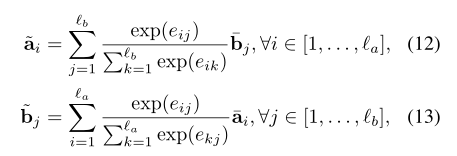
Enhancement of local inference information
利用减法和element-wise product计算 <aˉ,a~>之间的差异
然后,将得到的向量进行拼接
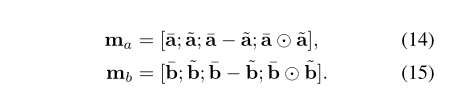
3. Inference Composition
The composition layer
和之前input encoding一样, 将上一步得到的 ma,mb再送入BiLSTM.
但是这里目的不同, 它们用于捕获局部推理信息 ma和 mb以及它们的上下文,以便进行推理组合。
Pooling
同时使用 MaxPooling 和 AvgPooling 进行池化操作, 最后接一个全连接层(tanh作为激活函数)+softmax
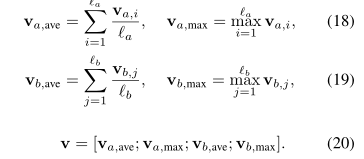
实验
参数设置
batch_size: 32
optimizer: Adam, 其中(momentum设为0.9, 0.999)
learning_rate: 0.0004
word embedding: 300
dropout: 0.5
hidden size: 300
OOV问题: initialized randomly with Gaussian samples
损失函数: 多分类的cross-entropy loss
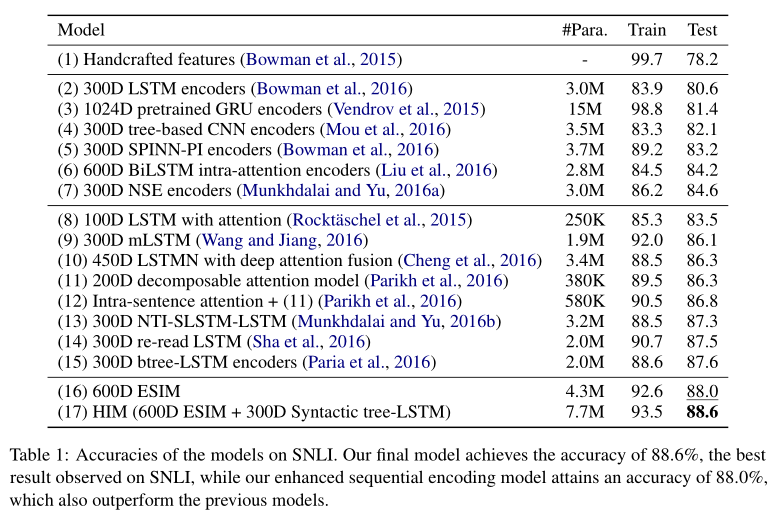
实验结果
数据集使用SNLI, acc作为评价指标

 查看17道真题和解析
查看17道真题和解析