
分类网络 DenseNet
DenseNet
论文:Densely Connected Convolutional Networks
DenseNet是在ResNet之后的一个分类网络,连接方式的改变,使其在各大数据集上取得比ResNet更好的效果.
网络结构
以DenseNet-121为例,介绍网络的结构细节.
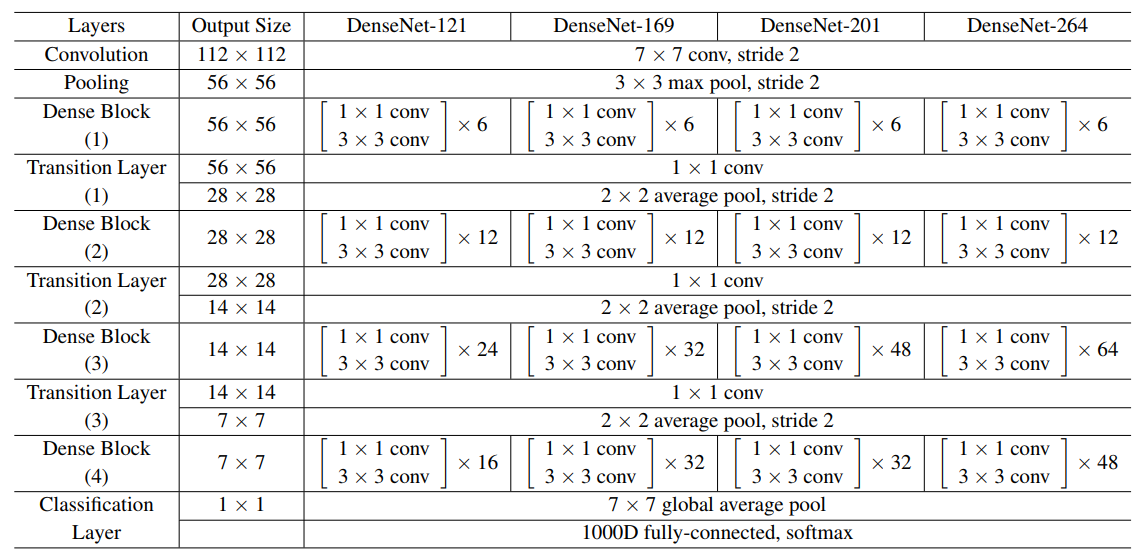
网络结构一开始与ResNet类似,先进行一个大尺度的卷积,再接一个池化层;随后接上连续几个子模块(Dense Block和Transitin Layer);最后接上一个池化和全连接.
以下重点介绍Dense Block 和 Transition layer.
Dense Block
从图中可以看到,第一个DenseBlock包含6个[1*1 conv, 3*3 conv], 此处的[1*1 conv, 3*3 conv]即为Bottleneck结构,具体如下:
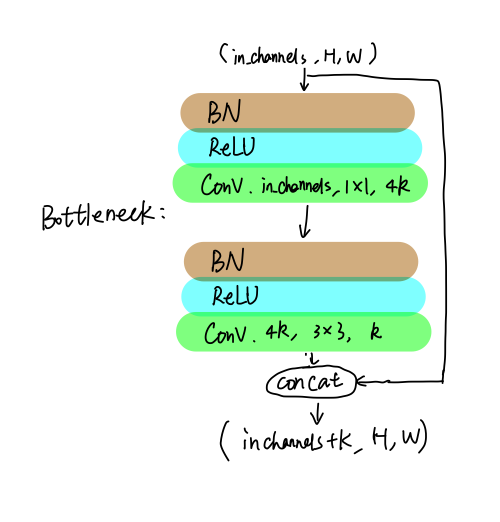
我字怎么这么丑 = =!
BottleNeck包含两个卷积,和常规的卷积-BN-ReLU模式不一样,此处的BN-ReLU放在卷积前面(有文章实验证明过这样效果更好).1*1卷积的输出通道数是 4∗k,此处k是一个特征图增长系数,可以理解成BottleNeck贡献的特征图个数;3*3卷积的输出通道数是 k;整个模块的输出是将输入和3*3卷积的输出堆叠在一起(concat),即共输出 in_channels+k个通道.
接下来介绍为什么网络是密集连接的!
DenseNet-121的第一个DenseBlock包含了6个BottleNeck,BottleNeck之间是串联在一起的.
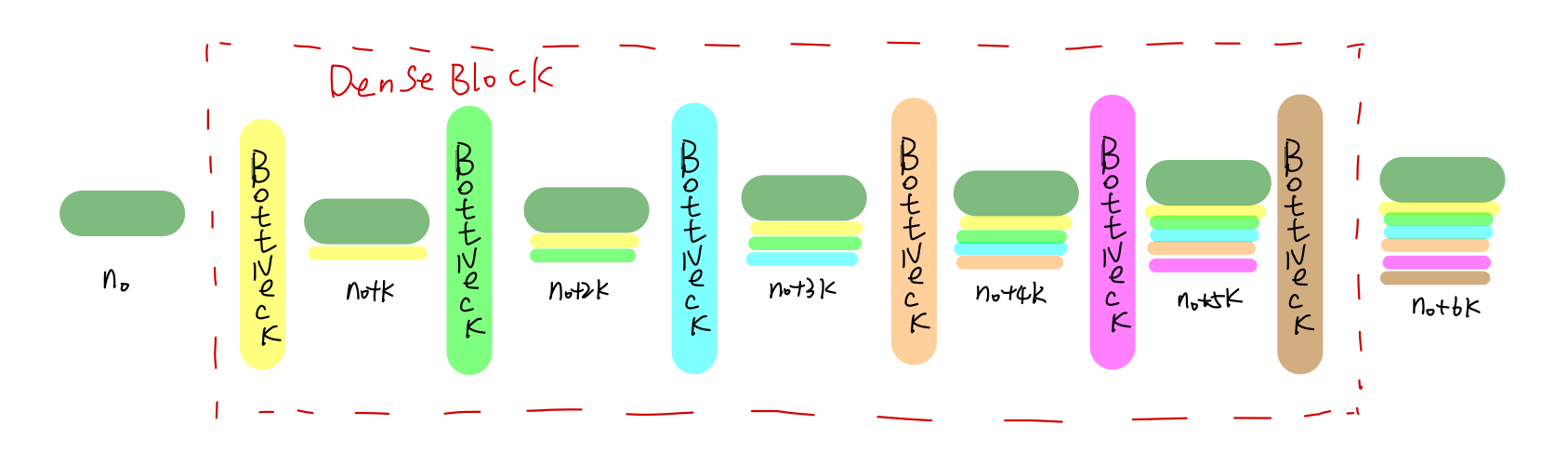
图中横向表示特征图,纵向表示BottleNecks.整个DenseBlck的输入通道个数为 n0.相应颜色的BottleNeck产生对应颜色的 k个特征图.由于BottleNeck的输出将本身的输出( k个通道)和输入concat在一起了,所以输出为 n0+k个通道,以此类推,后续通道数每经过一个BottleNeck,通道数增加 k个(所以称 k为通道增加系数).
以粉红***ottleNeck为例,说明整个DenseBlock为密集连接.
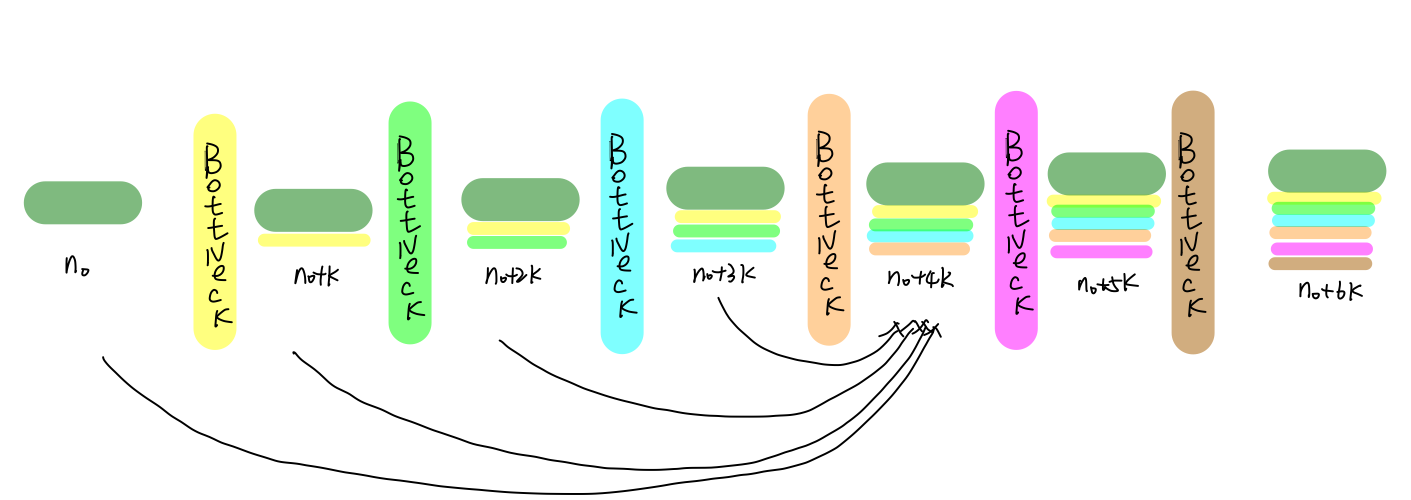
仔细观察粉红***otteNeck的输入,其实是来自于前面每一层BottleNeck输出和原始输入的堆叠.而且每一个BottleNeck的输入都是其前面所有层输出的堆叠,这就是DenseNet为什么是密集连接的原因,也是DenseNet取得良好效果的原因:
- 传递到粉红***ottleNeck的梯度,能直接传递到其前面各层BottleNeck中,一方面避免了梯度消失,另一方面加快了参数的迭代速度,提高了训练效率
- 网络在前向传播过程中,每个BottleNeck利用其前面所有网络层的输出结果作为输入,产生 k个特征图.作者认为这是一个利用当前"集体成果"(前面所有层的输出),产生新特征,同时再将新特征加入"集体成果"中,不断成长壮大的过程.
- ResNet中BottleNeck的输出和原始输入的融合方式采用的是相加,作者认为这种方式会破坏已经学到的特征,因此采用concat的方式.
Transition layer
Transition Layer就比较平平无奇了,是一个卷积加池化,用于整合学到的特征,降低特征图的尺寸.
小结
网络四个优点
- 减轻梯度消失
- 提高了特征的传播效率
- 提高了特征的利用效率
- 减小了网络的参数量
