
丢个板子在这方便我复制喵
语法相关
关闭流输入输出
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
快读快写
inline ll read(){
ll sum = 0,fl = 1;
int ch = getchar();
for(;!isdigit(ch);ch = getchar())
if(ch=='-')
fl = -1;
for(;isdigit(ch);ch = getchar())
sum = sum*10+ch-'0';
return fl*sum;
}
inline void write(ll x){
static int sta[35];
int top = 0;
if(x<0)
putchar('-'),x=-x;
do{
sta[top++] = x%10,x/=10;
}while(x);
while(top)
putchar(sta[--top]+48);
putchar('\n');
}
文件读入输出
freopen("mid.in","r",stdin); //从文件mid.in里读取数据
freopen("mid.out","w",stdout); //程序运行会创建文件mid.out将结果写入
以文件作为输入编译运行
PS D:\Homework> g++ -o E "D:\Homework\AtCoder\AtCoder Beginner Contest 325\E.cpp"
PS D:\Homework> Get-Content "D:\Homework\AtCoder\AtCoder Beginner Contest 325\testcase01.txt" | .\E
auto遍历map
#include <iostream>
#include <map>
int main() {
std::map<std::string, int> myMap = {{"apple", 1}, {"orange", 2}, {"pear", 3}};
// 使用 auto 关键字和范围for循环
for (auto& pair : myMap) {
std::cout << pair.first << ": " << pair.second << std::endl; // 自动推导 pair 的类型为 std::pair<const std::string, int>&
}
return 0;
}
函数内定义函数
用auto
void outerFunction() {
// 在函数内部定义一个 lambda 表达式
auto innerFunction = [](int x, int y) -> int {
return x + y;
};
int result = innerFunction(3, 4); // 调用 lambda 表达式
std::cout << "Result: " << result << std::endl;
}
用std::function
需要传入和返回值的示例
#include <functional>
void outerFunction() {
// 定义一个 std::function 来表示内嵌函数
std::function<int(int, int)> innerFunction = [](int x, int y) -> int {
return x - y;
};
int result = innerFunction(10, 4); // 调用 std::function
std::cout << "Result: " << result << std::endl;
}
void函数的示例
#include <functional>
int main(){
std::function<void()> func = [](){
std::cout << "Lambda function test!" << std::end1;
};
func(); //调用封装的lambda表达式
return 0;
}
std::set
insert: 向集合中插入元素。
emplace: 在集合中就地构造元素。
erase: 从集合中删除指定元素。
find: 查找集合中是否存在指定元素。
count: 返回集合中与指定元素相等的元素的数量(通常为0或1)。
clear: 清空集合中的所有元素。
size: 返回集合中元素的数量。
empty: 检查集合是否为空。
swap: 交换两个集合的内容。
begin: 返回指向集合中第一个元素的迭代器。
end: 返回指向集合中最后一个元素之后位置的迭代器。
lower_bound: 返回指向第一个不小于给定键值的元素的迭代器。
upper_bound: 返回指向第一个大于给定键值的元素的迭代器。
equal_range: 返回一个范围,其中包含所有与给定键值相等的元素。
max_size: 返回集合能容纳的最大元素数量。
自定义set的排序规则以及重载运算符的写法
#include <iostream>
#include <set>
// 自定义比较函数
bool customCompare(int a, int b) {
// 实现自定义的比较逻辑,这里以整数的绝对值大小为例
return abs(a) < abs(b);
}
// 自定义函数对象(Functor)
struct CustomComparator {
bool operator()(int a, int b) const {
// 实现自定义的比较逻辑,这里以整数的平方大小为例
return (a * a) < (b * b);
}
};
int main() {
// 使用自定义比较函数创建 std::set
std::set<int, decltype(&customCompare)> customSet(customCompare);
// 使用自定义函数对象创建 std::set
std::set<int, CustomComparator> functorSet;
// 插入元素
customSet.insert(5);
customSet.insert(-3);
customSet.insert(2);
functorSet.insert(5);
functorSet.insert(-3);
functorSet.insert(2);
// 遍历输出结果
std::cout << "Custom compare function set: ";
for (int num : customSet) {
std::cout << num << " ";
}
std::cout << std::endl;
std::cout << "Functor set: ";
for (int num : functorSet) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
std::bitset
bitset<1000>a; //定义长度为1000的01串
a[0]=1; //没有定义的默认为0
a.count() //返回a中1的个数
a.set(i) //把第i位设为1
a.reset(i) //把第i位设为0
std::map
map
优点:有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作;红黑树,内部实现一个红黑数使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高。
缺点: 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
适用处:对于那些有顺序要求的问题,用map会更高效一些
unordered_map
优点: 因为内部实现了哈希表,因此其查找速度非常的快
缺点: 哈希表的建立比较耗费时间
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
std::array
array<int, 5> 表示一个包含 5 个 int 的数组
访问元素
- 通过索引:使用 arr[index] 或 at(index)。
- arr[index]:普通索引访问,不检查边界。
- arr.at(index):带边界检查,如果越界会抛出 std::out_of_range 异常。
- 其他方法:
- front():返回第一个元素。
- back():返回最后一个元素。
大小查询
- size():返回数组元素个数。
- empty():检查数组是否为空(对于 std::array 总是返回 false,因为大小固定)。
- max_size():返回数组的最大可能大小(等于 size())。
初始化
-
可以用初始化列表:std::array<int, 3> arr = {1, 2, 3};
-
如果初始化的元素少于数组大小,未指定的元素会被自动初始化为默认值(例如 0 对于 int):
std::array<int, 5> arr = {1, 2}; // 等价于 {1, 2, 0, 0, 0}
数组去重
vector<int> v;
//使用unique前必须排序(他只能删除相邻相同的元素,背过即可)
sort(v.begin(),v.end());
// unique(v.begin(),v.end())返回的是不重复元素的下一个
//背过即可
v.erase(unique(v.begin(),v.end()),v.end());
算法基础篇
前缀和&差分
前缀和
一维前缀和
#include <iostream>
using namespace std;
int N, A[10000], B[10000];
int main() {
cin >> N;
for (int i = 0; i < N; i++) {
cin >> A[i];
}
// 前缀和数组的第一项和原数组的第一项是相等的。
B[0] = A[0];
for (int i = 1; i < N; i++) {
// 前缀和数组的第 i 项 = 原数组的 0 到 i-1 项的和 + 原数组的第 i 项。
B[i] = B[i - 1] + A[i];
}
for (int i = 0; i < N; i++) {
cout << B[i] << " ";
}
return 0;
}
二维/多维前缀和
例:在一个 的只包含
和
的矩阵里找出一个不包含
的最大正方形,输出边长。
#include <algorithm>
#include <iostream>
using namespace std;
int a[103][103];
int b[103][103]; // 前缀和数组,相当于上文的 sum[]
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
cin >> a[i][j];
b[i][j] =
b[i][j - 1] + b[i - 1][j] - b[i - 1][j - 1] + a[i][j]; // 求前缀和
}
}
int ans = 0;
int l = 1;
while (l <= min(n, m)) { // 判断条件
for (int i = l; i <= n; i++) {
for (int j = l; j <= m; j++) {
if (b[i][j] - b[i - l][j] - b[i][j - l] + b[i - l][j - l] == l * l) {
ans = max(ans, l); // 在这里统计答案
}
}
}
l++;
}
cout << ans << endl;
return 0;
}
三维前缀和的参考实现
#include <iostream>
#include <vector>
int main() {
// Input.
int N1, N2, N3;
std::cin >> N1 >> N2 >> N3;
std::vector<std::vector<std::vector<int>>> a(
N1 + 1, std::vector<std::vector<int>>(N2 + 1, std::vector<int>(N3 + 1)));
for (int i = 1; i <= N1; ++i)
for (int j = 1; j <= N2; ++j)
for (int k = 1; k <= N3; ++k) std::cin >> a[i][j][k];
// Copy.
auto ps = a;
// Prefix-sum for 3rd dimension.
for (int i = 1; i <= N1; ++i)
for (int j = 1; j <= N2; ++j)
for (int k = 1; k <= N3; ++k) ps[i][j][k] += ps[i][j][k - 1];
// Prefix-sum for 2nd dimension.
for (int i = 1; i <= N1; ++i)
for (int j = 1; j <= N2; ++j)
for (int k = 1; k <= N3; ++k) ps[i][j][k] += ps[i][j - 1][k];
// Prefix-sum for 1st dimension.
for (int i = 1; i <= N1; ++i)
for (int j = 1; j <= N2; ++j)
for (int k = 1; k <= N3; ++k) ps[i][j][k] += ps[i - 1][j][k];
// Output.
for (int i = 1; i <= N1; ++i) {
for (int j = 1; j <= N2; ++j) {
for (int k = 1; k <= N3; ++k) {
std::cout << ps[i][j][k] << ' ';
}
std::cout << '\n';
}
std::cout << '\n';
}
return 0;
}
树上前缀和
**例:**给定一棵 n 个节点的树,多次询问 x, y 路径上的节点和。
给定点权的情况
设 acc[i] 表示从根节点到节点 i 的点权和。
先自顶向下 dfs 计算出前缀和 acc[],然后用前缀和拼凑(x, y)的路径和。
acc[x] + acc[y] - acc[lca(x, y)] - acc[fa(lca)]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=1e6+10;
vector<int> G[N];// 邻接表存树
int father[N];// 父节点
ll a[N];// 点权
ll acc[N];// 表示根节点到当前节点的路径上的点权和
void dfsGetAcc(int u,int fa)
{
if(u==0) return;
acc[u]=a[u];
if(acc[fa]!=0)
{
acc[u] += acc[fa];
return ;
}
dfsGetAcc(fa,father[fa]);
acc[u]+=acc[fa];
}
int n;
int dfsGetLca(int u,int v)
{
while(u!=v)
{
if(u>v) swap(u,v);
v=father[v];
}
return u;
}
ll query(int x,int y)// acc[x] + acc[y] - acc[lca(x, y)] - acc[fa(lca)]
{
int lca=dfsGetLca(x,y);
return acc[x]+acc[y]-acc[lca]-acc[father[lca]];
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%lld",&a[i]);
}
for(int i=2;i<=n;i++)
{
int fa;
scanf("%d",&fa);
G[fa].push_back(i);
father[i]=fa;
}
for(int i=1;i<=n;i++)
{
dfsGetAcc(i,father[i]);
}
int q;
scanf("%d",&q);
while(q--)
{
int x,y;
scanf("%d%d",&x,&y);
printf("%lld\n",query(x,y));
}
return 0;
}
复杂度是的
给定边权的情况
设 acc[i] 表示从根节点到节点i的边权和
先自顶向下 dfs 计算出前缀和 acc[],然后用前缀和拼凑(x, y)的路径和。
acc[x] + acc[y] - 2 · acc[lca(x, y)]
前缀积
-
给定一个长度大小为
的正整数数组, 查询
轮, 每次问一个区间所有元素的连续乘积
由于这个答案可能很大, 你只用输出结果对
取余数后的结果即可
LL get_inv(LL x) //乘法逆元
{
return quickpow(x, mod - 2, mod);
}
premul[0] = 1;
for(int i = 1; i <= n; i++)
premul[i] = premul[i - 1] * a[i] % mod;
LL ans = premul[r] * get_inv(premul[l - 1]) % mod;
前缀矩阵积
struct Mat
{
LL a[MAX_MAT][MAX_MAT];
Mat()
{
for(int i = 0; i < MAX_MAT; i++)
for(int j = 0; j < MAX_MAT; j++)
if(i == j) a[i][j] = 1;
else a[i][j] = 0;
}
Mat(LL a1, LL a2, LL a3, LL a4)
{
a[0][0] = a1;
a[0][1] = a2;
a[1][0] = a3;
a[1][1] = a4;
}
};
LL A[MAX_MAT][MAX_MAT << 1];
//求逆元
LL get_inv(LL x)
{
return quickpow(x, mod - 2, mod);
}
//行变换: 第a行减去第b行的k倍
void row_minus(int a, int b, LL k)
{
for(int i = 0; i < 2 * MAX_MAT; i++)
{
A[a][i] = (A[a][i] - A[b][i] * k % mod) % mod;
if(A[a][i] < 0) A[a][i] + mod;
}
}
//行变换: 第a行乘以k
void row_multiplies(int a, LL k)
{
for(int i = 0; i < 2 * MAX_MAT; i++)
A[a][i] = (A[a][i] * k) % mod;
}
//行变换: 交换第a行和第b行
void row_swap(int a, int b)
{
for(int i = 0; i < 2 * MAX_MAT; i++)
swap(A[a][i], A[b][i]);
}
//求逆矩阵
Mat getinv(Mat x)
{
memset(A, 0, sizeof A);
for(int i = 0; i < MAX_MAT; i++)
for(int j = 0; j < MAX_MAT; j++)
{
A[i][j] = x.a[i][j];
A[i][MAX_MAT + j] = i == j;
}
for(int i = 0; i < MAX_MAT; i++)
{
if(!A[i][j])
{
for(int j = i + 1; j < MAX_MAT; j++)
if(A[j][i])
{
row_swap(i, j);
break;
}
}
row_multiplies(i, get_inv(A[i][i]));
for(int j = i + 1; j < MAX_MAT; j++)
row_minus(j, i, A[j][i]);
}
for(int i = MAX_MAT - 1; i >= 0; i--)
for(int j = i - 1; j >= 0; j--)
row_minus(j, i, A[j][i]);
Mat ret;
for(int i = 0; i < MAX_MAT; i++)
for(int j = 0; j < MAX_MAT; j++)
ret.a[i][j] = A[i][MAX_MAT + j];
return ret;
}
Mat operator * (Mat x, Mat y)
{
Mat c;
for(int i = 0; i < MAX_MAT; i++)
for(int j = 0; j < MAX_MAT; j++)
c.a[i][j] = 0;
for(int i = 0; i < MAX_MAT; i++)
for(int j = 0; j < MAX_MAT; j++)
for(int k = 0; k < MAX_MAT; k++)
c.a[i][j] = (c.a[i][j] + x.a[i][k] * y.a[k][j] % mod) % mod;
return c;
}
presum[0] = Mat(1, 0, 0, 1);
for(int i = 1; i <= n; i++)
presum[i] = presum[i - 1] * t[i];
Mat ans = getinv(presum[l - 1]) * presum[r]; //矩阵乘法不能交换顺序
差分
差分,就是前缀和的逆运算
一维差分
**例:**输入一个长度为n的整数序列。接下来输入m个操作,每个操作包含三个整数l,r,c,表示将序列中[l,r]之间的每个数加上c。请你输出进行完所有操作后的序列。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int n,m,a[1000001],s,c[10000001];
void bil()//构造差分数组
{
for(int i = 1;i <= n;i++) c[i] = a[i] - a[i - 1];
}
void gexi(int x,int y,int z)//修改操作
{
c[x] += z;
c[y + 1] -= z;
}
signed main()
{
cin>>n>>m;
for(int i = 1;i <= n;i++) cin>>a[i];
bil();
while(m--)
{
int x,y,z;
cin>>x>>y>>z;
gexi(x,y,z);
}
s = c[1];
cout<<s<<' ';
for(int i = 2;i <= n;i++) s += c[i],cout<<s<<' ';
return 0;
}
二维差分
**例:**输入一个 行
列的整数矩阵,再输入
个操作,每个操作包含五个整数
,其中
和
表示一个子矩阵的左上角坐标和右下角坐标。 每个操作都要将选中的子矩阵中的每个元素的值加上
。 请你将进行完所有操作后的矩阵输出。
#include <bits/stdc++.h>
#define mod 998244353
#define N 1010
using namespace std;
int a[N][N],b[N][N];
void insert(int x1,int y1,int x2,int y2,int c)
{
b[x1][y1]+=c;
b[x2+1][y1]-=c;
b[x1][y2+1]-=c;
b[x2+1][y2+1]+=c;
}
int main()
{
int n,m,q;
cin>>n>>m>>q;
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
cin>>a[i][j];
insert(i,j,i,j,a[i][j]);
}
}
while(q--)
{
int x1,y1,x2,y2,c;
cin>>x1>>y1>>x2>>y2>>c;
insert(x1,y1,x2,y2,c);
}
for(int i=1;i<=n;i++)
{
for(int j=1;j<=m;j++)
{
b[i][j]+=b[i-1][j]+b[i][j-1]-b[i-1][j-1];
cout<<b[i][j]<<" ";
}
cout<<endl;
}
return 0;
}
树上差分
**例:**FJ 给他的牛棚的 个隔间之间安装了
根管道,隔间编号从
到
。所有隔间都被管道连通了。
FJ 有
条运输牛奶的路线,第
条路线从隔间
运输到隔间
。一条运输路线会给它的两个端点处的隔间以及中间途径的所有隔间带来一个单位的运输压力,你需要计算压力最大的隔间的压力是多少。
暂时看不懂,直接丢洛谷QwQ2000的板子了
#include <cstdio>
#include <algorithm>
#include <cstring>
using namespace std;
const int N=50005;
int n=0,k=0;
int head[N*2],next[N*2],to[N*2],edge=0;
int fa[N][20],depth[N],w1[N],w2[N];
int ans=0;
inline void addEdge(int u,int v) {
to[edge]=v,next[edge]=head[u],head[u]=edge++;
to[edge]=u,next[edge]=head[v],head[v]=edge++;
}
void dfs1(int x,int f,int d) {
depth[x]=d;
fa[x][0]=f;
for (int e=head[x];~e;e=next[e]) {
int& v=to[e];
if (v!=f)
dfs1(v,x,d+1);
}
}
inline void init() {
for (int j=1;(1<<j)<=n;++j)
for (int i=1;i<=n;++i)
if (fa[i][j-1]!=-1)
fa[i][j]=fa[fa[i][j-1]][j-1];
}
inline int lca(int u,int v) {
if (depth[u]<depth[v])
swap(u,v);
int i=0;
for (;(1<<i)<=n;++i)
;
--i;
for (int j=i;j>=0;--j)
if (depth[u]-(1<<j)>=depth[v])
u=fa[u][j];
if (u==v)
return u;
for (int j=i;j>=0;--j)
if (fa[v][j]!=fa[u][j] && fa[u][j]!=-1) {
u=fa[u][j];
v=fa[v][j];
}
return fa[u][0];
}
inline void plus(int x,int y) {
int z=lca(x,y);
++w1[x],++w1[y];
--w1[z];
if (fa[z][0]!=-1)
--w1[fa[z][0]];
}
void dfs2(int x,int f) {
w2[x]=w1[x];
for (int e=head[x];~e;e=next[e]) {
int& v=to[e];
if (v!=f) {
dfs2(v,x);
w2[x]+=w2[v];
}
}
ans=max(ans,w2[x]);
}
int main(void) {
memset(head,-1,sizeof(head));
memset(fa,-1,sizeof(fa));
scanf("%d %d",&n,&k);
for (int i=1;i<=n-1;++i) {
int u=0,v=0;
scanf("%d %d",&u,&v);
addEdge(u,v);
}
dfs1(1,-1,1);
init();
while (k--) {
int x=0,y=0;
scanf("%d %d",&x,&y);
plus(x,y);
}
dfs2(1,-1);
printf("%d\n",ans);
return 0;
}
二分
二分
#include <bits/stdc++.h>
using namespace std;
bool check()
{
// 里面写判断条件
}
int main()
{
// 满足条件就往左找,不满足就往右找
int l = 0, r = 1e9;
while(l < r)
{
int mid = l + r >> 1;
if(check(mid))
r = mid;
else
l = mid + 1;
}
cout << l << endl;
// 满足条件就往右找,不满足就往左找
l = 0, r = 1e9;
while(l < r)
{
int mid = l + r + 1 >> 1;
if(check(mid))
l = mid;
else
r = mid - 1;
}
cout << l << endl;
}
三分
三分的关键在于判断是不是凸函数
浮点数三分
// 寻找凸函数在[l, r]区间内的最值,eps 表示精度
double ternary_search_max(double l, double r, double eps) {
// 当区间长度大于精度要求时持续三分
while (r - l > eps) {
// 得到两个中间点
double lmid = l + (r - l) / 3.0;
double rmid = r - (r - l) / 3.0;
// 比较两个中间点的函数值,缩小搜索范围
if (cal(lmid) < cal(rmid))
l = lmid; // 排除左半区间
else
r = rmid; // 排除右半区间
}
return r;//返回右端点
}
// 寻找凹函数在[l, r]区间内的最值,eps 表示精度
double ternary_search_min(double l, double r, double eps) {
// 终止条件与最大值搜索相同
while (r - l > eps) {
double lmid = l + (r - l) / 3.0;
double rmid = r - (r - l) / 3.0;
// 比较逻辑与最大值搜索相反
if (cal(lmid) > cal(rmid))
l = lmid; // 最小值在右半区间
else
r = rmid; // 最小值在左半区间
}
return l;//返回左端点
}
//实际上返回 l 还是 r 已经不重要了,因为此时 l 和 r 相差不大
整数三分
// 寻找凸函数在[l, r]区间内的最值
int ternary_search_max(int l, int r) {
// 当区间长度大于 3 时持续三分
while (r - l > 3) {
// 得到两个中间点
int lmid = l + (r - l) / 3;
int rmid = r - (r - l) / 3;
// 比较两个中间点的函数值,缩小搜索范围
if (cal(lmid) < cal(rmid))
l = lmid;// 排除左半区间
else
r = rmid;// 排除右半区间
}
int ans = l;
for (int i = l; i <= r; ++i)//这里直接暴力算,因为实际判断太复杂了
if (cal(ans) < cal(i))
ans = i;
return ans;//返回结果
}
**例:**这是一道交互题。
有一把有 个刻度的尺子,刻度分别为
。不幸的是,尺子丢失了一个刻度
(
)。当你用尺子量一个长度为
的物体时,尺子量出的结果为:
- 若
,尺子将会量出正确的结果
。
- 否则,尺子将会量出错误的结果
。 你需要找出丢失的刻度
。你可以每次提供两个
至
内的整数
,你将会收到尺子量出的
的长度与尺子量出的
的长度之积。
你可以进行最多 次询问。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
void solve()
{
int l=0,r=1000;
while(l<r)
{
int mid=(r-l)/3;
int quart1=l+mid,quart2=r-mid;
cout<<"? "<<quart1<<" "<<quart2<<"\n";
cout.flush();
int res;
cin>>res;
if(res==quart1*quart2)
l=quart2+1;
else if(res==quart1*(quart2+1))
{
l=quart1+1,r=quart2;
}
else if(res==(quart1+1)*(quart2+1))
{
r=quart1;
}
}
cout<<"! "<<l<<"\n";
cout.flush();
}
int main()
{
int T=1;
scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
是的,这就是上青圣战那道压轴
二分函数
基础用法
upper_bound在从小到大的排好序的数组中,在数组的 [begin, end) 区间中二分查找第一个大于value的数,找到返回该数字的地址,没找到则返回end。
int main() {
std::vector<int> a = {1, 2, 4, 4, 6, 8};
int x = 4;
auto it = upper_bound(a.begin(), a.end(), x);
if (it != a.end()) {
std::cout << "第一个大于 " << x << " 的元素是:" << *it << std::endl;
} else {
std::cout << "没有找到大于 " << x << " 的元素。" << std::endl;
}
return 0;
}
lower_bound在从小到大的排好序的数组中,在数组的 [begin, end) 区间中二分查找第一个大于等于value的数,找到返回该数字的地址,没找到则返回end。
int main() {
std::vector<int> a = {1, 2, 4, 4, 6, 8};
int x = 4;
auto it = lower_bound(a.begin(), a.end(), x);
if (it != a.end()) {
std::cout << "第一个大于或等于 " << x << " 的元素是:" << *it << std::endl;
} else {
std::cout << "没有找到大于或等于 " << x << " 的元素。" << std::endl;
}
return 0;
}
用greater重载
upper_bound在从大到小的排好序的数组中,在数组的 [begin, end) 区间中二分查找第一个小于value的数,找到返回该数字的地址,没找到则返回end。
lower_bound在从大到小的排好序的数组中,在数组的 [begin, end) 区间中二分查找第一个小于等于value的数,找到返回该数字的地址,没找到则返回end。
排序
快速选择
给定一个长度为 的整数数列,以及一个整数
,请用快速选择算法求出数列从小到大排序后的第
个数。
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
typedef long long ll;
typedef double db;
int quick_choose(int a[],int l,int r,int target)
{
if(l==r) return a[l];
int x=a[l],i=l-1,j=r+1;
while(i<j)
{
while(a[++i]<x);
while(a[--j]>x);
if(i<j)
swap(a[i],a[j]);
}
int sl=j-l+1;
if(target<=sl)
return quick_choose(a,l,j,target);
else
return quick_choose(a,j+1,r,target-sl);
}
int main()
{
int n,k;
cin>>n>>k;
int a[n+1];
for(int i=1;i<=n;i++)
cin>>a[i];
int ans=quick_choose(a,1,n,k);
cout<<ans<<endl;
return 0;
}
逆序对的数量
给定一个长度为 的整数数列,请你计算数列中的逆序对的数量。
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
typedef long long ll;
int a[100005],tmp[100005];
ll merge_sort(int l,int r)
{
if(l>=r) return 0;
int mid=(l+r)>>1;
ll ans=merge_sort(l,mid)+merge_sort(mid+1,r);
int k=0,i=l,j=mid+1;
while(i<=mid and j<=r)
{
if(a[i]<=a[j])
tmp[k++]=a[i++];
else
{
tmp[k++]=a[j++];
ans+=mid-i+1;
}
}
while(i<=mid)
{
tmp[k++]=a[i++];
}
while(j<=r)
{
tmp[k++]=a[j++];
}
for(int i=l;i<=r;i++)
{
a[i]=tmp[i-l];
}
return ans;
}
int main()
{
int n;
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
ll ans=merge_sort(0,n-1);
cout<<ans<<endl;
return 0;
}
堆排序
#include <iostream>
#include <algorithm>
using namespace std;
int n,a[100000];
void print()
{
for(int i=1;i<=n;i++)
printf("%d ",a[i]);
printf("\n");
}
void Max_Heapify(int l,int r)//对第l到r个元素进行最大堆调整
{
int dad=l,son=dad*2;
while(son<=r)
{
if(son+1<=r and a[son+1]>a[son])
son++;
if(a[dad]>a[son])
return ;
swap(a[dad],a[son]);
dad=son;
son=dad*2;
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d",&a[i]);
}
//先对整个树进行一次最大堆调整
for (int i=n;i>0;i--)
Max_Heapify(i,n);
print();
for (int i=n;i>1;i--) {
swap(a[1],a[i]);
Max_Heapify(1,i-1);
print();
}
return 0;
}
倍增
ST表
用于解决RMQ问题(区间最大/最小值),可以做到的查询,比线段树快
#include <bits/stdc++.h>
using namespace std;
inline int read()
{
int x=0,f=1;char ch=getchar();
while (ch<'0'||ch>'9'){if (ch=='-') f=-1;ch=getchar();}
while (ch>='0'&&ch<='9'){x=x*10+ch-48;ch=getchar();}
return x*f;
}
const int N=1e5+10,M=20;
int dp[N][M];
int a[N];
int n,m;
int main()
{
n=read(),m=read();
for(int i=1;i<=n;i++) a[i]=read();
for(int j=0;j<M;j++)
{
for(int i=1;i+(1<<j)-1<=n;i++)
{
if(!j) dp[i][j]=a[i];
else dp[i][j]=max(dp[i][j-1],dp[i+(1<<(j-1))][j-1]);
}
}
while(m--)
{
int l=read(),r=read();
int res=log(r-l+1)/log(2);
printf("%d\n",max(dp[l][res],dp[r-(1<<res)+1][res]));
}
return 0;
}
树上倍增求LCA
见图论部分
动态规划
背包问题
0-1背包
#include <iostream>
using namespace std;
constexpr int MAXN = 13010;
int n, W, w[MAXN], v[MAXN], f[MAXN];
int main() {
cin >> n >> W;
for (int i = 1; i <= n; i++) cin >> w[i] >> v[i]; // 读入数据
for (int i = 1; i <= n; i++)
for (int l = W; l >= w[i]; l--)
if (f[l - w[i]] + v[i] > f[l]) f[l] = f[l - w[i]] + v[i]; // 状态方程
cout << f[W];
return 0;
}
完全背包
一个物品可以选无限次
#include <iostream>
using namespace std;
constexpr int MAXN = 1e4 + 5;
constexpr int MAXW = 1e7 + 5;
int n, W, w[MAXN], v[MAXN];
long long f[MAXW];
int main() {
cin >> W >> n;
for (int i = 1; i <= n; i++) cin >> w[i] >> v[i];
for (int i = 1; i <= n; i++)
for (int l = w[i]; l <= W; l++)
if (f[l - w[i]] + v[i] > f[l]) f[l] = f[l - w[i]] + v[i]; // 核心状态方程
cout << f[W];
return 0;
}
多重背包
一个物品可以选k次
index = 0;
for (int i = 1; i <= m; i++) {
int c = 1, p, h, k;
cin >> p >> h >> k;
while (k > c) {
k -= c;
list[++index].w = c * p;
list[index].v = c * h;
c *= 2;
}
list[++index].w = p * k;
list[index].v = h * k;
}
混合背包
就是有的只能选1次,有的只能选k次,有的可以选无限次
for (int i = 1; i <= n; i++) {
if (cnt[i] == 0) { // 如果数量没有限制使用完全背包的核心代码
for (int weight = w[i]; weight <= W; weight++) {
dp[weight] = max(dp[weight], dp[weight - w[i]] + v[i]);
}
} else { // 物品有限使用多重背包的核心代码,它也可以处理0-1背包问题
for (int weight = W; weight >= w[i]; weight--) {
for (int k = 1; k * w[i] <= weight && k <= cnt[i]; k++) {
dp[weight] = max(dp[weight], dp[weight - k * w[i]] + k * v[i]);
}
}
}
}
二维费用背包
for (int k = 1; k <= n; k++)
for (int i = m; i >= mi; i--) // 对经费进行一层枚举
for (int j = t; j >= ti; j--) // 对时间进行一层枚举
dp[i][j] = max(dp[i][j], dp[i - mi][j - ti] + 1);
分组背包
**例:**自 背包问世之后,小 A 对此深感兴趣。一天,小 A 去远游,却发现他的背包不同于
背包,他的物品大致可分为
组,每组中的物品相互冲突,现在,他想知道最大的利用价值是多少。
#include<bits/stdc++.h>
using namespace std;
int v,n,t;
int x;
int g[205][205];
int i,j,k;
int w[10001],z[10001];
int b[10001];
int dp[10001];
int main(){
cin>>v>>n;
for(i=1;i<=n;i++){
cin>>w[i]>>z[i]>>x;
t=max(t,x);
b[x]++;
g[x][b[x]]=i;
}
for(i=1;i<=t;i++){
for(j=v;j>=0;j--){
for(k=1;k<=b[i];k++){
if(j>=w[g[i][k]]){
dp[j]=max(dp[j],dp[j-w[g[i][k]]]+z[g[i][k]]);
}
}
}
}
cout<<dp[v];
return 0;
}
树形背包
洛谷P2015:有一棵苹果树,如果树枝有分叉,一定是分二叉(就是说没有只有一个儿子的结点)
这棵树共有 个结点(叶子点或者树枝分叉点),编号为
,树根编号一定是
。
我们用一根树枝两端连接的结点的编号来描述一根树枝的位置。下面是一颗有 个树枝的树:
2 5
\ /
3 4
\ /
1
现在这颗树枝条太多了,需要剪枝。但是一些树枝上长有苹果。
给定需要保留的树枝数量,求出最多能留住多少苹果。
输入格式
第一行 个整数
和
,分别表示表示树的结点数,和要保留的树枝数量。
接下来 行,每行
个整数,描述一根树枝的信息:前
个数是它连接的结点的编号,第
个数是这根树枝上苹果的数量。
输出格式
一个数,最多能留住的苹果的数量。
#include<iostream>
#include<cstring>
using namespace std;
const int N = 200010;
int idx;
int e[220], ne[220], h[220];
int dp[220][220];//以i为根节点保留j条边的最大权值和
int value[220];//权值
int st[220];//记录点有没有走过
int q;//保留q条边
int edge[220];//记录这个点为根节点时的边的个数
void add(int a, int b, int num)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx, value[idx++] = num;
}
void cal(int x)
{
st[x] = 1;
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
cal(j);
edge[x]+=edge[j]+1;
}
}
st[x]=0;
}
void dfs(int x)
{
st[x] = 1;
int head = h[x];
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
//cout << x << " " << j << " " << value[i] << "\n";
dfs(j);
//以x为根的时候,每次选边都必须选择该子节点到叶结点的一条路径
//所以对于dp[i][j]而言,必须表示到第i结点刚好选了j条边的情况
//for (int k = q; k >=1; k--)//遍历查找加上子节点能够形成的边的数量的情况的最优解
// if (dp[j][k - 1]) dp[x][k] = max(dp[x][k], dp[x][k - 1] + value[i]);
//for(int k=1;k<=q;k++)
// dp[x][k]=max(dp[x][k],)
for (int k = q; k >=1; k--)//此处遍历的是以x为根节点保留k条边的最优解,采取覆盖取值的方式
{
for (int kk = k; kk >= 1; kk--)//此处遍历的是在当前子节点所在的链上取kk条边,采取覆盖取值的方式
dp[x][k] = max(dp[x][k], dp[x][k - kk] + dp[j][kk - 1] + value[i]);
}
//for (int k = 1; k <= q; k++)
// cout << x << " " << j << " " << k << " " << dp[x][k] << "\n";
}
}
st[x] = 0;
}
int main()
{
memset(h, -1, sizeof(h));
int n;
cin >> n >> q;
for (int i = 1; i <= n - 1; i++)
{
int a, b, value;
cin >> a >> b >> value;
add(a, b,value);
add(b, a, value);
}
cal(1);
//for (int i = 1; i <= n; i++) cout << i << " " << edge[i] << "\n";
dfs(1);
cout << dp[1][q];
return 0;
}
树上dp
**例:**某大学有 个职员,编号为
。
他们之间有从属关系,也就是说他们的关系就像一棵以校长为根的树,父结点就是子结点的直接上司。
现在有个周年庆宴会,宴会每邀请来一个职员都会增加一定的快乐指数
,但是呢,如果某个职员的直接上司来参加舞会了,那么这个职员就无论如何也不肯来参加舞会了。
所以,请你编程计算,邀请哪些职员可以使快乐指数最大,求最大的快乐指数。
#include <bits/stdc++.h>
using namespace std;
const int N=6e3+10;
vector<int> G[N];
int father[N];
int r[N];
int n;
int dp[N][2];//dp[i][0]表示i不去,dp[i][1]表示i去
// dp[i][0]=sum(max(dp[son][1],dp[son][0]));
// dp[i][1]=sum(dp[son][0])+r[i];
void dfs(int u)
{
dp[u][1]=r[u];
for(auto v:G[u])
{
dfs(v);
dp[u][0]+=max(dp[v][0],dp[v][1]);
dp[u][1]+=dp[v][0];
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
scanf("%d",&r[i]);
father[i]=i;
}
for(int i=1;i<n;i++)
{
int son,fa;
scanf("%d%d",&son,&fa);
G[fa].push_back(son);
father[son]=fa;
}
int root=1;
while(father[root]!=root) root=father[root];
dfs(root);
printf("%d\n",max(dp[root][0],dp[root][1]));
return 0;
}
数位dp
**例:**反恐部队在尘土中发现了一枚定时炸弹。但这一次,恐怖分子改进了定时炸弹。定时炸弹的数字序列从1计数到N。如果当前的数字序列包含子序列“49”,那么爆炸的威力将增加一点。 现在反恐部队知道数字N。他们想知道最终的威力积分。你能帮助他们吗?
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=25;
ll dp[N][3];
//dp[i][0] 不含49
//dp[i][1] 不含49但最高位为9
//dp[i][2] 含49
void init()
{
memset(dp,0,sizeof(dp));
dp[0][0]=1;
for(int i=1;i<N;i++){
dp[i][0]=dp[i-1][0]*10-dp[i-1][1];
dp[i][1]=dp[i-1][0];
dp[i][2]=dp[i-1][2]*10+dp[i-1][1];
}
}
ll cal(ll n)
{
int num[N],len=0;
while(n){
num[++len]= n % 10;
n/=10;
}
num[len + 1]=0;
ll ans=0;
bool flag=false;
for(int i=len;i;i--){
ans+= num[i] * dp[i - 1][2];
if(flag){
ans+= num[i] * dp[i - 1][0];
}
else{
if(num[i] > 4){
ans+=dp[i-1][1];
}
if(num[i + 1] == 4 && num[i] == 9){
flag=true;
}
}
}
if(flag){
ans++;
}
return ans;
}
void solve()
{
ll n;
scanf("%lld",&n);
printf("%lld\n",cal(n));
}
int main()
{
init();
int T=1;
scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
例:求在 和
(含)之间的整数中,以十进制书写时正好包含
个非零数字的整数个数。
//
// Created by Swan416 on 2025-04-18 10:08.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
void solve()
{
string s; int k; cin>>s>>k;
vector<vector<vector<int>>> dp(s.size()+1,vector<vector<int>>(s.size()+1,vector<int>(2,-1)));
// dp[i][j][0/1]表示从高到低第i位,前面已经有j个非零数位,当前是/否处于前面已经有数位比S对应数位小的方案数
function<int(int,int,int)> dfs=[&](int now,int cnt,bool equalN) -> int {
if(now==s.size()) return cnt==k;
if(cnt>k) return 0;
if(dp[now][cnt][equalN]>=0 and !equalN) return dp[now][cnt][equalN];
int maxx=equalN ? s[now]-'0' : 9,sum=0;
for(int i=0;i<=maxx;i++)
{
sum+=dfs(now+1,cnt+(i!=0),equalN and (i==maxx));
}
return dp[now][cnt][equalN]=sum;
};
printf("%d\n",dfs(0,0,1));
}
int main()
{
int T=1;
//scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
子序列相关
最长公共子序列LCS
//O(n^2)
void solve() {
long long i, j, k, n, m, ma = 0, ans = 0, sum = 0;
cin>>n;
for(i=1;i<=n;i++)
cin>>a[i];
for(i=1;i<=n;i++)
cin>>b[i];
vector<vector<long long>>dp(n+1,vector<long long>(n+1,0));
//dp[i][j]意为以a[i]结尾,b[j]结尾的最长公共子序列的长度
for(i=1;i<=n;i++) {
for(j=1;j<=n;j++) {
if(a[i]==b[j])
dp[i][j]=dp[i-1][j-1]+1;
else
dp[i][j]=max(dp[i-1][j],dp[i][j-1]);//继承
}
}
cout<<dp[n][n]<<endl;
}
最长上升子序列LIS
O(n^2)
for(i=1;i<=n;i++) cin>>a[i];
vector<long long>dp(n+2,1);
for(i=1;i<=n;i++) {
for(j=1;j<i;j++) {
if(a[j]<a[i]) {
dp[i]=max(dp[i],dp[j]+1);
}
}
}
long long ma=0;
for(i=1;i<=n;i++)
ma=max(ma,dp[i]);
cout<<ma<<endl;
优化
//acwing896 最长上升子序列优化做法后续
#include<algorithm>
#include<iostream>
#include<cstring>
#include<cstdlib>
#include<utility>
#include<bitset>
#include<string>
#include<vector>
#include<cstdio>
#include<stack>
#include<queue>
#include<deque>
#include<cmath>
#include<map>
#include<set>
using namespace std;
#define int long long
const int N=200010;
const int Base=255;
const int MOD=1e9+7;
int a[N];
int low[N];//维护最长上升子序列
//注意这里找到的不一定是最长上升子序列,但是能确定是最长上升子序列的长度
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int n;
cin>>n;
for(int i=1;i<=n;i++)
cin>>a[i];
low[1]=a[1];
int lis=1;
for(int i=2;i<=n;i++)
{
if(a[i]>low[lis]) low[++lis]=a[i];//如果当前数大于维护序列末尾元素,则直接加入
else//如果当前数小于维护序列末尾元素则二分查找维护序列,找到第一个大于当前数字的位置
{
int l=1,r=lis;
while(l<=r)
{
int mid =(l+r)>>1;
if(low[mid]<a[i]) l=mid+1;
else if(low[mid]>a[i]) r=mid-1;
else
{
l=mid;
break;
}
}
low[l]=a[i];
}
}
cout<<lis;
return 0;
}
斜率优化DP
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int MAXN = 1e5 + 5;
const ll INF = 1e18;
ll n, S;
ll t[MAXN], c[MAXN];
ll sumT[MAXN], sumC[MAXN]; // 前缀和数组
ll dp[MAXN]; // dp[i]表示前i个任务的最小费用
int q[MAXN]; // 单调队列,存储决策点下标
int head, tail;
// 计算两点斜率 (y2 - y1)/(x2 - x1)
// 为避免浮点运算,用交叉相乘形式比较
ll slope(int j1, int j2) {
ll y1 = dp[j1] + S * sumC[j1] + sumT[j1] * sumC[j1];
ll y2 = dp[j2] + S * sumC[j2] + sumT[j2] * sumC[j2];
ll x1 = sumC[j1], x2 = sumC[j2];
return (y2 - y1) * (x2 - x1); // 实际比较时需结合符号判断
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
cin >> n >> S;
for (int i = 1; i <= n; ++i) {
cin >> t[i] >> c[i];
sumT[i] = sumT[i-1] + t[i];
sumC[i] = sumC[i-1] + c[i];
}
head = tail = 0;
q[tail++] = 0; // 初始决策点
for (int i = 1; i <= n; ++i) {
// 计算当前斜率k = sumT[i] + S
ll k = sumT[i] + S;
// 维护队头:移除不再最优的决策点
while (head + 1 < tail) {
int j1 = q[head], j2 = q[head+1];
ll val1 = dp[j1] + S * sumC[j1] + sumT[j1] * sumC[j1];
ll val2 = dp[j2] + S * sumC[j2] + sumT[j2] * sumC[j2];
// 比较k*(x2-x1)与(y2-y1)
if (k * (sumC[j2] - sumC[j1]) >= (val2 - val1)) {
head++;
} else {
break;
}
}
// 取队头为最优决策点
int j = q[head];
dp[i] = dp[j] + (S + sumT[i] - sumT[j]) * (sumC[i] - sumC[j]);
// 维护队尾:保持队列单调性
while (head + 1 < tail) {
int j1 = q[tail-2], j2 = q[tail-1], j3 = i;
if (slope(j1, j2) >= slope(j2, j3)) {
tail--;
} else {
break;
}
}
q[tail++] = i;
}
cout << dp[n] << endl;
return 0;
}
区间概率DP
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define ll long long
#define lowbit(x) x&(-x)
const int MOD=998244353;
const int N=1e6+10;
int qpow(int num,int k) {
int res=1;
while(k) {
if(k&1) res = (res * num) % MOD;
num = (num * num) % MOD;
k >>= 1;
}
return res % MOD;
}
int inv(int x) {
return qpow(x,MOD-2) % MOD;
}
int lcm(int x,int y) {
return x * y / __gcd(x,y);
}
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
int Base = uniform_int_distribution<>(8e8,9e8)(rng);
int a[N];
int b[N];
struct Seg
{
int l;
int r;
int p;
int q;
bool operator < (const Seg& other)
{
if(l != other.l) return l < other.l;
else return r < other.r;
}
}seg[N];
int dp[N];
int pre[N];//维护差分数组,记录每个位置不被覆盖的可能性
int M(int num1,int num2)
{
return num1 * num2 % MOD;
}
void solve() {
int n,m;
cin>>n>>m;
for(int i=0;i<=m;i++) pre[i] = 1;
for(int i=1;i<=n;i++)
{
int l,r,p,q;
cin>>l>>r>>p>>q;
seg[i].l = l;
seg[i].r = r;
seg[i].p = p;
seg[i].q = q;
pre[l] = M(pre[l],(q - p));
pre[l] = M(pre[l],inv(q));
// pre[r + 1] = D(pre[r + 1],D(q,q-p));
}
for(int i=1;i<=m;i++)
{
pre[i] = M(pre[i],pre[i - 1]);
}
sort(seg+1,seg+n+1);
dp[0] = 1;
for(int i=1;i<=n;i++)
{
int l = seg[i].l;
int r = seg[i].r;
int p = seg[i].p;
int q = seg[i].q;
//cout<<l<<" "<<r<<"\n";
int cur = M(p,inv(q-p));
cur = M(cur,pre[r]);
cur = M(cur,inv(pre[l-1]));
dp[r] = (dp[r] + M(dp[l-1],cur) ) % MOD;
}
cout<<dp[m]<<"\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t=1;
//cin>>t;
while(t--) {
solve();
}
return 0;
}
质因数状压DP
//牛客多校2-G 质因数状压dp
//OS:原来自己一直不会解的这一类问题是用状压dp来解决的吗
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=200010;
const int Base=255;
const int MOD=1e9+7;
int a[N];
int sher[5010][5010];
int prime[N]={2,3,5,7,11,13,17,19,23,29,31};
int dp[1010][1<<12];//状压dp
map< int, vector< pair<int,int> > >mp;
signed main()
{
//Si的范围是1000以内,根号1000以内的质因数不大于32
//对每个数进行质因数分解,大于等于32的质因数最多有一个,因为Si<=1000
//将小于等于31的质数叫做小质数,反之为大质数
int n;
cin>>n;
for(int i=1;i<=n;i++)
{
int x;
cin>>x;
int st=0;//记录当前元素的质数串
//对于构建质数串:当前每个位置i对应prime[i]里面的数
//为0则表示有偶数个这个数,为1则表示有奇数个这个数
//所以每次进行分解的时候都将st与当前位j为1的数进行异或处理
int value=1;//记录当前元素的贡献
for(int j=0;j<11;j++)
{
while(x%prime[j]==0)//进行分解质因数
{
x/=prime[j];
int num=(1<<j);
st ^= num;//异或处理记录当前位的prime[i]有多少个
if( (st & (1 << j))== 0 )//表示当前有偶数个prime[j],那么自己就能匹配成一个平方数
value *=prime[j];
//这里相乘的原因是因为每有一对prime[j],开出来的书就会乘一次prime[j]
}
}
mp[x].push_back({st,value});
//这里的x只有两种情况:1或者是大质数
}
dp[0][0]=1;
int pt=0;//记录当前位置
for (auto &[x, vec] : mp)
{
prime[11]=x;//x为1或者大质数
for(auto &[st,value] : vec)//遍历当前数组里面存的质数
{
pt++;
if(x!=1) st+=(1 << 11);
for(int p=0;p<(1<<12);p++)//遍历质数串
{
int tmp=p&st;//查找当前质数串和st都为1的位
int tmpvalue=value;//记录当前好集合计算完之后的值之和
for(int k=0;k<=11;k++)
{
if(tmp & (1<<k))//该位两个都为1
{
tmpvalue *= prime[k];
//这里相乘的原因是因为当两边匹配的时候,两边合并算出来的值就是相乘出的值
}
}
dp[pt][st^p]/*当两个数进行匹配的时候,都是奇数个的数会匹配在一起变为0,只有一个是奇数个数会保留仍是奇数个
都是偶数个数仍是偶数个数*/
=(dp[pt-1][st^p]/*由前面pt-1个数得出st^p质数串的值*/+dp[pt-1][p]/*由前面pt-1个数得出p质数串的值再乘上
当前的质数得到st^p质数串的值*/*tmpvalue)%MOD;
}
}
for(int i=(1<<11);i<(1<<12);i++)
dp[pt][i]=0;
//只保留大质数能够匹配的结果,此时i质数串最高位为0
}
cout<<(dp[pt][0]-1+MOD)%MOD;
return 0;
}
线段树存矩阵加速DP
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define ll long long
#define lowbit(x) x&(-x)
const int MOD=1e9 + 7;
const int N=1e6+10;
const int INF=1e18;
const double eps=1e-6;
const double PI=acos(-1.0);
int qpow(int num,int k) {
int res=1;
while(k) {
if(k%2) res = (res * num) % MOD;
num = (num * num) % MOD;
k/=2 ;
}
return res % MOD;
}
int inv(int x) {
return qpow(x,MOD-2);
}
int lcm(int x,int y) {
return x * y / __gcd(x,y);
}
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
int Base = uniform_int_distribution<>(8e8,9e8)(rng);
int a[N];
int b[N];
using Matrix = array<array<int,2>,2>;
Matrix operator*(const Matrix &a,const Matrix &b){//广义矩阵乘法
Matrix c;
//假设dp[i]为第i个l字符回正所需要的时间,num[i]表示第i个l字符前面有多少个r字符
//则dp[i] = max(dp[i-1] + 1,num[i])
//但是由于这里每次询问改变某个字符的时候会产生一定影响
//所以这里采用矩阵的方式,是用来方便使用线段树存储区间
c[0][0] = max(a[0][0] + b[0][0], a[0][1] + b[1][0]);
c[0][1] = max(a[0][0] + b[0][1], a[0][1] + b[1][1]);
c[1][0] = max(a[1][0] + b[0][0], a[1][1] + b[1][0]);
c[1][1] = max(a[1][0] + b[0][1], a[1][1] + b[1][1]);
return c;
}
int n,q;
string s;
struct node{
int l,r;
Matrix dp;
}tr[N * 4];//用线段树存区间的矩阵信息
void push_up(int d)
{
//每次修改值对包含修改位置的区间都进行一次更新
int ls = d * 2, rs = d * 2 + 1;
tr[d].dp = tr[ls].dp * tr[rs].dp;//将左右子树的对应区间进行合并
tr[d].l = tr[ls].l | tr[rs].l;//更新l字符是否出现
tr[d].r = tr[ls].r | tr[rs].r;//更新r字符是否出现
}
void build(int p,int l,int r)
{
//搭建线段树
if(l == r)
{
if(s[l] == 'L')
{
tr[p].l = 1;
tr[p].r = 0;
tr[p].dp[0] = {1,-INF};
tr[p].dp[1] = {0,0};
}
else
{
tr[p].l = 0;
tr[p].r = 1;
tr[p].dp[0] = {0,-INF};
tr[p].dp[1] = {-INF,1};
}
return ;
}
int ls = p * 2, rs = p * 2 + 1;
int mid = (l + r) / 2;
build(ls,l,mid);
build(rs,mid+1,r);
push_up(p);
}
void update(int p,int l,int r,int x)
{
//单点修改某个位置的值,其实这里跟build的过程类似
if(l == r)
{
if(s[l] == 'L')
{
tr[p].l = 1;
tr[p].r = 0;
tr[p].dp[0] = {1,-INF};
tr[p].dp[1] = {0,0};
}
else
{
tr[p].l = 0;
tr[p].r = 1;
tr[p].dp[0] = {0,-INF};
tr[p].dp[1] = {-INF,1};
}
return ;
}
int ls = p * 2, rs = p * 2 + 1;
int mid = (l + r) / 2;
if(x <= mid) update(ls,l,mid,x);
else update(rs,mid+1,r,x);
push_up(p);
}
Matrix query(int p,int l,int r,int L,int R)
{
//查询区间[L,R]的矩阵信息
int ls = p * 2, rs = p * 2 + 1;
int mid = (l + r) >> 1;
if(l == L && r == R) return tr[p].dp;
else if(R <= mid) return query(ls,l,mid,L,R);
else if(L > mid) return query(rs,mid+1,r,L,R);
else return query(ls,l,mid,L,mid) * query(rs,mid+1,r,mid+1,R);
}
int queryl(int p,int l,int r)
{
//查找最右边的l字符
int ls = p * 2, rs = p * 2 + 1;
int mid = (l + r) >> 1;
if(tr[p].l == 0) return 0;
else if(l == r) return l;
else if(tr[rs].l) return queryl(rs,mid+1,r);
else return queryl(ls,l,mid);
}
int queryr(int p,int l,int r)
{
//查找最左边的r字符
int ls = p * 2, rs = p * 2 + 1;
int mid = (l + r) >> 1;
if(tr[p].r == 0) return 0;
else if(l == r) return l;
else if(tr[ls].r) return queryr(ls,l,mid);
else return queryr(rs,mid+1,r);
}
void Love_Hitachi_Mako() {
cin>>n>>q;
cin>>s;
s = 'a' + s;
build(1,1,n);
while(q--)
{
int x;
cin>>x;
s[x] ^= 'L' ^ 'R';
update(1,1,n,x);
int l = queryl(1,1,n);
int r = queryr(1,1,n);
if(l == 0) cout<<0<<"\n";
else if(r == 0) cout<<0<<"\n";
else if(l < r) cout<<0<<"\n";
else
{
Matrix res = query(1,1,n,r,l);
cout<<max(res[0][0],res[1][0])<<"\n";
}
}
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t=1;
cin>>t;
while(t--) {
Love_Hitachi_Mako();
}
return 0;
}
字符串
字符串哈希
单哈希
#include <bits/stdc++.h>
#define all(a) a.begin(),a.end()
using namespace std;
int myHash(string s)
{
int p=131;
int mod=1e9+7;
int res=0;
for(int i=0;i<s.size();i++)
{
res=(1ll*res*p+s[i])%mod;
}
return res;
}
int main()
{
int n;
cin>>n;
int cnt=0;
vector<int> store;
for(int i=1;i<=n;i++)
{
string s;
cin>>s;
int h=myHash(s);
store.push_back(h);
}
sort(all(store));
for(int i=0;i<store.size();i++)
{
if(i==0 or store[i]!=store[i-1])
{
cnt++;
}
}
cout<<cnt<<endl;
return 0;
}
双哈希
#include <bits/stdc++.h>
#define all(a) a.begin(),a.end()
using namespace std;
typedef pair<int,int> pii;
pii myHash(string s)
{
pii ret;
int p=131;
int mod=1e9+7;
int res=0;
for(int i=0;i<s.size();i++)
{
res=(1ll*res*p+s[i])%mod;
}
ret.first=res;
p=233;
mod=1e9+9;
res=0;
for(int i=0;i<s.size();i++)
{
res=(1ll*res*p+s[i])%mod;
}
ret.second=res;
return ret;
}
int main()
{
int n;
cin>>n;
int cnt=0;
vector<pii> store;
for(int i=1;i<=n;i++)
{
string s;
cin>>s;
store.push_back(myHash(s));
}
sort(all(store));
for(int i=0;i<store.size();i++)
{
if(i==0 or store[i]!=store[i-1])
{
cnt++;
}
}
cout<<cnt<<endl;
return 0;
}
子串哈希
找出一个以 为前缀的最短回文串
#include <cstdio>
#include <iostream>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;
int n; string s;
ULL h1[500010];
ULL h2[500010];
ULL p[500010];
ULL query1(int l, int r)
{
ULL ret = h1[r];
ret -= h1[l - 1] * p[r - l + 1];
return ret;
}
ULL query2(int l, int r)
{
ULL ret = h2[l];
ret -= h2[r + 1] * p[r - l + 1];
return ret;
}
int main()
{
cin >> s; n = s.size();
s = " " + s + " "; p[0] = 1;
for (int i = 1; i <= n; i++)
{
h1[i] = h1[i - 1] * 13331;
h1[i] += s[i] - 'A' + 1;
p[i] = p[i - 1] * 13331;
}
for (int i = n; i >= 1; i--)
{
h2[i] = h2[i + 1] * 13331;
h2[i] += s[i] - 'A' + 1;
}
int f = 0, type = 0;
for (int i = n; i >= (n + 1) / 2; i--)
{
int len = n - i + 1;
if (query1(i - len + 1, i) == query2(i, n))
f = i, type = 1;
else if (query1(i - len + 2, i) == query2(i + 1, n))
f = i, type = 0;
}
for (int i = 1; i <= n; i++)
cout << s[i];
if (type == 1)
{
for (int i = f * 2 - n - 1; i >= 1; i--)
cout << s[i];
cout << endl;
}
else
{
for (int i = f * 2 - n; i >= 1; i--)
cout << s[i];
cout << endl;
}
return 0;
}
双模哈希封装
namespace Hash {
const int N = 1000010;
typedef unsigned long long ull;
typedef pair<ull,ull> puu;
ull base = 131;
ull mod1 = 25165843, mod2 = 1610612741;
ull bs1[N], bs2[N];
void init() {
bs1[0] = bs2[0] = 1;
for(int i = 1; i < N; i++) {
bs1[i] = bs1[i - 1] * base % mod1;
bs2[i] = bs2[i - 1] * base % mod2;
}
}
struct String
{
int n;
string s;
vector<ull> h1, h2;
String(string _s) {
n = _s.size();
s = " " + _s;
h1.resize(n + 1, 0), h2.resize(n + 1, 0);
for(int i = 1; i <= n; i++) {
h1[i] = (h1[i - 1] * base % mod1 + (ull)s[i]) % mod1;
h2[i] = (h2[i - 1] * base % mod2 + (ull)s[i]) % mod2;
}
}
ull get_hash1(int l, int r) {
return (h1[r] - h1[l - 1] * bs1[r - l + 1] % mod1 + mod1) % mod1;
}
ull get_hash2(int l, int r) {
return (h2[r] - h2[l - 1] * bs2[r - l + 1] % mod2 + mod2) % mod2;
}
puu get_hash(int l, int r) {
return {get_hash1(l, r), get_hash2(l, r)};
}
puu get_hash(void) {
return get_hash(1, n);
}
};
}
using namespace Hash;
判断回文串
#include<iostream>
using namespace std;
#define ull unsigned long long
const int maxn = 1e6 + 5;
ull p = 13331;
const int mod = 1e9 + 7;
const int mod1 = 1e8 + 15;
int main(){
int len;
while(cin >> len){
ull hash_a = 0, hash_b = 0,hash_aa = 0, hash_bb = 0;
getchar();
int mid = len / 2;
for (int i = 1; i <= mid; ++i){
char t = getchar();
hash_a = (hash_a * p + (ull)t) % mod;
hash_aa = (hash_aa * p + (ull)t) % mod1;
}
if(len & 1)
getchar();
ull pp = 1, pp1 = 1;
for (int i = 1; i <= mid; ++i){
char t = getchar();
hash_b = (hash_b + (ull)t * pp) % mod;
hash_bb = (hash_bb + (ull)t * pp1) % mod1;
pp = p * pp % mod;
pp1 = p * pp1 % mod1;
}
if(hash_a == hash_b && hash_aa == hash_bb)
cout << "YES" << endl;
else
cout << "NO" << endl;
}
return 0;
}
Trie树
给定 个模式串
和
次询问,每次询问给定一个文本串
,请回答
中有多少个字符串
满足
是
的前缀。
一个字符串 是
的前缀当且仅当从
的末尾删去若干个(可以为 0 个)连续的字符后与
相同。
输入的字符串大小敏感。例如,字符串 Fusu 和字符串 fusu 不同。
#include <bits/stdc++.h>
#define mod 998244353
#define N 100010
using namespace std;
int son[N][26],idx,cnt[N];
void insert(string s)
{
int p=0;
for(char c:s)
{
int u=c-'a';
if(!son[p][u])
son[p][u]=++idx;
p=son[p][u];
}
cnt[p]++;
}
int query(string s)
{
int p=0;
for(char c:s)
{
int u=c-'a';
if(!son[p][u])
return 0;
p=son[p][u];
}
return cnt[p];
}
int main()
{
int n;
cin >> n;
while(n--)
{
char cmd;
cin>>cmd;
if(cmd=='I')
{
string s;
cin>>s;
insert(s);
}
else if(cmd=='Q')
{
string s;
cin>>s;
cout<<query(s)<<'\n';
}
}
return 0;
}
01Trie树
Zeus 和 Prometheus 做了一个游戏,Prometheus 给 Zeus 一个集合,集合中包含了 个正整数,随后 Prometheus 将向 Zeus 发起
次询问,每次询问中包含一个正整数
,之后 Zeus 需要在集合当中找出一个正整数
,使得
与
的异或结果最大。Prometheus 为了让 Zeus 看到人类的伟大,随即同意 Zeus 可以向人类求助。你能证明人类的智慧么?
#include<bits/stdc++.h>
using namespace std;
#define ll long long
#define endl '\n'
const ll N=5e5+10;
ll tr[N*32][3];
ll idx=0;
ll mas[N];
ll as[N*32];
ll n,a,b,c,m;
void insert(ll x)
{
ll p=0;
for(int i=31;i>=0;--i)
{
bool id=(x>>i)&1;
if(!tr[p][id]) tr[p][id]=++idx;
p=tr[p][id];
}
as[p]=x;
}
ll find(ll x)
{
ll p=0;
for(int i=31;i>=0;--i)
{
bool id=((x>>i)&1);
if(tr[p][!id]) p=tr[p][!id];
else p=tr[p][id];
}
return as[p];
}
signed main()
{ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
cin>>n>>m;
for(int i=1;i<=n;++i) cin>>mas[i];
for(int i=1;i<=n;++i)
{
insert(mas[i]);
}
ll ans=0;
while(m--)
{
cin>>a;
cout<<find(a)<<endl;
}
return 0;
}
KMP
vector<int > get_next(string pattern) { //求next数组,并返回next数组
int plen = pattern.size();
vector<int> next(plen);
int i = 1, j = 0; //此时我们将[0,i]当作文本串,将[0,j]的串当作模板串
for (int i = 1; i < plen; i++) {
while (j > 0 and pattern[i] != pattern[j]) {
j = next[j-1];
}
if (pattern[i] == pattern[j]) { //这里的话,next就代表[0,i]区间的最长公共前后缀
next[i] = j+1;
j++;
}
}
return next;
}
void kmp(string text, string pattern) {//文本串,模板串
//分别表示文本串和模板串的长度
int tlen = text.size();
int plen = pattern.size();
vector<int > next=get_next(pattern);//next数组
//假设我们已经得到了next数组,由于next数组的一个含义是,当匹配失败,模板串指针前往的位置
//所以我们可以写出
int i=0,j = 0;
while(i<tlen){
if (pattern[j] == text[i]) {
j++;
i++;
if (j == plen) { //如果模板串全部都匹配上了
cout<<(i - j+1)<<'\n';//输出匹配成功的下标
j = next[j-1];
}
}
else {
if (j > 0) {
j = next[j - 1];
}
else {
i++;
}
}
}
for (int i = 0; i < next.size(); i++)cout << next[i] << ' ';
return ; //如果扫完了一遍文本串还没匹配,直接返回
}
int main() {
string text, pattern;
cin >> text >> pattern;
kmp(text, pattern);
}
Z函数(拓展KMP)
对于一个长度为 的字符串
,定义函数
表示
和
(即以
开头的后缀)的最长公共前缀(LCP)的长度,则
被称为
的Z函数。特别地,
。
国外一般将计算该数组的算法称为Z Algorithm,而国内则称其为扩展KMP。
下面这个代码可以在
的复杂度下算出Z函数
vector<int> z_function(string s) {
int n = (int)s.length();
vector<int> z(n);
for (int i = 1, l = 0, r = 0; i < n; ++i) {
if (i <= r && z[i - l] < r - i + 1) {
z[i] = z[i - l];
} else {
z[i] = max(0, r - i + 1);
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) ++z[i];
}
if (i + z[i] - 1 > r) l = i, r = i + z[i] - 1;
}
return z;
}
AC自动机
有 个由小写字母组成的模式串以及一个文本串
。每个模式串可能会在文本串中出现多次。你需要找出哪些模式串在文本串
中出现的次数最多。
#include<iostream>
#include<cstdio>
#include<cstdlib>
#include<cstring>
#include<cmath>
#include<queue>
#include<algorithm>
using namespace std;
struct Tree//字典树
{
int fail;//失配指针
int vis[26];//子节点的位置
int end;//标记以这个节点结尾的单词编号
}AC[100000];//Trie树
int cnt=0;//Trie的指针
struct Result
{
int num;
int pos;
}Ans[100000];//所有单词的出现次数
bool operator <(Result a,Result b)
{
if(a.num!=b.num)
return a.num>b.num;
else
return a.pos<b.pos;
}
string s[100000];
inline void Clean(int x)
{
memset(AC[x].vis,0,sizeof(AC[x].vis));
AC[x].fail=0;
AC[x].end=0;
}
inline void Build(string s,int Num)
{
int l=s.length();
int now=0;//字典树的当前指针
for(int i=0;i<l;++i)//构造Trie树
{
if(AC[now].vis[s[i]-'a']==0)//Trie树没有这个子节点
{
AC[now].vis[s[i]-'a']=++cnt;//构造出来
Clean(cnt);
}
now=AC[now].vis[s[i]-'a'];//向下构造
}
AC[now].end=Num;//标记单词结尾
}
void Get_fail()//构造fail指针
{
queue<int> Q;//队列
for(int i=0;i<26;++i)//第二层的fail指针提前处理一下
{
if(AC[0].vis[i]!=0)
{
AC[AC[0].vis[i]].fail=0;//指向根节点
Q.push(AC[0].vis[i]);//压入队列
}
}
while(!Q.empty())//BFS求fail指针
{
int u=Q.front();
Q.pop();
for(int i=0;i<26;++i)//枚举所有子节点
{
if(AC[u].vis[i]!=0)//存在这个子节点
{
AC[AC[u].vis[i]].fail=AC[AC[u].fail].vis[i];
//子节点的fail指针指向当前节点的
//fail指针所指向的节点的相同子节点
Q.push(AC[u].vis[i]);//压入队列
}
else//不存在这个子节点
AC[u].vis[i]=AC[AC[u].fail].vis[i];
//当前节点的这个子节点指向当
//前节点fail指针的这个子节点
}
}
}
int AC_Query(string s)//AC自动机匹配
{
int l=s.length();
int now=0,ans=0;
for(int i=0;i<l;++i)
{
now=AC[now].vis[s[i]-'a'];//向下一层
for(int t=now;t;t=AC[t].fail)//循环求解
Ans[AC[t].end].num++;
}
return ans;
}
int main()
{
int n;
while(233)
{
cin>>n;
if(n==0)break;
cnt=0;
Clean(0);
for(int i=1;i<=n;++i)
{
cin>>s[i];
Ans[i].num=0;
Ans[i].pos=i;
Build(s[i],i);
}
AC[0].fail=0;//结束标志
Get_fail();//求出失配指针
cin>>s[0];//文本串
AC_Query(s[0]);
sort(&Ans[1],&Ans[n+1]);
cout<<Ans[1].num<<endl;
cout<<s[Ans[1].pos]<<endl;
for(int i=2;i<=n;++i)
{
if(Ans[i].num==Ans[i-1].num)
cout<<s[Ans[i].pos]<<endl;
else
break;
}
}
return 0;
}
拓补排序优化
给你一个文本串 和
个模式串
,请你分别求出每个模式串
在
中出现的次数。
#include <cstdio>
#include <cstring>
#include <queue>
using namespace std;
constexpr int N = 2e5 + 6;
constexpr int LEN = 2e6 + 6;
constexpr int SIZE = 2e5 + 6;
int n;
namespace AC {
struct Node {
int son[26]; // 子结点
int ans; // 匹配计数
int fail; // fail 指针
int du; // 入度
int idx;
void init() { // 结点初始化
memset(son, 0, sizeof(son));
ans = fail = idx = 0;
}
} tr[SIZE];
int tot; // 结点总数
int ans[N], pidx;
void init() {
tot = pidx = 0;
tr[0].init();
}
void insert(char s[], int &idx) {
int u = 0;
for (int i = 1; s[i]; i++) {
int &son = tr[u].son[s[i] - 'a']; // 下一个子结点的引用
if (!son) son = ++tot, tr[son].init(); // 如果没有则插入新结点,并初始化
u = son; // 从下一个结点继续
}
// 由于有可能出现相同的模式串,需要将相同的映射到同一个编号
if (!tr[u].idx) tr[u].idx = ++pidx; // 第一次出现,新增编号
idx = tr[u].idx; // 这个模式串的编号对应这个结点的编号
}
void build() {
queue<int> q;
for (int i = 0; i < 26; i++)
if (tr[0].son[i]) q.push(tr[0].son[i]);
while (!q.empty()) {
int u = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (tr[u].son[i]) { // 存在对应子结点
tr[tr[u].son[i]].fail = tr[tr[u].fail].son[i]; // 只用跳一次 fail 指针
tr[tr[tr[u].fail].son[i]].du++; // 入度计数
q.push(tr[u].son[i]); // 并加入队列
} else
tr[u].son[i] =
tr[tr[u].fail]
.son[i]; // 将不存在的字典树的状态链接到了失配指针的对应状态
}
}
}
void query(char t[]) {
int u = 0;
for (int i = 1; t[i]; i++) {
u = tr[u].son[t[i] - 'a']; // 转移
tr[u].ans++;
}
}
void topu() {
queue<int> q;
for (int i = 0; i <= tot; i++)
if (tr[i].du == 0) q.push(i);
while (!q.empty()) {
int u = q.front();
q.pop();
ans[tr[u].idx] = tr[u].ans;
int v = tr[u].fail;
tr[v].ans += tr[u].ans;
if (!--tr[v].du) q.push(v);
}
}
} // namespace AC
char s[LEN];
int idx[N];
int main() {
AC::init();
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%s", s + 1);
AC::insert(s, idx[i]);
AC::ans[i] = 0;
}
AC::build();
scanf("%s", s + 1);
AC::query(s);
AC::topu();
for (int i = 1; i <= n; i++) {
printf("%d\n", AC::ans[idx[i]]);
}
return 0;
}
子序列自动机
例:Arc081_C - Don't Be a Subsequence
输入一个字符串a,求不是它的子序列的最短串。如果有多个,输出字典序最小的。
//
// Created by Swan416 on 2025-08-03 22:41.
// 子序列自动机板子题
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
// 子序列自动机是一种可以快速判断字符串t是否是字符串s子串的算法
void solve()
{
string s; cin>>s; int n=s.size();
// 定义数组nxt[i][j]指从第i个位置后的字符串中j首次出现的位置
// 此时对于另一串t,若t为s的子串,则t的每个位置的元素,可以利用nxt数组在s上的剩余字串得到匹配
vector<vector<int>> nxt(n+1,vector<int>(26,-1));
// 我们从后往前枚举字符串的每一个位置
for(int i=n-1;i>=0;i--)
{
for(int j=0;j<26;j++) nxt[i][j]=nxt[i+1][j];
nxt[i][s[i]-'a']=i+1;
}
function<bool(string)> check=[&](string t)
{
// 查找t是否是s的子串
int p=-1;
for(int i=0;i<t.size();i++)
{
// 在s的剩余字串中查找t[i]的下一个位置
p=nxt[p+1][t[i]-'a'];
if(p==-1) return false; // 没有找到
}
return true;
};
// 上面是板子部分,这题要求的是找到字典序最小的不是s子串的字符串,直接bfs即可
queue<string> q;
q.push("");
while(!q.empty())
{
string t=q.front(); q.pop();
// 如果t不是s的子串,则输出
if(!check(t))
{
cout<<t<<endl;
return;
}
// 否则继续扩展
for(int i=0;i<26;i++)
{
string nt=t+(char)('a'+i);
if(nt.size()<=n+1) q.push(nt); // 限制长度,防止爆搜
}
}
}
int main()
{
int T=1;
//scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
求字符串子串个数
处理出 数组之后可以对该串进行
设 表示从 1 到
中长度为
的子序列个数
则易得
queue<int> q;
int f[MAXN][MAXN], d[MAXN];
void Dp()
{
f[0][0] = 1;
q.push(0);
while (!q.empty())
{
int u = q.front(); q.pop();
for (int i = 1; i <= m; i++)
{
if (!nxt[u][i]) continue;
for (int j = 0; j <= u; j++) f[nxt[u][i]][j + 1] += f[u][j];
d[nxt[u][i]]--;
if (!d[nxt[u][i]]) q.push(nxt[u][i]);
}
}
}
其实可以看出这个本质上就是在 上跑拓扑
,所以
数组本质上就是一个
后缀排序
读入一个长度为 的由大小写英文字母或数字组成的字符串,请把这个字符串的所有非空后缀按字典序从小到大排序,然后按顺序输出后缀的第一个字符在原串中的位置。位置编号为
到
。
#include <algorithm>
#include <cstdio>
#include <cstring>
#include <iostream>
using namespace std;
constexpr int N = 1000010;
char s[N];
int n;
int m, p, rk[N * 2], oldrk[N], sa[N * 2], id[N], cnt[N];
int main() {
scanf("%s", s + 1);
n = strlen(s + 1);
m = 128;
for (int i = 1; i <= n; i++) cnt[rk[i] = s[i]]++;
for (int i = 1; i <= m; i++) cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; i--) sa[cnt[rk[i]]--] = i;
for (int w = 1;; w <<= 1, m = p) { // m = p 即为值域优化
int cur = 0;
for (int i = n - w + 1; i <= n; i++) id[++cur] = i;
for (int i = 1; i <= n; i++)
if (sa[i] > w) id[++cur] = sa[i] - w;
memset(cnt, 0, sizeof(cnt));
for (int i = 1; i <= n; i++) cnt[rk[i]]++;
for (int i = 1; i <= m; i++) cnt[i] += cnt[i - 1];
for (int i = n; i >= 1; i--) sa[cnt[rk[id[i]]]--] = id[i];
p = 0;
memcpy(oldrk, rk, sizeof(oldrk));
for (int i = 1; i <= n; i++) {
if (oldrk[sa[i]] == oldrk[sa[i - 1]] &&
oldrk[sa[i] + w] == oldrk[sa[i - 1] + w])
rk[sa[i]] = p;
else
rk[sa[i]] = ++p;
}
if (p == n) break; // p = n 时无需再排序
}
for (int i = 1; i <= n; i++) printf("%d ", sa[i]);
return 0;
}
manacher算法(马拉车)
可以用求出字符串中最长回文子串长度
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int maxn=11000002;
char data[maxn<<1];
int p[maxn<<1],cnt,ans;
inline void qr(){
char c=getchar();
data[0]='~',data[cnt=1]='|';
while(c<'a'||c>'z') c=getchar();
while(c>='a'&&c<='z') data[++cnt]=c,data[++cnt]='|',c=getchar();
}
int main(){
qr();
for(int t=1,r=0,mid=0;t<=cnt;++t){
if(t<=r) p[t]=min(p[(mid<<1)-t],r-t+1);
while(data[t-p[t]]==data[t+p[t]]) ++p[t];
//暴力拓展左右两侧,当t-p[t]==0时,由于data[0]是'~',自动停止。故不会下标溢出。
//假若我这里成功暴力扩展了,就意味着到时候r会单调递增,所以manacher是线性的。
if(p[t]+t>r) r=p[t]+t-1,mid=t;
//更新mid和r,保持r是最右的才能保证我们提前确定的部分回文半径尽量多。
if(p[t]>ans) ans=p[t];
}
printf("%d\n",ans-1);
return 0;
}
数学
高精度
加法
#include<iostream>
#include<vector>
using namespace std;
vector<int>add(vector<int>&a,vector<int>&b)
{
vector<int>n;
int t=0;
for(int i=0;i<a.size()||i<b.size();i++)
{
if(i<a.size()) t+=a[i];
if(i<b.size()) t+=b[i];
n.push_back(t%10);
t/=10;
}
if(t>0) n.push_back(t%10);
return n;
}
int main()
{
vector<int>a,b;
string c,d;
cin>>c>>d;
for(int i=c.size()-1;i>=0;i--) a.push_back(c[i]-'0');
for(int j=d.size()-1;j>=0;j--) b.push_back(d[j]-'0');
auto n=add(a,b);
for(int i=n.size()-1;i>=0;i--) cout<<n[i];
return 0;
}
减法
#include<iostream>
#include<vector>
using namespace std;
bool check(vector<int>&a,vector<int>&b)
{
if(a.size()!=b.size()) return a.size()>b.size();
for(int i=a.size()-1;i>=0;i--)
{
if(a[i]!=b[i]) return a[i]>b[i];
}
return true;
}
vector<int>sub(vector<int>&a,vector<int>&b)
{
vector<int>c;
int t=0;
for(int i=0;i<a.size();i++)
{
t=a[i]-t;
if(i<b.size()) t-=b[i];
c.push_back((t+10)%10);
if(t<0) t=1;
else t=0;
}
while(c.size()>1&&c.back()==0) c.pop_back();
return c;
}
int main()
{
string A,B;
cin>>A>>B;
vector<int>a,b;
for(int i=A.size()-1;i>=0;i--) a.push_back(A[i]-'0');
for(int i=B.size()-1;i>=0;i--) b.push_back(B[i]-'0');
if(check(a,b))
{
auto c=sub(a,b);
for(int i=c.size()-1;i>=0;i--) cout<<c[i];
}
else
{
cout<<"-";
auto c=sub(b,a);
for(int i=c.size()-1;i>=0;i--) cout<<c[i];
}
return 0;
}
乘法
#include<iostream>
#include<vector>
using namespace std;
void mul(vector<int>a,int b)
{
vector<int>c;
int t=0;
for(int i=0;i<a.size();i++)
{
t+=a[i]*b;
c.push_back(t%10);
t/=10;
}
while(t>0)
{
c.push_back(t%10);
t/=10;
}
while(c.size()>1&&c.back()==0) c.pop_back();
for(int i=c.size()-1;i>=0;i--) cout<<c[i];
}
int main()
{
string a;
int b;
cin>>a>>b;
vector<int>A;
for(int i=a.size()-1;i>=0;i--) A.push_back(a[i]-'0');
mul(A,b);
return 0;
}
除法
#include<iostream>
#include<algorithm>
#include<vector>
using namespace std;
vector<int>div(vector<int>&a,int &d,int &r)
{
vector<int>c;
for(int i=a.size()-1;i>=0;i--)
{
r=r*10+a[i];
c.push_back(r/d);
r%=d;
}
reverse(c.begin(),c.end());
while(c.size()>1&&c.back()==0) c.pop_back();
return c;
}
int main()
{
string c;
int d;
cin>>c>>d;
vector<int>a;
for(int i=c.size()-1;i>=0;i--) a.push_back(c[i]-'0');
int r=0;
auto b=div(a,d,r);
for(int i=b.size()-1;i>=0;i--)
{
cout<<b[i];
}
cout<<endl<<r<<endl;
return 0;
}
封装板子
#include <bits/stdc++.h>
using namespace std;
class bigint {
#define VC vector<char>
#define pb push_back
#define bt bigint
#define f(i, a, b) for(int i=(a);i<=(b);++i)
#define rf(i, a, b) for(int i=(a);i>=(b);--i)
public:
int symbol = 1;
std::VC _a;
int size() const { return _a.size(); }
char &operator[](int i) { return _a[i]; }
static bt add(bt A, bt B) {
if (A.size() < B.size())return add(B, A);
std::VC C;
int t = 0;
f(i, 0, A.size() - 1) {
t += A[i];
if (i < B.size()) t += B[i];
C.pb(t % 10);
t /= 10;
}
if (t) C.pb(t);
return {C};
}
void resize(int size) { _a.reserve(size); }
static bigint plu(bigint A, bigint B) {
if (A.symbol == -1 && B.symbol == -1) {
auto t = add(A, B);
t.symbol = -1;
return t;
}
if (A.symbol == -1 && B.symbol == 1) { return sub(B, A); }
if (A.symbol == 1 && B.symbol == -1) { return sub(A, B); }
return add(A, B);
}
template<class T,class Y>
friend bt operator+(T A, Y B) { return plu(A, B); }
static bt sub(bt A, bt B) {
A.symbol = 1, B.symbol = 1;
std::VC C;
if (A < B) {
bt a;
a = sub(B, A);
a.symbol = -1;
return a;
}
int t = 0;
f(i, 0, A.size() - 1) {
t = A[i] - t;
if (i < B.size()) t -= B[i];
C.pb((t + 10) % 10);
if (t < 0) t = 1; else t = 0;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return bigint(C);
}
static bt SUB(bt A, bt B) {
if (A.symbol == -1 && B.symbol == -1) {
bigint t;
t = sub(A, B);
t.symbol *= -1;
return t;
}
if (A.symbol == 1 && B.symbol == -1) { return add(A, B); }
if (A.symbol == -1 && B.symbol == 1) {
bigint a = add(A, B);
a.symbol = -1;
return a;
}
return sub(A, B);
}
template<class T,class Y>
friend bt operator-(T A, Y B) { return SUB(A, B); }
static bt smilemul(bt &A, char b) {
if (b == 0)return bt(0);
if (b == 1)return A;
std::VC C;
int t = 0;
for (int i = 0; i < A.size() || t; i++) {
if (i < A.size()) t += A[i] * b;
C.pb(t % 10);
t /= 10;
}
while (C.size() > 1 && C.back() == 0) C.pop_back();
return {C};
}
static bigint mul(bt A, bt B) {
int len1 = A.size(), len2 = B.size(), cnt = len1 + len2;
VC x;
long long *c = new long long[len1 + len2 + 10], t = 0;
f(i, 0, len1 + len2 + 8)c[i] = 0;
f(i, 0, len1 - 1)f(j, 0, len2 - 1)c[i + j] += A[i] * B[j];
f(i, 0, cnt - 1) {
t += c[i];
c[i] = t % 10;
t /= 10;
}
while (t) {
c[++cnt] = t % 10;
t /= 10;
}
while (cnt >= 1 && c[cnt] == 0) cnt--;
x.assign(c, c + cnt + 1);
bigint ans(x, x.size() * 2);
delete[] c;
return {x, int(x.size() * 2)};
}
friend bigint MUL(bt A, bt B) {
if (A.symbol * B.symbol == 1)return mul(A, B);
else {
bt t = mul(A, B);
t.symbol = -1;
return t;
}
}
template<class T,class Y>
friend bt operator*(T A, Y B) { return MUL(A, B); }
static bigint smilediv(bt A, int b) {
char *cha = new char[A.size()], *ans = new char[A.size()];
int l = A.size(), m = l - 1, x = 0;
std::copy(A._a.begin(), A._a.end(), cha);
rf(i, l - 1, 0) {
ans[i] = (x * 10 + cha[i]) / b;
x = (cha[i] + x * 10) % b;
}
while (!ans[m] && m >= 1)m--;
bigint z(0);
z._a.assign(ans, ans + m + 1);
delete []cha;
delete[]ans;
return z;
}
static bigint div(bt A, bt B) {
if (A < B)return {0};
bt l = 1, r = A;
while (l <= r) {
if(r.symbol==-1)exit(1);
bt mid = smilediv(l + r, 2);
if (A < mid * B)r = mid - 1;
else l = mid + 1;
}
return r;
}
friend bigint DIV(bt A, bt B) {
bt t = div(A, B);
if (A.symbol * B.symbol == -1)t.symbol = -1;
return t;
}
template<class T,class Y>
friend bt operator/(T A, Y B) { return DIV(A, B); }
static bigint mod(bt A, bt B) {
bt x = A / B;
return A - x * B;
}
friend bigint MOD(bt A, bt B) { return mod(mod(A, B) + B, B); }
template<class T,class Y>
friend bt operator%(T A, Y B) { return MOD(A, B); }
bigint(VC c, int maxsize) : _a(std::move(c)) { }
bigint(VC c) :_a(std::move(c)) { }
bigint() { _a.assign({0}); }
template<class T>
bigint(T z, int maxsize) {
_a.clear();
unsigned long long x = z;
string s = to_string(x);
if (s[0] != '-')rf(i, s.size() - 1, 0)_a.pb(s[i] - '0');
else {
rf(i, s.size() - 1, 1)_a.pb(s[i] - '0');
symbol = -1;
}
}
template<class T>
bigint(T z) {
_a.clear();
string s;
if (typeid(z) != typeid(const char *) && typeid(z) != typeid(string))s = to_string((long long) z); else s = z;
if (s[0] != '-') { rf(i, s.size() - 1, 0)_a.pb(s[i] - '0'); }
else {
rf(i, s.size() - 1, 1)_a.pb(s[i] - '0');
symbol = -1;
}
}
friend std::ostream &operator<<(std::ostream &os, bt cc) {
if (cc.symbol == -1 && !(cc._a.size() == 1 && cc[0] == 0))os << '-';
rf(i, cc.size() - 1, 0)os << int(cc[i]);
return os;
}
friend std::istream &operator>>(std::istream &is, bt &cc) {
cc._a.clear();
std::string x;
is >> x;
if (x[0] == '-') {
cc.symbol = -1;
rf(i, x.size() - 1, 1)cc._a.pb(x[i] - '0');
}
else
rf(i, x.size() - 1, 0)cc._a.pb(x[i] - '0');
return is;
}
template<class T>
bool operator<(T A) {
bigint other = A;
if (this->symbol == -1 && other.symbol == 1 && !(*(this) == other))return 1;
if (this->size() < other.size())return 1;
else if (this->size() > other.size())return 0;
else if (this->size() == other.size())rf(i, this->size() - 1, 0) { if ((*this)[i] < other[i])return 1; }
return 0;
}
bool operator<(bigint A) {
bigint other = A;
if (this->symbol == -1 && other.symbol == 1 && !(*(this) == other))return 1;
if (this->size() < other.size())return 1;;
if (this->size() > other.size())return 0;
if (this->size() == other.size())rf(i, this->size() - 1, 0) { if ((*this)[i] < other[i])return 1;else if((*this)[i] > other[i])return 0; }
return 0;
}
template<class T>
bool operator==(T A) {
bigint other(A);
if (other._a == this->_a && other.symbol == this->symbol ||
(this->size() == 1 && this->symbol == -1 && other.symbol == 1 && other.size() == 1 && (*this)[0] == 0 &&other[0] == 0))return 1;
return 0;
}
template<class T>
bool operator>(T A) {
bigint other(A);
if (*this < other == 0 && (*this == other) == 0)return true;
return false;
}
template<class T>
bool operator<=(T A) {
bigint other(A);
if (*(this) < other || *this == other)return 1;
return 0;
}
template<class T>
bool operator>=(T A) {
bigint other(A);
if (*(this) > other || *this == other)return 1;
return 0;
}
bigint operator-() {
auto t = *this;
t.symbol *= -1;
return t;
}
bigint operator+=(bt other) {
*this = *this + other;
return *this;
}
bigint operator-=(bt other) {
*this = *this - other;
return *this;
}
bigint operator*=(bt other) {
*this = *this * other;
return *this;
}
bigint operator/=(bt other) {
*this = *this / other;
return *this;
}
bigint operator%=(bt other) {
*this = *this % other;
return *this;
}
bigint operator++(int) {
bt t = *this;
*this = *this + 1;
return t;
}
bigint operator++() {
*this = *this + 1;
return *this;
}
operator int() const {
int t = 0;
for (int i = _a.size() - 1; i >= 0; i--) { t = t * 10 + _a[i]; }
return t;
}
};
int main()
{
bigint a,b,c,d;
cin>>a>>b>>c>>d;
cout<<a+b*c/d;
return 0;
}
Java语法参考
import java.math.BigInteger;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
BigInteger[] f = new BigInteger[1001];
f[0] = BigInteger.ONE;
f[1] = BigInteger.ONE;
f[2] = BigInteger.valueOf(2);
f[3] = BigInteger.valueOf(4);
for (int i = 4; i <= 1000; i++) {
f[i] = f[i - 1].add(f[i - 2]).add(f[i - 4]);
}
while (scanner.hasNextInt()) {
int n = scanner.nextInt();
System.out.println(f[n]);
}
scanner.close();
}
}
逆元
(a/b)%P=(a*b)%P=(a%P)*(b%P)%P
a/b=a*pow(mod,b-2)
快速幂
ll qpow(ll a,ll b,ll mod)
{
ll res=1;
while(b)
{
if(b&1) res=res*a%mod;
a=a*a%mod;
b>>=1;
}
return res;
}
矩阵快速幂
广义的斐波那契数列是指形如 an =p * an-1 +q * an-2 的数列。
#include <iostream>
#include <cstring>
#include <cstdio>
using namespace std;
typedef long long LL;
LL n, Mod, p, q, a1, a2, ans;
struct mat{
LL m[4][4];
}Ans, base;
inline void init() {
Ans.m[1][1] = a2, Ans.m[1][2] = a1;
base.m[1][1] = p, base.m[2][1] = q, base.m[1][2] = 1;
}
inline mat mul(mat a, mat b) {
mat res;
memset(res.m, 0, sizeof(res.m));
for(int i=1; i<=2; i++) {
for(int j=1; j<=2; j++) {
for(int k=1; k<=2; k++) {
res.m[i][j] += (a.m[i][k] % Mod) * (b.m[k][j] % Mod);
res.m[i][j] %= Mod;
}
}
}
return res;
}
inline void Qmat_pow(int p) {
while (p) {
if(p & 1) Ans = mul(Ans, base);
base = mul(base, base);
p >>= 1;
}
}
int main() {
scanf("%lld%lld%lld%lld%lld%lld", &p, &q, &a1, &a2, &n, &Mod);
if(n == 1) {
cout<<a1;
return 0;
}
if(n == 2) {
cout<<a2;
return 0;
}
init();
Qmat_pow(n-2);
ans = Ans.m[1][1];
ans %= Mod;
printf("%lld", ans);
}
龟速乘
ll quick_add(ll a,ll b,ll mol)
{
ll res=0;
while(b)
{
if(b&1) res=(res+a)%mol;
a=(a+a)%mol;
b>>=1;
}
return res;
}
光速幂
- 设底数为
- 主要思想就是分块, 预处理出
和
预处理,
查询
struct Lightspeed_Pow
{
int ST_small[N], ST_big[N];
int block;
int maxn = 1e12; //最大的可能指数
void init(int x) //传入底数a, O(sqrt(n))预处理
{
block = sqrt(maxn) + 1;
ST_small[0] = 1;
for(int i = 1; i <= block; i++)
ST_small[i] = ST_small[i - 1] * x % mod;
ST_big[0] = 1;
for(int i = 1; i <= block; i++)
ST_big[i] = ST_big[i - 1] * ST_small[block] % mod;
}
int calc(int x) //传入指数b, O(1)查询
{
return ST_big[x / block] * ST_small[x % block] % mod;
}
}pw;
牛顿迭代法求立方根
#include<iostream>
#include<cmath>
using namespace std;
double ide(double x,double m)
{
long double y=x*x*x-m,k,b,x0;
if(fabs(y)<0.0000000001)
return x;
else
{
k=x*x*2;
b=y-k*x;
x0=-b/k;
return ide(x0,m);
}
}
int main()
{
long double n,num;
cin>>n;
printf("%.6f",ide(n/2,n));
return 0;
}
扩展欧几里得算法
用于求的一组可行解
int Exgcd(int a, int b, int &x, int &y) {
if (!b) {
x = 1;
y = 0;
return a;
}
int d = Exgcd(b, a % b, x, y);
int t = x;
x = y;
y = t - (a / b) * y;
return d;
}
函数返回的值为,在这个过程中计算
即可。
高斯消元求解线性方程组
高斯消元
-
通过初等行变换 把 增广矩阵 化为 阶梯型矩阵 并回代 得到方程的解
-
适用于求解 包含
个方程,
例如该方程组
增广矩阵为
- 接下来的所有操作都用该增广矩阵,代替原方程组
前置知识:初等行(列)变换
- 把某一行乘一个非
的数 (方程的两边同时乘上一个非
- 交换某两行 (交换两个方程的位置)
- 把某行的若干倍加到另一行上去 (把一个方程的若干倍加到另一个方程上去)
接下来,运用初等行变换,把增广矩阵,变为阶梯型矩阵
阶梯型矩阵
最后再把阶梯型矩阵从下到上回代到第一层即可得到方程的解
算法步骤
枚举每一列c,
- 找到当前列绝对值最大的一行
- 用初等行变换(2) 把这一行换到最上面(未确定阶梯型的行,并不是第一行)
- 用初等行变换(1) 将该行的第一个数变成
- 用初等行变换(3) 将下面所有行的当且列的值变成
#include
#include
#include
using namespace std;
const int N = 110;
const double eps = 1e-6;
int n;
double a[N][N];
int gauss()
{
int c, r;// c 代表 列 col , r 代表 行 row
for (c = 0, r = 0; c < n; c ++ )
{
int t = r;// 先找到当前这一列,绝对值最大的一个数字所在的行号
for (int i = r; i < n; i ++ )
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
if (fabs(a[t][c]) < eps) continue;// 如果当前这一列的最大数都是 0 ,那么所有数都是 0,就没必要去算了,因为它的约束方程,可能在上面几行
for (int i = c; i < n + 1; i ++ ) swap(a[t][i], a[r][i]);//// 把当前这一行,换到最上面(不是第一行,是第 r 行)去
for (int i = n; i >= c; i -- ) a[r][i] /= a[r][c];// 把当前这一行的第一个数,变成 1, 方程两边同时除以 第一个数,必须要到着算,不然第一个数直接变1,系数就被篡改,后面的数字没法算
for (int i = r + 1; i < n; i ++ )// 把当前列下面的所有数,全部消成 0
if (fabs(a[i][c]) > eps)// 如果非0 再操作,已经是 0就没必要操作了
for (int j = n; j >= c; j -- )// 从后往前,当前行的每个数字,都减去对应列 * 行首非0的数字,这样就能保证第一个数字是 a[i][0] -= 1*a[i][0];
a[i][j] -= a[r][j] * a[i][c];
r ++ ;// 这一行的工作做完,换下一行
}
if (r < n)// 说明剩下方程的个数是小于 n 的,说明不是唯一解,判断是无解还是无穷多解
{// 因为已经是阶梯型,所以 r ~ n-1 的值应该都为 0
for (int i = r; i < n; i ++ )//
if (fabs(a[i][n]) > eps)// a[i][n] 代表 b_i ,即 左边=0,右边=b_i,0 != b_i, 所以无解。
return 2;
return 1;// 否则, 0 = 0,就是r ~ n-1的方程都是多余方程
}
// 唯一解 ↓,从下往上回代,得到方程的解
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[j][n] * a[i][j];//因为只要得到解,所以只用对 b_i 进行操作,中间的值,可以不用操作,因为不用输出
return 0;
}
int main()
{
cin >> n;
for (int i = 0; i < n; i ++ )
for (int j = 0; j < n + 1; j ++ )
cin >> a[i][j];
int t = gauss();
if (t == 0)
{
for (int i = 0; i < n; i ++ ) printf("%.2lf\n", a[i][n]);
}
else if (t == 1) puts("Infinite group solutions");
else puts("No solution");
return 0;
}
欧拉函数
求的是小于等于和
互质的数的个数
int euler_phi(int n) {
int ans = n;
for (int i = 2; i * i <= n; i++)
if (n % i == 0) {
ans = ans / i * (i - 1);
while (n % i == 0) n /= i;
}
if (n > 1) ans = ans / n * (n - 1);
return ans;
}
欧拉函数常用于化简一列最大公约数的和,下面记欧拉函数为
素数筛
Miller-Rabin素性测试
一个的素数判定算法
bool millerRabin(int n) {
if (n < 3 || n % 2 == 0) return n == 2;
if (n % 3 == 0) return n == 3;
int u = n - 1, t = 0;
while (u % 2 == 0) u /= 2, ++t;
// test_time 为测试次数,建议设为不小于 8
// 的整数以保证正确率,但也不宜过大,否则会影响效率
for (int i = 0; i < test_time; ++i) {
// 0, 1, n-1 可以直接通过测试, a 取值范围 [2, n-2]
int a = rand() % (n - 3) + 2, v = quickPow(a, u, n);
if (v == 1) continue;
int s;
for (s = 0; s < t; ++s) {
if (v == n - 1) break; // 得到平凡平方根 n-1,通过此轮测试
v = (long long)v * v % n;
}
// 如果找到了非平凡平方根,则会由于无法提前 break; 而运行到 s == t
// 如果 Fermat 素性测试无法通过,则一直运行到 s == t 前 v 都不会等于 -1
if (s == t) return 0;
}
return 1;
}
埃筛
朴素版本
vector<int> prime;
bool is_prime[N];
void Eratosthenes(int n) {
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; ++i) is_prime[i] = true;
for (int i = 2; i <= n; ++i) {
if (is_prime[i]) {
prime.push_back(i);
if ((long long)i * i > n) continue;
for (int j = i * i; j <= n; j += i)
// 因为从 2 到 i - 1 的倍数我们之前筛过了,这里直接从 i
// 的倍数开始,提高了运行速度
is_prime[j] = false; // 是 i 的倍数的均不是素数
}
}
}
顺便维护最大质因子
const int N=1e5+10;
vector<bool> isPrime(N,true);
vector<int> maxPrimeFactor(N,0);
void init(){
isPrime[0]=isPrime[1]=false;
for(int i=2;i<N;i++)
{
if(isPrime[i])
{
maxPrimeFactor[i]=i;
for(int j=i+i;j<N;j+=i)
{
isPrime[j]=false;
maxPrimeFactor[j]=i;
}
}
}
}
区间筛
问题: 对一段区间
执行筛法
在埃氏筛的基础上, 只需要枚举 的所有质数, 就能把
内的所有合数筛掉. 枚举
内的所有质数, 每次筛掉区间
内的合数
const int N = 1000010;
//对区间[a, b]执行筛法
//isprime_seg[i - a] = true 表示 i 是素数
bool isprime_seg[N];
bool isprime_sqrtb[N];
//当a = 1时, 区间筛跑出来isprime_seg[1 - 1] = true(即把1视为素数,因此a=1时加上一个特判)
void get_prime(LL a, LL b)
{
for(int i = 0; (LL)i * i <= b; i++)
isprime_sqrtb[i] = true;
for(int i = 0; i <= b - a; i++)
isprime_seg[i] = true;
for(int i = 2; (LL)i * i <= b; i++)
if(isprime_sqrtb[i])
{
for(int j = 2 * i; (LL)j * j <= b; j += i)
isprime_sqrtb[j] = false; //筛[2, sqrt(b)]
for(LL j = max(2LL, (a + i - 1) / i) * i; j <= b; j += i)
isprime_seg[j - a] = false; //筛[a, b]
}
if(a == 1)
isprime_seg[0] = false;
}
只筛小于 的和奇数优化
的和奇数优化
vector<int> prime;
bool is_prime[N];
void Eratosthenes(int n) {
is_prime[0] = is_prime[1] = false;
for (int i = 2; i <= n; ++i) is_prime[i] = true;
// 大于2的偶数不是质数,先筛掉
for (int i = 4; i <= n; i += 2) is_prime[i] = false;
// i * i <= n 说明 i <= sqrt(n)
for (int i = 2; i * i <= n; ++i) {
if (is_prime[i])
for (int j = i * i; j <= n; j += i) is_prime[j] = false;
}
for (int i = 2; i <= n; ++i)
if (is_prime[i]) prime.push_back(i);
}
只求个数的空间优化
int count_primes(int n) {
constexpr static int S = 10000;
vector<int> primes;
int nsqrt = sqrt(n);
vector<char> is_prime(nsqrt + 1, true);
for (int i = 2; i <= nsqrt; i++) {
if (is_prime[i]) {
primes.push_back(i);
for (int j = i * i; j <= nsqrt; j += i) is_prime[j] = false;
}
}
int result = 0;
vector<char> block(S);
for (int k = 0; k * S <= n; k++) {
fill(block.begin(), block.end(), true);
int start = k * S;
for (int p : primes) {
int start_idx = (start + p - 1) / p;
int j = max(start_idx, p) * p - start;
for (; j < S; j += p) block[j] = false;
}
if (k == 0) block[0] = block[1] = false;
for (int i = 0; i < S && start + i <= n; i++) {
if (block[i]) result++;
}
}
return result;
}
时间复杂度不变但是空间复杂度可以压到
欧筛
vector<int> pri;
bool not_prime[N];
void pre(int n) {
for (int i = 2; i <= n; ++i) {
if (!not_prime[i]) {
pri.push_back(i);
}
for (int pri_j : pri) {
if (i * pri_j > n) break;
not_prime[i * pri_j] = true;
if (i % pri_j == 0) {
// i % pri_j == 0
// 换言之,i 之前被 pri_j 筛过了
// 由于 pri 里面质数是从小到大的,所以 i 乘上其他的质数的结果一定会被
// pri_j 的倍数筛掉,就不需要在这里先筛一次,所以这里直接 break
// 掉就好了
break;
}
}
}
}
欧筛求欧拉函数
vector<int> pri;
bool not_prime[N];
int phi[N];
void pre(int n) {
phi[1] = 1;
for (int i = 2; i <= n; i++) {
if (!not_prime[i]) {
pri.push_back(i);
phi[i] = i - 1;
}
for (int pri_j : pri) {
if (i * pri_j > n) break;
not_prime[i * pri_j] = true;
if (i % pri_j == 0) {
phi[i * pri_j] = phi[i] * pri_j;
break;
}
phi[i * pri_j] = phi[i] * phi[pri_j];
}
}
}
Min25筛
定义积性函数 ,且
(
是一个质数),求
对 取模。
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cmath>
#define ll long long
using namespace std;
const ll MOD=1000000007,inv2=500000004,inv3=333333336;
ll prime[1000005],num,sp1[1000005],sp2[1000005];
ll n,Sqr,tot,g1[1000005],g2[1000005],w[1000005],ind1[1000005],ind2[1000005];
bool flag[1000005];
void pre(int n)//预处理,线性筛
{
flag[1]=1;
for(int i=1;i<=n;i++)
{
if(!flag[i])
{
prime[++num]=i;
sp1[num]=(sp1[num-1]+i)%MOD;
sp2[num]=(sp2[num-1]+1ll*i*i)%MOD;
}
for(int j=1;j<=num&&prime[j]*i<=n;j++)
{
flag[i*prime[j]]=1;
if(i%prime[j]==0)break;
}
}
}
ll S(ll x,int y)//第二部分
{
if(prime[y]>=x)return 0;
ll k=x<=Sqr?ind1[x]:ind2[n/x];
ll ans=(g2[k]-g1[k]+MOD-(sp2[y]-sp1[y])+MOD)%MOD;
for(int i=y+1;i<=num&&prime[i]*prime[i]<=x;i++)
{
ll pe=prime[i];
for(int e=1;pe<=x;e++,pe=pe*prime[i])
{
ll xx=pe%MOD;
ans=(ans+xx*(xx-1)%MOD*(S(x/pe,i)+(e!=1)))%MOD;
}
}
return ans%MOD;
}
int main()
{
scanf("%lld",&n);
Sqr=sqrt(n);
pre(Sqr);
for(ll i=1;i<=n;)
{
ll j=n/(n/i);
w[++tot]=n/i;
g1[tot]=w[tot]%MOD;
g2[tot]=g1[tot]*(g1[tot]+1)/2%MOD*(2*g1[tot]+1)%MOD*inv3%MOD;
g2[tot]--;
g1[tot]=g1[tot]*(g1[tot]+1)/2%MOD-1;
if(n/i<=Sqr)ind1[n/i]=tot;
else ind2[n/(n/i)]=tot;
i=j+1;
}//g1,g2分别表示一次项和二次项,ind1和ind2用来记录这个数在数组中的位置
for(int i=1;i<=num;i++)//由于g数组可以滚动,所以就只开了一维
{
for(int j=1;j<=tot&&prime[i]*prime[i]<=w[j];j++)
{
ll k=w[j]/prime[i]<=Sqr?ind1[w[j]/prime[i]]:ind2[n/(w[j]/prime[i])];
g1[j]-=prime[i]*(g1[k]-sp1[i-1]+MOD)%MOD;
g2[j]-=prime[i]*prime[i]%MOD*(g2[k]-sp2[i-1]+MOD)%MOD;
g1[j]%=MOD,g2[j]%=MOD;
if(g1[j]<0)g1[j]+=MOD;
if(g2[j]<0)g2[j]+=MOD;
}
}
printf("%lld\n",(S(n,0)+1)%MOD);
return 0;
}
GCD/因数相关
大整数的GCD
Stein 算法
- 如果
或
, 则
,
- 如果
- 如果
- 如果
- 如果
, 则
复杂度:
//递归形式
int stein(int a, int b) {
if(a < b) a ^= b, b ^= a, a ^= b;
if(b == 0) return a;
if((!(a & 1)) && (!(b & 1))) return stein(a >> 1, b >> 1) << 1;
else if((a & 1) && (!(b & 1))) return stein(a, b >> 1);
else if((!(a & 1)) && (b & 1)) return stein(a >> 1, b);
else return stein(a - b, b);
}
//迭代形式
int stein(int a, int b) {
int k = 1;
while((!(a & 1)) && (!(b & 1))) {
k <<= 1;
a >>= 1;
b >>= 1;
}
while(!(a & 1)) a >>= 1;
while(!(b & 1)) b >>= 1;
if(a < b) a ^= b, b ^= a, a ^= b;
while(a != b) {
a -= b;
if(a < b) a ^= b, b ^= a, a ^= b;
}
return k * a;
}
试除法分解质因数
void divide(int x)
{
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
{
int s = 0;
while (x % i == 0) x /= i, s ++ ;
cout << i << ' ' << s << endl;
}
if (x > 1) cout << x << ' ' << 1 << endl;
cout << endl;
}
打表求因数和
#include <cstdio>
const int maxn = 500000+2;
int sum[maxn];
int main()
{
for(int i=1; i<maxn; i++)
for(int j=1; i*j<maxn; j++)
sum[i*j] += i;
int a;
while(scanf("%d",&a)!=EOF)
printf("%d\n",sum[a]);
return 0;
}
GCD卷积
#include<bits/stdc++.h>
using namespace std;
/**
* 计算两个数组的gcd卷积
* 参数:
* n: 数组最大下标(1-based)
* a: 第一个数组(长度为n+1,a[0]未使用)
* b: 第二个数组(长度为n+1,b[0]未使用)
* 返回:
* c: gcd卷积数组(c[k] = 所有gcd(i,j)=k的a[i]*b[j]之和)
*/
vector<long long> gcd_convolution(int n, const vector<long long>& a, const vector<long long>& b) {
// 步骤1: 计算倍数和数组f、g
// f[k] = 所有a[i]的和,其中i是k的倍数(i <= n)
// g[k] = 所有b[j]的和,其中j是k的倍数(j <= n)
vector<long long> f(n + 1, 0);
vector<long long> g(n + 1, 0);
for (int k = 1; k <= n; ++k) {
// 遍历k的所有倍数(k, 2k, 3k, ... <=n)
for (int multiple = k; multiple <= n; multiple += k) {
f[k] += a[multiple];
g[k] += b[multiple];
}
}
// 步骤2: 计算h[k] = f[k] * g[k]
// h[k]表示所有i、j是k的倍数时,a[i]*b[j]的和(即gcd(i,j)是k的倍数的情况)
vector<long long> h(n + 1, 0);
for (int k = 1; k <= n; ++k) {
h[k] = f[k] * g[k];
}
// 步骤3: 容斥原理求c[k]
// c[k] = h[k] - 所有c[m]的和(m是k的倍数且m > k)
// 从大到小计算,确保计算c[k]时,所有更大的倍数m的c[m]已求出
vector<long long> c(n + 1, 0);
for (int k = n; k >= 1; --k) {
c[k] = h[k];
// 减去所有k的倍数m(m > k)的c[m]
for (int m = 2 * k; m <= n; m += k) {
c[k] -= c[m];
}
}
return c;
}
// 示例用法
int main() {
// 问题:n=5,计算a和b的gcd卷积
int n = 5;
vector<long long> c = gcd_convolution(n, a, b);//这里需要将两个vector传给函数
// 输出结果
cout << "gcd卷积结果:" << endl;
for (int k = 1; k <= n; ++k) {
cout<<c[k]<<" ";
}
return 0;
}
矩阵
设 为一个域 (如
,
,
等), 满足
,
的数表
称为 上的一个
元矩阵
矩阵乘法
假设 ,
是两个
元矩阵, 它们的乘积
也是一个
元矩阵,
, 满足
矩阵快速幂
int qmi(int m, int k, int p)
{
int res = 1 % p, t = m;
while(k)
{
if(k & 1) res = res * t % p;
t = t * t % p;
k >>= 1;
}
return res;
}
class Array{
public:
int n, m, a[N][N];
Array(int _n, int _m) {
n = _n, m = _m;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
a[i][j] = 0;
}
Array operator + (Array &B) {
Array res(n, m);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
res.a[i][j] = (a[i][j] + B.a[i][j]) % mod;
return res;
}
Array operator - (Array &B) {
Array res(n, m);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
res.a[i][j] = ((a[i][j] - B.a[i][j]) % mod + mod) % mod;
return res;
}
Array operator * (Array &B) {
Array res(n, B.m);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= B.m; j++)
for(int k = 1; k <= m; k++)
res.a[i][j] = (res.a[i][j] + a[i][k] * B.a[k][j] % mod) % mod;
return res;
}
void init() { // 单位矩阵
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
a[i][j] = (i == j ? 1 : 0);
}
void debug() {
cout << "Array(" << n << " x " << m << "):\n";
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
cout << a[i][j] << " \n"[j == m];
}
int sum() { // 直接求元素和
int res = 0;
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
res = (res + a[i][j]) % mod;
return res;
}
void read() {
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
cin >> a[i][j];
}
Array inv() { // 求逆矩阵
Array B(n, n * 2);
for(int i = 1; i <= n; i++)
{
for(int j = 1; j <= n; j++)
B.a[i][j] = a[i][j];
B.a[i][i + n] = 1;
}
for(int i = 1, r; i <= n; i++)
{
r = i;
for(int j = i + 1; j <= n; j++)
if(B.a[j][i] > B.a[r][i]) r = j;
if(r != i) swap(B.a[i], B.a[r]);
int kk = qmi(B.a[i][i], mod - 2, mod); //求逆元
for(int k = 1; k <= n; k++)
{
if(k == i) continue;
int p = B.a[k][i] * kk % mod;
for(int j = i; j <= (n << 1ll); j++)
B.a[k][j] = ((B.a[k][j] - p * B.a[i][j]) % mod + mod) % mod;
}
for(int j = 1; j <= (n << 1ll); j++)
B.a[i][j] = (B.a[i][j] * kk % mod);
}
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
B.a[i][j] = B.a[i][j + n];
B.m = n;
return B;
}
int calc() { // 求行列式
Array B(n, n);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= n; j++)
B.a[i][j] = a[i][j];
int sum = 1;
for(int i = 1, r; i <= n; i++)
{
r = i;
for(int j = i + 1; j <= n; j++)
if(B.a[j][i] > B.a[r][i]) r = j;
if(r != i)
{
swap(B.a[i], B.a[r]);
sum *= -1;
}
int kk = qmi(B.a[i][i], mod - 2, mod); //求逆元
for(int k = n; k > i; k--)
{
int p = B.a[k][i] * kk % mod;
for(int j = i; j <= n; j++)
B.a[k][j] = ((B.a[k][j] - p * B.a[i][j]) % mod + mod) % mod;
}
}
for(int i = 1; i <= n; i++)
sum = ((sum * B.a[i][i]) % mod + mod) % mod;
return sum;
}
};
Array qmi(Array A, int b) {
Array res(A.n, A.n);
res.init();
while (b) {
if (b & 1) res = res * A;
A = A * A;
b = b >> 1;
}
return res;
}
矩阵快速幂优化线性递推常见递推形式
,
分块
整数分块
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define ll long long
#define lowbit(x) x&(-x)
const int MOD=1e9 + 7;
const int N=1e6+10;
int qpow(int num,int k) {
int res=1;
while(k) {
if(k%2) res = (res * num) % MOD;
num = (num * num) % MOD;
k/=2 ;
}
return res % MOD;
}
int inv(int x) {
return qpow(x,MOD-2);
}
int lcm(int x,int y) {
return x * y / __gcd(x,y);
}
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
int Base = uniform_int_distribution<>(8e8,9e8)(rng);
int a[N];
int b[N];
int n,k;
int solve2(int i,int j,int n1)
{
int len = (j - i + 1) % MOD;//这里计算的是区间的长度
int num = (n1 / i) % MOD;//计算的是这个区间块对应的贡献
return len * num % MOD;
}
int solve1(int n1)
{
int sum = 0;
for(int i=2,j=0;i<=n1 && j<=k;i= ++j)
{
int tmp = n1 / i;//枚举商
j = min(n1 / tmp,k);//更新块的边界
sum += solve2(i,j,n1);
}
return sum;
}
void Love_Hitachi_Mako() {
cin>>n>>k;
int ans;
ans = (ans + solve1(n)) % MOD;
ans = (ans + solve1(n - 1)) % MOD;
cout<<(ans + n + k - 1) % MOD<<"\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t=1;
//cin>>t;
while(t--) {
Love_Hitachi_Mako();
}
return 0;
}
除法分块
//2024_SCAU 暑期组队专题训练3-数学&博弈专题(实际上只有一道博弈)
//求余定理+除法分块
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N=200010;
const int Base=255;
const int MOD=1e9+7;
int a[N];
signed main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
//除法分块+求余定理
//首先要知道求余有这样一个等式
//a%b =a - b * a/b (其实就是利用了编程整型计算中除法向下取整定位离a最近的b的倍数)
//将其带入公式中可知
//G(n,k) = n*k - (求和)(i * k/i )
//如果直接枚举i肯定是超时的
//这里又要用到程序中整形计算中除法向下取整的方法:除法分块
//由于除法向下取整,所以会存在多个i的k/i值相同
//所以可以用枚举块的方法,枚举块的左端点,计算k/i,然后计算右端点,再根据右端点更新左端点便可
//那么右端点的值是多少呢
//由于除法向下取整,所以多个k/i相同,同时k/i必然是k的因数
//所以当我用k/(k/i)的时候,得到的肯定是能够使该算式整除的i,即右端点
//枚举块的左端点便可
int n,k;
cin>>n>>k;
int i=1;
int res=0;
while(i<=n)
{
int num1=k/i;//首先计算k/i
if(num1==0) break;
int num2=k/num1;//然后计算该块的右边界
int num=min(n,num2);//注意不要出界
int value=(i+num)/2;//计算平均值便于计算
int len=(num-i+1);//计算区间的长度
res+=num1*(num-i+1)*(i+num)>>1;//注意这里除2放在外面是梯形求和
i=num+1;//更新块的左边界
}
cout<<n*k-res<<endl;
return 0;
}
位运算
位运算的运算律
| 公式名称 | 运算规则 |
|---|---|
| 交换律 | A & B = B & A , A ∧ B = B ∧ A |
| 结合律(注意结合律只能在同符号下进行) | ( A & B ) & C = A & ( B & C ) |
| 等幂律 | A & A = A , A ∣ A = A |
| 零律 | A & 0 = 0 |
| 互补律(注意,这不同于逻辑运算) | A & ∼ A = 0 , A ∣ ∼ A = − 1 |
| 同一律 | A ∣ 0 = A , A ∧ 0 = A |
位运算高级操作
| 功能 | 示例 | 位运算 |
|---|---|---|
| 去掉最后一位 | 0100 − > 0010 | x > > 1 |
| 在最后加一个0 | 0100 − > 1000 | x < < 1 |
| 在最后加一个1 | 0100 − > 1001 | ( x < < 1 ) + 1 |
| 将最后一位变为1 | 0100 − > 0101 | x ∣ 1 |
| 将最后一位变为0 | 0101 − > 0100,这里实际上就是先确保最低位变为1,再减去1。 | ( x ∣ 1 ) − 1 |
| 最后一位取反 | 0100 − > 0101,利用异或性质,其中除最后一位其余不变。 | x ∧ 1 |
| 把右数的第k位变为1 | 0001 − > 1001 , k = 4 | x ∣ ( 1 < < ( k − 1 ) ) |
| 把右数的第k位变为0 | 1001 − > 0001 , k = 4,这个操作实际上就是先得到了1000,然后取反得到0111,最后利用按位与的性质其余位不变,最高位为0 | x & ( ∼ ( 1 < < ( k − 1 ) ) ) |
| 把右数的第k位取反 | 1000 − > 0000 , k = 4,利用异或性质 | x ∧ ( 1 < < ( k − 1 ) ) |
对顶堆动态维护中位数
#include <bits/stdc++.h>
using namespace std;
int a[100010],n;
priority_queue<int> q1;//down底
priority_queue<int,vector<int>,greater<int> > q2;//up顶
int main() {
cin>>n;
for(int i=1;i<=n;i++)
cin>>a[i];
q2.push(a[1]);
for(int i=2;i<=n+1;i++){
//if(i%2==0) cout<<q2.top()<<"\n";
if(i>n) break;
if(q2.size()>q1.size()){
if(a[i]>q2.top()){
q1.push(q2.top());
q2.pop();
q2.push(a[i]);
}else q1.push(a[i]);
}else{
if(a[i]<q1.top()){
q2.push(q1.top());
q1.pop();
q1.push(a[i]);
}else q2.push(a[i]);
}
}
return 0;
}
排列组合
圆排列
n 个不同元素随机取一圈的图推列数,记做 Qn
考虑其中已经排序的一圈,从不同位置断开,又变成 n 个不同的线性排列,又变成 n 个不同的线性排列,,则
例如,3 个不同元素的最排列列数为
把左边图排列列断开,可得线性排列:1,2,3;2,3,1;3,1,2
把右边图排列列断开,可得线性排列:1,3,2;3,2,1;2,1,3
对于 n 个不同元素,选 m 个元素取一圈的图推列数,
记做 ,最终
错位排列
错位排列是没有任何元素出现在其有序位置的排列。对于 的排列
,如果满足
,则
是
的错位排列。
错位排列数
,即
,即
,即
,即
递推式
边界
,
求组合数
预处理逆元求组合数
const ll MOD=1e9+7;
const int N=2e6+10;
ll fact[N],infact[N];
void ini()
{
fact[0]=infact[0]=1;
for(int i=1;i<N;i++)
{
fact[i]=fact[i-1]*i%MOD;
infact[i]=qpow(fact[i],MOD-2);
}
}
ll C(ll a,ll b)
{
if(a<b)
return 0;
return fact[a]*infact[b]%MOD*infact[a-b]%MOD;
}
Lucas定理求组合数
Lucas定理: 若p是质数, 则对于任意整数 1
m




(mod p)
求组合数Ⅲ
(mod p)
//快速幂模板
int qmi(int a,int k,int p)
{
int res=1;
while(k)
{
if(k&1)(long long)res=res*a%p;
a=(long long)a*a%p;
k>>=1;
}
return res;
}
//通过定理求组合数C_a^b
int C(int a,int b,int p)
{
if(a<b)return 0;
long long x=1,y=1; //x是分子,y是分母
for(int i=a,j=1;j<=b;i--,j++)
{
x=(long long)x*i%p;
y=(long long)y*j%p;
}
return x*(long long)qmi(y,p-2,p)%p;
}
int Lucas(long long a,long long b,int p)
{
if(a<p&&b<p)return C(a,b,p);
return (long long)C(a%p,b%p,p)*Lucas(a/p,b/p,p)%p;
}
一些公式
排列数公式
排列数性质
组合数公式
组合数性质
组合数求和公式
二项式定理
二项式系数
,
有关二项式系数的恒等式
朱世杰恒等式
二阶求和公式
范德蒙恒等式
三阶求和公式 李善兰恒等式
FFT
A * B Problem Plus (HDU 1402) : 求 , 其中
,
的长度不超过
令 ,
#include <bits/stdc++.h>
using namespace std;
const int N = 200010;
const double PI = acos(-1.0);
struct Complex { // 复数
double x, y;
Complex(double _x = 0.0, double _y = 0.0) {
x = _x;
y = _y;
}
Complex operator-(const Complex &b) const {
return Complex(x - b.x, y - b.y);
}
Complex operator+(const Complex &b) const {
return Complex(x + b.x, y + b.y);
}
Complex operator*(const Complex &b) const {
return Complex(x * b.x - y * b.y, x * b.y + y * b.x);
}
};
/*
* 进行 FFT 和 IFFT 前的反置变换
* 位置 i 和 i 的二进制反转后的位置互换
*len 必须为 2 的幂
*/
void change(Complex y[], int len) {
int i, j, k;
for (int i = 1, j = len / 2; i < len - 1; i++) {
if (i < j) swap(y[i], y[j]);
// 交换互为小标反转的元素,i<j 保证交换一次
// i 做正常的 + 1,j 做反转类型的 + 1,始终保持 i 和 j 是反转的
k = len / 2;
while (j >= k) {
j = j - k;
k = k / 2;
}
if (j < k) j += k;
}
}
/*
* 做 FFT
*len 必须是 2^k 形式
*on == 1 时是 DFT,on == -1 时是 IDFT
*/
void fft(Complex y[], int len, int on) {
change(y, len); // 蝴蝶变换
for (int h = 2; h <= len; h <<= 1) {
Complex wn(cos(2 * PI / h), sin(on * 2 * PI / h));
for (int j = 0; j < len; j += h) {
Complex w(1, 0);
for (int k = j; k < j + h / 2; k++) {
Complex u = y[k];
Complex t = w * y[k + h / 2];
y[k] = u + t;
y[k + h / 2] = u - t;
w = w * wn;
}
}
}
if (on == -1) {
for (int i = 0; i < len; i++) {
y[i].x /= len;
}
}
}
int n, m;
string A, B;
Complex a[N], b[N], c[N];
int sum[N];
void solve()
{
n = A.size(), m = B.size();
int len = 1;
// FFT 要求 len 是 2 的幂次
while(len < n * 2 || len < m * 2)
len <<= 1;
for(int i = 0; i < n; i++)
a[i] = Complex(A[n - i - 1] - '0', 0);
for(int i = n; i < len; i++)
a[i] = Complex(0, 0);
for(int i = 0; i < m; i++)
b[i] = Complex(B[m - i - 1] - '0', 0);
for(int i = m; i < len; i++)
b[i] = Complex(0, 0);
// DFT 将 A, B 从系数表示转化为点值表示
fft(a, len, 1);
fft(b, len, 1);
// 计算 C(x) = A(x)B(x) 的点值表示
for(int i = 0; i < len; i++)
c[i] = a[i] * b[i];
// IDFT 将 C 从点值表示转化为系数表示
fft(c, len, -1);
// 计算 C(10) 的值
for(int i = 0; i < len; i++)
sum[i] = int(c[i].x + 0.5);
int t = 0;
for(int i = 0; i < len; i++)
{
sum[i] += t;
t = sum[i] / 10;
sum[i] %= 10;
}
len --;
// 去除前导零
while(len > 0 && sum[len] == 0)
len --;
for(int i = len; i >= 0; i--)
cout << sum[i];
cout << '\n';
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
while(cin >> A)
{
cin >> B;
solve();
}
return 0;
}
NTT
快速数论变换(NTT)其算法的本质思想跟FFT无异,只是将复数域上的变换,移动到了取模域,将单位根替换为其在取模域的等价
namespace NTT//优化过的ntt,使用时记得初始化。998244353,1004535809,469762049,985661441,167772161. g = 3.950009857,g=7
{
const int p = 998244353,g = 3;
int w[maxn<<2],inv[maxn<<2],r[maxn<<2],last;
int mod(int x){return x >= p ? x - p : x;}
ll qp(ll base,ll n)
{
base %= p;
ll res = 1;
while(n){
if(n&1) (res *= base) %= p;
(base *= base) %= p;
n >>= 1;
}
return res;
}
void init()
{
int lim = maxn << 1;//最长数组的两倍
inv[1] = 1;
for(int i=2;i<=lim;i++) inv[i] = mod(p - 1ll * (p / i) * inv[p%i] % p);
for(int i=1;i<lim;i<<=1)
{
int wn = qp(g,(p - 1) / (i<<1));
for(int j=0,ww=1;j<i;j++,ww=1ll*ww*wn%p) w[i+j] = ww;
}
}
void ntt(vector<int> &f,int n,int op)
{
if(last!=n)
{
for(int i=1;i<n;i++) r[i] = (r[i>>1]>>1)|((i&1)?(n>>1):0);
last=n;
}
for(int i=1;i<n;i++) if(i<r[i])swap(f[i],f[r[i]]);
for(int i=1;i<n;i<<=1)
for(int j=0;j<n;j+=i<<1)
for(int k=0;k<i;k++)
{
int x=f[j+k],y=1ll*f[i+j+k]*w[i+k]%p;
f[j+k]=mod(x+y);f[i+j+k]=mod(x-y+p);
}
if(op==-1)
{
reverse(&f[1],&f[n]);
for(int i=0;i<n;i++)f[i]=1ll*f[i]*inv[n]%p;
}
}
}
using NTT::ntt;
多重集+容斥定理计算
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define ll long long
#define lowbit(x) x&(-x)
const int MOD= 998244353;
const int N=1e6+10;
int qpow(int num,int k) {
int res=1;
while(k) {
if(k%2) res = (res * num) % MOD;
num = (num * num) % MOD;
k/=2 ;
}
return res % MOD;
}
int inv(int x) {
return qpow(x,MOD-2);
}
int lcm(int x,int y) {
return x * y / __gcd(x,y);
}
mt19937 rng(chrono::steady_clock::now().time_since_epoch().count());
int Base = uniform_int_distribution<>(8e8,9e8)(rng);
int a[N];
int b[N];
int prex[N];//预处理阶乘
int freq[N];//记录每个数字的出现次数
int isprime[2 * N];//记录是否为质数
int vis[2 * N];
vector<int>prime;
int dp[N];//记录每个数字被选为第i个质数下的方案个数
void init()
{
prex[0] = 1;
for(int i=1;i<=1000000;i++) prex[i] = (prex[i - 1] * i) % MOD;
for(int i=2;i<=N;i++)
{
if(!vis[i]) prime.push_back(i),isprime[i] = 1;
int cnt = prime.size();
for(int j=0;j<cnt;j++)
{
if(i * prime[j] > N) break;
vis[i * prime[j]] = 1;
if(i % prime[j] == 0) break;
}
}
}
void Love_Hitachi_Mako() {
int n;
cin>>n;
for(int i=1;i<=2 * n;i++) cin>>a[i],freq[a[i]]++;
int freqx = 1;
for(int i=1;i<=1000000;i++)
{
freqx = (freqx * prex[freq[i]]) % MOD;//计算所有数字出现次数的阶乘的乘积
}
int C = (prex[n] * inv(freqx)) % MOD;//这里首先计算的是在固定n个质数的情况下,n个指数的分配个数
//cout<<prex[n]<<" "<<freqx<<" "<<C<<"\n";
set<int>st;//记录2n个数字里面的质数
for(int i=1;i<=2 * n;i++) if(isprime[a[i]]) st.insert(a[i]);
if(st.size() < n)
{
cout<<0<<"\n";
return ;
}
dp[0] = 1;
for(auto p : st)
{
for(int j=n;j>=1;j--)
{
//cout<<j<<" "<<p<<" "<<dp[j - 1]<<" "<<freq[p]<<"\n";
dp[j] = (dp[j] + (dp[j - 1] * freq[p]) % MOD) % MOD;//这里使用了分步计数法,选择p作为第j个数字的方案个数就是选择j-1的方案个数乘上p的可选择数
}
}
cout<<(dp[n] * C) % MOD<<"\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
init();
int t=1;
//cin>>t;
while(t--) {
Love_Hitachi_Mako();
}
return 0;
}
数论相关
杨辉三角
卢卡斯定理
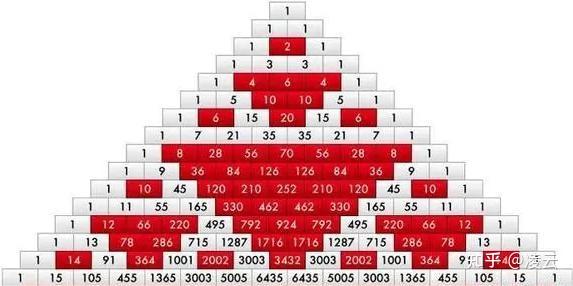
图为杨辉三角中能被2整除的数的分布,呈倒三角且具有分形的性质
对于一个质数,则有:
用于求大组合数取模
long long Lucas(long long a, long long b, long long m)
{
if (b == 0) return 1;
return (C(a % m, b % m, m) * Lucas(a / m, b / m, m)) % m;
}
杨辉三角形第2的幂行所有数都是奇数,此为卢卡斯定理的特殊情况。
其他奇妙小性质性质
- 第
行(第
行(第
层)正中央的数字。
- 将三角形左端对齐之后,沿右斜45度的对角线方向取得的数之和为斐波那契数。
- 将第奇数行正中央的数减去其左侧(或右侧)第二个数,得到的差为卡塔兰数。
卡特兰数
**例:**入栈顺序为,求所有可能的出栈顺序的总数。
#include <iostream>
using namespace std;
int n;
long long f[25];
int main() {
f[0] = 1;
cin >> n;
for (int i = 1; i <= n; i++) f[i] = f[i - 1] * (4 * i - 2) / (i + 1);
cout << f[n] << endl;
return 0;
}
常用公式
常见问题
- 有2n个人排成一行进入剧场。入场费5元。其中只有n个人有一张5元钞票,另外n人只有10 元钞票,剧院无其它钞票,问有多少种方法使得只要有10元的人买票,售票处就有5元的钞票找零?
- 有一个大小为n × n 的方格图左下角为 (0,0)右上角为(n,n),从左下角开始每次都只能向右或者向上走一单位,不走到对角线y=x上方(但可以触碰)的情况下到达右上角有多少可能的路径?
- 在圆上选择2n个点,将这些点成对连接起来使得所得到的n条线段不相交的方法数?
- 对角线不相交的情况下,将一个凸多边形区域分成三角形区域的方法数?
- 一个栈(无穷大)的进栈序列为1,2,3,···,n有多少个不同的出栈序列?
- n个结点可构造多少个不同的二叉树?
- 由n个+1和n个-1组成的排列中,满足前缀和>=0的排列有多少种?
- 括号化问题。左括号和右括号各有n个时,合法的括号表达式的个数有多少种?
- 对凸n+2边形进行不同的三角形分割(只连接顶点对形成n个三角形)数为多少?
定义法求卡特兰数
int solve1()
{
f1[0] = f1[1] = 1;
cin >> n;
for (int i = 2; i <= n; i++)
{
for (int j = 0; j < i; j++)
{
f1[i] += (f1[j] * f1[i - j - 1]); //f(n)=f(0)f(n-1)+f(1)f(n-2)+...+f(n1)f(0)
}
}
printf("%lld\n", f1[n]);
return 0;
}
int solve2()
{
f2[0] = f2[1] = 1;
cin >> n;
for (int i = 2; i <= n; i++)
{
f2[i] += f2[i - 1] * (4 * i - 2) / (i + 1); //f(n)=f(n-1)*(4*n-2)/(n+1)
}
printf("%lld\n", f2[n]);
return 0;
}
//公式3:
int solve3()
{
cin >> n;
for (int i = 1; i <= 2 * n; i++)
{
f[i][0] = f[i][i] = 1;
for (int j = 1; j < i; j++)
{
f[i][j] = f[i - 1][j] + f[i - 1][j - 1]; //f(n)=c(2n,n)/(n+1)
}
}
printf("%lld", f[2 * n][n] / (n + 1));
return 0;
}
卡特兰数求模模板
const int C_maxn = 1e4 + 10;
LL CatalanNum[C_maxn];
LL inv[C_maxn];
inline void Catalan_Mod(int N, LL mod)
{
inv[1] = 1;
for(int i=2; i<=N+1; i++)///线性预处理 1 ~ N 关于 mod 的逆元
inv[i] = (mod - mod / i) * inv[mod % i] % mod;
CatalanNum[0] = CatalanNum[1] = 1;
for(int i=2; i<=N; i++)
CatalanNum[i] = CatalanNum[i-1] * (4 * i - 2) %mod * inv[i+1] %mod;
}
斯特林数
斯特林数主要处理的是把个不同的元素分成
个集合或环的个数问题
第二类斯特林数
表示将个元素划分为
个集合,每个集合非空的方案数,记作
,又称为斯特林子集数
const int N=5e3+3;
ll S[N][N];
void cal()
{
S[0][0]=1;
for(int i=1;i<N;++i)
{
for(int j=1;j<=i;++j)
S[i][j]=S[i-1][j-1]+(ll)j*S[i-1][j];
}
}
const int N=2e5+3;
ll v[N];
int p[N>>2],n;
void seive()
{
int cnt=0;
v[1]=1;//!!
for(int i=2;i<N;++i)
{
if(!v[i])
{
p[cnt++]=i;
v[i]=fast_power(i,n);
}
for(int j=0;j<cnt && i*p[j]<N;++j)
{
v[i*p[j]]=v[i]*v[p[j]]%mod;
if(i%p[j]==0)
break;
}
}
}
ll cal(int m)
{
ll res=0;
for(int i=0;i<=m;++i)
{
if((m-i)&1)
res=(res-v[i]*inv[i]%mod*inv[m-i]%mod+mod)%mod;
else
res=(res+v[i]*inv[i]%mod*inv[m-i]%mod)%mod;
}
return res;
}
第一类斯特林数
个不同元素构成
个圆排列的方案数,记为
const int N=5e3+3;
ll s[N][N];
void cal()
{
s[0][0]=1;
for(int i=1;i<N;++i)
{
for(int j=1;j<=i;++j)
s[i][j]=s[i-1][j-1]+(ll)(i-1)*s[i-1][j];
}
}
线性基
线性基三大性质
- 原序列里面的任意一个数都可以由线性基里面的一些数异或得到
- 线性基里面的任意一些数异或起来都不能得到
- 线性基里面的数的个数唯一,并且在保持性质一的前提下,数的个数是最少的
void add(ll x)
{
for(int i=60;i>=0;i--)
{
if(x&(1ll<<i))//注意,如果i大于31,前面的1的后面一定要加ll
{
if(d[i])x^=d[i];
else
{
d[i]=x;
break;//插入成功就退出
}
}
}
}
得出的d为a的线性基
数列中取若干值最大化异或和
首先构造出这个序列的线性基,然后从线性基的最高位开始,假如当前的答案异或线性基的这个元素可以变得更大,那么就异或它,答案的初值为0。
ll ans()
{
ll anss=0;
for(int i=60;i>=0;i--)//记得从线性基的最高位开始
if((anss^d[i])>anss)anss^=d[i];
return anss;
}
中国剩余定理
问题:
一堆物品
3个3个分剩2个
5个5个分剩3个
7个7个分剩2个
问这个物品有多少个
//n个方程:x=a[i](mod m[i]) (0<=i<n)
LL china(int n, LL *a, LL *m){
LL M = 1, ret = 0;
for(int i = 0; i < n; i ++) M *= m[i];
for(int i = 0; i < n; i ++){
LL w = M / m[i];
ret = (ret + w * inv(w, m[i]) * a[i]) % M;
}
return (ret + M) % M;
}
威尔逊定理
是
为质数的充分必要条件
裴蜀定理
关于未知数和
的线性丢番图方程
有整数解时当且仅当
是
及
的最大公约数
的倍数。
例如,12和42的最大公约数是6,则方程有解,其中每组解
、
都被称为裴蜀数,可用拓展欧几里得算法求得。
博弈论
Nim博弈
给定n堆石子,两位玩家轮流操作,每次操作可以从任意一堆石子中拿走任意数量的石子(可以拿完,但不能不拿),最后无法进行操作的人视为失败。 问如果两人都采用最优策略,先手是否必胜。
结论:如果所有石子数的异或和不等于0,则先手必胜,反之先手必败。
巴什博弈
有一堆总数为n的物品,2名玩家轮流从中拿取物品。每次至少拿1件,至多拿m件,不能不拿,最终将物品拿完者获胜。
if (n % (p + q) == 0)//p为最少取,q为最多取
{
printf("second\n"); //必败态
}
else
{
printf("first\n"); //必胜态
}
威佐夫博弈
有两堆各若干个物品,两个人轮流从任一堆取至少一个或同时从两堆中取同样多的物品,规定每次至少取一个,多者不限,最后取光者得胜。
结论:两堆物品n,m个(n<=m), 如果第一个数等于两数差值*黄金比例再向下取整,那么是一个奇异局势
#include<iostream>
#include<cmath>
#include<cstdio>
#define endl '\n'
using namespace std;
const int M = 1000;
int a[M];
const double lorry =(sqrt(5.0)+1.0)/2;
//奇异局势:第一个数是两数差值*黄金比列向下取整
int main()
{
int m,n;
while(cin>>n>>m)
{
if(n>m) swap(n,m);
int d = m-n;
if(n==(int)(d*lorry)) printf("0\n");
else printf("1\n");
}
return 0;
}
反Nim博弈
有三堆各若干个物品,两个人轮流从某一堆取任意多的物品,规定每次至少取一个,多者不限,最后取光者得负。
结论:先手胜利条件:①各堆石子个数不都为1, 异或和不为0;②各堆石子个数都为1,异或和为0;否则后手胜利
斐波那契博弈
一堆石子有n个,两人轮流取,先取者第一次可以去任意多个,但是不能取完,以后每次取的石子数不能超过上次取子数的2倍。取完者胜。
同样是一个规律:先手胜当且仅当n不是斐波那契数。
海盗分金博弈
背景
5个海盗抢到了100枚金币,每一颗都一样的大小和价值。
他们决定这么分:
- 抽签决定自己的号码(1,2,3,4,5)
- 首先,由1号提出分配方案,然后大家5人进行表决,当半数以上的人同意时(包括半数),按照他的提案进行分配,否则将被扔入大海喂鲨鱼。
- 如果1号死后,再由2号提出分配方案,然后大家4人进行表决,当且仅当半超过半数的人同意时,按照他的提案进行分配,否则将被扔入大海喂鲨鱼。
- 依次类推......
每个海盗都是很聪明的人,都能很理智的判断得失,从而做出选择。
第一个海盗提出怎样的分配方案才能够使自己的收益最大化?
(如果在规则中加上下面一条会更加完善:海盗在自己的收益最大化的前提下乐意看到其他海盗被扔入大海喂鲨鱼。不加也说的过去,因为其他海盗被扔入大海喂鲨鱼符合每个海盗的最大化利益。)
背景分析
首先到了4号提出的方案的时候肯定是最终方案,因为不管5号同意不同意都能通过,所以4号5号不必担心自己被投入大海。那此时5号获得的金币为0,4号获得的金币为100。
5号:因为4号提方案的时候 ,自己获取的金币为0 。所以只要4号之前的人分配给自己的金币大于0就同意该方案。
4号:如果3号提的方案一定能获得通过(原因:3号给5号的金币大于0, 5号就同意 因此就能通过),那自己获得的金币就为0,所以只要2号让自己获得的金币大于0就会同意。
3号:因为到了自己提方案的时候可以给5号一金币,自己的方案就能通过,但考虑到2号提方案的时候给4号一个金币,2号的方案就会通过,那自己获得的金币就为0。所以只要1号让自己获得的金币大于0就会同意。
2号:因为到了自己提方案的时候只要给4号一金币,就能获得通过,根本就不用顾及3 号 5号同意不同意,所以不管1号怎么提都不会同意。
1号:2号肯定不会同意。但只要给3号一块金币,5号一块金币(因为5号如果不同意,那么4号分配的时候,他什么都拿不到)就能获得通过。
所以答案是
98,0,1,0,1。
一般结论
有X个海盗,A 颗宝石,其它规则同上。
当X< 2A+2时,
则1号海盗的最大化收益 Y=A+1-((X+1)/2所得数取整)。
(当X=2A+1时,1号海盗的最大化收益为0,但可保命。)
当X>=2A+2时,
若X=2A+2的B次幂,则1号海盗可保命,但无收益。其他海盗的收益情况由前面讨论可知有规律,但海盗的编号不固定,对它们的表述省略。
若X不等于2A+2的某次幂,设B=b是能使(X>2A+2的B次幂)成立的最大B,则(X+1-(2A+2的b次幂))号海盗可保命,但无收益。之前的海盗都会被扔到海里去喂鱼。之后的海盗的收益情况由前面讨论可知有规律,但海盗的编号不固定,对它们的表述省略。
数据结构
并查集
const int N = 100010;
int fa[N];
int find(int x) {
return x == fa[x] ? x : fa[x] = find(fa[x]);
}
void merge(int x, int y) {
fa[find(x)] = find(y);
}
void init(int n) {
for (int i = 1; i <= n; i++) {
fa[i] = i;
}
}
离散化
#include<iostream>
#include<vector>
#include<algorithm>
typedef std::pair<int, int> PLL;
int n, m;//n次询问,m次查询
int x, c;//在x加上 c
int l, r;//输出区间值
std::vector<int> alls;//所有的下标放的位置
std::vector<PLL> add;//插入修改值
std::vector<PLL> query;//查询操作
int sum[3000000];//离散化后的数组,变成前缀和数组
int find(int x)
{
int l = -1, r = alls.size();
int mid = l + r >> 1;
while (l + 1 < r)
{
if (alls[mid] >= x)
r = mid;
else
l = mid;
mid = l + r >> 1;
}
return l + 1;
}
int main()
{
std::cin >> n >> m;
// 1 第一步 离散化下标
for (int i = 1; i <= n; i++)
{ //离散化插入区间
std::cin >> x >> c;
add.push_back({x, c});
alls.push_back(x);
}
for (int i = 1; i <= m; i++)
{ //离散化查询区间
std::cin >> l >> r;
query.push_back({l, r});
alls.push_back(l);
alls.push_back(r);
}
// 2 排序去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end());
// 3 插入操作
for (auto item: add)
{
int x = find(item.first); //将这个下标在alls数组中找到,使用alls的下标作为下标
sum[x] += item.second;
}
// 4 前缀和
for (int i = 1; i <= alls.size(); i++)
sum[i] += sum[i - 1];
// 5 查询
for (auto item: query)
{
int l = find(item.first);
int r = find(item.second);
std::cout << sum[r] - sum[l - 1] << std::endl;
}
return 0;
}
树状数组
lowbit(x)表示x的二进制表示中最低位的1代表的值。
#define lowbit(x) ((x) & -(x))
class FenwickTree {
private:
vector<int> sums_;
public:
FenwickTree(int n) : sums_(n + 1, 0) {}
void update(int i, int delta) {
while (i < sums_.size()) {
sums_[i] += delta;
i += lowbit(i);
}
}
int query(int i) const {
int sum = 0;
while (i > 0) {
sum += sums_[i];
i -= lowbit(i);
}
return sum;
}
int query(int i, int j) const {
return query(j) - query(i - 1);
}
};
二维树状数组
#include<bits/stdc++.h>
using namespace std;
const long long N = 2e5 + 20;
long long s[301][301][101],a[301][301];
const long long inf = 0x3f;
const long long Ninf = 0xc0;
const long long mod = 1e9 + 7;
const long long mol = 998244353;
typedef pair<long long, long long> pll;
long long n,m;
long long lowbit(long long x) {
return x & (-x);
}
void add(long long x,long long y,long long c,long long val) {//c是颜色
for(long long i=x;i<=n;i+=lowbit(i)) {
for(long long j=y;j<=m;j+=lowbit(j)) {
s[i][j][c]+=val;
}
}
}
long long query(long long x,long long y,long long c) {
long long res=0;
for(long long i=x;i;i-=lowbit(i)) {
for(long long j=y;j;j-=lowbit(j)) {
res+=s[i][j][c];
}
}
return res;
}
void solve() {
cin>>n>>m;
for(long long i=1;i<=n;i++) {
for(long long j=1;j<=m;j++) {
long long c;
cin>>c;
a[i][j]=c;
add(i,j,c,1);//s[i][j][c]++
}
}
long long q;
cin>>q;
while(q--) {
long long op;
cin>>op;
if(op==1) {
long long x,y,c;
cin>>x>>y>>c;
add(x,y,a[x][y],-1);
a[x][y]=c;
add(x,y,c,1);
}
else {
long long x1,y1,x2,y2,c;
cin>>x1>>x2>>y1>>y2>>c;
long long ans=0;
ans=query(x2,y2,c)-query(x2,y1-1,c)-query(x1-1,y2,c)+query(x1-1,y1-1,c);
cout<<ans<<endl;
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
long long t = 1;
//cin>>t;
while (t--)
solve();
return 0;
}
权值树状数组
#include<bits/stdc++.h>
using namespace std;
const long long N = 2e5 + 20;
long long a[N],b[N];
const long long inf = 0x3f;
const long long Ninf = 0xc0;
const long long mod = 1e9 + 7;
const long long mol = 998244353;
typedef pair<long long, long long> pll;
long long s[N],n,m,idx;
long long lowbit(long long x) {
return x&(-x);
}
void add(long long x,long long val) {
while(x<=n) {
s[x]+=val;
x+=lowbit(x);
}
}
long long find_kth(long long k) {//找第k小
long long ans=0,sum=0;
for(long long i=20;i>=0;i--) {
ans+=(1<<i);
if(ans>n || sum+s[ans]>=k)//因为要考虑有重复元素,所以我们找的其实是一个满足小于他的个数小于k的最大数
ans-=(1<<i);
else
sum+=s[ans];
}
return ans+1;
}
void solve() {
long long i, j, k,ma = 0, ans = 0, sum = 0;
cin>>n;
for(i=1;i<=n;i++)
cin>>a[i],b[i]=a[i];
sort(b+1,b+1+n);
idx=unique(b+1,b+1+n)-b-1;//离散化
for(i=1;i<=n;i++) {
a[i]=lower_bound(b+1,b+1+idx,a[i])-b;
}
for(i=1;i<=n;i++) {//建立权值树状数组
add(a[i],1);
if(i&1) {//奇数时,输出[1,i]的中位数
cout<<b[find_kth((i+1)/2)]<<endl;
}
}
}
int main() {
ios::sync_with_stdio(false);
cin.tie(0);
long long t = 1;
// cin >> t;
while (t--)
solve();
return 0;
}
线段树
evil的封装们
- 可以用线段树维护信息条件之一就是, 区间信息满足可加性
- 对于简单问题来说, 没有必要对懒标记做很复杂的设计, 但是当需要维护的信息足够复杂, 或者修改操作足够复杂, 多种懒标记互相影响时, 这是有必要的
- 在复杂问题中, 至少要为
设计如下三个函数
pushdown()标记下传
cal_lazy()tag_union()
维护四种操作:
- 询问区间
内的元素和
- 询问区间
- 将区间
- 将区间
struct tnode
{
long long sum[2], lazy[2];
int l, r;
};
struct Segment_Tree
{
tnode t[4 * MAXN];
void init_lazy(int root)
{
t[root].lazy[0] = 1;
t[root].lazy[1] = 0;
}
void union_lazy(int fa, int ch)
{
long long temp[2];
temp[0] = t[fa].lazy[0] * t[ch].lazy[0];
temp[1] = t[fa].lazy[0] * t[ch].lazy[1] + t[fa].lazy[1];
t[ch].lazy[0] = temp[0];
t[ch].lazy[1] = temp[1];
}
void cal_lazy(int root)
{
t[root].sum[1] = t[root].lazy[0] * t[root].lazy[0] * t[root].sum[1]
+ t[root].lazy[1] * t[root].lazy[1] * (t[root].r - t[root].l + 1)
+ t[root].lazy[0] * t[root].lazy[1] * 2 * t[root].sum[0];
t[root].sum[0] = t[root].lazy[0] * t[root].sum[0]
+ t[root].lazy[1] * (t[root].r - t[root].l + 1);
return;
}
void push_down(int root)
{
if (t[root].lazy[0] != 1 || t[root].lazy[1] != 0)
{
cal_lazy(root);
if (t[root].l != t[root].r)
{
int ch = root << 1;
union_lazy(root, ch);
union_lazy(root, ch + 1);
}
init_lazy(root);
}
}
void update (int root)
{
int ch = root << 1;
push_down(ch);
push_down(ch + 1);
t[root].sum[0] = t[ch].sum[0] + t[ch + 1].sum[0];
t[root].sum[1] = t[ch].sum[1] + t[ch + 1].sum[1];
}
void build(int root, int l, int r)
{
t[root].l = l;
t[root].r = r;
init_lazy(root);
if (l != r)
{
int mid = (l + r) >> 1;
int ch = root << 1;
build(ch, l, mid);
build(ch + 1, mid + 1, r);
update(root);
}
else
{
t[root].sum[0] = A[l];
t[root].sum[1] = A[l] * A[l];
}
}
void change(int root, int l, int r, long long delta, int op)
{
push_down(root);
if (l == t[root].l && r == t[root].r)
{
t[root].lazy[op] = delta;
return;
}
int mid = (t[root].l + t[root].r) >> 1;
int ch = root << 1;
if (r <= mid)change(ch, l, r, delta,op);
else if (l > mid)change(ch + 1, l, r, delta,op);
else
{
change(ch, l, mid, delta,op);
change(ch + 1, mid + 1, r, delta,op);
}
update(root);
}
long long sum(int root, int l, int r, int op)
{
push_down(root);
if (t[root].l == l && t[root].r == r)
{
return t[root].sum[op];
}
int mid = (t[root].l + t[root].r) >> 1;
int ch = root << 1;
if (r <= mid)return sum(ch, l, r, op);
else if (l > mid)return sum(ch + 1, l, r, op);
else return sum(ch, l, mid, op) + sum(ch + 1, mid + 1, r, op);
}
};
维护三种操作:
- 将区间
- 将区间
- 查询区间
struct tnode
{
long long sum[2], lazy[2];
int l, r;
};
tnode operator + (const tnode &A, const tnode &B)
{
tnode C;
C.l = A.l;
C.r = B.r;
C.lazy[0] = 1;
C.lazy[1] = 0;
C.sum[0] = A.sum[0] + B.sum[0];
if (C.sum[0] >= mod)C.sum[0] -= mod;
C.sum[1] = A.sum[1] + B.sum[1];
if (C.sum[1] >= mod)C.sum[1] -= mod;
C.sum[1] += A.sum[0] * B.sum[0] % mod;
if (C.sum[1] >= mod)C.sum[1] -= mod;
return C;
}
struct Segment_Tree
{
tnode t[4 * MAXN];
void init_lazy(int root)
{
t[root].lazy[0] = 1;
t[root].lazy[1] = 0;
}
void union_lazy(int fa, int ch)
{
long long temp[2];
temp[0] = t[fa].lazy[0] * t[ch].lazy[0] % mod;
temp[1] = ((t[fa].lazy[0] * t[ch].lazy[1] % mod) + t[fa].lazy[1]) % mod;
t[ch].lazy[0] = temp[0];
t[ch].lazy[1] = temp[1];
}
void cal_lazy(int root)
{
long long len = (t[root].r - t[root].l + 1) % mod;
t[root].sum[1] = (len * (len - 1) / 2 % mod * t[root].lazy[1] % mod * t[root].lazy[1] % mod + t[root].lazy[0] * t[root].lazy[0] % mod * t[root].sum[1] % mod + t[root].lazy[0] * t[root].lazy[1] % mod * (len - 1) % mod * t[root].sum[0] % mod) % mod;
t[root].sum[0] = (len * t[root].lazy[1] % mod + t[root].lazy[0] * t[root].sum[0] % mod) % mod;
return;
}
void push_down(int root)
{
if (t[root].lazy[0] != 1 || t[root].lazy[1] != 0)
{
cal_lazy(root);
if (t[root].l != t[root].r)
{
int ch = root << 1;
union_lazy(root, ch);
union_lazy(root, ch + 1);
}
init_lazy(root);
}
}
void update (int root)
{
int ch = root << 1;
push_down(ch);
push_down(ch + 1);
t[root] = t[ch] + t[ch + 1];
}
void build(int root, int l, int r)
{
t[root].l = l;
t[root].r = r;
init_lazy(root);
if (l != r)
{
int mid = (l + r) >> 1;
int ch = root << 1;
build(ch, l, mid);
build(ch + 1, mid + 1, r);
update(root);
}
else
{
t[root].sum[0] = A[l] % mod;
t[root].sum[1] = 0;
}
}
void change(int root, int l, int r, long long delta, int op)
{
push_down(root);
if (l == t[root].l && r == t[root].r)
{
t[root].lazy[op] = delta % mod;
return;
}
int mid = (t[root].l + t[root].r) >> 1;
int ch = root << 1;
if (r <= mid)change(ch, l, r, delta, op);
else if (l > mid)change(ch + 1, l, r, delta, op);
else
{
change(ch, l, mid, delta, op);
change(ch + 1, mid + 1, r, delta, op);
}
update(root);
}
tnode sum(int root, int l, int r)
{
push_down(root);
if (t[root].l == l && t[root].r == r)
{
return t[root];
}
int mid = (t[root].l + t[root].r) >> 1;
int ch = root << 1;
if (r <= mid)return sum(ch, l, r);
else if (l > mid)return sum(ch + 1, l, r);
else return sum(ch, l, mid) + sum(ch + 1, mid + 1, r);
}
};
求区间最值
如果你曾经玩过俄罗斯方块足够长的时间,你可能体验过俄罗斯方块效应——即使在你停止游戏后,仍然会看到下落的方块。为了保持专注于解决问题并避免这种干扰,我们将考虑游戏的简化版本。
该游戏在一个由方形单元格组成的棋盘上进行,这些单元格排列成网格。网格的列从左到右依次编号。棋盘向右和向上是无限的。每个单元格要么是空的,要么是填充的,最初所有单元格都是空的。
给定一系列个矩形块,块一个一个地掉落到棋盘上。块的大小各不相同。大小为
的块要么是垂直的(
个单元格),要么是水平的(
个单元格)。当一个块在指定的列上掉落时,它从所有当前填充单元格的上方开始,直直下落,直到它要么到达棋盘的底部,要么落在一个已经填充的单元格上。一旦块落下,它将填充其最终的单元格。
每次块落下时,如果没有空单元格上方有填充单元格,则游戏被认为是安全的;否则,游戏被认为是不安全的,违规的块将从棋盘上移除,游戏将继续进行下一个块,仿佛它从未掉落过。
在下面的示例中,对应于第一个样本输入,一旦第二个块落下,游戏就变得不安全,因此该块被移除,后续的块保持游戏安全。
 |  |  |  |
给定块的序列及其掉落位置,你的任务是确定每个块在落下后是否使棋盘变得不安全。
//
// Created by Swan416 on 2025-03-22 19:41.
//
#include <bits/stdc++.h>
#define int long long
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
struct Node {
ll l, r;
ll max_val, min_val;
ll add;
Node *left, *right;
Node(ll l_, ll r_) : l(l_), r(r_), max_val(0), min_val(0), add(0), left(nullptr), right(nullptr) {}
};
class SegmentTree {
public:
Node *root;
void push_down(Node *node) {
if (node->l < node->r) {
ll mid = node->l + (node->r - node->l) / 2;
if (!node->left) {
node->left = new Node(node->l, mid);
}
if (!node->right) {
node->right = new Node(mid + 1, node->r);
}
if (node->add != 0) {
node->left->max_val += node->add;
node->left->min_val += node->add;
node->left->add += node->add;
node->right->max_val += node->add;
node->right->min_val += node->add;
node->right->add += node->add;
node->add = 0;
}
}
}
void range_add(Node *node, ll L, ll R, ll delta)
{
if (node->r < L || node->l > R) return;
if (L <= node->l && node->r <= R) {
node->max_val += delta;
node->min_val += delta;
node->add += delta;
return;
}
push_down(node);
range_add(node->left, L, R, delta);
range_add(node->right, L, R, delta);
node->max_val = max(node->left->max_val, node->right->max_val);
node->min_val = min(node->left->min_val, node->right->min_val);
}
pair<ll, ll> query_max_min(Node *node, ll L, ll R) // 所查区间左闭右闭
{
if (node->r < L || node->l > R) {
return {LLONG_MIN, LLONG_MAX};
}
if (L <= node->l && node->r <= R) {
return {node->max_val, node->min_val};
}
push_down(node);
auto left_res = query_max_min(node->left, L, R);
auto right_res = query_max_min(node->right, L, R);
ll current_max = max(left_res.first, right_res.first);
ll current_min = min(left_res.second, right_res.second);
return {current_max, current_min};
}
SegmentTree() {
root = new Node(0, 2e18);
}
};
void solve()
{
int n;
cin>>n;
vector<tuple<ll,ll,ll>> all;
// 分别是要左边界右边界和高度
for(int i=0;i<n;i++)
{
char c;
int x,y;
cin>>c>>x>>y;
if(c=='|')
{
all.push_back({y,y,x});
}
else
{
all.push_back({y,y+x-1,1});
}
}
// 存所有端点方便离散化
vector<ll> all_x;
for(auto [l,r,h]:all)
{
all_x.push_back(l);
all_x.push_back(r);
}
all_x.push_back(0);
all_x.push_back(2e18);
sort(all_x.begin(),all_x.end());
// ------------------------------------------杰杰酱大人太强了-------------------------------- //
vector<int> all_x_jjj;
int idx_n=all_x.size();
for(int i=0;i<idx_n;i++)
{
if(i>0 and all_x[i]-all_x_jjj.back()>1)
all_x_jjj.push_back(all_x_jjj.back()+1);
all_x_jjj.push_back(all_x[i]);
}
all_x=all_x_jjj;
// -----------------------------------------离散化WA了就加这个------------------------------- //
all_x.erase(unique(all_x.begin(),all_x.end()),all_x.end());
map<ll,ll> x_to_id;
for(int i=0;i<all_x.size();i++)
{
x_to_id[all_x[i]]=i;
}
// 直接把input里面的l,r改掉得了
for(auto &[l,r,h]:all)
{
l=x_to_id[l];
r=x_to_id[r];
}
// 线段树准备操作
string ans="";
SegmentTree seg;
for(auto [l,r,h]:all)
{
// 首先l到r必须得是平着的也就是区间内最大值要等于最小值,否则就给ans加一个‘U’直接continue
auto [max_val,min_val]=seg.query_max_min(seg.root,l,r);
if(max_val!=min_val)
{
ans+='U';
continue;
}
// 区间内全部加h,然后给ans加一个‘S’
seg.range_add(seg.root,l,r,h);
ans+='S';
}
cout<<ans<<endl;
}
signed main()
{
int T=1;
//scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
求区间和
#include <bits/stdc++.h>
#define all(a) a.begin(),a.end()
#define lowbit(x) ((x)&(-x))
#define lc p<<1
#define rc p<<1|1
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
inline ll read()
{
ll sum=0,fl=1;
int ch=getchar();
for(;!isdigit(ch);ch=getchar())
if(ch=='-')
fl=-1;
for(;isdigit(ch);ch=getchar())
sum=sum*10+ch-'0';
return fl*sum;
}
inline void write(ll x)
{
if(x<0)
{
putchar('-');
x=-x;
}
static int sta[35];
int top=0;
do{
sta[top++]=x%10,x/=10;
}while(x);
while(top) putchar(sta[--top]+48);
putchar('\n');
}
const int N=3e5+10;
struct node{
ll l,r,sum,add;
}tr[N<<2];
void pushup(ll p)
{
tr[p].sum=tr[lc].sum+tr[rc].sum;
}
void pushdown(ll p)
{
if(tr[p].add){
tr[lc].sum+=tr[p].add*(tr[lc].r-tr[lc].l+1);
tr[rc].sum+=tr[p].add*(tr[rc].r-tr[rc].l+1);
tr[lc].add+=tr[p].add;
tr[rc].add+=tr[p].add;
tr[p].add=0;
}
}
void build(ll p,ll l,ll r)
{
tr[p].l=l;
tr[p].r=r;
if(l==r)
{
tr[p].sum=0;
return ;
}
ll mid=(l+r)>>1;
build(lc,l,mid);
build(rc,mid+1,r);
pushup(p);
}
void update(ll p,ll l,ll r,ll k)
{
if(tr[p].l>=l and tr[p].r<=r)
{
tr[p].sum+=k*(tr[p].r-tr[p].l+1);
tr[p].add+=k;
return ;
}
pushdown(p);
ll mid=(tr[p].l+tr[p].r)>>1;
if(l<=mid) update(lc,l,r,k);
if(r>mid) update(rc,l,r,k);
pushup(p);
}
ll query(ll p,ll l,ll r)
{
if(tr[p].l>=l and tr[p].r<=r)
return tr[p].sum;
pushdown(p);
ll mid=(tr[p].l+tr[p].r)>>1;
ll res=0;
if(l<=mid) res+=query(lc,l,r);
if(r>mid) res+=query(rc,l,r);
return res;
}
void solve()
{
int n=read();
//memset(tr,0,sizeof(tr));
for(int i=0;i<=n;i++) tr[i]={0,0,0,0};
build(1,0,n+1);
for(int i=1;i<=n;i++)
{
int x=read();
if(i-x>0) {
//printf("l");
update(1,i-x,i-x,1);
update(1,i,i,1);
}
if(i+x<=n) {
//printf("r");
update(1,i+x,i+x,1);
update(1,i,i,1);
}
//printf("\n");
}
int ans=0;
for(int i=1;i<=n;i++)
{
//write(query(1,i,i));
if(query(1,i,i)==0)
{
ans++;
}
}
if(ans==n) ans--;
write(ans);
}
int main()
{
int T=1;
T=read();
while(T--) solve();
return 0;
}
区间异或+求和查询
CF242E
你得到了一个序列 ,其中包含
个元素
。
你需要执行
个操作,分为两种:
1 l r:求的和。
2 l r x:将
假设这个序列为 。
第一次所有的数和 0 异或:;
第二次所有的数和 1 异或:;
第三次所有的数和 1 异或:。
发现了什么?
- 如果和 0 异或,那么 1 的个数不变;
- 如果和 1 异或,相当于将区间取反,那么 1 的个数为原来 0 的个数,即 1 的个数为
。
于是,可以将每个数转成二进制,然后定义线段树中 为在区间
中第
进制位为 1 的个数。
如果要与 异或,那么将
拆成二进制,如果第
进制位为 1 那么
;如果为 0 则不变。(和之前发现的规律相类似)
如果要求和,那么就是每个 的个数乘以
求和即可。
#include <cstdio>
#include <algorithm>
using namespace std;
int read(){
char ch=getchar();int num=0;
while(ch<'0'||ch>'9')ch=getchar();
while('0'<=ch&&ch<='9'){num=num*10+ch-'0';ch=getchar();}
return num;
}
const int MAXN=1e5+2;
int N,M,a[MAXN];
int cnt[MAXN<<2][20],tag[MAXN<<2];
#define ls(i) i<<1
#define rs(i) (i<<1)|1
void up(int cur){
for(int i=0;i<20;i++)
cnt[cur][i]=cnt[ls(cur)][i]+cnt[rs(cur)][i];
}
void buildTree(int L,int R,int cur){
if(L==R){
for(int i=0;i<20;i++)
if((a[L]>>i)&1)cnt[cur][i]=1;
return;
}
int mid=(L+R)>>1;
buildTree(L,mid,ls(cur));
buildTree(mid+1,R,rs(cur));
up(cur);
}
void down(int L,int R,int cur){
int mid=(L+R)>>1;
for(int i=0;i<20;i++)
if((tag[cur]>>i)&1){//区间取反
cnt[ls(cur)][i]=(mid-L+1)-cnt[ls(cur)][i];
cnt[rs(cur)][i]=(R-mid)-cnt[rs(cur)][i];
}
tag[ls(cur)]^=tag[cur];
tag[rs(cur)]^=tag[cur];
tag[cur]=0;
}
void update(int L,int R,int cur,int l,int r,int val){
if(R<l||r<L)return;
if(l<=L && R<=r){
for(int i=0;i<20;i++)//区间取反
if((val>>i)&1)cnt[cur][i]=(R-L+1)-cnt[cur][i];
tag[cur]^=val;
return;
}
int mid=(L+R)>>1;
down(L,R,cur);//下传标记
update(L,mid,ls(cur),l,r,val);
update(mid+1,R,rs(cur),l,r,val);
up(cur);
}
long long query(int L,int R,int cur,int l,int r){
if(R<l||r<L)return 0;
if(l<=L && R<=r){
long long ret=0,Pow=1;
for(int i=0;i<20;i++){//求和
ret+=Pow*cnt[cur][i];
Pow<<=1;
}
return ret;
}
int mid=(L+R)>>1;
down(L,R,cur);
return query(L,mid,ls(cur),l,r)+query(mid+1,R,rs(cur),l,r);
}
int main(){
N=read();
for(int i=1;i<=N;i++)a[i]=read();
buildTree(1,N,1);
M=read();
for(int i=1,opt,L,R;i<=M;i++){
opt=read();L=read();R=read();
if(opt==1)printf("%lld\n",query(1,N,1,L,R));
else update(1,N,1,L,R,read());
}
return 0;
}
线段树上二分
模板题 洛谷U502676
给出一段长度为 的数列
与
个询问, 每组询问给出
,
,
, 询问在
中第一个大于
的数的位置 (下标). 如果不存在, 输出
,
int n, m, a[N];
struct node {
int l, r;
int mx;
}tr[N * 4];
void pushup(int u) {
tr[u].mx = max(tr[u << 1].mx, tr[u << 1 | 1].mx);
}
void build(int u, int l, int r) {
tr[u] = {l, r};
if(l == r) {
tr[u].mx = a[l];
return;
}
int mid = l + r >> 1;
build(u << 1, l, mid), build(u << 1 | 1, mid + 1, r);
pushup(u);
}
int query(int u, int l, int r, int k) {
if(tr[u].mx <= k) return -1;
if(tr[u].l >= l && tr[u].r <= r) {
if(tr[u].l == tr[u].r) return tr[u].l;
if(tr[u << 1].mx > k) return query(u << 1, l, r, k);
else return query(u << 1 | 1, l, r, k);
}
int mid = tr[u].l + tr[u].r >> 1, res = -1;
if(l <= mid) res = query(u << 1, l, r, k);
if(r > mid && res == -1) res = query(u << 1 | 1, l, r, k);
return res;
}
void solve()
{
cin >> n >> m;
for(int i = 1; i <= n; i++)
cin >> a[i];
build(1, 1, n);
while(m --) {
int l, r, k;
cin >> l >> r >> k;
cout << query(1, l, r, k) << '\n';
}
}
区间乘法/加法 求区间和
#include<bits/stdc++.h>
using namespace std;
const long long N = 2e5 + 20;
long long a[N];
const long long inf = 0x3f;
const long long Ninf = 0xc0;
const long long mod = 1e9 + 7;
const long long mol = 998244353;
typedef pair<long long, long long> pll;
#define lc u<<1
#define rc u<<1|1
long long n, q, p, w[N];//p是模,w[i]表示第i个点的权值
struct Tree
{
long long l, r, sum, mul, add;//sum表示区间和,mul表示区间乘懒标记,add表示区间加懒标记
} tr[N << 2];
void pushup(long long u)
{
tr[u].sum = (tr[lc].sum + tr[rc].sum) % p;
}
void build(long long u, long long l, long long r)
{
tr[u] = {l, r, w[r], 1, 0};
if (l == r)
return;
long long mid = (l + r) >> 1;
build(lc, l, mid);
build(rc, mid + 1, r);
pushup(u);
}
void calc(Tree &t, long long m = 1, long long a = 0)
{//mul懒标记乘m,add懒标记加a
t.sum = (t.sum * m + a * (t.r - t.l + 1)) % p;
t.mul = (t.mul * m) % p;
t.add = (t.add * m + a) % p;
}
void pushdown(long long u)
{//下传懒标记
calc(tr[lc], tr[u].mul, tr[u].add);
calc(tr[rc], tr[u].mul, tr[u].add);
tr[u].mul = 1, tr[u].add = 0;//清空懒标记
}
void change(long long u, long long l, long long r, long long m = 1, long long a = 0)
{//区间乘m, 区间加a
if (tr[u].l >= l && tr[u].r <= r)
{
calc(tr[u], m, a);
return;
}
pushdown(u);
long long mid = (tr[u].l + tr[u].r) >> 1;
if (l <= mid)
change(lc, l, r, m, a);
if (r > mid)
change(rc, l, r, m, a);
pushup(u);
}
long long query(long long u, long long l, long long r)
{//区间求和
if (tr[u].l >= l && tr[u].r <= r)
return tr[u].sum;
pushdown(u);
long long mid = (tr[u].l + tr[u].r) >> 1;
long long res = 0;
if (l <= mid)
res = (res + query(lc, l, r)) % p;
if (r > mid)
res = (res + query(rc, l, r)) % p;
return res;
}
void solve()
{
cin >> n >> q >> p;
for (long long i = 1; i <= n; i++)
cin >> w[i];
build(1, 1, n);
while (q--)
{
long long op, l, r, k;
cin >> op >> l >> r;
if (op == 1)
{
cin >> k;
change(1, l, r, k, 0);
}
else if (op == 2)
{
cin >> k;
change(1, l, r, 1, k);
}
else
{
cout << query(1, l, r) << "\n";
}
}
}
int main()
{
ios::sync_with_stdio(false);
cin.tie(0);
long long t = 1;
//cin>>t;
while (t--)
solve();
return 0;
}
二维线段树
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define pii pair<int, int>
#define all(x) (x).begin(), (x).end()
// #define endl '\n'
// #define endl " line in : " << __LINE__ << endl
ostream& operator << (ostream &out, const pii &p) {
return out << '{' << p.first << ',' << p.second << '}';
}
const int N = 2e5 + 5, INF = 1e17, P = 998244353;
#define lc (x << 1)
#define rc (x << 1 | 1)
struct SegmentTree {
int n;
vector<int> sum, laz;
void init(int n) {
assert(n >= 1);
this->n = n;
sum.assign(n * 4 + 5, 0);
laz.assign(n * 4 + 5, 0);
}
void modify(int x, int l, int r, int L, int R, int V) {
if (L <= l && r <= R) {
laz[x] = laz[x] + V;
return;
}
int mid = (l + r) >> 1;
if (L <= mid) modify(lc, l, mid, L, R, V);
if (R > mid) modify(rc, mid + 1, r, L, R, V);
sum[x] += V * (min(r, R) - max(l, L) + 1);
}
void modify(int L, int R, int V) {
assert(1 <= L && L <= R && R <= n);
modify(1, 1, n, L, R, V);
}
int query(int x, int l, int r, int L, int R) {
int res = laz[x] * (min(r, R) - max(l, L) + 1);
if (L <= l && r <= R)
return res + sum[x];
int mid = (l + r) >> 1;
if (L <= mid) res = res + query(lc, l, mid, L, R);
if (R > mid) res = res + query(rc, mid + 1, r, L, R);
return res;
}
int query(int L, int R) {
assert(1 <= L && L <= R && R <= n);
return query(1, 1, n, L, R);
}
};
struct SegmentTree2 {
int n, m;
// vector<int> sum, laz;
vector<SegmentTree> sum, laz;
void init(int n, int m) {
this->n = n, this->m = m;
sum.assign(n * 4 + 5, {});
laz.assign(n * 4 + 5, {});
for (int i = 0; i < n * 4 + 5; i++)
sum[i].init(m), laz[i].init(m);
}
void modify(int x, int l, int r, int L, int R, int U, int D, int V) {
if (L <= l && r <= R) {
// laz[x] = laz[x] + V;
laz[x].modify(U, D, V);
return;
}
int mid = (l + r) >> 1;
if (L <= mid) modify(lc, l, mid, L, R, U, D, V);
if (R > mid) modify(rc, mid + 1, r, L, R, U, D, V);
// sum[x] += V * (min(r, R) - max(l, L) + 1);
sum[x].modify(U, D, V * (min(r, R) - max(l, L) + 1));
}
void modify(int L, int R, int U, int D, int V) {
assert(1 <= L && L <= R && R <= n && 1 <= U && U <= D && D <= m);
modify(1, 1, n, L, R, U, D, V);
}
int query(int x, int l, int r, int L, int R, int U, int D) {
// int res = laz[x] * (min(r, R) - max(l, L) + 1);
int res = laz[x].query(U, D) * (min(r, R) - max(l, L) + 1);
if (L <= l && r <= R)
return res + sum[x].query(U, D);
int mid = (l + r) >> 1;
if (L <= mid) res = res + query(lc, l, mid, L, R, U, D);
if (R > mid) res = res + query(rc, mid + 1, r, L, R, U, D);
return res;
}
int query(int L, int R, int U, int D) {
assert(1 <= L && L <= R && R <= n && 1 <= U && U <= D && D <= m);
return query(1, 1, n, L, R, U, D);
}
};
#undef lc
#undef rc
int n, m, q;
SegmentTree2 tree;
void test() {
cin >> n >> m;
tree.init(n, m);
// for (int i = 1; i <= n; i++)
// for (int j = 1; j <= n; j++) {
// int t; cin >> t;
// tree.modify(i, i, j, j, t);
// }
int op, x1, y1, x2, y2, z;
// cin >> q;
while (cin >> op) {
if (op == 1) {
cin >> x1 >> y1 >> x2 >> y2 >> z;
tree.modify(x1, x2, y1, y2, z);
}
else {
cin >> x1 >> y1 >> x2 >> y2;
cout << tree.query(x1, x2, y1, y2) << endl;
}
}
}
signed main() {
ios::sync_with_stdio(0);
cin.tie(0);
// int T; cin >> T; while (T--)
test();
return 0;
}
主席树(可持久化线段树)
题目描述
如题,你需要维护这样的一个长度为 的数组,支持如下几种操作
-
在某个历史版本上修改某一个位置上的值
-
访问某个历史版本上的某一位置的值
此外,每进行一次操作(对于操作2,即为生成一个完全一样的版本,不作任何改动),就会生成一个新的版本。版本编号即为当前操作的编号(从1开始编号,版本0表示初始状态数组)
输入格式
输入的第一行包含两个正整数 , 分别表示数组的长度和操作的个数。
第二行包含个整数,依次为初始状态下数组各位的值(依次为
,
)。
接下来行每行包含3或4个整数,代表两种操作之一(
为基于的历史版本号):
-
对于操作1,格式为
,即为在版本
的基础上,将
修改为
。
-
对于操作2,格式为
,即访问版本
#include<cstdio>
int n,m,rt[1000010],cnt;//cnt记录版本的序号
struct tree{
int ls,rs,value;
}t[21000010];
inline void read(int &x,char ch=getchar(),bool f=0)
{
for(x=0;ch>'9'||ch<'0';f=ch=='-',ch=getchar());
for(;ch>='0'&&ch<='9';x=(x<<3)+(x<<1)+(ch^48),ch=getchar());
(f)&&(x=-x);
}
void build(int &point,int l,int r)
{
point=++cnt;
if(l==r)
{
read(t[point].value);
return;
}
int mid=(l+r)>>1;
build(t[point].ls,l,mid);
build(t[point].rs,mid+1,r);
}
void change(int &point,int last,int l,int r,int pos,int value)
{
point=++cnt,t[point]=t[last];
if(l==r)
{
t[point].value=value;
return;
}
int mid=(l+r)>>1;
if(pos<=mid)change(t[point].ls,t[last].ls,l,mid,pos,value);
else change(t[point].rs,t[last].rs,mid+1,r,pos,value);
}
int que(int point,int l,int r,int loc)
{
if(l==r)return t[point].value;
int mid=(l+r)>>1;
if(loc<=mid)return que(t[point].ls,l,mid,loc);
else return que(t[point].rs,mid+1,r,loc);
}
int main()
{
read(n),read(m);
build(rt[0],1,n);
for(int i=1,last,flag,x,y,loc;i<=m;i++)
{
read(last),read(flag);
if(flag==1)
{
read(x),read(y);
change(rt[i],rt[last],1,n,x,y);
}
else
{
read(loc);
printf("%d\n",que(rt[last],1,n,loc));
rt[i]=rt[last];//注意新建的版本序号
}
}
}
evil封装
//N = 4 * maxn + 2 * log2(maxn)
struct Persistent_Segment_Tree
{
int lch[N], rch[N], tot; // 左孩子和右孩子数组,tot表示节点的数量
int sum[N], lazy[N]; // sum数组用于存储节点的和,lazy数组用于存储懒惰标记
void init()
{
tot = 0; // 初始化节点数量为0
}
inline void cpy(int from, int to)
{
lch[to] = lch[from]; // 复制左孩子
rch[to] = rch[from]; // 复制右孩子
sum[to] = sum[from]; // 复制和
lazy[to] = lazy[from]; // 复制懒惰标记
}
void build(int &root, int l, int r)
{
root = ++ tot; // 新建一个节点,节点数量加1
lazy[root] = 0; // 初始化懒惰标记为0
if(l == r)
{
sum[root] = 0; // 叶节点的和为0
return;
}
int mid = (l + r) >> 1; // 计算中点
build(lch[root], l, mid); // 递归构建左子树
build(rch[root], mid + 1, r); // 递归构建右子树
sum[root] = sum[lch[root]] + sum[rch[root]]; // 计算当前节点的和
}
void change(int &root, int old, int L, int R, int l, int r, long long v)
{
root = ++ tot; // 新建一个节点,节点数量加1
cpy(old, root); // 复制旧节点的信息到新节点
sum[root] += v * (r - l + 1); // 更新当前节点的和
if(l == L && r == R)
{
lazy[root] += v; // 更新当前节点的懒惰标记
return;
}
int mid = (L + R) >> 1; // 计算中点
if(r <= mid) change(lch[root], lch[root], L, mid, l, r, v); // 更新左子树
else if(l > mid) change(rch[root], rch[root], mid + 1, R, l, r, v); // 更新右子树
else
{
change(lch[root], lch[root], L, mid, l, mid, v); // 更新左子树的一部分
change(rch[root], rch[root], mid + 1, R, mid + 1, r, v); // 更新右子树的一部分
}
return;
}
int qsum(int root, int L, int R, int l, int r)
{
if(l == L && r == R)
{
return sum[root]; // 返回当前节点的和
}
int ans = lazy[root] * (r - l + 1); // 计算当前节点的懒惰标记对应的值
int mid = (L + R) >> 1; // 计算中点
if(r <= mid) return ans + qsum(lch[root], L, mid, l, r); // 查询左子树
else if(l > mid) return ans + qsum(rch[root], mid + 1, R, l, r); // 查询右子树
else return ans + qsum(lch[root], L, mid, l , mid) + qsum(rch[root], mid + 1, R, mid + 1, r); // 查询左右子树的一部分
}
int q(int s, int t, int L, int R, int k)
{
if(L == R)
{
return L; // 返回叶节点的值
}
int mid = (L + R) >> 1; // 计算中点
if(k <= sum[lch[t]] - sum[lch[s]]) // 如果k小于等于左子树的和
{
return q(lch[s], lch[t], L, mid, k); // 在左子树中查询
}
else
{
return q(rch[s], rch[t], mid + 1, R, k - (sum[lch[t]] - sum[lch[s]])); // 在右子树中查询
}
}
};
struct discretization_node
{
int num;
int ki;
} disc[MAXN];
// 比较函数,用于排序
bool cmp(discretization_node x, discretization_node y)
{
return x.num < y.num;
}
// 离散化函数
void discretization(int a[], int inv[], int n, discretization_node disc[])
{
// 初始化离散化节点数组
for (int i = 1; i <= n; i++)
{
disc[i].num = a[i];
disc[i].ki = i;
}
// 对离散化节点数组进行排序
sort(disc + 1, disc + 1 + n, cmp);
int cnt = 0, per;
// 进行离散化
for (int i = 1; i <= n; i++)
{
// 如果当前数字与前一个数字不相同,则计数器加一
if (i == 1 || a[disc[i].ki] != per)
++cnt;
per = a[disc[i].ki];
a[disc[i].ki] = cnt;
inv[cnt] = disc[i].num;
}
return;
}
Persistent_Segment_Tree seg;
int root[MAXN], T, n, m, l, r, t, k;
int a[MAXN], b[MAXN], v;
int main()
{
while (scanf("%d %d", &n, &m) != EOF)
{
T = 0;
// 读取输入数组 a
for (int i = 1; i <= n; i++)
{
scanf("%d", &a[i]);
}
// 进行离散化
discretization(a, b, n, disc);
// 初始化持久化线段树
seg.init();
// 构建初始线段树
seg.build(root[T], 1, n);
// 逐个插入元素并构建持久化线段树
for (int i = 1; i <= n; i++)
{
T++;
seg.change(root[T], root[T - 1], 1, n, a[i], a[i], 1);
}
// 处理查询操作
for (int i = 1; i <= m; i++)
{
scanf("%d %d %d", &l, &r, &k);
// 在持久化线段树上查询第 k 小的元素,并输出对应的离散化前的值
printf("%d\n", b[seg.q(root[l - 1], root[r], 1, n, k)]);
}
}
}
李超树
要求在平面直角坐标系下维护两个操作:
- 在平面上加入一条线段。记第
条被插入的线段的标号为
- 给定一个数
,询问与直线
相交的线段中,交点纵坐标最大的线段的编号。
例:高速公路升级
NowLand 的高速公路系统已使用数十年,需升级。该国拥有 个城市和
条单向高速公路,车辆走第
条高速,可在
分钟从城市
到
,升级该高速能减少用时
分钟,且可多次升级。 总统将从首都城市
出发前往城市
,仅用高速公路,想通过升级高速(最多
次)缩短行程时间。需对不同升级次数
,计算城市
到
的最短时间。
#include<bits/stdc++.h>
using i64 = long long;
using u64 = unsigned long long;
using i128 = __int128;
#define int i128
#define i64 i128
std::istream& operator>>(std::istream& is, i128& n) {
std::string s;
is >> s;
n = 0;
for (char c : s) {
n = n * 10 + (c - '0');
}
return is;
}
std::ostream& operator<<(std::ostream& os, i128 n) {
if (n == 0) {
return os << 0;
}
std::string s = "";
while (n) {
s += '0' + (n % 10);
n /= 10;
}
std::reverse(s.begin(), s.end());
return os << s;
}
struct LiChao {
static constexpr i64 inf = 5E19;
struct Line {
i64 k;
i64 b;
Line(i64 k = 0, i64 b = -inf): k{k}, b{b} {}
i64 eval(i64 x) {
// std::cout << k * x + b << ' ' << k << ' ' << x << ' ' << b << '\n';
return k * x + b;
}
};
struct Node {
Line line;
Node* lsh;
Node* rsh;
Node(): line{}, lsh{nullptr}, rsh{nullptr} {}
Node(Line l): line{l}, lsh{nullptr}, rsh{nullptr} {}
};
Node* root;
static constexpr int xL = 0;
static constexpr int xR = 2E9;
LiChao(): root{nullptr} {}
void add_line(Node*& t, int l, int r, Line line) {
if (t == nullptr) {
t = new Node(line);
return ;
}
int mid = (l + r) >> 1;
int bm = (line.eval(mid) > t->line.eval(mid));
if (bm == 1) {
std::swap(line, t->line);
}
int bl = (line.eval(l) > t->line.eval(l)), br = (line.eval(r) > t->line.eval(r));
if (bl == 1) add_line(t->lsh, l, mid, line);
if (br == 1) add_line(t->rsh, mid + 1, r, line);
}
void add_line(Line l) {
add_line(root, xL, xR, l);
}
i64 query(Node*& t, int l, int r, int v) {
if (t == nullptr) {
return -inf;
}
i64 res = t->line.eval(v);
if (l == r) {
return res;
}
int mid = (l + r) >> 1;
if (v <= mid) {
res = std::max(res, query(t->lsh, l, mid, v));
} else {
res = std::max(res, query(t->rsh, mid + 1, r, v));
}
return res;
}
i64 query(int v) {
return query(root, xL, xR, v);
}
};
void solve () {
int n, m;
std::cin >> n >> m;
std::vector<std::vector<std::pair<int, int>>>adj(n + 1);
std::vector<std::vector<std::pair<int, int>>>adj1(n + 1);
std::vector<std::array<int, 4>>edges(m);
for (auto& [u, v, t, w] : edges) {
std::cin >> u >> v >> t >> w;
adj[u].push_back({v, t});
adj1[v].push_back({u,t});
}
auto dijkstra = [&](int s,int x) {
std::vector<i64>d(n + 1, -1);
std::priority_queue<std::pair<i64, int>, std::vector<std::pair<i64, int>>, std::greater<>>pq;
d[s] = 0;
pq.push({0, s});
while (!pq.empty()) {
auto [h, u] = pq.top();
pq.pop();
if (h != d[u]) {
continue;
}
if(x==0)
{
for (auto [v, t] : adj[u]) {
if (d[v] == -1 || d[v] > h + t) {
d[v] = h + t;
pq.push({d[v], v});
}
}
}
else
{
for (auto [v, t] : adj1[u]) {
if (d[v] == -1 || d[v] > h + t) {
d[v] = h + t;
pq.push({d[v], v});
}
}
}
}
return d;
};
LiChao lc;
auto d1 = dijkstra(1,0), dn = dijkstra(n,1);
for (auto [u, v, t, w] : edges) {
/*if(u==1&&v==3)
{
std::cout<<u<<" "<<v<<" "<<t<<" "<<w<<"\n";
}*/
if (d1[u] != -1 && dn[v] != -1) {
i64 cost = d1[u] + dn[v] + t;
lc.add_line(LiChao::Line(w, -cost));
}
}
int q;
std::cin >> q;
while (q--) {
int k;
std::cin >> k;
i64 ans = -lc.query(k);
assert(ans > 0);
assert(lc.root != nullptr);
std::cout << ans << '\n';
}
}
auto main() ->int32_t {
std::ios::sync_with_stdio(false);
std::cin.tie(nullptr);
int t = 1;
std::cin >> t;
while (t--) {
solve();
}
return 0;
}
吉司机线段树
题意
给出一个长度为 的数组
, 接下来有
次操作, 操作有如下三种:
- 给出
,
,
, 把
变成
- 给出
- 给出
数据范围:
样例输入
1
5 5
1 2 3 4 5
1 1 5
2 1 5
0 3 5 3
1 1 5
2 1 5
样例输出
5
15
3
12
因为在给一个节点打上区间取 标记的时候, 我们无法快速更新区间和, 所以这一个问题是无法通过传统的懒标记来解决的.
考虑对线段树中的每一个节点除了维护区间和 以外, 还要额外维护区间中的最大值
、严格次大值
以及最大值个数
.
现在假设我们要让区间 对
取
, 我们先在线段树中定位这个区间, 对定位的每一个节点, 我们开始暴力搜索. 搜索到每一个节点时, 我们分三种情况讨论:
- 当
时, 显然这一次修改不会对这个节点产生影响, 直接退出.
- 当
时, 显然这一次修改只会影响到所有最大值, 所以我们把
加上
, 把
更新为
- 当
时, 我们无法直接更新这一个节点的信息, 因此在这时, 我们对当前节点的左儿子和右儿子进行递归搜索.
通过势能分析, 可以证明这个算法的复杂度是 的
const int N = 1000010;
int a[N];
struct Segment_Tree_Beats {
struct node {
int l, r;
// 区间和, 最大值, 次大值, 最大值个数
int sum, mx, se, cnt;
};
vector<node> tr;
void pushup(int u) {
tr[u].sum = tr[u << 1].sum + tr[u << 1 | 1].sum;
tr[u].mx = max(tr[u << 1].mx, tr[u << 1 | 1].mx);
if(tr[u << 1].mx == tr[u << 1 | 1].mx) {
tr[u].cnt = tr[u << 1].cnt + tr[u << 1 | 1].cnt;
tr[u].se = max(tr[u << 1].se, tr[u << 1 | 1].se);
} else if(tr[u << 1].mx > tr[u << 1 | 1].mx) {
tr[u].cnt = tr[u << 1].cnt;
tr[u].se = max(tr[u << 1].se, tr[u << 1 | 1].mx);
} else {
tr[u].cnt = tr[u << 1 | 1].cnt;
tr[u].se = max(tr[u << 1].mx, tr[u << 1 | 1].se);
}
}
void pushdown(int u) { // 最大值即相当于懒标记
if(tr[u << 1].mx > tr[u].mx) {
tr[u << 1].sum -= (tr[u << 1].mx - tr[u].mx) * tr[u << 1].cnt;
tr[u << 1].mx = tr[u].mx;
}
if(tr[u << 1 | 1].mx > tr[u].mx) {
tr[u << 1 | 1].sum -= (tr[u << 1 | 1].mx - tr[u].mx) * tr[u << 1 | 1].cnt;
tr[u << 1 | 1].mx = tr[u].mx;
}
}
void build(int u, int l, int r) {
if(l == r) {
tr[u] = {l, r, a[l], a[l], -1, 1};
return;
}
tr[u] = {l, r};
int mid = l + r >> 1;
build(u << 1, l, mid), build(u << 1 | 1, mid + 1, r);
pushup(u);
}
Segment_Tree_Beats(int n) {
tr.resize((n + 10) * 4);
build(1, 1, n);
}
/* 修改里看似没有处理 c <= tr[u].se 的情况
但一直递归到叶子节点, 因为叶子节点自身是没有次大值的
叶子节点一定会出现 c > tr[u].se 的情况
需要注意的是: 当涉及区间 + 操作时, 叶子节点的次大值会被操作,
因此初始化时需要把叶子节点的次大值初始化为 -inf (而不是 -1)
*/
void modify(int u, int l, int r, int c) {
if(c >= tr[u].mx) return;
if(tr[u].l >= l && tr[u].r <= r && c > tr[u].se) {
tr[u].sum -= (tr[u].mx - c) * tr[u].cnt;
tr[u].mx = c;
return;
}
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
if(l <= mid) modify(u << 1, l, r, c);
if(r > mid) modify(u << 1 | 1, l, r, c);
pushup(u);
}
int query_max(int u, int l, int r) {
if(tr[u].l >= l && tr[u].r <= r)
return tr[u].mx;
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1, res = 0;
if(l <= mid) res = max(res, query_max(u << 1, l, r));
if(r > mid) res = max(res, query_max(u << 1 | 1, l, r));
return res;
}
int query_sum(int u, int l, int r) {
if(tr[u].l >= l && tr[u].r <= r)
return tr[u].sum;
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1, res = 0;
if(l <= mid) res += query_sum(u << 1, l, r);
if(r > mid) res += query_sum(u << 1 | 1, l, r);
return res;
}
};
void solve()
{
int n, m;
cin >> n >> m;
for(int i = 1; i <= n; i++)
cin >> a[i];
Segment_Tree_Beats Tr(n);
while(m --) {
int op;
cin >> op;
if(op == 0) {
int l, r, c;
cin >> l >> r >> c;
Tr.modify(1, l, r, c);
} else if(op == 1) {
int l, r;
cin >> l >> r;
cout << Tr.query_max(1, l, r) << '\n';
} else {
int l, r;
cin >> l >> r;
cout << Tr.query_sum(1, l, r) << '\n';
}
}
}
平衡树
听起来很高端,其实主要的作用就是可以快速对数组进行区间旋转的操作
普通平衡树
模版题(P6136)
您需要动态地维护一个可重集合 ,并且提供以下操作:
- 向
- 从
- 查询
- 查询如果将
- 查询
- 查询
本题强制在线,保证所有操作合法(操作 保证存在至少一个
,操作
保证存在答案)。
#include<iostream>
using namespace std;
const int N=1.1e6;
struct node{
int ch[2],fa;
int val,cnt,siz;
int&l=ch[0],&r=ch[1];
void set(int v,int c=1,int s=1){
l=r=fa=0;
val=v;
cnt=c;
siz=s;
}
}t[N+5];
int tot,root;
bool get(int);
void push_up(int);
void add(int,int,bool);
void del(int);
void rotate(int);
int splay(int,int=0);
int push(int);
void pop(int);
int val_find(int);
int rank_find(int,int);
int find_rank(int);
int bound(int,bool);
int pre(int);
int nxt(int);
int main(){
int n,m;
cin>>n>>m;
push(2147483647);
push(-2147483648);
for(int i=1,x;i<=n;i++) cin>>x,push(x);
int ans=0,lst=0;
while(m--){
int op,x;
cin>>op>>x;
x^=lst;
if(op==1) push(x);
if(op==2) pop(x);
if(op==3) ans^=lst=find_rank(x)-1;
if(op==4) ans^=lst=t[rank_find(root,x+1)].val;
if(op==5) ans^=lst=t[splay(pre(x))].val;
if(op==6) ans^=lst=t[splay(nxt(x))].val;
// if(op==1) push(x);
// if(op==2) pop(x);
// if(op==3) cout<<find_rank(x)-1<<endl;
// if(op==4) cout<<t[rank_find(root,x+1)].val<<endl;
// if(op==5) cout<<t[splay(pre(x))].val<<endl;
// if(op==6) cout<<t[splay(nxt(x))].val<<endl;
}
cout<<ans;
}
bool get(int u){
return t[t[u].fa].r==u;
}
void push_up(int u){
t[u].siz=t[t[u].l].siz+t[t[u].r].siz+t[u].cnt;
}
void add(int fa,int u,bool k){
t[t[u].fa=fa].ch[k]=u;
}
void del(int u){
t[t[u].l].fa=t[t[u].r].fa=t[t[u].fa].ch[get(u)]=0;
t[u].set(0,0,0);
}
void rotate(int u){
int k=get(u),fa=t[u].fa,ffa=t[fa].fa,son=t[u].ch[k^1];
add(ffa,u,get(fa));
add(u,fa,k^1);
add(fa,son,k);
push_up(fa);
push_up(u);
}
int splay(int u,int v){
for(int fa;(fa=t[u].fa)^v;rotate(u))
if(t[fa].fa^v)
rotate(get(fa)==get(u)?fa:u);
!v&&(root=u);
return u;
}
int push(int val){
if(!root){
t[++tot].set(val);
return root=tot;
}
int x=val_find(val);
if(t[x].val==val){
t[x].cnt++;
push_up(x);
return x;
}
t[++tot].set(val);
add(x,tot,t[x].val<val);
return splay(tot);
}
void pop(int val){
int u=val_find(val);
if(t[u].cnt>1) t[u].cnt--;
else {
int Pre=pre(val),Nxt=nxt(val);
splay(Pre);
splay(Nxt,Pre);
del(u);
splay(Nxt);
}
push_up(root);
}
int val_find(int val){
int u=root,fa;
while(u)
if(t[fa=u].val==val)
return splay(u);
else
u=t[u].ch[t[u].val<val];
return fa;
}
int rank_find(int u,int rank){
int l=t[t[u].l].siz;
if(rank<=l) return rank_find(t[u].l,rank);
if(l+t[u].cnt<rank) return rank_find(t[u].r,rank-t[u].cnt-l);
return splay(u);
}
int find_rank(int val){
int ans=t[t[push(val)].l].siz+1;
pop(val);
return ans;
}
int bound(int val,bool k){
int u=t[push(val)].ch[k];
while(t[u].ch[k^1])
u=t[u].ch[k^1];
pop(val);
return u;
}
int pre(int val){
return bound(val,0);
}
int nxt(int val){
return bound(val,1);
}
文艺平衡树
模板题(P3391)
您需要写一种数据结构(可参考题目标题),来维护一个有序数列。
其中需要提供以下操作:翻转一个区间,例如原有序序列是 ,翻转区间是
的话,结果是
。
#include<iostream>
using namespace std;
#define MAXN 1000007
#define INF 100000089
struct Splay_tree{
int f,sub_size,cnt,value,tag;
int son[2];
}s[MAXN];
int original[MAXN],root,wz;
inline bool which(int x){
return x==s[s[x].f].son[1];
}
inline void update(int x){
if(x){
s[x].sub_size=s[x].cnt;
if(s[x].son[0])s[x].sub_size+=s[s[x].son[0]].sub_size;
if(s[x].son[1])s[x].sub_size+=s[s[x].son[1]].sub_size;
}
}
inline void pushdown(int x){
if(x&&s[x].tag){
s[s[x].son[1]].tag^=1;
s[s[x].son[0]].tag^=1;
swap(s[x].son[1],s[x].son[0]);
s[x].tag=0;
}
}
inline void rotate(int x){
int fnow=s[x].f,ffnow=s[fnow].f;
pushdown(x),pushdown(fnow);
bool w=which(x);
s[fnow].son[w]=s[x].son[w^1];
s[s[fnow].son[w]].f=fnow;
s[fnow].f=x;
s[x].f=ffnow;
s[x].son[w^1]=fnow;
if(ffnow){
s[ffnow].son[s[ffnow].son[1]==fnow]=x;
}
update(fnow);
}
inline void splay(int x,int goal){
for(int qwq;(qwq=s[x].f)!=goal;rotate(x)){
if(s[qwq].f!=goal){//这个地方特别重要,原因是需要判断的是当前的父亲有没有到目标节点,而如果把“qwq”改成“x”……就会炸
rotate(which(x)==which(qwq)?qwq:x);
}
}
if(goal==0){
root=x;
}
}
int build_tree(int l, int r, int fa) {
if(l > r) { return 0; }
int mid = (l + r) >> 1;
int now = ++ wz;
s[now].f=fa;
s[now].son[0]=s[now].son[1]=0;
s[now].cnt++;
s[now].value=original[mid];
s[now].sub_size++;
s[now].son[0] = build_tree(l, mid - 1, now);
s[now].son[1] = build_tree(mid + 1, r, now);
update(now);
return now;
}
inline int find(int x){
int now=root;
while(1)
{
pushdown(now);
if(x<=s[s[now].son[0]].sub_size){
now=s[now].son[0];
}
else {
x-=s[s[now].son[0] ].sub_size + 1;
if(!x)return now;
now=s[now].son[1];
}
}
}
inline void reverse(int x,int y){
int l=x-1,r=y+1;
l=find(l),r=find(r);
splay(l,0);
splay(r,l);
int pos=s[root].son[1];
pos=s[pos].son[0];
s[pos].tag^=1;
}
inline void dfs(int now){
pushdown(now);
if(s[now].son[0])dfs(s[now].son[0]);
if(s[now].value!=-INF&&s[now].value!=INF){
cout<<s[now].value<<" ";
}
if(s[now].son[1])dfs(s[now].son[1]);
}
int main(){
int n,m,x,y;
cin>>n>>m;
original[1]=-INF,original[n+2]=INF;
for(int i=1;i<=n;i++){
original[i+1]=i;
}
root=build_tree(1,n+2,0);//有一个良好的定义变量习惯很重要……重复定义同一个变量(比如全局的和局部的同名)那么就会发生覆盖。
for(int i=1;i<=m;i++){
cin>>x>>y;
reverse(x+1,y+1);
}
dfs(root);
}
例题/struct封装(arc153_b)
我们有一个包含 行(从上到下)和
列(从左到右)的网格。初始时,位于第
行(从上数)和第
列(从左数)的格子中有一个小写英文字母
。
我们需要对这个网格进行 次操作。在第
次操作中,会给定整数
和
,满足
且
,并执行以下步骤:
- 设
为网格中的矩形区域,定义如下:
是顶部
行和最左侧
列的交集;
是顶部
列的交集;
是底部
行和最左侧
是底部
- 将
这里的 180 度旋转是指,对于网格中的矩形区域 ,将位于第
行(从上数)和第
列(从左数)的格子中的字符移动到第
行(从下数)和第
列(从左数)的格子中,其中
是
的总行数。参见示例图。
在所有 次操作完成后,输出最终的网格。
//
// Created by Swan416 on 2025-05-22 20:37.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
const int N = 5e5 + 5, mod = 998244353, INF = 2e9;
int n, m;
struct stu {
int root, idx;
struct edge {
int s[2], val, p, sz, lazy;
void init(int _val, int _p) {
val = _val; p = _p;
sz = 1;
}
}tree[N];
void push_up(int p) {
tree[p].sz = tree[tree[p].s[0]].sz + tree[tree[p].s[1]].sz + 1;
}
void push_down(int p) {
if (tree[p].lazy) {
swap(tree[p].s[0], tree[p].s[1]);
tree[tree[p].s[0]].lazy ^= 1;
tree[tree[p].s[1]].lazy ^= 1;
tree[p].lazy = 0;
}
}
int get(int x) {
return tree[tree[x].p].s[1] == x;
}
void rotate(int x) {
int y = tree[x].p, z = tree[y].p;
int kx = get(x), ky = get(y);
tree[z].s[ky] = x, tree[x].p = z;
tree[y].s[kx] = tree[x].s[kx ^ 1]; tree[tree[x].s[kx ^ 1]].p = y;
tree[x].s[kx ^ 1] = y; tree[y].p = x;
push_up(y); push_up(x);
}
void splay(int x, int k) {
while (tree[x].p != k) {
int y = tree[x].p, z = tree[y].p;
if (z != k) {
if (get(x) ^ get(y)) rotate(x);
else rotate(y);
}
rotate(x);
}
if (!k) root = x;
}
void insert(int v) {
int u = root, p = 0;
while (u) p = u, u = tree[u].s[v > tree[u].val];
u = ++idx;
if (p) tree[p].s[v > tree[p].val] = u;
tree[u].init(v, p);
splay(u, 0);
}
int get_k(int k) {
int u = root;
while (1) {
push_down(u);
if (tree[tree[u].s[0]].sz >= k) u = tree[u].s[0];
else if (tree[tree[u].s[0]].sz + 1 == k) return u;
else {
k -= tree[tree[u].s[0]].sz + 1;
u = tree[u].s[1];
}
}
splay(u, 0);
return -1;
}
void rev(int l, int r) {
l = get_k(l), r = get_k(r + 2);
splay(l, 0); splay(r, l);
tree[tree[r].s[0]].lazy ^= 1;
}
int ID[N], tot;
void output(int u) {
push_down(u);
if (tree[u].s[0]) output(tree[u].s[0]);
if (tree[u].val >= 1 && tree[u].val <= max(n, m)) ID[++tot] = tree[u].val;
if (tree[u].s[1]) output(tree[u].s[1]);
}
}tr1, tr2;
void solve()
{
scanf("%d%d",&n,&m);
vector<string> org(n+1);
for(int i=1;i<=n;i++){
cin>>org[i];
org[i] = " " + org[i];
}
tr1.insert(-INF);
for(int i=1;i<=n;i++){
tr1.insert(i);
tr1.insert(INF);// 加上INF是为了防止在树中没有元素的情况下,直接取到根节点
}
tr2.insert(-INF);
for(int i=1;i<=m;i++){
tr2.insert(i);
tr2.insert(INF);
}
int q; scanf("%d",&q);
while(q--){
int x,y; scanf("%d%d",&x,&y);
tr1.rev(1,x); tr1.rev(x+1,n);
tr2.rev(1,y); tr2.rev(y+1,m);
}
tr1.output(tr1.root);
tr2.output(tr2.root);
for(int i=1;i<=n;i++){
for(int j=1;j<=m;j++){
printf("%c",org[tr1.ID[i]][tr2.ID[j]]);
}
printf("\n");
}
}
int main()
{
int T=1;
//scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
Splay树
- 将某个节点通过旋转直接一路提到根的操作就称"伸展"操作
- 伸展树在所有操作后, 都会执行这个
操作将它提到根
- 写起来都要写成这种
的形式, 比如说
root = insert(x) - 基于
splay, 可以写出一些关键操作, 比如说insert()find()delete()kth()lower_bound()upper_bound()merge/link()split/cut()
- 伸展树维护区间的特长
- 区间拼接
- 区间翻转
- 区间大段插入
int stot, stop, sstk[MAXN], n, root1, root2, root3, root, number[MAXN], tail;
struct tree
{
int ch[2];
int fa;
int size;
int cnt;
int num;
bool rev;
}t[MAXN];
//更新节点root的size属性,表示以root为根节点的子树的节点总数
void update(int root)
{
t[root].size = t[root].cnt + t[t[root].ch[0]].size + t[t[root].ch[1]].size;
}
//将节点root的标记向下传递,即将root的翻转标记应用到其子节点
void pushdown(int root)
{
if(t[root].rev)
{
swap(t[root].ch[0], t[root].ch[1]);
t[root].rev ^= 1;
t[t[root].ch[0]].rev ^= 1;
t[t[root].ch[1]].rev ^= 1;
}
return;
}
//将从root到根节点路径上的所有节点都进行pushdown操作,确保在对树进行操作之前,没有延迟的标记
void push_until(int root)
{
while(root)
{
sstk[++stop] = root;
root = t[root].fa;
}
while(stop)
{
pushdown(sstk[stop--]);
}
return;
}
//对节点root进行一次旋转操作,旋转操作会改变root和其父节点、祖父节点的关系,以及子节点的位置
void rot(int root)
{
int fa = t[root].fa;
int gfa = t[fa].fa;
int t1 = (root != t[fa].ch[0]);
int t2 = (fa != t[gfa].ch[0]);
int ch = t[root].ch[1^t1];
t[root].fa = gfa;
t[root].ch[1^t1] = fa;
t[fa].ch[0^t1] = ch;
t[fa].fa = root;
t[ch].fa = fa;
t[gfa].ch[0^t2] = root;
update(fa);
return;
}
//将节点root通过一系列的旋转操作,旋转到树的根节点位置,并返回旋转后的根节点
int splay(int root)
{
push_until(root);
while(t[root].fa)
{
int fa = t[root].fa, gfa = t[fa].fa;
if(gfa)
{
(t[fa].ch[0] == root) ^ (t[gfa].ch[0] == fa) ? rot(root) : rot(fa);
}
rot(root);
}
update(root);
return root;
}
//在以root为根的子树中,找到第k小的元素,并将其旋转到根节点位置,返回旋转后的根节点
int kth(int root, int k)
{
for(;;)
{
pushdown(root);
if(k <= t[t[root].ch[0]].size)
{
root = t[root].ch[0];
}
else if(k > t[t[root].ch[0]].size + t[root].cnt)
{
k -= t[t[root].ch[0]].size + t[root].cnt;
root = t[root].ch[1];
}
else
{
return splay(root);
}
}
}
//向以root为根节点的子树中插入一个值为num的节点,如果已经存在值为num的节点,则增加其计数器,返回插入/旋转后的根节点
int ins(int root, int num)
{
while(root && t[root].num != num && t[root].ch[num > t[root].num])
root = t[root].ch[num > t[root].num];
if(root && t[root].num == num)
{
t[root].cnt ++;
return splay(root);
}
t[++stot].num = num;
t[stot].cnt = t[stot].size = 1;
t[stot].rev = 0;
t[stot].fa = root;
t[stot].ch[0] = t[stot].ch[1] = 0;
t[root].ch[num > t[root].num] = stot;
root = stot;
return splay(root);
}
//将以root1和root2为根的两棵子树连接起来,并返回连接后的根节点
int links(int root1, int root2)
{
if(!root1 || !root2) return root1 | root2;
root1 = kth(root1, t[root1].size);
t[root1].ch[1] = root2;
t[root2].fa = root1;
update(root1);
return root1;
}
//将以root为根的子树切割成两个子树,k是切割的位置,root1和root2用于返回切割后的两个子树的根节点
void cuts(int root, int k, int &root1, int &root2)
{
if(k == 0)
{
root1 = 0;
root2 = root;
return;
}
root1 = kth(root, k);
root2 = t[root1].ch[1];
t[root1].ch[1] = t[root2].fa = 0;
update(root1);
return;
}
int build(int l, int r)
{
if(r < l) return 0;
int mid = (l + r) >> 1;
int new_node = ++stot;
t[new_node].num = mid;
t[new_node].cnt = 1;
t[new_node].rev = 0;
t[new_node].fa = 0;
t[new_node].ch[0] = build(l, mid - 1);
t[new_node].ch[1] = build(mid + 1, r);
t[t[new_node].ch[0]].fa = new_node;
t[t[new_node].ch[1]].fa = new_node;
update(new_node);
return new_node;
}
void dfs(int root)
{
pushdown(root);
if(t[root].ch[0])
{
dfs(t[root].ch[0]);
}
number[++tail] = t[root].num;
if(t[root].ch[1])
{
dfs(t[root].ch[1]);
}
return;
}
void init()
{
stot = 0;
root = 0;
}
int main()
{
//初始化 + 建树
init();
tail = 0;
root = build(1, n);
//将[l, r]区间翻转
scanf("%d %d", &l, &r);
cuts(root, l - 1, root1, root2);
cuts(root2, r - l + 1, root2, root3);
t[root2].rev ^= 1;
root = links(root1, root2);
root = links(root, root3);
//树的中序遍历存储在number[]数组中
dfs(root);
}
ST表
可以查询区间最值及其位置 注意数组的第二位是数据范围取log 也就是数组内的数都是1e9就取20,1e18就去30
CF1696D
排列是由从 到
的
个不同整数任意排列组成的数组。例如,
是一个排列,但
不是一个排列(
在数组中出现两次),
也不是一个排列(
但数组中有
)。
给定一个排列 ,
。对于整数
,
,使得
,定义
为
,定义
为
。
让我们构建一个有 个顶点的无向图,编号从
到
。对于每一对整数
,如果
和
都成立,或者
和
都成立,就在顶点
和
之间添加一条长度为
的无向边。
在这个图中,找到从顶点 到顶点
的最短路径长度。我们可以证明
和
总是通过某条路径相连,因此最短路径总是存在。
//
// Created by Swan416 on 2025-04-17 10:36.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
void solve()
{
int n; scanf("%d",&n);
vector<int> a(n+1);
for(int i=1;i<=n;i++) scanf("%d",&a[i]);
pii mx[n+1][20],mn[n+1][20];// st表
for(int i=1;i<=n;i++)
{
mx[i][0] = {a[i],i};
mn[i][0] = {a[i],i};
}
function <void()> init =[&]()->void{
for(int j=1;j<20;j++)
{
for(int i=1;i+(1<<j)-1<=n;i++)
{
mx[i][j] = max(mx[i][j-1],mx[i+(1<<(j-1))][j-1]);
mn[i][j] = min(mn[i][j-1],mn[i+(1<<(j-1))][j-1]);
}
}
};
function <pii(int,int)> getmx = [&](int l,int r)->pii{
int k = log2(r-l+1);
return max(mx[l][k],mx[r-(1<<k)+1][k]);
};
function <pii(int,int)> getmn = [&](int l,int r)->pii{
int k = log2(r-l+1);
return min(mn[l][k],mn[r-(1<<k)+1][k]);
};
init();
function <int(int,int)> get = [&](int l,int r)->int{
// printf("l=%d r=%d\n",l,r);
if(r==l) return 0;
int p1=getmx(l,r).second,p2=getmn(l,r).second;
if(p1>p2) swap(p1,p2);
return get(l,p1)+get(p2,r)+1;
};
int ans=get(1,n);
printf("%d\n",ans);
}
int main()
{
int T=1;
scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
逆序对个数
归并排序法
注意跑完这个逆序队个数之后原数组a会变成排序好的状态
const int N=2e5+10;
int temp[N],a[N];
long long find(int l, int r){
if(l >= r) return 0;
int mid = l + (r - l >> 1);
long long res = 0;
res += find(l, mid);
res += find(mid + 1, r);
int i = l, j = mid + 1, k = 0;
while(i <= mid && j <= r){
if(a[i] <= a[j]) temp[k++] = a[i++];
else
{
temp[k++] = a[j++];
res += mid - i + 1;
}
}
while(i <= mid) temp[k++] = a[i++];
while(j <= r) temp[k++] = a[j++];
for(i = l,k = 0;i <= r;i++)
a[i] = temp[k++];
return res;
}
树状数组法
我们要求解总逆序对个数可以分解成数组中的数一个一个放入得出当时的逆序对个数,然后相加。 也就是说,我们每加入一个数,都要得出此时数组中比这个数大的数的个数。 那么变成每加入一个数,我们令比它小的数记录一次,这样之后遇到这个数,就可以知道前面比它大的数有多少个。这时我们的树状数组就有用处了。 没错,树状数组的含义在这里就是这个数在所处数组位置之前有几个数比它大。
要特别注意的是,我们在用树状数组求解逆序对个数时,常常会遇到量值过大的情况,这个时候需要进行离散化后在进行构建树状数组。
#include <iostream>
#include <algorithm>
#include <string.h>
using namespace std;
const int MAX = 5e5 +10;
int n;
int a[MAX],b[MAX],c[MAX];
bool cmp (int x, int y)
{
return a[x] < a[y];
}
inline int Lowbit(int x)
{
return x & (-x);
}
inline void Add(int pos)
{
while(pos <= n)
{
c[pos]++;
pos += Lowbit(pos);
}
}
inline int Query(int pos)
{
long long res = 0;
while(pos > 0)
{
res += c[pos];
pos -= Lowbit(pos);
}
return res;
}
int main()
{
cin >> n;
for(int i = 1; i <= n; i++)
{
scanf("%d",&a[i]);
b[i] = i; //给b数组初始化
}
stable_sort(b + 1, b + n + 1, cmp); //给b数组按a数组从大到小的顺序排序
long long sum = 0;
for(int i = 1; i <= n; i++)
{
a[b[i]] = i; //配合前面排序函数对a数组进行离散化
}
for(int i = n; i >= 1; i--)
{
sum += Query(a[i] - 1); //从后往前则是找此时数组中比这个数小的数的个数
Add(a[i]); //更新树状数组
}
cout << sum;
}
分块
第一行输入一个数字 n。 第二行输入 几个数字,第i个数字为 a:,以空格隔开。 接下来输入 n 行询问,每行输入四个数字 opt、l、r、c,以空格隔开。 若 opt =0,表示将位于,,的之间的数字都加 c。 若 opt = 1,表示询问位于|l,,|的所有数字的和 mod(c + 1)。
#include <cmath>
#include <iostream>
using namespace std;
int id[50005], len;
// id 表示块的编号, len=sqrt(n) , 即上述题解中的s, sqrt的时候时间复杂度最优
long long a[50005], b[50005], s[50005];
// a 数组表示数据数组, b 数组记录每个块的整体赋值情况, 类似于 lazy_tag, s
// 表示块内元素总和
void add(int l, int r, long long x) { // 区间加法
int sid = id[l], eid = id[r];
if (sid == eid) { // 在一个块中
for (int i = l; i <= r; i++) a[i] += x, s[sid] += x;
return;
}
for (int i = l; id[i] == sid; i++) a[i] += x, s[sid] += x;
for (int i = sid + 1; i < eid; i++)
b[i] += x, s[i] += len * x; // 更新区间和数组(完整的块)
for (int i = r; id[i] == eid; i--) a[i] += x, s[eid] += x;
// 以上两行不完整的块直接简单求和,就OK
}
long long query(int l, int r, long long p) { // 区间查询
int sid = id[l], eid = id[r];
long long ans = 0;
if (sid == eid) { // 在一个块里直接暴力求和
for (int i = l; i <= r; i++) ans = (ans + a[i] + b[sid]) % p;
return ans;
}
for (int i = l; id[i] == sid; i++) ans = (ans + a[i] + b[sid]) % p;
for (int i = sid + 1; i < eid; i++) ans = (ans + s[i]) % p;
for (int i = r; id[i] == eid; i--) ans = (ans + a[i] + b[eid]) % p;
// 和上面的区间修改是一个道理
return ans;
}
int main() {
int n;
cin >> n;
len = sqrt(n); // 均值不等式可知复杂度最优为根号n
for (int i = 1; i <= n; i++) { // 题面要求
cin >> a[i];
id[i] = (i - 1) / len + 1;
s[id[i]] += a[i];
}
for (int i = 1; i <= n; i++) {
int op, l, r, c;
cin >> op >> l >> r >> c;
if (op == 0)
add(l, r, c);
else
cout << query(l, r, c + 1) << endl;
}
return 0;
}
图论
链式前向星存图
图的存储方式主要有链接矩阵、邻接表两种,邻接矩阵的好处是写建图简单方便但占内存较大,节点数量稍微大点的题目就开不下数组了(适合稠密图);而邻接表虽然节省空间,但其指针形式难写易错,且vector形式的读取太慢易导致大数据下的TLE。针对上述问题,这里就产生了一种比较中庸的方式:链式前向星。
简单来说,链式前向星就是把数据以链表形式连接在一起,那么连接的条件是什么呢?我们回想一下图里面邻接表里存的是每个点的连接点。那么这里的链式前向星存的就是以每个点为起点的所有边。
const int maxn = 200000 + 10;
typedef pair<int,int> P;
struct Node//结构体进行链式前向星存图
{
int to,next,flag;//终点 + 下个边编号 + 当前航线
};
Node node[2*maxn];
int dis[maxn],head[maxn];
bool judge[maxn];
int n,m,tot;
void AddEdge(int a,int b,int c)//加边函数(分配编号)
{
node[tot].next = head[a];node[tot].to = b;node[tot].flag = c;head[a] = tot++;
}
struct Arrive//在跑最短路时记录前导航线 + 目前花费 + 当前港口
{
int flagin,val,portid;
bool operator <(const Arrive &another)const{//按照花费由小到大排序
return val>another.val;
}
Arrive(int a,int b,int c):flagin(a),val(b),portid(c) {}
};
void Dijkstra(int a)
{
priority_queue<Arrive>que;
que.push(Arrive(0,0,a));
while(!que.empty()){
Arrive p = que.top();
que.pop();
int id = p.portid;
if(judge[id])continue;
judge[id] = 1;
for(int i = head[id];~i;i = node[i].next){//遍历链式前向星
int cost = p.val + (p.flagin==node[i].flag?0:1);//估测花费(判断航线是否一致)
if(dis[node[i].to]>cost&&!judge[node[i].to]){//更新
dis[node[i].to] = cost;
que.push(Arrive(node[i].flag,cost,node[i].to));
}
}
}
}
int main()
{
while(scanf("%d%d",&n,&m)!=EOF){
tot = 0;//初始化
memset(dis,INF,sizeof(dis));//这个地方用mem A了而且时间很短,用循环超时QAQ
//for(int i = 0;i<=n;i++)dis[i] = INF;
memset(judge,0,sizeof(judge));
memset(head,-1,sizeof(head));
for(int i = 0;i<m;i++){
int a,b,c;
scanf("%d%d%d",&a,&b,&c);
AddEdge(a,b,c);//无向图双向建边
AddEdge(b,a,c);
}
dis[1] = 0;
Dijkstra(1);
printf("%d\n",dis[n]==INF?-1:dis[n]);
}
return 0;
}
树上问题
求树的直径
constexpr int N = 10000 + 10;
int n, d = 0;
int d1[N], d2[N];
vector<int> E[N];
void dfs(int u, int fa) {
d1[u] = d2[u] = 0;
for (int v : E[u]) {
if (v == fa) continue;
dfs(v, u);
int t = d1[v] + 1;
if (t > d1[u])
d2[u] = d1[u], d1[u] = t;
else if (t > d2[u])
d2[u] = t;
}
d = max(d, d1[u] + d2[u]);
}
int main() {
scanf("%d", &n);
for (int i = 1; i < n; i++) {
int u, v;
scanf("%d %d", &u, &v);
E[u].push_back(v), E[v].push_back(u);
}
dfs(1, 0);
printf("%d\n", d);
return 0;
}
求树上端点序号最大的直径(CF2107D)
有一棵包含个节点的苹果树,初始时每个节点上都有一个苹果。你手中拿着一张纸,起初纸上没有任何内容。
只要树上至少还剩一个苹果,你就通过执行以下操作在这棵苹果树上进行遍历:
- 选择一条苹果路径
。当且仅当路径
- 设该路径上的苹果数量为
,按照
的顺序将这三个数字写在纸上。
- 然后移除路径
这里,路径指的是从
到
的唯一最短路径上的顶点序列。
设纸上的数字序列为。你的任务是找出字典序最大的可能序列
。
#include <bits/stdc++.h>
using namespace std;
// 使用梅森旋转算法(Mersenne Twister)生成随机数,这里其实在本题中未实际使用
mt19937_64 RNG(chrono::steady_clock::now().time_since_epoch().count());
int main()
{
int t;
cin >> t; // 读取测试用例的数量
while (t--){ // 循环处理每个测试用例
int n;
cin >> n; // 读取当前测试用例中树的节点数量
// 邻接表,用于存储树的结构,adj[i] 存储与节点 i 相邻的所有节点
vector<vector<int>> adj(n + 1);
for (int i = 1; i < n; i++){ // 读取树的 n - 1 条边
int u, v;
cin >> u >> v; // 读取边的两个端点
// 无向图,所以需要在两个端点的邻接表中都添加对方
adj[u].push_back(v);
adj[v].push_back(u);
}
// used 数组用于标记节点上的苹果是否已被移除,初始都为 false
vector <bool> used(n + 1, false);
// seen 数组用于在 DFS 中标记节点是否已被访问,初始都为 false
vector <bool> seen(n + 1, false);
// ans 数组用于存储最终结果,每个元素是一个三元组 {d, u, v}
vector <array<int, 3>> ans;
// p 数组用于记录每个节点在 DFS 中的父节点,初始都为 -1
vector <int> p(n + 1, -1);
while (true){
// 检查是否所有节点的苹果都已被移除,如果是则退出循环
if (count(used.begin() + 1, used.end(), false) == 0){
break;
}
// 每次新的一轮开始时,重置 seen 数组
seen.assign(n + 1, false);
// 定义一个递归的 lambda 函数 dfs 用于深度优先搜索
auto dfs = [&](auto self, int u, int par) -> pair<int, int>{
// 初始化结果,第一个元素表示从当前节点出发的最长路径长度,第二个元素表示路径终点节点
pair <int, int> ans = {1, u};
// 记录当前节点的父节点
p[u] = par;
// 标记当前节点已被访问
seen[u] = true;
// 遍历当前节点的所有相邻节点
for (int v : adj[u]){
// 如果相邻节点不是父节点且该节点的苹果未被移除
if (v != par && !used[v]){
// 递归调用 dfs 函数,计算从相邻节点出发的最长路径
auto pi = self(self, v, u);
// 路径长度加 1
pi.first += 1;
// 更新最长路径
ans = max(ans, pi);
}
}
return ans;
};
// 遍历所有节点
for (int i = 1; i <= n; i++)
// 如果该节点的苹果未被移除且未被访问
if (!used[i] && !seen[i]){
// 第一次 dfs,找到距离节点 i 最远的节点 j
auto [d1, j] = dfs(dfs, i, -1);
// 第二次 dfs,找到距离节点 j 最远的节点 k
auto [d2, k] = dfs(dfs, j, -1);
// 将直径信息 {d2, max(j, k), min(j, k)} 添加到结果数组中
ans.push_back({d2, max(j, k), min(j, k)});
// 从节点 k 开始,沿着父节点路径回溯,标记路径上的节点的苹果已被移除
while (k != -1){
used[k] = true;
k = p[k];
}
}
}
// 对结果数组按字典序降序排序
sort(ans.begin(), ans.end(), greater<array<int, 3>>());
// 输出结果
for (auto [x, y, z] : ans){
cout << x << " " << y << " " << z << " ";
}
cout << '\n';
}
return 0;
}
求树的中心
在树中,如果节点x作为根节点时,从x出发的最长链最短,那么称x为这棵树的中心
求法
寻找一个点 ,使其作为根节点时,最长链的长度最短。
具体步骤
- 维护
,表示节点
- 维护
,表示不与
- 维护
,表示节点
- 找到点
最小,那么
// 这份代码默认节点编号从 1 开始,即 i ∈ [1,n],使用vector存图
int d1[N], d2[N], up[N], x, y, mini = 1e9; // d1,d2对应上文中的len1,len2
struct node {
int to, val; // to为边指向的节点,val为边权
};
vector<node> nbr[N];
void dfsd(int cur, int fa) { // 求取len1和len2
for (node nxtn : nbr[cur]) {
int nxt = nxtn.to, w = nxtn.val; // nxt为这条边通向的节点,val为边权
if (nxt == fa) {
continue;
}
dfsd(nxt, cur);
if (d1[nxt] + w > d1[cur]) { // 可以更新最长链
d2[cur] = d1[cur];
d1[cur] = d1[nxt] + w;
} else if (d1[nxt] + w > d2[cur]) { // 不能更新最长链,但可更新次长链
d2[cur] = d1[nxt] + w;
}
}
}
void dfsu(int cur, int fa) {
for (node nxtn : nbr[cur]) {
int nxt = nxtn.to, w = nxtn.val;
if (nxt == fa) {
continue;
}
up[nxt] = up[cur] + w;
if (d1[nxt] + w != d1[cur]) { // 如果自己子树里的最长链不在nxt子树里
up[nxt] = max(up[nxt], d1[cur] + w);
} else { // 自己子树里的最长链在nxt子树里,只能使用次长链
up[nxt] = max(up[nxt], d2[cur] + w);
}
dfsu(nxt, cur);
}
}
void GetTreeCenter() { // 统计树的中心,记为x和y(若存在)
dfsd(1, 0);
dfsu(1, 0);
for (int i = 1; i <= n; i++) {
if (max(d1[i], up[i]) < mini) { // 找到了当前max(len1[x],up[x])最小点
mini = max(d1[i], up[i]);
x = i;
y = 0;
} else if (max(d1[i], up[i]) == mini) { // 另一个中心
y = i;
}
}
}
例题:HDU2739
作为已知宇宙的统治种族,戈雷利安人时常感到无聊,因此他们经常以下列方式征服新的星域:
1) 先遣部队找到合适行星实施占领,建立区域戈雷利安星系政府(简称RGGG),统辖该星域所有事务。
2) 征服下一颗行星时,会在新行星与RGGG所在行星之间建立单向跃迁链路。通过这种方式连接的行星构成区域戈雷利安行星网络(RGPN)。
3) 后续每征服一颗新行星,都会将其与RGPN中最近的行星建立跃迁链路,以此最小化联网成本。若存在多个等距行星,则选择最早被征服的那个。
这会导致一个问题:由于征服顺序的随机性,经过一段时间后RGGG所在位置可能不再理想。有些需要联系RGGG的戈雷利安人只需跃迁一两次,而另一些可能需要数十次——考虑到每次跃迁需间隔10小时,这将极其不便。
因此,戈雷利安人每年会分析RGPN网络,将RGGG迁移至最优位置。最优位置定义为:能使RGPN中任意行星到达RGGG所需最大跃迁次数最小的行星。实际情况中,这样的行星总是恰好存在1或2颗。当存在2颗时,它们必定通过跃迁链路直接相连,此时RGGG会在这两颗行星上均等分配。
你的任务是编写程序找出RGGG的最优行星。本题设定中,被征服星域是坐标为(0,0,0)到(1000,1000,1000)的立方体空间。
//
// Created by Swan416 on 2025-03-31 13:39.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
#define QwQ cin.tie(0);cout.tie(0);ios::sync_with_stdio(0);
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
inline ll read(){
ll sum = 0,fl = 1;
int ch = getchar();
for(;!isdigit(ch);ch = getchar())
if(ch=='-')
fl = -1;
for(;isdigit(ch);ch = getchar())
sum = sum*10+ch-'0';
return fl*sum;
}
inline void write(ll x){
static int sta[35];
int top = 0;
do{
sta[top++] = x%10,x/=10;
}while(x);
while(top)
putchar(sta[--top]+48);
putchar('\n');
}
int n;
struct planet{
int id;
int x,y,z;
int dist(const planet &p)
{
return abs(x-p.x)*abs(x-p.x)+abs(y-p.y)*abs(y-p.y)+abs(z-p.z)*abs(z-p.z);
}
};
void solve()
{
vector<planet> p(n);
vector<int> id(n,0);
for(int i=0;i<n;i++)
{
cin>>p[i].id>>p[i].x>>p[i].y>>p[i].z;
id[i]=p[i].id;
}
// 建树
vector<int> G[n];
for(int i=1;i<n;i++)
{
// 找在它之前的离它最近的星球连边
int minDist=INT_MAX,nearest=-1;
for(int j=0;j<i;j++)
{
int d=p[i].dist(p[j]);
if(d<minDist)
{
minDist=d;
nearest=j;
}
}
G[nearest].push_back(i);
G[i].push_back(nearest);
}
// 找这棵树的中心
vector<int> len1(n,0);// 表示节点i子树内的最长链
vector<int> len2(n,0);// 表示不与len1[i]重叠的最长链
vector<int> up(n,0);// 表示节点i子树外的最长链,该链必定经过i的父节点
// 最后找x使得max(len1[x],up[x])最小,那么x就是这棵树的中心
function <void(int,int)> dfsd=[&](int cur,int fa) -> void // 计算len1和len2
{
for(auto &i:G[cur])
{
if(i==fa)
continue;
dfsd(i,cur);
if(len1[i]+1>len1[cur])
{
len2[cur]=len1[cur];
len1[cur]=len1[i]+1;
}
else if(len1[i]+1>len2[cur])
len2[cur]=len1[i]+1;
}
};
function <void(int,int)> dfsu=[&](int cur,int fa) -> void // 计算up
{
for(auto &i:G[cur])
{
if(i==fa)
continue;
up[i]=up[cur]+1;
if(len1[i]+1==len1[cur])// 自己子树里的最长链在nxt子树里,只能使用次长链
up[i]=max(up[i],len2[cur]+1);
else// 自己子树里的最长链不在nxt子树里,可以使用最长链
up[i]=max(up[i],len1[cur]+1);
dfsu(i,cur);
}
};
dfsd(0,-1);
dfsu(0,-1);
// 中心可能有两个或一个,两个的话按id升序输出
vector<int> center;
int minLen=INT_MAX;
for(int i=0;i<n;i++)
{
int cur=max(len1[i],up[i]);
if(cur<minLen)
{
minLen=cur;
center.clear();
center.push_back(i);
}
else if(cur==minLen)
center.push_back(i);
}
if(center.size()==1)
cout<<id[center[0]]<<endl;
else
{
int a=id[center[0]],b=id[center[1]];
if(a>b)
swap(a,b);
cout<<a<<' '<<b<<endl;
}
}
int main()
{
while(cin>>n)
{
if(n==0)
break;
solve();
}
return 0;
}
求树的重心
如果在树中选择某个节点并删除,这棵树将分为若干棵子树,统计子树节点数并记录最大值。取遍树上所有节点,使此最大值取到最小的节点被称为整个树的重心。
// 这份代码默认节点编号从 1 开始,即 i ∈ [1,n]
int size[MAXN], // 这个节点的「大小」(所有子树上节点数 + 该节点)
weight[MAXN], // 这个节点的「重量」,即所有子树「大小」的最大值
centroid[2]; // 用于记录树的重心(存的是节点编号)
void GetCentroid(int cur, int fa) { // cur 表示当前节点 (current)
size[cur] = 1;
weight[cur] = 0;
for (int i = head[cur]; i != -1; i = e[i].nxt) {
if (e[i].to != fa) { // e[i].to 表示这条有向边所通向的节点。
GetCentroid(e[i].to, cur);
size[cur] += size[e[i].to];
weight[cur] = max(weight[cur], size[e[i].to]);
}
}
weight[cur] = max(weight[cur], n - size[cur]);
if (weight[cur] <= n / 2) { // 依照树的重心的定义统计
centroid[centroid[0] != 0] = cur;
}
}
求lca
洛谷 P3379
如题,给定一棵有根多叉树,请求出指定两个点直接最近的公共祖先。
#include <bits/stdc++.h>
using namespace std;
constexpr int N = 5e5 + 5;
int n, m, R, dn, dfn[N], mi[19][N];
vector<int> e[N];
int get(int x, int y) {return dfn[x] < dfn[y] ? x : y;}
void dfs(int id, int f) {
mi[0][dfn[id] = ++dn] = f;
for(int it : e[id]) if(it != f) dfs(it, id);
}
int lca(int u, int v) {
if(u == v) return u;
if((u = dfn[u]) > (v = dfn[v])) swap(u, v);
int d = __lg(v - u++);
return get(mi[d][u], mi[d][v - (1 << d) + 1]);
}
int main() {
scanf("%d %d %d", &n, &m, &R);
for(int i = 2, u, v; i <= n; i++) {
scanf("%d %d", &u, &v);
e[u].push_back(v), e[v].push_back(u);
}
dfs(R, 0);
for(int i = 1; i <= __lg(n); i++)
for(int j = 1; j + (1 << i) - 1 <= n; j++)
mi[i][j] = get(mi[i - 1][j], mi[i - 1][j + (1 << i - 1)]);
for(int i = 1, u, v; i <= m; i++) scanf("%d %d", &u, &v), printf("%d\n", lca(u, v));
return 0;
}
DFS序
- 定义多叉树的
序是一种类二叉树先序遍历
- 定义
是
- 定义
数组是
- 定义
数组是
- 对于一棵多叉树, 发现将其利用
- 之前定义过
数组, 其实它还有一个含义, 它还表示
数组
- 定义
数组表示在
- 定义
数组表示在
- 有了
数组, 子树的维护问题就转化成了数组区间的维护问题
void dfs(int u)
{
dfn[++ timestamp] = u;
L[u] = timestamp;
vis[u] = true;
for(auto v: G[u])
if(!vis[v])
dfs(v);
R[u] = timestamp;
}
树上启发式合并
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define lowbit(x) x&(-x)
const int MOD=1e9+7;
const int N=1000100;
int a[N];//记录节点的颜色
int ans[N];//记录每个节点的主要颜色
int siz[N];//记录每个节点为根节点的子树大小
int cnt[N];//记录每种颜色的个数
int son[N];//记录重儿子
int e[N],ne[N],h[N];
int idx;//链式前向星存图
int maxvalue;
int sum;
void add(int x,int y) {
e[++idx] = y,ne[idx] = h[x],h[x] = idx;
}
void dfs1(int x,int fa) {//第一次dfs,寻找重儿子
siz[x] = 1;
for(int i=h[x];i;i=ne[i]) {
int to = e[i];
if(to!=fa) {
dfs1(to,x);
siz[x] += siz[to];
if(siz[to] > siz[son[x]]) son[x] = to;
}
}
}
void update(int x,int fa,int sign,int eson) {//dfs方式查找当前子树对应答案
int color = a[x];
cnt[color] += sign;
if(cnt[color] > maxvalue) maxvalue = cnt[color],sum = color;
else if(cnt[color] == maxvalue) sum += color;
for(int i=h[x];i;i=ne[i]) {
int to = e[i];
if(to!=fa && to!=eson) {
update(to,x,sign,eson);
}
}
}
void dfs2(int x,int fa,int isson) {
for(int i=h[x];i;i=ne[i]) {
int to = e[i];
if(to!=fa && to!=son[x]) {//先dfs查找轻儿子的情况
dfs2(to,x,0);
}
}
if(son[x]) dfs2(son[x], x,1);//然后dfs查找重儿子的情况
update(x,fa,1,son[x]);//查找当前节点的对应答案
ans[x] = sum;
if(!isson) update(x,fa,-1,0),sum = maxvalue = 0;//将轻节点的数据移除
}
void solve() {
int n;
cin>>n;
for(int i=1;i<=n;i++) cin>>a[i];
for(int i=1;i<=n-1;i++) {
int x,y;
cin>>x>>y;
add(x,y);
add(y,x);
}
dfs1(1,0);
dfs2(1,0,1);
for(int i=1;i<=n;i++) cout<<ans[i]<<" ";
}
signed main() {
int t=1;
while(t--) {
solve();
}
return 0;
}
动态树(Link Cut Tree)
给定 个点以及每个点的权值,要你处理接下来的
个操作。
操作有四种,操作从 到
编号。点从
到
编号。
0 x y代表询问从和。保证
1 x y代表连接2 x y代表删除边,不保证边
3 x y代表将点
#include<cstdio>
#include<cstring>
#include<algorithm>
#define mid (l+r)/2
using namespace std;
const int N = 200010;
int n, q, m, cnt = 0;
int a[N], b[N], T[N];
int sum[N<<5], L[N<<5], R[N<<5];
inline int build(int l, int r)
{
int rt = ++ cnt;
sum[rt] = 0;
if (l < r){
L[rt] = build(l, mid);
R[rt] = build(mid+1, r);
}
return rt;
}
inline int update(int pre, int l, int r, int x)
{
int rt = ++ cnt;
L[rt] = L[pre]; R[rt] = R[pre]; sum[rt] = sum[pre]+1;
if (l < r){
if (x <= mid) L[rt] = update(L[pre], l, mid, x);
else R[rt] = update(R[pre], mid+1, r, x);
}
return rt;
}
inline int query(int u, int v, int l, int r, int k)
{
if (l >= r) return l;
int x = sum[L[v]] - sum[L[u]];
if (x >= k) return query(L[u], L[v], l, mid, k);
else return query(R[u], R[v], mid+1, r, k-x);
}
int main()
{
scanf("%d%d", &n, &q);
for (int i = 1; i <= n; i ++){
scanf("%d", &a[i]);
b[i] = a[i];
}
sort(b+1, b+1+n);
m = unique(b+1, b+1+n)-b-1;
T[0] = build(1, m);
for (int i = 1; i <= n; i ++){
int t = lower_bound(b+1, b+1+m, a[i])-b;
T[i] = update(T[i-1], 1, m, t);
}
while (q --){
int x, y, z;
scanf("%d%d%d", &x, &y, &z);
int t = query(T[x-1], T[y], 1, m, z);
printf("%d\n", b[t]);
}
return 0;
}
拓补排序
#include <bits/stdc++.h>
using namespace std;
int n,m;
const int N=514;
vector<int> G[N];
int inD[N];
map<pii,int> mp;
void solve()
{
for(int i=1;i<=n;i++)
G[i].clear();
memset(inD,0,sizeof(inD));
mp.clear();
for(int i=1;i<=m;i++)
{
int u,v;
cin>>u>>v;
if(u==v or mp[{u,v}])
continue;
G[u].push_back(v);
inD[v]++;
mp[{u,v}]=1;
}
vector<int> ans;
priority_queue<int,vector<int>,greater<int>> q;
for(int i=1;i<=n;i++)
if(!inD[i])
q.push(i);
while(q.size())
{
int u=q.top();
q.pop();
ans.push_back(u);
for(auto v:G[u])
{
inD[v]--;
if(!inD[v])
q.push(v);
}
}
if(ans.size()<n)
{
cout<<"Impossible!"<<endl;
return;
}
for(int i=0;i<n;i++)
{
if(i)
cout<<" ";
cout<<ans[i];
}
}
int main()
{
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
while(cin>>n>>m)
{
solve();
}
return 0;
}
最小生成树
最小生成树也叫最小代价树,对于一个 带权连通无向图 G=(V,E),生成树不同,每棵树的权(即树中所有边上的权值之和)也可能不同。设R为G的所有生成树的集合,若T为R中 边的权值之和最小 的生成树,则T称为G的最小生成树(Minimum-Spanning-Tree,MST)。
Prim算法
// 使用二叉堆优化的 Prim 算法。
#include <cstring>
#include <iostream>
#include <queue>
using namespace std;
constexpr int N = 5050, M = 2e5 + 10;
struct E {
int v, w, x;
} e[M * 2];
int n, m, h[N], cnte;
void adde(int u, int v, int w) { e[++cnte] = E{v, w, h[u]}, h[u] = cnte; }
struct S {
int u, d;
};
bool operator<(const S &x, const S &y) { return x.d > y.d; }
priority_queue<S> q;
int dis[N];
bool vis[N];
int res = 0, cnt = 0;
void Prim() {
memset(dis, 0x3f, sizeof(dis));
dis[1] = 0;
q.push({1, 0});
while (!q.empty()) {
if (cnt >= n) break;
int u = q.top().u, d = q.top().d;
q.pop();
if (vis[u]) continue;
vis[u] = true;
++cnt;
res += d;
for (int i = h[u]; i; i = e[i].x) {
int v = e[i].v, w = e[i].w;
if (w < dis[v]) {
dis[v] = w, q.push({v, w});
}
}
}
}
int main() {
cin >> n >> m;
for (int i = 1, u, v, w; i <= m; ++i) {
cin >> u >> v >> w, adde(u, v, w), adde(v, u, w);
}
Prim();
if (cnt == n)
cout << res;
else
cout << "No MST.";
return 0;
}
Kruskal算法
算法思路:
-
将所有边按照权值的大小进行升序排序,然后从小到大一一判断。
-
如果这个边与之前选择的所有边不会组成回路,就选择这条边分;反之,舍去。
-
直到具有 n 个顶点的连通网筛选出来 n-1 条边为止。
-
筛选出来的边和所有的顶点构成此连通网的最小生成树。
判断是否会产生回路的方法为:使用并查集。
-
在初始状态下给各个个顶点在不同的集合中。、
-
遍历过程的每条边,判断这两个顶点的是否在一个集合中。
-
如果边上的这两个顶点在一个集合中,说明两个顶点已经连通,这条边不要。如果不在一个集合中,则要这条边。
举个例子,下图一个连通网,克鲁斯卡尔算法查找图 1 对应的最小生成树,需要经历以下几个步骤:
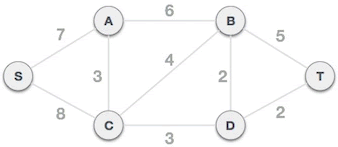
- 将连通网中的所有边按照权值大小做升序排序:

- 从 B-D 边开始挑选,由于尚未选择任何边组成最小生成树,且 B-D 自身不会构成环路,所以 B-D 边可以组成最小生成树。
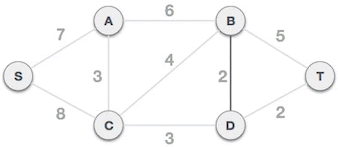
- D-T 边不会和已选 B-D 边构成环路,可以组成最小生成树:
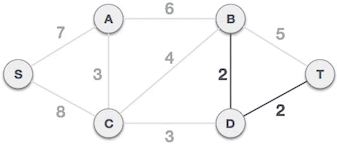
- A-C 边不会和已选 B-D、D-T 边构成环路,可以组成最小生成树:
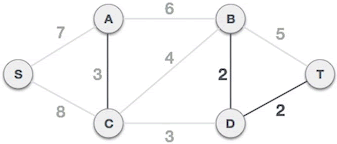
- C-D 边不会和已选 A-C、B-D、D-T 边构成环路,可以组成最小生成树:
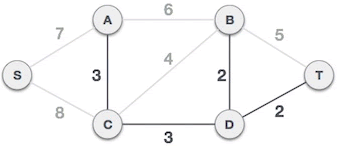
- C-B 边会和已选 C-D、B-D 边构成环路,因此不能组成最小生成树:
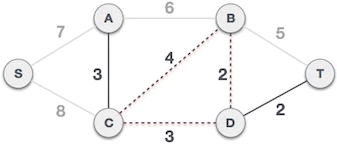
- B-T 、A-B、S-A 三条边都会和已选 A-C、C-D、B-D、D-T 构成环路,都不能组成最小生成树。而 S-A 不会和已选边构成环路,可以组成最小生成树。
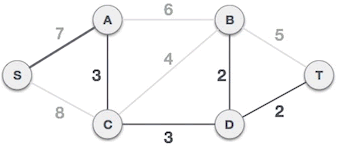
- 如图下图 所示,对于一个包含 6 个顶点的连通网,我们已经选择了 5 条边,这些边组成的生成树就是最小生成树。
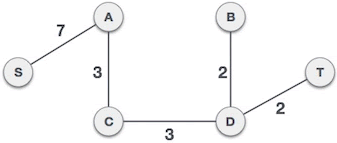
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int n,m;
const int N=100010;
const int M=200010;
int pre[N];
int find(int x)
{
if(pre[x]!=x) pre[x]=find(pre[x]);
return pre[x];
}
struct Edge
{
int a, b, w;
bool operator<(const Edge &t) const
{
return w < t.w;
}
}all[M];
void kruskal()
{
sort(all,all+m);
int res=0,cnt=0;
for(int i=0;i<m;i++)
{
int a=all[i].a,b=all[i].b,w=all[i].w;
a=find(a),b=find(b);
if(a!=b)
{
pre[a]=b;
res+=w;
cnt++;
}
}
if(cnt<n-1) puts("impossible");
else printf("%d\n", res);
}
int main()
{
scanf("%d%d", &n, &m);
for(int i=1;i<=n;i++) pre[i]=i;
for(int i=0;i<m;i++)
{
int a,b,w;
scanf("%d%d%d", &a, &b, &w);
all[i]={a,b,w};
}
kruskal();
return 0;
}
Kruskal重构树
用"虚点"来表示 连来的树边, 用新的点权来代表边权
基本思想: 在运行 算法的过程中, 对于两个可以合并的节点
, 断开其中的连边, 并新建一个节点
, 把
向
,
连边并作为他们的父亲, 同时, 把
之间的边权当作
的点权
void Ex_Kruskal()
{
int cnt = n;
sort(e, e + m, cmp);
for(int i = 1; i < n * 2; i++) p[i] = i;
for(int i = 0; i < m; i++)
{
int u = get(e[i].x), v = get(e[i].y);
if(u != v)
{
++ cnt;
p[u] = p[v] = cnt;
val[cnt] = e[i].w;
add(cnt, u), add(cnt, v);
if(cnt == 2 * n - 1) break;
}
}
}
重构树的性质:
- 节点个数为
- 它是一棵二叉树
- 若边权升序, 则它是一个大根堆
- 任意两点路径边权最大值为
重构树上
的点权
最短路
dijsktra
朴素版
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
const int N=510;
int mp[N][N];
bool bl[N];
int dis[N];
int n,m;
int dijkstra()
{
memset(dis,0x3f,sizeof(dis));
dis[1]=0;
for(int i=0;i<n;i++)
{
int t=-1;
for(int j=1;j<=n;j++)
{
if(!bl[j])
{
if(t==-1 or dis[t]>dis[j])
t=j;
}
}
bl[t]=true;
for(int j=1;j<=n;j++)
dis[j]=min(dis[j],dis[t]+mp[t][j]);
}
if(dis[n]==0x3f3f3f3f) return -1;
else return dis[n];
}
int main()
{
cin>>n>>m;
memset(mp,0x3f,sizeof(mp));
while(m--)
{
int a,b,c;
cin>>a>>b>>c;
mp[a][b]=min(mp[a][b],c);
}
int ans=dijkstra();
cout<<ans<<endl;
return 0;
}
堆优化版
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
const int N=150010;
vector<pii> adj[N];
bool bl[N];
ll dis[N];
ll n,m;
int dijkstra()
{
memset(dis,0x3f,sizeof(dis));
dis[1]=0;
priority_queue<pii,vector<pii>,greater<pii>> q;
q.push({0,1});
while(q.size())
{
pii x=q.top();
q.pop();
int ver=x.second,distance=x.first;
if(bl[ver])
continue;
bl[ver]=true;
for(auto edge : adj[ver])
{
int j = edge.first;
int w = edge.second;
if(dis[j]>dis[ver]+w)
{
dis[j]=dis[ver]+w;
q.push({dis[j],j});
}
}
}
return dis[n];
}
int main()
{
cin>>n>>m;
while(m--)
{
int a,b,c;
cin>>a>>b>>c;
adj[a].push_back({b,c});
}
int ans=dijkstra();
if(ans==0x3f3f3f3f)
cout<<-1<<endl;
else
cout<<ans<<endl;
return 0;
}
bellman-ford
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
int main()
{
int n,m,k;
cin >> n >> m >> k;
int x[m],y[m],z[m];
for(int i=0;i<m;i++)
{
cin >> x[i] >> y[i] >> z[i];
}
int dis[n+1];
memset(dis,0x3f,sizeof(dis));
dis[1]=0;
int backup[n+1];
for(int i=0;i<k;i++)
{
memcpy(backup,dis,sizeof(dis));
for(int j=0;j<m;j++)
{
dis[y[j]]=min(dis[y[j]],backup[x[j]]+z[j]);
}
}
// if(dis[n]==0x3f3f3f3f)
if(dis[n]>0x3f3f3f3f/2)//因为有负权边,所以必须这样写
{
cout << "impossible" << endl;
}
else
{
cout << dis[n] << endl;
}
return 0;
}
spfa
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
const int N=100010;
vector<vector<int>> to(N),lv(N);
int n,m;
bool bl[N];
int dis[N];
int spfa()
{
memset(dis,0x3f,sizeof(dis));
dis[1]=0;
queue<int> q;
q.push(1);
bl[1]=true;
while(q.size())
{
int x=q.front();
q.pop();
bl[x]=false;
for(int i=0;i<to[x].size();i++)
{
int y=to[x][i],z=lv[x][i];
if(dis[y]>dis[x]+z)
{
dis[y]=dis[x]+z;
if(!bl[y])
{
q.push(y);
bl[y]=true;
}
}
}
}
if(dis[n]==0x3f3f3f3f) return 0x3f3f3f3f;
return dis[n];
}
int main()
{
cin>>n>>m;
while(m--)
{
int x,y,z;
cin>>x>>y>>z;
to[x].push_back(y);
lv[x].push_back(z);
}
int ans=spfa();
if(ans==0x3f3f3f3f) cout<<"impossible"<<endl;
else cout<<ans<<endl;
return 0;
}
Floyd
#include <bits/stdc++.h>
#define mod 998244353
using namespace std;
const int N=250;
int n;
int d[N][N];
void floyd()
{
for(int k=1;k<=n;k++)
{
for(int i=1;i<=n;i++)
{
for(int j=1;j<=n;j++)
{
d[i][j]=min(d[i][j],d[i][k]+d[k][j]);
}
}
}
}
int main()
{
int m,k;
cin>>n>>m>>k;
memset(d,0x3f,sizeof d);
for(int i=1;i<=n;i++) d[i][i]=0;
while(m--)
{
int x,y,z;
cin>>x>>y>>z;
d[x][y]=min(d[x][y],z);
}
floyd();
while(k--)
{
int x,y;
cin>>x>>y;
if(d[x][y]>0x3f3f3f3f/2) cout<<"impossible"<<endl;
else cout<<d[x][y]<<endl;
}
return 0;
}
传递闭包
for (int k = 1; k <= n; k++)//记得k循环在i和j之前
for (int i = 1; i <= n; i++)
for (int j = 1; j <= n; j++)
a[i][j] |= a[i][k] & a[k][j];
分层图最短路
不同层记录不同状态,例如下面这题
给你一个有向图,图中有 个顶点和
条边。
-th 边
是一条从顶点
到顶点
的有向边。
最初,您位于顶点 。您要重复以下操作直到到达顶点
:
- 执行以下两个操作之一:
- 从当前顶点沿一条有向边移动。这样做的代价是
,选择一个顶点
,使得有一条从
- 逆转所有边的方向。这样做的代价是
。更确切地说,如果且仅如果在此操作之前有一条从
- 从当前顶点沿一条有向边移动。这样做的代价是
可以保证,对于给定的图,重复这些操作可以从顶点 到达顶点
。
求到达顶点 所需的最小总成本。
我们将图变成两层,这两层的对应节点之间建边权为X的双向边,然后这两层对比起来边的方向是完全相反的,那结果就是到这两层任意一层的n的位置
//
// Created by Swan416 on 2025-03-25 16:23.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
void solve()
{
ll n,m,x;
cin>>n>>m>>x;
vector<pll> G[2*n+1];// 存有向图终点和权值
for(int i=1;i<=m;i++)
{
ll u,v;
cin>>u>>v;
G[u].push_back({v,1});
G[v+n].push_back({u+n,1});
}
for(int i=1;i<=n;i++)
{
G[i].push_back({i+n,x});
G[i+n].push_back({i,x});
}
// dijkstra求1到n或2n的最短路
vector<ll> dis(2*n+1,1e18);
dis[1]=0;
priority_queue<pll,vector<pll>,greater<>> q;
q.push({0,1});
while(!q.empty())
{
auto [d,u]=q.top();
q.pop();
if(d>dis[u]) continue;
for(auto [v,w]:G[u])
{
if(dis[v]>dis[u]+w)
{
dis[v]=dis[u]+w;
q.push({dis[v],v});
}
}
}
ll ans=min(dis[n],dis[2*n]);
if(ans==1e18) cout<<-1<<endl;
else cout<<ans<<endl;
}
int main()
{
int T=1;
//scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
单源次短路
#include <bits/stdc++.h>
using namespace std;
using ll = long long;
const int N = 205;
const double INF = 1e18;
int n, m;
int fa[N]; // 记录最短路上的前驱节点
double d[N]; // 存储距离
pair<int, int> c[N]; // 存储坐标
vector<pair<int, double>> g[N]; // 邻接表存图
// 计算两点间欧几里得距离
double dst(int a, int b) {
ll dx = c[a].first - c[b].first;
ll dy = c[a].second - c[b].second;
return sqrt(dx * dx + dy * dy);
}
// Dijkstra 算法。eu 和 ev 是要临时排除的边的两个端点
void dij(int s, int eu, int ev) {
for (int i = 1; i <= n; ++i) {
d[i] = INF;
}
d[s] = 0.0;
// 优先队列优化 Dijkstra
priority_queue<pair<double, int>, vector<pair<double, int>>, greater<pair<double, int>>> q;
q.push({0.0, s});
while (!q.empty()) {
auto [dis, u] = q.top();
q.pop();
if (dis > d[u]) {
continue;
}
for (auto& edg : g[u]) {
int v = edg.first;
double w = edg.second;
// 如果是需要排除的边,则跳过
if ((u == eu && v == ev) || (u == ev && v == eu)) {
continue;
}
if (d[u] + w < d[v]) {
d[v] = d[u] + w;
// 只有在第一次求完整图的最短路时才记录前驱
if (eu == 0 && ev == 0) {
fa[v] = u;
}
q.push({d[v], v});
}
}
}
}
int main() {
ios::sync_with_stdio(0);
cin.tie(0);
cout.tie(0);
cin >> n >> m;
for (int i = 1; i <= n; ++i) {
cin >> c[i].first >> c[i].second;
}
for (int i = 0; i < m; ++i) {
int u, v;
cin >> u >> v;
if (u == v) continue; // 跳过自环
double w = dst(u, v);
g[u].push_back({v, w});
g[v].push_back({u, w}); // 无向图,双向添加
}
// 第一次运行,计算最短路,并记录路径
dij(1, 0, 0);
double s2 = INF;
// 从终点 n 开始,沿最短路径回溯到起点 1
int x = n;
while (x != 0 && fa[x] != 0) {
int y = fa[x];
// 临时删除边 (y, x) 后,重新计算最短路
dij(1, y, x);
// 更新次短路长度
s2 = min(s2, d[n]);
// 继续回溯
x = y;
}
// 如果 s2 仍然是 INF,说明不存在次短路
if (s2 > INF / 2) {
cout << -1 << endl;
} else {
cout << fixed << setprecision(2) << s2 << endl;
}
return 0;
}
2-SAT
2-SAT一般给出个布尔变量(取0或者取1),再给出个关于这些布尔变量的约束条件(见下文),求出是否能找到解满足这些约束条件。
2-SAT可以建图,转换成强连通分量进而判断矛盾问题。对于布尔变量,只有2个取值,取0或者取1,所以对于任意一个布尔变量,我们可用其原变量(即取1值)和其反变量(即取0值)依据约束条件来构建图。
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int MOD=998244353;
const int N=1000100;
struct Tree{
int l,r,sum,add;
}tree[N];
void build(int p,int l,int r) {//递归建树
if(l>r) return ;
tree[p].l=l;
tree[p].r=r;
int mid = (l+r)>>1;
build(p*2,l,mid);
build(p*2+1,mid+1,r);
tree[p].sum = tree[p*2].sum + tree[p*2+1].sum;
return ;
}
int qpow(int num,int k) {
int res=1;
while(k) {
if(k%2) res = (res * num) % MOD;
num = (num * num) % MOD;
k/=2;
}
return res%MOD;
}
int a[N];
int e[N],ne[N],h[N];
int idx;
int n,m;
int visitnum;
int instack[N];
int sta[N];
int top;
int dfn[N];
int low[N];
int color[N];
int tot;
void add(int a,int b) {
e[idx]=b,ne[idx]=h[a],h[a]=idx++;
}
void tarjan(int x) {
visitnum++;
dfn[x] = low[x] = visitnum;
sta[++top]=x;
instack[x]=1;
for(int i=h[x];i!=-1;i=ne[i]) {
int j=e[i];
if(!dfn[j]) {
tarjan(j);
low[x] = min(low[x],low[j]);
}
else if(instack[j]) {
low[x] = min(low[x],dfn[j]);
}
}
int j;
if(dfn[x]==low[x]) {
tot++;
do {
j=sta[top--];
color[j]=tot;
instack[j]=0;
}while(j!=x);
}
}
void solve() {
idx=0;
tot=0;
visitnum=0;
for(int i=0;i<2*n;i++) {
h[i]=-1;
dfn[i]=0;
low[i]=0;
}
for(int i=1;i<=m;i++) {
int a1,a2,c1,c2;
cin>>a1>>a2>>c1>>c2;
add(2*a1+c1,2*a2+1-c2);
add(2*a2+c2,2*a1+1-c1);
}
for(int i=0;i<2*n;i++) {
if(!dfn[i]) {
tarjan(i);
}
}
for(int i=0;i<2*n;i+=2) {
if(color[i] == color[i+1]) {
cout<<"NO\n";
return ;
}
}
cout<<"YES\n";
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(0);
cout.tie(0);
int t=1;
//cin>>t;
while(cin>>n>>m) {
solve();
}
return 0;
}
一般图匹配
给一个图,节点两两组队的最多对数
带花树算法 (Blossom Alogorithm)
-
总体思想: 找增广路直到没有为止
-
算法过程:
-
多次BFS, 从一个未匹配点出发将它染成黑色 (最开始所有点都是无色)
-
枚举与它相邻的点
-
若这个点没有在这次BFS找增广中访问过
- 它是一个未匹配点
找到增广路, 返回修改匹配情况
- 它是一个已匹配点
- 它是一个未匹配点
-
若这个点在这一次BFS中访问过: 说明找到了一个环
-
这个点是白色
-
这个点是黑色
-
若这个奇环已经缩过了, 则跳过这个点
-
若这个奇环没有缩过, 去处理它:
-
找到这个环的环顶 (即搜索中进入环的地方, 也即
-
将环顶到
-
并将环上的这些点的并查集父亲指向
(用并查集来缩环)
(只需要它们拥有同等的地位, 不需要物理上变成同一个点)
-
-
-
-
-
//match[i]: i匹配的谁
//last[i]: i通过非匹配边连的上一个点是谁
int lca(int x, int y) //求环顶
{
tmp ++; //为了不清vis数组,每次进入函数时给vis赋的值都不一样就可以了
while(1)
{
if(x != 0)
{
x = findfa(x); //先去x的环顶(处理非简单环的情况)
if(vis[x] == tmp) return x; //x走过,已经是环顶了,返回
vis[x] = tmp; //标记走过
if(match[x]) x = last[match[x]]; //往上跳一条匹配边和非匹配边(BFS一层就是走了一条匹配边和一条非匹配边)
else x = 0;
}
swap(x, y); //交换xy
}
}
void flower(int a, int r) //缩环(的一半)
{
while(a != r)
{
int b = match[a], c = last[b]; //a是黑点所以先跳匹配边再跳非匹配边
if(findfa(c) != r) last[c] = b; //因为奇环里到底怎么匹配还不知道,干脆把原来的匹配边也记录一组非匹配边(任意相邻两个点都有可能是最终的匹配)
if(col[b] == 2) q.push(b), col[b] = 1;
if(col[c] == 2) q.push(c), col[c] = 1; //环上的白点要变成黑点
fa[findfa(a)] = findfa(b);
fa[findfa(b)] = findfa(c); //并查集维护父亲
a = c; //往上跳
}
}
int work(int s)
{
for(int i = 1; i <= n; i++)
last[i] = col[i] = vis[i] = 0, fa[i] = i; //清数组
while(!q.empty()) q.pop();
col[s] = 1; //给起点标成黑色
q.push(s);
while(!q.empty()) //广搜
{
int x = q.front();
q.pop();
for(int i = head[x]; i > 0; i = edge[i].next)
{
int y = edge[i].t;
if(match[x] == y) continue; //走的匹配边(走回去了)
if(findfa(x) == findfa(y)) continue;
//两个点在同一个已经缩过的奇环里
if(col[y] == 2) continue; //偶环
if(col[y] == 1) //黑点——奇环
{
int r = lca(x, y); //r是环顶
if(findfa(x) != r) last[x] = y;
if(findfa(y) != r) last[y] = x; //xy都是靠非匹配边接在一起
flower(x, r);
flower(y, r); //缩花,每次缩掉花的一半
}
else if(!match[y]) //else: col等于0——在这次增广中y没访问过;match为0,这个点是个未匹配的点——增广路已经求到了
{
last[y] = x; //y通过非匹配边和x连到一起
for(int u = y; u != 0;) //顺着交错路走回去
{
int v = last[u]; //last是他通过非匹配边连的上一个点
int w = match[v]; //去v原来匹配的点
match[v] = u;
match[u] = v; //匹配边和非匹配边交换——uv成为新一对
u = w; //再从w开始往前走直到把这个增广路修改完
//这里之所以没有改last的值是因为用过了就没用了,后面会退出work函数,再次进入就清空了
}
return 1;
}
else //col等于0——在本次增广中y没访问过,且y原来有匹配
{
last[y] = x; //通过未匹配边的y的前一个点为x
col[y] = 2; //y自己是白点
col[match[y]] = 1; //y通过匹配边连的前一个点是黑点
q.push(match[y]); //这个黑点入队
}
}
}
return 0;
}
点分治
点分治,是一种针对可带权树上简单路径统计问题的算法。本质上是一种带优化的暴力,带上一点容斥的感觉。
注意对于树上路径,并不要求这棵树有根,即我们只需要对无根树进行统计。
#include<iostream>
#include<cstdio>
#include<algorithm>
using namespace std;
// 宏定义:最大节点数(根据题目调整)
#define N 10001
// 宏定义:register关键字缩写,用于优化变量存储(加速访问)
#define re register
// 快速读入函数:比cin/cout快,处理大量输入时常用
inline int read(){
int x=0,f=1; // x存储结果,f标记正负(1为正,-1为负)
char c=getchar(); // 读取字符
while(c<'0'||c>'9'){ // 处理非数字字符(主要是负号)
if(c=='-')f=-1; // 遇到负号,修改符号标记
c=getchar();
}
while(c>='0'&&c<='9'){ // 处理数字字符
// 等价于x = x*10 + (c-'0'),用位运算加速(10x = 8x + 2x = x<<3 + x<<1)
x=(x<<3)+(x<<1)+c-'0';
c=getchar();
}
return x*f; // 返回带符号的结果
}
// 全局变量定义
int n,m; // n:节点数;m:查询数
int query[101]; // 存储m个查询的目标值
// 树相关变量
int e_cnt=0; // 边的计数器
int head[N]; // 邻接表头数组,head[u]表示u的第一条边的索引
int maxp[N]; // 存储每个节点的最大子树大小(用于找重心)
int siz[N]; // 存储每个节点的子树大小
int root; // 当前找到的重心
int tot=0; // 临时计数器,用于存储当前处理的节点数量
int d[N]; // d[u]:节点u到当前重心的距离
int b[N]; // b[u]:标记u属于当前重心的哪个子树(用于去重)
int a[N]; // 临时数组,存储当前处理的所有节点(用于排序和双指针)
bool vis[N]; // 标记节点是否已作为重心处理过(避免重复处理)
bool ok[101]; // 标记每个查询是否有解(true表示存在符合条件的路径)
// 边的结构体:邻接表存储
struct Edge{
int to; // 边的终点
int nxt; // 下一条边的索引(邻接表链式存储)
int val; // 边的权值
}edge[N<<1]; // 边数组,大小为2*N(因为树是无向图,每条边存两次)
// 添加边的函数(无向图,双向添加)
void add(int a,int b,int c){
e_cnt++; // 边计数器自增
edge[e_cnt].nxt=head[a]; // 新边的下一条指向a原来的第一条边
edge[e_cnt].to=b; // 新边的终点是b
edge[e_cnt].val=c; // 新边的权值是c
head[a]=e_cnt; // a的第一条边更新为当前边
}
// 找重心的递归函数
// u:当前节点;fa:父节点;total:当前子树的总节点数
void get_root(int u,int fa,int total){
siz[u]=1; // 初始化当前节点的子树大小为1(包含自身)
maxp[u]=0; // 初始化最大子树大小为0
// 遍历u的所有邻边
for(re int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to; // 邻边的终点v
// 跳过父节点和已处理的节点(避免重复计算)
if(v==fa||vis[v])continue;
// 递归计算v的子树信息
get_root(v,u,total);
siz[u]+=siz[v]; // 更新u的子树大小(加上v的子树大小)
// 更新u的最大子树大小(取当前最大值和v的子树大小的较大者)
maxp[u]=max(siz[v],maxp[u]);
}
// 最大子树大小还需与“父方向的子树大小”比较(total - siz[u])
maxp[u]=max(maxp[u],total-siz[u]);
// 更新重心:如果当前节点的最大子树更小,则设为新重心
if(!root||maxp[u]<maxp[root]){
root=u;
}
}
// 排序比较函数:按节点到重心的距离从小到大排序
bool cmp(int x,int y){
return d[x]<d[y];
}
// 计算子树中各节点到重心的距离
// u:当前节点;fa:父节点;dis:当前距离;from:标记来自哪个子树(用于去重)
void get_dis(int u,int fa,int dis,int from){
a[++tot]=u; // 将当前节点加入临时数组
d[u]=dis; // 记录u到重心的距离
b[u]=from; // 标记u属于from子树(from是重心的直接子节点)
// 遍历u的所有邻边
for(re int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to; // 邻边的终点v
// 跳过父节点和已处理的节点
if(v==fa||vis[v])continue;
// 递归计算v的距离(距离累加边权)
get_dis(v,u,dis+edge[i].val,from);
}
}
// 在当前重心处理查询:判断是否存在两条路径之和等于查询值
// 核心:处理所有经过当前重心的路径
void calc(int u){
tot=0; // 重置临时计数器
a[++tot]=u; // 将重心自身加入数组(距离为0)
d[u]=0; // 重心到自身的距离为0
b[u]=u; // 重心不属于任何子树(用自身标记)
// 遍历重心的所有邻边,处理每个子树
for(int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to; // 邻边的终点v(重心的直接子节点)
if(vis[v])continue; // 跳过已处理的子树
// 计算v所在子树中所有节点到重心的距离,标记来源为v
get_dis(v,u,edge[i].val,v);
}
// 按距离从小到大排序(为双指针法做准备)
sort(a+1,a+tot+1,cmp);
// 处理每个查询
for(int i=1;i<=m;i++){
int l=1,r=tot; // 双指针:l从左向右,r从右向左
if(ok[i])continue; // 已找到解的查询直接跳过
// 双指针寻找是否存在d[a[l]] + d[a[r]] == query[i]
while(l<r){
if(d[a[l]]+d[a[r]]>query[i]){
// 和太大,右指针左移
r--;
}
else if(d[a[l]]+d[a[r]]<query[i]){
// 和太小,左指针右移
l++;
}
else if(b[a[l]]==b[a[r]]){
// 两条路径来自同一子树(不符合,因为路径需经过重心)
// 处理:若右指针前一个距离相同,移动右指针;否则移动左指针
if(d[a[r]]==d[a[r-1]])r--;
else l++;
}
else{
// 找到符合条件的两条路径(来自不同子树)
ok[i]=true;
break;
}
}
}
}
// 点分治主函数:递归处理每个重心
void solve(int u){
vis[u]=true; // 标记当前节点为已处理(作为重心)
calc(u); // 处理经过当前重心的所有路径
// 递归处理当前重心的所有子树
for(re int i=head[u];i;i=edge[i].nxt){
int v=edge[i].to; // 子树的根节点
if(vis[v])continue; // 跳过已处理的子树
root=0; // 重置重心标记
// 在v所在的子树中找新的重心(子树大小为siz[v])
get_root(v,0,siz[v]);
// 递归处理新重心
solve(root);
}
}
int main(){
n=read(),m=read(); // 读入节点数和查询数
// 读入n-1条边(构建树)
for(re int i=1;i<=n-1;i++){
int u,v,w;
u=read(),v=read(),w=read(); // 读入边的两个端点和权值
add(u,v,w); // 双向添加边
add(v,u,w);
}
// 读入m个查询
for(re int i=1;i<=m;i++){
query[i]=read();
if(!query[i])ok[i]=1; // 特判:查询值为0时,存在路径(自身到自身)
}
// 初始化找重心:从整棵树(总节点数n)开始
maxp[0]=n; // 初始最大子树大小设为n(用于第一次比较)
get_root(1,0,n); // 从节点1开始找整棵树的重心
solve(root); // 启动点分治
// 输出每个查询的结果
for(re int i=1;i<=m;i++){
if(ok[i]){
cout<<"AYE"<<endl; // 存在符合条件的路径
}
else{
cout<<"NAY"<<endl; // 不存在符合条件的路径
}
}
return 0;
}
欧拉回路/通路
定义
欧拉回路:不重不漏经过所有边最后回到起点的路径
欧拉通路:不一定要回到起点
判定存在性
回路:所有点的度都得是偶数
通路:允许有恰好两个点的度为奇数
Hierholzer算法找欧拉路径
例:CF2110E
2077年,统治世界的机器人发现人类的音乐并不出色,于是开始创作属于自己的音乐。
为了谱写乐曲,机器人使用一种能发出n种不同声音的特殊乐器。每个声音由音量和音高两个特征组成。一连串声音的组合就称为音乐。如果任意两个相邻声音仅在音量或仅在音高上存在差异,这段音乐就被称为优美的;如果任意三个连续声音的音量或音高完全相同,则被视为单调的。
你需要用乐器所有声音各一次,创作出优美且不单调的音乐。
//
// Created by Swan416 on 2025-05-25 17:32.
//
#include <bits/stdc++.h>
#define maxOf(a) *max_element(a.begin(),a.end())
#define minOf(a) *min_element(a.begin(),a.end())
#define all(a) a.begin(),a.end()
using namespace std;
typedef long long ll;
typedef double db;
typedef pair<int,int> pii;
typedef pair<ll,ll> pll;
void solve()
{
int n; scanf("%d",&n);
vector<pii> input(n);
vector<int> all_numbers;
for(int i=0;i<n;i++){
scanf("%d%d",&input[i].first,&input[i].second);
input[i].second+=1e9+7;
all_numbers.push_back(input[i].first);
all_numbers.push_back(input[i].second);
}
sort(all(all_numbers));
all_numbers.erase(unique(all(all_numbers)),all_numbers.end());
map<int,int> mp;
for(int i=0;i<all_numbers.size();i++){
mp[all_numbers[i]]=i+1;
}
map<pii,int> pos;
for(int i=0;i<n;i++){
input[i].first=mp[input[i].first];
input[i].second=mp[input[i].second];
// printf("%d %d\n",input[i].first,input[i].second);
pos[input[i]]=i+1;
}
int m=all_numbers.size();
/* ------离散化结束------ */
vector<int> G[m+1];
for(int i=0;i<n;i++){
G[input[i].first].push_back(input[i].second);
G[input[i].second].push_back(input[i].first);
}
int odd=0,even=0;
for(int i=1;i<=m;i++){
if(G[i].size()%2) odd++;
else even++;
}
if(odd!=2 and odd!=0){
printf("NO\n");
return ;
}
/* -----欧拉回路是否存在----- */
std::map<std::pair<int,int>,int> mp22;
std::vector<int> oul;
std::vector<int> idxx(m+1000,0);
function<void(int)> dfs = [&](int poi)-> void {
// std::cout << poi << " " << idxx[poi] << "\n";
while(idxx[poi] < (int)G[poi].size()) {
int next = G[poi][idxx[poi]];
idxx[poi] ++;
if(mp22.count({poi,next}) || mp22.count({next,poi})) {
// std::cout << "\t" << poi << " " << next << "\n";
continue;
}
mp22[{poi,next}] ++;
// std::cout << "\t" << next << "\n";
dfs(next);
}
oul.push_back(poi);
};
int start=-1;
for(int i=1;i<=m;i++){
if(G[i].size()%2==1){
start=i;
break;
}
}
if(start==-1) start=1;
// cout<<start<<endl;
dfs(start);
// for(int i=oul.size()-1;i>=0;i--){
// printf("%d ",oul[i]);
// }
// printf("\n");
vector<int> ans;
for(int i=0;i<oul.size()-1;i++){
int cur=max(pos[{oul[i],oul[i+1]}],pos[{oul[i+1],oul[i]}]);
ans.push_back(cur);
}
if(ans.size()<n){
printf("NO\n");
return ;
}
printf("YES\n");
for(int i=0;i<n;i++){
printf("%d ",ans[i]);
}
printf("\n");
}
int main()
{
int T=1;
scanf("%d",&T);
while(T--)
{
solve();
}
return 0;
}
targan缩点
#include<bits/stdc++.h>
using namespace std;
const int maxn=10000+15;
int n,m,sum,tim,top,s;
int p[maxn],head[maxn],sd[maxn],dfn[maxn],low[maxn];//DFN(u)为节点u搜索被搜索到时的次序编号(时间戳),Low(u)为u或u的子树能够追溯到的最早的栈中节点的次序号
int stac[maxn],vis[maxn];//栈只为了表示此时是否有父子关系
int h[maxn],in[maxn],dist[maxn];
struct EDGE
{
int to;int next;int from;
}edge[maxn*10],ed[maxn*10];
void add(int x,int y)
{
edge[++sum].next=head[x];
edge[sum].from=x;
edge[sum].to=y;
head[x]=sum;
}
void tarjan(int x)
{
low[x]=dfn[x]=++tim;
stac[++top]=x;vis[x]=1;
for (int i=head[x];i;i=edge[i].next)
{
int v=edge[i].to;
if (!dfn[v]) {
tarjan(v);
low[x]=min(low[x],low[v]);
}
else if (vis[v])
{
low[x]=min(low[x],low[v]);
}
}
if (dfn[x]==low[x])
{
int y;
while (y=stac[top--])
{
sd[y]=x;
vis[y]=0;
if (x==y) break;
p[x]+=p[y];
}
}
}
int topo()
{
queue <int> q;
int tot=0;
for (int i=1;i<=n;i++)
if (sd[i]==i&&!in[i])
{
q.push(i);
dist[i]=p[i];
}
while (!q.empty())
{
int k=q.front();q.pop();
for (int i=h[k];i;i=ed[i].next)
{
int v=ed[i].to;
dist[v]=max(dist[v],dist[k]+p[v]);
in[v]--;
if (in[v]==0) q.push(v);
}
}
int ans=0;
for (int i=1;i<=n;i++)
ans=max(ans,dist[i]);
return ans;
}
int main()
{
scanf("%d%d",&n,&m);
for (int i=1;i<=n;i++)
scanf("%d",&p[i]);
for (int i=1;i<=m;i++)
{
int u,v;
scanf("%d%d",&u,&v);
add(u,v);
}
for (int i=1;i<=n;i++)
if (!dfn[i]) tarjan(i);
for (int i=1;i<=m;i++)
{
int x=sd[edge[i].from],y=sd[edge[i].to];
if (x!=y)
{
ed[++s].next=h[x];
ed[s].to=y;
ed[s].from=x;
h[x]=s;
in[y]++;
}
}
printf("%d",topo());
return 0;
}
单源最短路径
给定一个 个点,
条有向边的带非负权图,请你计算从
出发,到每个点的距离。
#include<iostream>
#include<cstdio>
#include<queue>
using namespace std;
int head[100000],cnt;
long long ans[1000000];
bool vis[1000000];
int m,n,s;
struct edge{
int to;
int nextt;
int wei;
}edge[1000000];
struct priority{
int ans;
int id;
bool operator <(const priority &x)const{
return x.ans<ans;
}
};
void addedge(int x,int y,int z){
edge[++cnt].to=y;
edge[cnt].wei=z;
edge[cnt].nextt=head[x];
head[x]=cnt;
}
priority_queue<priority> q;
int main(){
cin>>m>>n>>s;
for(int i=1;i<=n;i++){
ans[i]=2147483647;
}
ans[s]=0;
for(int i=1;i<=n;i++){
int a,b,c;
cin>>a>>b>>c;
addedge(a,b,c);
}
int u;
q.push((priority){0,s});
while(!q.empty()){
priority temp=q.top();
q.pop();
u=temp.id;
if(!vis[u]){
vis[u]=1;
for(int i=head[u];i;i=edge[i].nextt){
int v=edge[i].to;
if(ans[v]>ans[u]+edge[i].wei){
ans[v]=ans[u]+edge[i].wei;
if(!vis[v]){
q.push((priority){ans[v],v});
}
}
}
}
}
for(int i=1;i<=m;i++){
cout<<ans[i]<<' ';
}
}
其实就是堆优化的dijsktra
负环
给定一个 个点的有向图,请求出图中是否存在从顶点
出发能到达的负环。
#include<cstdio>
#include<cstring>
#include<queue>
#define inf 0x3f3f3f3f
using namespace std;
const int MAXN=2010;
const int MAXM=3010;
int n,m;
int en=-1,eh[MAXN];
struct edge{
int u,v,w,next;
edge(int U=0,int V=0,int W=0,int N=0):u(U),v(V),w(W),next(N){}
};edge e[MAXM<<1];
inline void add_edge(int u,int v,int w){
e[++en]=edge(u,v,w,eh[u]);eh[u]=en;
}
void input(){
scanf("%d %d",&n,&m);
en=-1;
memset(eh,-1,sizeof(eh));
int u,v,w;
for(int i=1;i<=m;++i)
{
scanf("%d %d %d",&u,&v,&w);
add_edge(u,v,w);
if(w>=0)add_edge(v,u,w);
}
}
int dis[MAXN],cnt[MAXN];
bool vis[MAXN];
queue<int> q;
void spfa(){
fill(dis+1,dis+n+1,inf);
memset(cnt,0,sizeof(cnt));
memset(vis,0,sizeof(vis));
while(!q.empty())q.pop();
dis[1]=0;vis[1]=1;q.push(1);
int u,v,w;
while(!q.empty()){
u=q.front();vis[u]=0;q.pop();
for(int i=eh[u];i!=-1;i=e[i].next){
v=e[i].v;w=e[i].w;
if(dis[u]+w<dis[v]){
dis[v]=dis[u]+w;
if(!vis[v]){
if(++cnt[v]>=n){
//注意就是这个位置的判断。一定要保证在判vis之后,即判入队次数;而不是在判vis之前,即判松弛次数!!!
printf("YES\n");return;
}
vis[v]=1;q.push(v);
}
}
}
}
printf("NO\n");
}
int main(){
int t;
scanf("%d",&t);
for(int i=1;i<=t;++i){
input();
spfa();
}
return 0;
}
二分图
染色法判断
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
int n,m;
vector<vector<int>> mp(100010);
int color[100010];
bool dfs(int u)
{
for(auto v:mp[u])
{
if(color[v]==0)
{
color[v]=3-color[u];
if(!dfs(v)) return false;
}
else if(color[v]==color[u])
{
return false;
}
}
return true;
}
int main()
{
scanf("%d%d", &n, &m);
memset(color,0,sizeof(color));
while(m--)
{
int a,b;
scanf("%d%d", &a, &b);
mp[a].push_back(b);
mp[b].push_back(a);
}
bool flag = true;
for(int i=1;i<=n;i++)
{
if(color[i]==0)
{
color[i] = 1;
if(!dfs(i))
{
flag = false;
break;
}
}
}
if(flag) puts("Yes");
else puts("No");
return 0;
}
匈牙利算法
给定一个二分图,其中左半部包含 个点(编号
),右半部包含
个点(编号
),二分图共包含
条边。
数据保证任意一条边的两个端点都不可能在同一部分中。
请你求出二分图的最大匹配数。
二分图的匹配:给定一个二分图
,在
中的任意两条边都不依附于同一个顶点,则称
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
#include <bits/stdc++.h>
using namespace std;
void solve(){
int n,m,e;
scanf("%d%d%d",&n,&m,&e);
vector<int> G[n+m+1];
for(int i=1;i<=e;i++){
int u,v;
scanf("%d%d",&u,&v);
v+=n;
G[u].push_back(v);
G[v].push_back(u);
}
vector<int> match(n+m+1,-1);
vector<bool> vis(n+m+1);
function<bool(int)> dfs=[&](int u)->bool{
for(auto v:G[u]){
if(vis[v]) continue;
vis[v]=true;
if(match[v]==-1||dfs(match[v])){
match[u]=v;
match[v]=u;
return true;
}
}
return false;
};
int ans=0;
for(int i=1;i<=n+m;i++){
if(match[i]==-1){
fill(all(vis),false);
if(dfs(i))
ans++;
}
}
printf("%d\n",ans);
}
完美匹配(边带权)
完美匹配就是对于边带权的二分图,找到一些边集还要保证权值和最大
快速判断
Hall定理 : 对于一个二分图, 如果对于左边任意子集 , 其对应连接了右边的点集 , 都有 , 那么这 个二分图有完美匹配 (充分必要条件)
KM算法
-
前提: 基于完备匹配的, 若不一定能完美匹配需要加边加点补足
-
原理: 贪心地执行增广操作, 最开始只有值最大的边是有效边, 增广完成还不能完备匹配后新增一些边作为有效边, 而这些边用于增广会替换掉之前的权值更大的边, 所以新增的边应该是用于替换代价尽量小的边
-
具体操作: 给每个点预设一个顶标, 只有两个端点的顶标加起来等于边权的边, 我们才认为是有效边, 即
的时候才是有效边
最开始左集合的每个点的顶标为他连出去权值最大的边的权值, 右集合每个点顶标为
(可理解为找出一条损失最小的增广路). 找到之后修改顶标: 左侧所有遍历过的点减去
, 右边所有遍历过的点加上
重复找匹配 + 修改顶标的操作, 一直到找到一个完美匹配即可
-
时间复杂度
int dfs(int x)
{
visx[x] = 1;
for(int i = 1; i <= m; i++)
{
if(!visy[i] && lx[x] + ly[i] == w[x][i])
{
visy[i] = 1;
if(link[i] == -1 || dfs(link[i]))
{
link[i] = x;
return 1;
}
}
}
return 0;
}
memset(ly, 0, sizeof ly);
memset(lx, 0xf7, sizeof lx);
memset(link, -1, sizeof link);
for(int i = 1; i <= n; i++)
for(int j = 1; j <= m; j++)
lx[i] = max(w[i][j], lx[i]);
for(int i = 1; i <= n; i++)
{
while(1)
{
memset(visx, 0, sizeof visx);
memset(visy, 0, sizeof visy);
if(dfs(i)) break;
int d = 0x7f7f7f7f;
for(int j = 1; j <= n; j++)
if(visx[j])
for(int k = 1; k <= m; k++)
if(!visy[k]) d = min(d, lx[j] + ly[k] - w[j][k]);
if(d == 0x7f7f7f7f) return -1;
for(int j = 1; j <= n; j++) if(visx[j]) lx[j] -= d;
for(int j = 1; j <= m; j++) if(visy[j]) ly[j] += d;
}
}
网络流
最大流
第一行包含四个正整数 ,分别表示点的个数、有向边的个数、源点序号、汇点序号。
接下来 行每行包含三个正整数
,表示第
条有向边从
出发,到达
,边权为
(即该边最大流量为
)。
#include <bits/stdc++.h>
#define int long long
using namespace std;
const int N = 10010, M = 200010, INF = 1e15;
struct edge{
int ed;
int len;
int id;
};
vector <edge> e[N];
int n, m, S, T;
int dep[N], cur[N];
bool bfs(){
memset(dep, -1, sizeof dep);
queue <int> q;
q.push(S);
dep[S] = 0;
while (!q.empty()){
int t = q.front();
q.pop();
for (int i = 0; i < e[t].size(); i = i + 1){
int ed = e[t][i].ed;
if (dep[ed] == -1 && e[t][i].len){
dep[ed] = dep[t] + 1;
q.push(ed);
}
}
}
memset(cur, 0, sizeof(cur));
return (dep[T] != -1);
}
int dfs(int st, int limit){
if (st == T)
return limit;
for (int i = cur[st]; i < e[st].size(); i = i + 1){
cur[st] = i; // 当前弧优化
int ed = e[st][i].ed;
if (dep[ed] == dep[st] + 1 && e[st][i].len){
int t = dfs(ed, min(e[st][i].len, limit));
if (t){
e[st][i].len -= t;
e[ed][e[st][i].id].len += t;
return t;
}
else
dep[ed] = -1;
}
}
return 0;
}
int dinic(){
int r = 0, flow;
while (bfs()) while (flow = dfs(S, INF)) r += flow;
return r;
}
signed main(){
cin >> n >> m >> S >> T;
while (m -- ){
int st, ed, len;
cin >> st >> ed >> len;
int sti = e[st].size();
int edi = e[ed].size();
e[st].push_back((edge){ed, len, edi});
e[ed].push_back((edge){st, 0, sti});
}
cout << dinic();
return 0;
}
最小费用最大流
#include <cstdio>
#include <queue>
#include <cstring>
using namespace std;
const int MAXN = 5001;
const int MAXM = 50001;
int n, m, s, t, edge_sum = 1;
int maxflow, mincost;
int dis[MAXN], head[MAXN], incf[MAXN], pre[MAXN];//dis表示最短路,incf表示当前增广路上最小流量,pre表示前驱
bool vis[MAXN];
struct Edge {
int next, to, dis, flow;
}edge[MAXM << 1];
inline void addedge(int from, int to, int flow, int dis) {
edge[++edge_sum].next = head[from];
edge[edge_sum].to = to;
edge[edge_sum].dis = dis;
edge[edge_sum].flow = flow;
head[from] = edge_sum;
}
inline bool spfa() {//关于SPFA,他诈尸了
queue <int> q;
memset(dis, 0x3f, sizeof(dis));
memset(vis, 0, sizeof(vis));
q.push(s);
dis[s] = 0;
vis[s] = 1;
incf[s] = 1 << 30;
while(!q.empty()) {
int u = q.front();
vis[u] = 0;
q.pop();
for(register int i = head[u]; i; i = edge[i].next) {
if(!edge[i].flow) continue;//没有剩余流量
int v = edge[i].to;
if(dis[v] > dis[u] + edge[i].dis) {
dis[v] = dis[u] + edge[i].dis;
incf[v] = min(incf[u], edge[i].flow);//更新incf
pre[v] = i;
if(!vis[v]) vis[v] = 1, q.push(v);
}
}
}
if(dis[t] == 1061109567) return 0;
return 1;
}
inline void MCMF() {
while(spfa()) {//如果有增广路
int x = t;
maxflow += incf[t];
mincost += dis[t] * incf[t];
int i;
while(x != s) {//遍历这条增广路,正向边减流反向边加流
i = pre[x];
edge[i].flow -= incf[t];
edge[i^1].flow += incf[t];
x = edge[i^1].to;
}
}
}
signed main() {
scanf("%d%d%d%d", &n,&m,&s,&t);
for(register int u,v,w,x,i = 1; i <= m; ++i) {
scanf("%d%d%d%d",&u,&v,&w,&x);
addedge(u,v,w,x);
addedge(v,u,0,-x);//反向边费用为-f[i]
}
MCMF();//最小费用最大流
printf("%d %d\n",maxflow,mincost);
return 0;
}
计算几何
各种距离
曼哈顿距离
顾名思义,在曼哈顿街区要从一个十字路口开车到另一个十字路口,驾驶距离显然不是两点间的直线距离。这个实际驾驶距离就是“曼哈顿距离”。曼哈顿距离也称为“城市街区距离”(City Block distance)。
切比雪夫距离
国际象棋中,国王可以直行、横行、斜行,所以国王走一步可以移动到相邻8个方格中的任意一个。国王从格子(x1,y1)走到格子(x2,y2)最少需要多少步?这个距离就叫切比雪夫距离。
曼哈顿距离和切比雪夫距离的转化
- 曼哈顿距离转切比雪夫距离:在曼哈顿坐标系中的点
,转换到切比雪夫坐标系中变为
,此时曼哈顿坐标系中的曼哈顿距离等于切比雪夫坐标系中的切比雪夫距离,证明思路是将坐标系中的单位正方形进行转化。
- 切比雪夫距离转曼哈顿距离:切比雪夫坐标系中的点
,此时切比雪夫坐标系中的切比雪夫距离等于曼哈顿坐标系中的曼哈顿距离,证明方法是利用上述变换的逆变换 。
应用
在二维平面城市中有 个客户,其位置坐标为
(
),还有
个候选配送站,坐标为
(
)。快递侠移动时只能沿水平或垂直方向,两点距离用曼哈顿距离定义,即
。快递侠要从配送站中选一个,使得到最远客户的距离(到所有客户曼哈顿距离的最大值)尽可能小,要求计算出这个最小的最大距离 。
全部转为切比雪夫距离之后就很好解决了
#include <algorithm>
#include <cmath>
#include <cstdio>
#include <iostream>
using namespace std;
void solve() {
int c, h;
cin >> c >> h;
int corners[4][2];
int x, y;
cin >> x >> y;
for (int i = 0; i < 4; ++i) {
corners[i][0] = x;
corners[i][1] = y;
}
for (int i = 1; i < c; ++i) {
cin >> x >> y;
if (x + y < corners[0][0] + corners[0][1]) {
corners[0][0] = x;
corners[0][1] = y;
}
if (x + y > corners[1][0] + corners[1][1]) {
corners[1][0] = x;
corners[1][1] = y;
}
if (x - y < corners[2][0] - corners[2][1]) {
corners[2][0] = x;
corners[2][1] = y;
}
if (x - y > corners[3][0] - corners[3][1]) {
corners[3][0] = x;
corners[3][1] = y;
}
}
int ans = 0;
int min_dist = -1;
for (int i = 0; i < h; ++i) {
cin >> x >> y;
int dist = 0;
for (int j = 0; j < 4; ++j) {
dist = max(dist, abs(corners[j][0] - x) + abs(corners[j][1] - y));
}
if (dist < min_dist || min_dist == -1) {
min_dist = dist;
ans = i;
}
}
cout << min_dist << "\n";
}
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr), cout.tie(nullptr);
int T;
cin >> T;
while (T--) solve();
return 0;
}
凸包
Point p[N],s[N];
long long n;
db Andrew()
{
long long top=0;
sort(p+1,p+1+n,cmp);
for(int i=1;i<=n;i++)//求下凸包
{
while(top>1&&cross(s[top-1],s[top],p[i])<=0)top--;
s[++top]=p[i];
}
int t=top;
for(int i=n-1;i>=1;i--)//求上凸包
{
while(top>t&&cross(s[top-1],s[top],p[i])<=0)top--;
s[++top]=p[i];
}
n=top-1;//n为凸点个数,最后一个是原点,成环了
db res=0;//周长
for(int i=1;i<n;i++)
res+=dis(s[i],s[i+1]);
return res;
}
通用
#include <bits/stdc++.h>
using namespace std;
// using point_t=long long;
using point_t=long double; //全局数据类型
constexpr point_t eps=1e-8;
constexpr point_t INF=numeric_limits<point_t>::max();
constexpr long double PI=3.1415926535897932384l;
// 点与向量
template<typename T> struct point
{
T x,y;
bool operator==(const point &a) const {return (abs(x-a.x)<=eps && abs(y-a.y)<=eps);}
bool operator<(const point &a) const {if (abs(x-a.x)<=eps) return y<a.y-eps; return x<a.x-eps;}
bool operator>(const point &a) const {return !(*this<a || *this==a);}
point operator+(const point &a) const {return {x+a.x,y+a.y};}
point operator-(const point &a) const {return {x-a.x,y-a.y};}
point operator-() const {return {-x,-y};}
point operator*(const T k) const {return {k*x,k*y};}
point operator/(const T k) const {return {x/k,y/k};}
T operator*(const point &a) const {return x*a.x+y*a.y;} // 点积
T operator^(const point &a) const {return x*a.y-y*a.x;} // 叉积,注意优先级
int toleft(const point &a) const {const auto t=(*this)^a; return (t>eps)-(t<-eps);} // to-left 测试
T len2() const {return (*this)*(*this);} // 向量长度的平方
T dis2(const point &a) const {return (a-(*this)).len2();} // 两点距离的平方
// 涉及浮点数
long double len() const {return sqrtl(len2());} // 向量长度
long double dis(const point &a) const {return sqrtl(dis2(a));} // 两点距离
long double ang(const point &a) const {return acosl(max(-1.0l,min(1.0l,((*this)*a)/(len()*a.len()))));} // 向量夹角
point rot(const long double rad) const {return {x*cos(rad)-y*sin(rad),x*sin(rad)+y*cos(rad)};} // 逆时针旋转(给定角度)
point rot(const long double cosr,const long double sinr) const {return {x*cosr-y*sinr,x*sinr+y*cosr};} // 逆时针旋转(给定角度的正弦与余弦)
};
using Point=point<point_t>;
// 极角排序
struct argcmp
{
bool operator()(const Point &a,const Point &b) const
{
const auto quad=[](const Point &a)
{
if (a.y<-eps) return 1;
if (a.y>eps) return 4;
if (a.x<-eps) return 5;
if (a.x>eps) return 3;
return 2;
};
const int qa=quad(a),qb=quad(b);
if (qa!=qb) return qa<qb;
const auto t=a^b;
// if (abs(t)<=eps) return a*a<b*b-eps; // 不同长度的向量需要分开
return t>eps;
}
};
// 直线
template<typename T> struct line
{
point<T> p,v; // p 为直线上一点,v 为方向向量
bool operator==(const line &a) const {return v.toleft(a.v)==0 && v.toleft(p-a.p)==0;}
int toleft(const point<T> &a) const {return v.toleft(a-p);} // to-left 测试
bool operator<(const line &a) const // 半平面交算法定义的排序
{
if (abs(v^a.v)<=eps && v*a.v>=-eps) return toleft(a.p)==-1;
return argcmp()(v,a.v);
}
// 涉及浮点数
point<T> inter(const line &a) const {return p+v*((a.v^(p-a.p))/(v^a.v));} // 直线交点
long double dis(const point<T> &a) const {return abs(v^(a-p))/v.len();} // 点到直线距离
point<T> proj(const point<T> &a) const {return p+v*((v*(a-p))/(v*v));} // 点在直线上的投影
};
using Line=line<point_t>;
//线段
template<typename T> struct segment
{
point<T> a,b;
bool operator<(const segment &s) const {return make_pair(a,b)<make_pair(s.a,s.b);}
// 判定性函数建议在整数域使用
// 判断点是否在线段上
// -1 点在线段端点 | 0 点不在线段上 | 1 点严格在线段上
int is_on(const point<T> &p) const
{
if (p==a || p==b) return -1;
return (p-a).toleft(p-b)==0 && (p-a)*(p-b)<-eps;
}
// 判断线段直线是否相交
// -1 直线经过线段端点 | 0 线段和直线不相交 | 1 线段和直线严格相交
int is_inter(const line<T> &l) const
{
if (l.toleft(a)==0 || l.toleft(b)==0) return -1;
return l.toleft(a)!=l.toleft(b);
}
// 判断两线段是否相交
// -1 在某一线段端点处相交 | 0 两线段不相交 | 1 两线段严格相交
int is_inter(const segment<T> &s) const
{
if (is_on(s.a) || is_on(s.b) || s.is_on(a) || s.is_on(b)) return -1;
const line<T> l{a,b-a},ls{s.a,s.b-s.a};
return l.toleft(s.a)*l.toleft(s.b)==-1 && ls.toleft(a)*ls.toleft(b)==-1;
}
// 点到线段距离
long double dis(const point<T> &p) const
{
if ((p-a)*(b-a)<-eps || (p-b)*(a-b)<-eps) return min(p.dis(a),p.dis(b));
const line<T> l{a,b-a};
return l.dis(p);
}
// 两线段间距离
long double dis(const segment<T> &s) const
{
if (is_inter(s)) return 0;
return min({dis(s.a),dis(s.b),s.dis(a),s.dis(b)});
}
};
using Segment=segment<point_t>;
// 多边形
template<typename T> struct polygon
{
vector<point<T>> p; // 以逆时针顺序存储
size_t nxt(const size_t i) const {return i==p.size()-1?0:i+1;}
size_t pre(const size_t i) const {return i==0?p.size()-1:i-1;}
// 回转数
// 返回值第一项表示点是否在多边形边上
// 对于狭义多边形,回转数为 0 表示点在多边形外,否则点在多边形内
pair<bool,int> winding(const point<T> &a) const
{
int cnt=0;
for (size_t i=0;i<p.size();i++)
{
const point<T> u=p[i],v=p[nxt(i)];
if (abs((a-u)^(a-v))<=eps && (a-u)*(a-v)<=eps) return {true,0};
if (abs(u.y-v.y)<=eps) continue;
const Line uv={u,v-u};
if (u.y<v.y-eps && uv.toleft(a)<=0) continue;
if (u.y>v.y+eps && uv.toleft(a)>=0) continue;
if (u.y<a.y-eps && v.y>=a.y-eps) cnt++;
if (u.y>=a.y-eps && v.y<a.y-eps) cnt--;
}
return {false,cnt};
}
// 多边形面积的两倍
// 可用于判断点的存储顺序是顺时针或逆时针
T area() const
{
T sum=0;
for (size_t i=0;i<p.size();i++) sum+=p[i]^p[nxt(i)];
return sum;
}
// 多边形的周长
long double circ() const
{
long double sum=0;
for (size_t i=0;i<p.size();i++) sum+=p[i].dis(p[nxt(i)]);
return sum;
}
};
using Polygon=polygon<point_t>;
//凸多边形
template<typename T> struct convex: polygon<T>
{
// 闵可夫斯基和
convex operator+(const convex &c) const
{
const auto &p=this->p;
vector<Segment> e1(p.size()),e2(c.p.size()),edge(p.size()+c.p.size());
vector<point<T>> res; res.reserve(p.size()+c.p.size());
const auto cmp=[](const Segment &u,const Segment &v) {return argcmp()(u.b-u.a,v.b-v.a);};
for (size_t i=0;i<p.size();i++) e1[i]={p[i],p[this->nxt(i)]};
for (size_t i=0;i<c.p.size();i++) e2[i]={c.p[i],c.p[c.nxt(i)]};
rotate(e1.begin(),min_element(e1.begin(),e1.end(),cmp),e1.end());
rotate(e2.begin(),min_element(e2.begin(),e2.end(),cmp),e2.end());
merge(e1.begin(),e1.end(),e2.begin(),e2.end(),edge.begin(),cmp);
const auto check=[](const vector<point<T>> &res,const point<T> &u)
{
const auto back1=res.back(),back2=*prev(res.end(),2);
return (back1-back2).toleft(u-back1)==0 && (back1-back2)*(u-back1)>=-eps;
};
auto u=e1[0].a+e2[0].a;
for (const auto &v:edge)
{
while (res.size()>1 && check(res,u)) res.pop_back();
res.push_back(u);
u=u+v.b-v.a;
}
if (res.size()>1 && check(res,res[0])) res.pop_back();
return {res};
}
// 旋转卡壳
// 例:凸多边形的直径的平方
T rotcaliper() const
{
const auto &p=this->p;
if (p.size()==1) return 0;
if (p.size()==2) return p[0].dis2(p[1]);
const auto area=[](const point<T> &u,const point<T> &v,const point<T> &w){return (w-u)^(w-v);};
T ans=0;
for (size_t i=0,j=1;i<p.size();i++)
{
const auto nxti=this->nxt(i);
ans=max({ans,p[j].dis2(p[i]),p[j].dis2(p[nxti])});
while (area(p[this->nxt(j)],p[i],p[nxti])>=area(p[j],p[i],p[nxti]))
{
j=this->nxt(j);
ans=max({ans,p[j].dis2(p[i]),p[j].dis2(p[nxti])});
}
}
return ans;
}
// 判断点是否在凸多边形内
// 复杂度 O(logn)
// -1 点在多边形边上 | 0 点在多边形外 | 1 点在多边形内
int is_in(const point<T> &a) const
{
const auto &p=this->p;
if (p.size()==1) return a==p[0]?-1:0;
if (p.size()==2) return segment<T>{p[0],p[1]}.is_on(a)?-1:0;
if (a==p[0]) return -1;
if ((p[1]-p[0]).toleft(a-p[0])==-1 || (p.back()-p[0]).toleft(a-p[0])==1) return 0;
const auto cmp=[&](const point<T> &u,const point<T> &v){return (u-p[0]).toleft(v-p[0])==1;};
const size_t i=lower_bound(p.begin()+1,p.end(),a,cmp)-p.begin();
if (i==1) return segment<T>{p[0],p[i]}.is_on(a)?-1:0;
if (i==p.size()-1 && segment<T>{p[0],p[i]}.is_on(a)) return -1;
if (segment<T>{p[i-1],p[i]}.is_on(a)) return -1;
return (p[i]-p[i-1]).toleft(a-p[i-1])>0;
}
// 凸多边形关于某一方向的极点
// 复杂度 O(logn)
// 参考资料:https://codeforces.com/blog/entry/48868
template<typename F> size_t extreme(const F &dir) const
{
const auto &p=this->p;
const auto check=[&](const size_t i){return dir(p[i]).toleft(p[this->nxt(i)]-p[i])>=0;};
const auto dir0=dir(p[0]); const auto check0=check(0);
if (!check0 && check(p.size()-1)) return 0;
const auto cmp=[&](const point<T> &v)
{
const size_t vi=&v-p.data();
if (vi==0) return 1;
const auto checkv=check(vi);
const auto t=dir0.toleft(v-p[0]);
if (vi==1 && checkv==check0 && t==0) return 1;
return checkv^(checkv==check0 && t<=0);
};
return partition_point(p.begin(),p.end(),cmp)-p.begin();
}
// 过凸多边形外一点求凸多边形的切线,返回切点下标
// 复杂度 O(logn)
// 必须保证点在多边形外
pair<size_t,size_t> tangent(const point<T> &a) const
{
const size_t i=extreme([&](const point<T> &u){return u-a;});
const size_t j=extreme([&](const point<T> &u){return a-u;});
return {i,j};
}
// 求平行于给定直线的凸多边形的切线,返回切点下标
// 复杂度 O(logn)
pair<size_t,size_t> tangent(const line<T> &a) const
{
const size_t i=extreme([&](...){return a.v;});
const size_t j=extreme([&](...){return -a.v;});
return {i,j};
}
};
using Convex=convex<point_t>;
// 圆
struct Circle
{
Point c;
long double r;
bool operator==(const Circle &a) const {return c==a.c && abs(r-a.r)<=eps;}
long double circ() const {return 2*PI*r;} // 周长
long double area() const {return PI*r*r;} // 面积
// 点与圆的关系
// -1 圆上 | 0 圆外 | 1 圆内
int is_in(const Point &p) const {const long double d=p.dis(c); return abs(d-r)<=eps?-1:d<r-eps;}
// 直线与圆关系
// 0 相离 | 1 相切 | 2 相交
int relation(const Line &l) const
{
const long double d=l.dis(c);
if (d>r+eps) return 0;
if (abs(d-r)<=eps) return 1;
return 2;
}
// 圆与圆关系
// -1 相同 | 0 相离 | 1 外切 | 2 相交 | 3 内切 | 4 内含
int relation(const Circle &a) const
{
if (*this==a) return -1;
const long double d=c.dis(a.c);
if (d>r+a.r+eps) return 0;
if (abs(d-r-a.r)<=eps) return 1;
if (abs(d-abs(r-a.r))<=eps) return 3;
if (d<abs(r-a.r)-eps) return 4;
return 2;
}
// 直线与圆的交点
vector<Point> inter(const Line &l) const
{
const long double d=l.dis(c);
const Point p=l.proj(c);
const int t=relation(l);
if (t==0) return vector<Point>();
if (t==1) return vector<Point>{p};
const long double k=sqrt(r*r-d*d);
return vector<Point>{p-(l.v/l.v.len())*k,p+(l.v/l.v.len())*k};
}
// 圆与圆交点
vector<Point> inter(const Circle &a) const
{
const long double d=c.dis(a.c);
const int t=relation(a);
if (t==-1 || t==0 || t==4) return vector<Point>();
Point e=a.c-c; e=e/e.len()*r;
if (t==1 || t==3)
{
if (r*r+d*d-a.r*a.r>=-eps) return vector<Point>{c+e};
return vector<Point>{c-e};
}
const long double costh=(r*r+d*d-a.r*a.r)/(2*r*d),sinth=sqrt(1-costh*costh);
return vector<Point>{c+e.rot(costh,-sinth),c+e.rot(costh,sinth)};
}
// 圆与圆交面积
long double inter_area(const Circle &a) const
{
const long double d=c.dis(a.c);
const int t=relation(a);
if (t==-1) return area();
if (t<2) return 0;
if (t>2) return min(area(),a.area());
const long double costh1=(r*r+d*d-a.r*a.r)/(2*r*d),costh2=(a.r*a.r+d*d-r*r)/(2*a.r*d);
const long double sinth1=sqrt(1-costh1*costh1),sinth2=sqrt(1-costh2*costh2);
const long double th1=acos(costh1),th2=acos(costh2);
return r*r*(th1-costh1*sinth1)+a.r*a.r*(th2-costh2*sinth2);
}
// 过圆外一点圆的切线
vector<Line> tangent(const Point &a) const
{
const int t=is_in(a);
if (t==1) return vector<Line>();
if (t==-1)
{
const Point v={-(a-c).y,(a-c).x};
return vector<Line>{{a,v}};
}
Point e=a-c; e=e/e.len()*r;
const long double costh=r/c.dis(a),sinth=sqrt(1-costh*costh);
const Point t1=c+e.rot(costh,-sinth),t2=c+e.rot(costh,sinth);
return vector<Line>{{a,t1-a},{a,t2-a}};
}
// 两圆的公切线
vector<Line> tangent(const Circle &a) const
{
const int t=relation(a);
vector<Line> lines;
if (t==-1 || t==4) return lines;
if (t==1 || t==3)
{
const Point p=inter(a)[0],v={-(a.c-c).y,(a.c-c).x};
lines.push_back({p,v});
}
const long double d=c.dis(a.c);
const Point e=(a.c-c)/(a.c-c).len();
if (t<=2)
{
const long double costh=(r-a.r)/d,sinth=sqrt(1-costh*costh);
const Point d1=e.rot(costh,-sinth),d2=e.rot(costh,sinth);
const Point u1=c+d1*r,u2=c+d2*r,v1=a.c+d1*a.r,v2=a.c+d2*a.r;
lines.push_back({u1,v1-u1}); lines.push_back({u2,v2-u2});
}
if (t==0)
{
const long double costh=(r+a.r)/d,sinth=sqrt(1-costh*costh);
const Point d1=e.rot(costh,-sinth),d2=e.rot(costh,sinth);
const Point u1=c+d1*r,u2=c+d2*r,v1=a.c-d1*a.r,v2=a.c-d2*a.r;
lines.push_back({u1,v1-u1}); lines.push_back({u2,v2-u2});
}
return lines;
}
// 圆的反演
tuple<int,Circle,Line> inverse(const Line &l) const
{
const Circle null_c={{0.0,0.0},0.0};
const Line null_l={{0.0,0.0},{0.0,0.0}};
if (l.toleft(c)==0) return {2,null_c,l};
const Point v=l.toleft(c)==1?Point{l.v.y,-l.v.x}:Point{-l.v.y,l.v.x};
const long double d=r*r/l.dis(c);
const Point p=c+v/v.len()*d;
return {1,{(c+p)/2,d/2},null_l};
}
tuple<int,Circle,Line> inverse(const Circle &a) const
{
const Circle null_c={{0.0,0.0},0.0};
const Line null_l={{0.0,0.0},{0.0,0.0}};
const Point v=a.c-c;
if (a.is_in(c)==-1)
{
const long double d=r*r/(a.r+a.r);
const Point p=c+v/v.len()*d;
return {2,null_c,{p,{-v.y,v.x}}};
}
if (c==a.c) return {1,{c,r*r/a.r},null_l};
const long double d1=r*r/(c.dis(a.c)-a.r),d2=r*r/(c.dis(a.c)+a.r);
const Point p=c+v/v.len()*d1,q=c+v/v.len()*d2;
return {1,{(p+q)/2,p.dis(q)/2},null_l};
}
};
// 圆与多边形面积交
long double area_inter(const Circle &circ,const Polygon &poly)
{
const auto cal=[](const Circle &circ,const Point &a,const Point &b)
{
if ((a-circ.c).toleft(b-circ.c)==0) return 0.0l;
const auto ina=circ.is_in(a),inb=circ.is_in(b);
const Line ab={a,b-a};
if (ina && inb) return ((a-circ.c)^(b-circ.c))/2;
if (ina && !inb)
{
const auto t=circ.inter(ab);
const Point p=t.size()==1?t[0]:t[1];
const long double ans=((a-circ.c)^(p-circ.c))/2;
const long double th=(p-circ.c).ang(b-circ.c);
const long double d=circ.r*circ.r*th/2;
if ((a-circ.c).toleft(b-circ.c)==1) return ans+d;
return ans-d;
}
if (!ina && inb)
{
const Point p=circ.inter(ab)[0];
const long double ans=((p-circ.c)^(b-circ.c))/2;
const long double th=(a-circ.c).ang(p-circ.c);
const long double d=circ.r*circ.r*th/2;
if ((a-circ.c).toleft(b-circ.c)==1) return ans+d;
return ans-d;
}
const auto p=circ.inter(ab);
if (p.size()==2 && Segment{a,b}.dis(circ.c)<=circ.r+eps)
{
const long double ans=((p[0]-circ.c)^(p[1]-circ.c))/2;
const long double th1=(a-circ.c).ang(p[0]-circ.c),th2=(b-circ.c).ang(p[1]-circ.c);
const long double d1=circ.r*circ.r*th1/2,d2=circ.r*circ.r*th2/2;
if ((a-circ.c).toleft(b-circ.c)==1) return ans+d1+d2;
return ans-d1-d2;
}
const long double th=(a-circ.c).ang(b-circ.c);
if ((a-circ.c).toleft(b-circ.c)==1) return circ.r*circ.r*th/2;
return -circ.r*circ.r*th/2;
};
long double ans=0;
for (size_t i=0;i<poly.p.size();i++)
{
const Point a=poly.p[i],b=poly.p[poly.nxt(i)];
ans+=cal(circ,a,b);
}
return ans;
}
// 点集的凸包
// Andrew 算法,复杂度 O(nlogn)
Convex convexhull(vector<Point> p)
{
vector<Point> st;
if (p.empty()) return Convex{st};
sort(p.begin(),p.end());
const auto check=[](const vector<Point> &st,const Point &u)
{
const auto back1=st.back(),back2=*prev(st.end(),2);
return (back1-back2).toleft(u-back1)<=0;
};
for (const Point &u:p)
{
while (st.size()>1 && check(st,u)) st.pop_back();
st.push_back(u);
}
size_t k=st.size();
p.pop_back(); reverse(p.begin(),p.end());
for (const Point &u:p)
{
while (st.size()>k && check(st,u)) st.pop_back();
st.push_back(u);
}
st.pop_back();
return Convex{st};
}
// 半平面交
// 排序增量法,复杂度 O(nlogn)
// 输入与返回值都是用直线表示的半平面集合
vector<Line> halfinter(vector<Line> l, const point_t lim=1e9)
{
const auto check=[](const Line &a,const Line &b,const Line &c){return a.toleft(b.inter(c))<0;};
// 无精度误差的方法,但注意取值范围会扩大到三次方
/*const auto check=[](const Line &a,const Line &b,const Line &c)
{
const Point p=a.v*(b.v^c.v),q=b.p*(b.v^c.v)+b.v*(c.v^(b.p-c.p))-a.p*(b.v^c.v);
return p.toleft(q)<0;
};*/
l.push_back({{-lim,0},{0,-1}}); l.push_back({{0,-lim},{1,0}});
l.push_back({{lim,0},{0,1}}); l.push_back({{0,lim},{-1,0}});
sort(l.begin(),l.end());
deque<Line> q;
for (size_t i=0;i<l.size();i++)
{
if (i>0 && l[i-1].v.toleft(l[i].v)==0 && l[i-1].v*l[i].v>eps) continue;
while (q.size()>1 && check(l[i],q.back(),q[q.size()-2])) q.pop_back();
while (q.size()>1 && check(l[i],q[0],q[1])) q.pop_front();
if (!q.empty() && q.back().v.toleft(l[i].v)<=0) return vector<Line>();
q.push_back(l[i]);
}
while (q.size()>1 && check(q[0],q.back(),q[q.size()-2])) q.pop_back();
while (q.size()>1 && check(q.back(),q[0],q[1])) q.pop_front();
return vector<Line>(q.begin(),q.end());
}
// 点集形成的最小最大三角形
// 极角序扫描线,复杂度 O(n^2logn)
// 最大三角形问题可以使用凸包与旋转卡壳做到 O(n^2)
pair<point_t,point_t> minmax_triangle(const vector<Point> &vec)
{
if (vec.size()<=2) return {0,0};
vector<pair<int,int>> evt;
evt.reserve(vec.size()*vec.size());
point_t maxans=0,minans=INF;
for (size_t i=0;i<vec.size();i++)
{
for (size_t j=0;j<vec.size();j++)
{
if (i==j) continue;
if (vec[i]==vec[j]) minans=0;
else evt.push_back({i,j});
}
}
sort(evt.begin(),evt.end(),[&](const pair<int,int> &u,const pair<int,int> &v)
{
const Point du=vec[u.second]-vec[u.first],dv=vec[v.second]-vec[v.first];
return argcmp()({du.y,-du.x},{dv.y,-dv.x});
});
vector<size_t> vx(vec.size()),pos(vec.size());
for (size_t i=0;i<vec.size();i++) vx[i]=i;
sort(vx.begin(),vx.end(),[&](int x,int y){return vec[x]<vec[y];});
for (size_t i=0;i<vx.size();i++) pos[vx[i]]=i;
for (auto [u,v]:evt)
{
const size_t i=pos[u],j=pos[v];
const size_t l=min(i,j),r=max(i,j);
const Point vecu=vec[u],vecv=vec[v];
if (l>0) minans=min(minans,abs((vec[vx[l-1]]-vecu)^(vec[vx[l-1]]-vecv)));
if (r<vx.size()-1) minans=min(minans,abs((vec[vx[r+1]]-vecu)^(vec[vx[r+1]]-vecv)));
maxans=max({maxans,abs((vec[vx[0]]-vecu)^(vec[vx[0]]-vecv)),abs((vec[vx.back()]-vecu)^(vec[vx.back()]-vecv))});
if (i<j) swap(vx[i],vx[j]),pos[u]=j,pos[v]=i;
}
return {minans,maxans};
}
// 平面最近点对
// 扫描线,复杂度 O(nlogn)
point_t closest_pair(vector<Point> points)
{
sort(points.begin(),points.end());
const auto cmpy=[](const Point &a,const Point &b){if (abs(a.y-b.y)<=eps) return a.x<b.x-eps; return a.y<b.y-eps;};
multiset<Point,decltype(cmpy)> s{cmpy};
point_t ans=INF;
for (size_t i=0,l=0;i<points.size();i++)
{
const point_t sqans=sqrtl(ans)+1; // 整数情况
// const point_t sqans=sqrtl(ans)+1; // 浮点数情况
while (l<i && points[i].x-points[l].x>=sqans) s.erase(s.find(points[l++]));
for (auto it=s.lower_bound(Point{-INF,points[i].y-sqans});it!=s.end()&&it->y-points[i].y<=sqans;it++)
{
ans=min(ans,points[i].dis2(*it));
}
s.insert(points[i]);
}
return ans;
}
// 判断多条线段是否有交点
// 扫描线,复杂度 O(nlogn)
bool segs_inter(const vector<Segment> &segs)
{
if (segs.empty()) return false;
using seq_t=tuple<point_t,int,Segment>;
const auto seqcmp=[](const seq_t &u, const seq_t &v)
{
const auto [u0,u1,u2]=u;
const auto [v0,v1,v2]=v;
if (abs(u0-v0)<=eps) return make_pair(u1,u2)<make_pair(v1,v2);
return u0<v0-eps;
};
vector<seq_t> seq;
for (auto seg:segs)
{
if (seg.a.x>seg.b.x+eps) swap(seg.a,seg.b);
seq.push_back({seg.a.x,0,seg});
seq.push_back({seg.b.x,1,seg});
}
sort(seq.begin(),seq.end(),seqcmp);
point_t x_now;
auto cmp=[&](const Segment &u, const Segment &v)
{
if (abs(u.a.x-u.b.x)<=eps || abs(v.a.x-v.b.x)<=eps) return u.a.y<v.a.y-eps;
return ((x_now-u.a.x)*(u.b.y-u.a.y)+u.a.y*(u.b.x-u.a.x))*(v.b.x-v.a.x)<((x_now-v.a.x)*(v.b.y-v.a.y)+v.a.y*(v.b.x-v.a.x))*(u.b.x-u.a.x)-eps;
};
multiset<Segment,decltype(cmp)> s{cmp};
for (const auto [x,o,seg]:seq)
{
x_now=x;
const auto it=s.lower_bound(seg);
if (o==0)
{
if (it!=s.end() && seg.is_inter(*it)) return true;
if (it!=s.begin() && seg.is_inter(*prev(it))) return true;
s.insert(seg);
}
else
{
if (next(it)!=s.end() && it!=s.begin() && (*prev(it)).is_inter(*next(it))) return true;
s.erase(it);
}
}
return false;
}
// 多边形面积并
// 轮廓积分,复杂度 O(n^2logn),n为边数
// ans[i] 表示被至少覆盖了 i+1 次的区域的面积
vector<long double> area_union(const vector<Polygon> &polys)
{
const size_t siz=polys.size();
vector<vector<pair<Point,Point>>> segs(siz);
const auto check=[](const Point &u,const Segment &e){return !((u<e.a && u<e.b) || (u>e.a && u>e.b));};
auto cut_edge=[&](const Segment &e,const size_t i)
{
const Line le{e.a,e.b-e.a};
vector<pair<Point,int>> evt;
evt.push_back({e.a,0}); evt.push_back({e.b,0});
for (size_t j=0;j<polys.size();j++)
{
if (i==j) continue;
const auto &pj=polys[j];
for (size_t k=0;k<pj.p.size();k++)
{
const Segment s={pj.p[k],pj.p[pj.nxt(k)]};
if (le.toleft(s.a)==0 && le.toleft(s.b)==0)
{
evt.push_back({s.a,0});
evt.push_back({s.b,0});
}
else if (s.is_inter(le))
{
const Line ls{s.a,s.b-s.a};
const Point u=le.inter(ls);
if (le.toleft(s.a)<0 && le.toleft(s.b)>=0) evt.push_back({u,-1});
else if (le.toleft(s.a)>=0 && le.toleft(s.b)<0) evt.push_back({u,1});
}
}
}
sort(evt.begin(),evt.end());
if (e.a>e.b) reverse(evt.begin(),evt.end());
int sum=0;
for (size_t i=0;i<evt.size();i++)
{
sum+=evt[i].second;
const Point u=evt[i].first,v=evt[i+1].first;
if (!(u==v) && check(u,e) && check(v,e)) segs[sum].push_back({u,v});
if (v==e.b) break;
}
};
for (size_t i=0;i<polys.size();i++)
{
const auto &pi=polys[i];
for (size_t k=0;k<pi.p.size();k++)
{
const Segment ei={pi.p[k],pi.p[pi.nxt(k)]};
cut_edge(ei,i);
}
}
vector<long double> ans(siz);
for (size_t i=0;i<siz;i++)
{
long double sum=0;
sort(segs[i].begin(),segs[i].end());
int cnt=0;
for (size_t j=0;j<segs[i].size();j++)
{
if (j>0 && segs[i][j]==segs[i][j-1]) segs[i+(++cnt)].push_back(segs[i][j]);
else cnt=0,sum+=segs[i][j].first^segs[i][j].second;
}
ans[i]=sum/2;
}
return ans;
}
// 圆面积并
// 轮廓积分,复杂度 O(n^2logn)
// ans[i] 表示被至少覆盖了 i+1 次的区域的面积
vector<long double> area_union(const vector<Circle> &circs)
{
const size_t siz=circs.size();
using arc_t=tuple<Point,long double,long double,long double>;
vector<vector<arc_t>> arcs(siz);
const auto eq=[](const arc_t &u,const arc_t &v)
{
const auto [u1,u2,u3,u4]=u;
const auto [v1,v2,v3,v4]=v;
return u1==v1 && abs(u2-v2)<=eps && abs(u3-v3)<=eps && abs(u4-v4)<=eps;
};
auto cut_circ=[&](const Circle &ci,const size_t i)
{
vector<pair<long double,int>> evt;
evt.push_back({-PI,0}); evt.push_back({PI,0});
int init=0;
for (size_t j=0;j<circs.size();j++)
{
if (i==j) continue;
const Circle &cj=circs[j];
if (ci.r<cj.r-eps && ci.relation(cj)>=3) init++;
const auto inters=ci.inter(cj);
if (inters.size()==1) evt.push_back({atan2l((inters[0]-ci.c).y,(inters[0]-ci.c).x),0});
if (inters.size()==2)
{
const Point dl=inters[0]-ci.c,dr=inters[1]-ci.c;
long double argl=atan2l(dl.y,dl.x),argr=atan2l(dr.y,dr.x);
if (abs(argl+PI)<=eps) argl=PI;
if (abs(argr+PI)<=eps) argr=PI;
if (argl>argr+eps)
{
evt.push_back({argl,1}); evt.push_back({PI,-1});
evt.push_back({-PI,1}); evt.push_back({argr,-1});
}
else
{
evt.push_back({argl,1});
evt.push_back({argr,-1});
}
}
}
sort(evt.begin(),evt.end());
int sum=init;
for (size_t i=0;i<evt.size();i++)
{
sum+=evt[i].second;
if (abs(evt[i].first-evt[i+1].first)>eps) arcs[sum].push_back({ci.c,ci.r,evt[i].first,evt[i+1].first});
if (abs(evt[i+1].first-PI)<=eps) break;
}
};
const auto oint=[](const arc_t &arc)
{
const auto [cc,cr,l,r]=arc;
if (abs(r-l-PI-PI)<=eps) return 2.0l*PI*cr*cr;
return cr*cr*(r-l)+cc.x*cr*(sin(r)-sin(l))-cc.y*cr*(cos(r)-cos(l));
};
for (size_t i=0;i<circs.size();i++)
{
const auto &ci=circs[i];
cut_circ(ci,i);
}
vector<long double> ans(siz);
for (size_t i=0;i<siz;i++)
{
long double sum=0;
sort(arcs[i].begin(),arcs[i].end());
int cnt=0;
for (size_t j=0;j<arcs[i].size();j++)
{
if (j>0 && eq(arcs[i][j],arcs[i][j-1])) arcs[i+(++cnt)].push_back(arcs[i][j]);
else cnt=0,sum+=oint(arcs[i][j]);
}
ans[i]=sum/2;
}
return ans;
}
# include <cstdio>
# include <cstring>
# include <cmath>
# include <vector>
# include <algorithm>
using namespace std;
# define mp make_pair
//挂
namespace io {
const int L=(1<<21)+1;
char ibuf[L],*iS,*iT,obuf[L],*oS=obuf,*oT=obuf+L-1,c,st[55];int f,tp;
#define gc() (iS==iT?(iT=(iS=ibuf)+fread(ibuf,1,L,stdin),(iS==iT?EOF:*iS++)):*iS++)
inline void flush() {
fwrite(obuf,1,oS-obuf,stdout);
oS=obuf;
}
inline void putc(char x) { *oS++=x; if (oS==oT) flush(); }
template<class I> inline void gi(I&x) {
for (f=1,c=gc();c<'0'||c>'9';c=gc()) if (c=='-') f=-1;
for (x=0;c<='9'&&c>='0';c=gc()) x=x*10+(c&15); x*=f;
}
template<class I> inline void print(I x) {
if (!x) putc('0');
if (x<0) putc('-'),x=-x;
while (x) st[++tp]=x%10+'0',x/=10;
while (tp) putc(st[tp--]);
}
inline void gs(char*s, int&l) {
for (c=gc();c<'a'||c>'z';c=gc());
for (l=0;c<='z'&&c>='a';c=gc()) s[l++]=c;
s[l]=0;
}
inline void ps(const char*s) { for (int i=0,n=strlen(s);i<n;i++) putc(s[i]); }
struct IOFLUSHER{ ~IOFLUSHER() { flush(); } } _ioflusher_;
};
using io::putc;
using io::gi;
using io::gs;
using io::ps;
using io::print;
//
/*
说明:所有角度为弧度制(对应math函数)
*/
//定义+极小量
typedef double db;
#define dbformat "%lf"
const db eps=1e-8;
//判断正负0 (有点精妙)
inline int dcmp(const db &x) { return (x>eps)-(x<-eps); }
inline db sqr(db x){ return x * x; }
//构造二维坐标点变量
struct P{
db x,y;
inline db mo2() { return x*x+y*y; }//模平方
inline db mo() { return sqrt(mo2()); }//模
inline db angle() { return atan2(y,x); }//稳定地(相对于atan)计算方位角(范围-pai到pai)
inline void readint() { gi(x),gi(y); }//整数输入(不一定是int)
inline void readdb() { scanf(dbformat dbformat,&x,&y); }//分数输入
inline P rot90() { return (P){-y,x}; }//逆时针旋转90度
inline P rot(db r) {//旋转矩阵法计算逆时针旋转r度坐标
db Sin=sin(r),Cos=cos(r);
return (P){x*Cos-y*Sin,x*Sin+y*Cos};
}
inline void uni() {//向量单位化
db d=mo();
if (dcmp(d))
x/=d,y/=d;
}
};
//定义各种运算和比较
inline bool operator < (const P &a,const P &b) { return dcmp(a.x-b.x)?a.x<b.x:a.y<b.y; }//先x后y
inline bool operator == (const P &a,const P&b) { return !dcmp(a.x-b.x)&&!dcmp(a.y-b.y); }//x与y相差不到eps
inline bool operator != (const P &a,const P &b) { return dcmp(a.x-b.x)||dcmp(a.y-b.y); }//前一个取反
inline P operator + (const P &a,const P &b) { return (P){a.x+b.x,a.y+b.y}; }//向量相加
inline P operator - (const P &a,const P &b) { return (P){a.x-b.x,a.y-b.y}; }//向量相减
inline P operator * (const P &p,const db &t) { return (P){p.x*t,p.y*t}; }//数乘
inline P operator / (const P &p,const db &t) { return (P){p.x/t,p.y/t}; }//数除
inline db operator * (const P &a,const P &b) { return a.x*b.y-a.y*b.x; }//叉积(a * b = a.mo() * b.mo() * sin(b.angle() - a.angle()))
inline db dot(const P &a,const P&b) { return a.x*b.x+a.y*b.y; }//点积(dot(a , b) = a.mo() * b.mo() * cos(b.angle() - a.angle()))
//点积的夹角可以认为是小于180度的cos正值,然而叉积的必须严格从a向b(因为可能有正负问题)
//垂直时,点积为0,平行或共线时,叉积为0
inline db dis_point2(const P &a,const P &b) { return (a-b).mo2(); }//距离平方
inline db dis_point(const P &a,const P &b) { return (a-b).mo(); }//距离
//向量变量(两点决定,有方向问题(计算角时))固定向量非自由向量
struct line{
P a,b;
inline db angle() { return (b-a).angle(); }//计算角度
};
//这里开始复杂了一点,作者应该是记录了注释,然而因为现实问题全成了乱码 ,我保留了tm,作为重要的标志(就连作者都留下了注释)
//判断是否在向量所在直线
inline bool in_point_line(const P &p,const line &l) {//?е????????
return dcmp((p-l.a)*(l.b-l.a))==0;
}
//判断点是否处于向量所在直线或者向量所指方向的左侧
inline bool in_halfplane(const P &p,const line &l) {//?е?????????
return (p-l.a)*(l.b-l.a)<=eps;
}
//判断是否处于向量内部(包含首尾端点)
inline bool in_point_segment(const P &p,const line &l) {//?е????????
return in_point_line(p,l)&&dcmp(dot(p-l.a,l.b-l.a))>=0&&dcmp(dot(p-l.b,l.a-l.b))>=0;
}
//点到直线垂直距离
inline db dis_point_line(const P &p,const line &l) {//????????
return fabs((p-l.a)*(l.b-l.a))/dis_point(l.a,l.b);
}
//判断是否相交
inline bool cross_segment_segment(const line &a,const line &b) {//?ж???????????
return dcmp((b.a-a.a)*(a.b-a.a))*dcmp((b.b-a.a)*(a.b-a.a))!=1&&
dcmp((a.a-b.a)*(b.b-b.a))*dcmp((a.b-b.a)*(b.b-b.a))!=1;
}
//计算交点
inline P cross_line_line(const line &a,const line &b) {//??????
db s1=(b.a-a.a)*(a.b-a.a);
db s2=(a.b-a.a)*(b.b-a.a);
return b.a+(b.b-b.a)*(s1/(s1+s2));
}
//计算点到一条固定向量上点的最小距离
inline db dis_point_segment(const P &p,const line &l) {//????ξ???
if (dot(p-l.a,l.b-l.a)<=0) return dis_point(p,l.a);
if (dot(p-l.b,l.a-l.b)<=0) return dis_point(p,l.b);
return dis_point_line(p,l);
}
//计算两固定向量上点最短距离
inline db dis_segment_segment(const line &a,const line &b) {//???????ξ???
if (cross_segment_segment(a,b))
return 0;
return min(min(dis_point_segment(a.a,b),dis_point_segment(a.b,b))
,min(dis_point_segment(b.a,a),dis_point_segment(b.b,a)));
}
//点到直线垂线与直线的交点
inline P proj_point_line(const P &p,const line &l) {//????????????
return l.a+(l.b-l.a)*(dot(p-l.a,l.b-l.a)/dis_point2(l.b,l.a));
}
//定义圆变量
struct circle{ P o; db r; };
//点与圆,正在圆外,0上,负内
inline int in_point_cirlce(const P &p,const circle &c) {//???????λ?? 1:?? 0:??? -1:???
return dcmp(dis_point(p,c.o)-c.r);
}
//线与圆,正与圆相离,0相切,负相交
inline int in_line_circle(const line &l,const circle &c) {//????????λ?? 1:???? 0:???? -1:??
return dcmp(dis_point_line(c.o,l)-c.r);
}
//圆与圆关系(a半径更大b半径更小,如果不满足会交换)???(原模板出错了,修改了一下)
//两个判别值(ar-br , ar + br)
// 0<ar - br 1==ar - br 2<ar+br 3==ar + br 4>ar + br
// 内含 内切 相交 外切 相离
inline int in_circle_circle(const circle &a,const circle &b) {//?????λ?ù????
//0:??? 1:???? 2:?? 3:???? 4:????
if (a.r<b.r) return in_circle_circle(b,a);
db dis=dis_point(a.o,b.o);
if (dcmp(dis-(a.r+b.r))>=0) return dcmp(dis-(a.r+b.r))+3;
return dcmp(dis+b.r-a.r)+1;
}
//求直线与圆两个交点
inline pair<P,P> cross_line_circle(const line &l,const circle &c) {//????????????
P o=proj_point_line(c.o,l);
P d=(l.b-l.a);d.uni();
db len=sqrt(c.r*c.r-dis_point2(c.o,o));
d=d*len;
return mp(o-d,o+d);
}
//求圆与圆的交点(用到余弦定理)
inline pair<P,P> cross_circle_circle(const circle &a,const circle &b) {//??????????
db len=dis_point2(a.o,b.o);
db t=a.r*a.r+len-b.r*b.r;
P e=a.o+(b.o-a.o)*(t/2/len);
db p=sqrt(a.r*a.r-dis_point2(a.o,e));//???又错了(已修改)
P d=(b.o-a.o).rot90()*(p/sqrt(len));
return mp(e+d,e-d);
}
//求点与圆切点 (用到了射影定理)
inline pair<P,P> proj_point_circle(P p,const circle &c) {//???????е?
db dis2=dis_point2(p,c.o);
db h=c.r*c.r*(dis2-c.r*c.r)/dis2;
db w=sqrt(c.r*c.r-h);h=sqrt(h);
p=p-c.o;p.uni();
return mp(c.o+p*w+p.rot90()*h,c.o+p*w-p.rot90()*h);
}
//后头两个感觉没什么用,懒得检查了
//相离(或外切内切相交)两圆外公切线 (类平行)
inline pair<line,line> proj_circle_circle_out(const circle &a,const circle &b) {//???????????????
if (!dcmp(a.r-b.r)) {
P p=(b.o-a.o).rot90();p.uni();
return mp((line){a.o+p*a.r,b.o+p*b.r},(line){a.o-p*a.r,b.o-p*b.r});
}
if (a.r<b.r)
return proj_circle_circle_out(b,a);
pair<P,P>p=proj_point_circle(b.o,(circle){a.o,a.r-b.r});
P d1=(p.first-a.o)*(b.r/(a.r-b.r));
P d2=(p.second-a.o)*(b.r/(a.r-b.r));
return mp((line){p.first+d1,b.o+d1},(line){p.first+d2,b.o+d2});
}
//相离(或外切)两圆内公切线(交叉)
inline pair<line,line> proj_circle_circle_in(const circle &a,const circle &b) {//????????????????
if (a.r<b.r)
return proj_circle_circle_in(b,a);
pair<P,P>p=proj_point_circle(b.o,(circle){a.o,a.r+b.r});
P d1=(p.first-a.o)*(b.r/(a.r+b.r));
P d2=(p.first-a.o)*(b.r/(a.r+b.r));
return mp((line){p.first-d1,b.o-d1},(line){p.second-d2,b.o-d2});
}
//自行脑补部分
const long double pai = acos(-1);
//三角形
struct tri
{
P a, b, c;
};
//三角形有向面积(带正负)向量ca叉cb
inline db tri_s(tri x)
{
return 0.5 * ((x.a - x.c) * (x.b - x.c));
}
//重载类型
inline db tri_s(P a , P b , P c)
{
return 0.5 * ((a - c) * (b - c));
}
//三角形面积
inline db tri_as(tri x)
{
return 0.5 * fabs((x.a - x.c) * (x.b - x.c));
}
//重载类型
inline db tri_as(P a , P b , P c)
{
return 0.5 * fabs((a - c) * (b - c));
}
//两向量夹角(有向a到b , 范围-pai到pai)
inline db ang(P a , P b)
{
db xita = pai + b.angle() - a.angle();
if(dcmp(xita - pai) > 0)
xita -= 2 * pai;
return xita;
}
//绝对值的那个角
inline db a_ang(P a , P b)
{
return fabs(ang(P a , P b));
}
//三角形顶点为C时与圆相交时的面积
inline db Triangle_cross_Circle(P A , P B , P C, db r){
db a, b, c, x, y;
db s = tri_s(A , B , C);
a = (B-C).mo();
b = (A-C).mo();
c = (A-B).mo();
if (a <= r && b <= r) return s;
else if (a<r && b>=r) {
x = (dot(A-B,C-B) + sqrt(c*c*r*r - sqr((A-B)*(C-B))))/c;
return asin(s*(c-x)*2.0/c/b/r)*r*r*0.5 + s*x/c;
}
else if (a >= r && b<r) {
y = (dot(B-A,C-A) + sqrt(c*c*r*r - sqr((B-A) * (C-A))))/c;
return asin(s*(c-y)*2.0/c/a/r)*r*r*0.5 + s*y/c;
}
else {
if (dcmp(fabs(2.0*s) - r*c) >= 0 || dot(B-A,C-A) <= 0 || dot(A-B,C-B) <= 0) {
if (dot(A-C,B-C) < 0) {
if ((A-C) * (B-C) < 0) return (-pai - asin(s*2.0/a/b))*r*r*0.5;
else return (pai - asin(s*2.0/a/b))*r*r*0.5;
}
else return asin(s*2.0/a/b)*r*r*0.5;
}
else {
x = (dot(A-B,C-B) + sqrt(c*c*r*r - sqr((A-B) * (C-B))))/c;
y = (dot(B-A,C-A) + sqrt(c*c*r*r - sqr((B-A) * (C-A))))/c;
return (asin(s*(1-x/c)*2/r/b) + asin(s*(1-y/c)*2/r/a))*r*r*0.5 + s*((y+x)/c-1);
}
}
}
//计算多边形面积
inline db duobian_s(vector<P> &X)
{
int i, siz = X.size();
db ans = 0;
for(i = 0 ; i < siz ; i++)
ans += X[i] * X[(i + 1) % siz];
return 0.5 * fabs(ans);
}
//终极杀器,多边形与圆重合面积
inline db duobian_circle_s(vector<P> &X , circle c)
{
int i, siz = X.size();
db ans = 0;
for (i = 0 ; i < siz ; i++)
res += Triangle_cross_Circle(X[i] , X[(i + 1) % siz] , c.o , c.r);
return fabs(ans);
}
