ARM/Linux嵌入式面经(八):OPPO三面
OPPO三面
一面(4.2,20min)
# 1.自我介绍
# 2.三个项目,问的很详细
后面专门会出一版怎么做自我介绍,以及项目怎么写,会怎么问,你该怎么回答。
3.SPI是什么?有几条线?几种模式?
SPI协议简介
板卡内不同芯片间通讯最常用的三种串行协议:UART、I2C、SPI,之前写过串口协议及其FPGA实现,今天我们来介绍SPI协议,SPI是Serial Perripheral Interface的简称,是由Motorola公司推出的一种高速、全双工的总线协议。
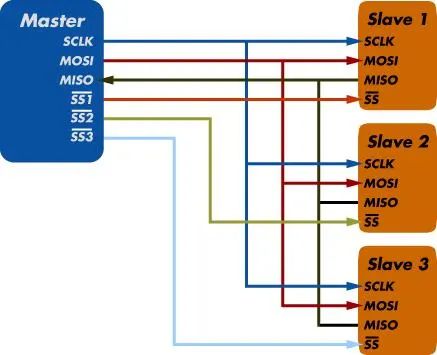
与IIC类似,SPI也是采用主从方式工作,主机通常为FPGA、MCU或DSP等可编程控制器,从机通常为EPROM、Flash,AD/DA,音视频处理芯片等设备。
一般由SCLK、CS、MOSI,MISO四根线组成,有的地方可能是:SCK、SS、SDI、SDO等名称,都是一样的含义,当有多个从机存在时,通过CS来选择要控制的从机设备。
和标准SPI类似的协议,还有TI的SSP协议,区别主要在片选信号的时序上。
-
4线还是3线? 当我们谈到SPI时,默认情况下都是指标准的4线制Motorola SPI协议,即SCLK,MOSI,MISO和CS共4根数据线,标准4线制的好处是可以实现数据的全双工传输。当只有一个主机和一个从机设备时,只需要一个CS,多个从机需要多个CS,各数据线的介绍:
-
SCLK,时钟信号,时钟频率即SPI速率,和SPI模式有关
-
MOSI,主机输出,从机输入
-
MISO,主机输入,从机输出
-
CS,从机设备选择,低电平有效
3线制SPI,根据不同的应用场景,主要有以下2种类型:
- 只有3根线:SCLK,CS和DI或DO,适用于单工通讯,主机只发送或接收数据。
- 只有3根线:SCLK,SDIO和CS,这里的SDIO作为双向端口,适用于半双工通讯,比如ADI的多款ADC芯片都支持双向传输。在使用FPGA操作双向端口时,作为输入时要设置为高阻态z。
4种工作模式
既然是进行数据传输,双方就要明确从机在什么时刻去采样主机发出的数据,主机在什么时刻去读取从机发来的数据。
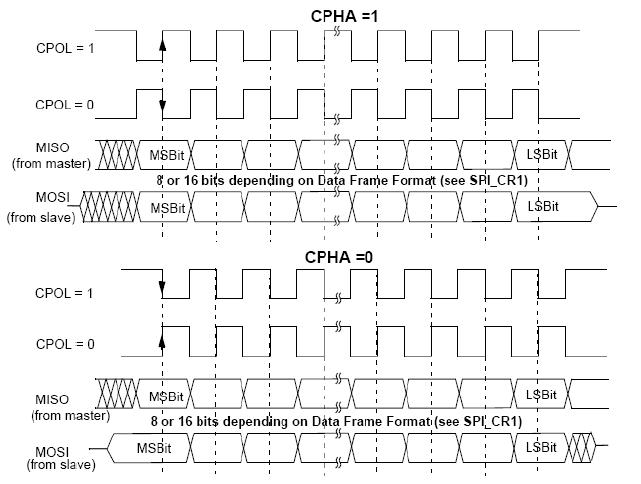
对于STM32等MCU自带的硬件SPI外设来说,可能没有那么重要,只需要配置一下模式就行了,但是对于使用使用GPIO模拟或者FPGA来实现SPI的时序,这一点是非常重要的,这就涉及到SPI标准协议的工作模式了,通过CPOL(Clock Polarity)时钟极性和CPHA(Clock Phase)时钟相位的不同组合,可以分为4种模式。
一般从机器件的工作模式是固定的,主机需要采用一样的工作模式,双方才能正常“交流”。
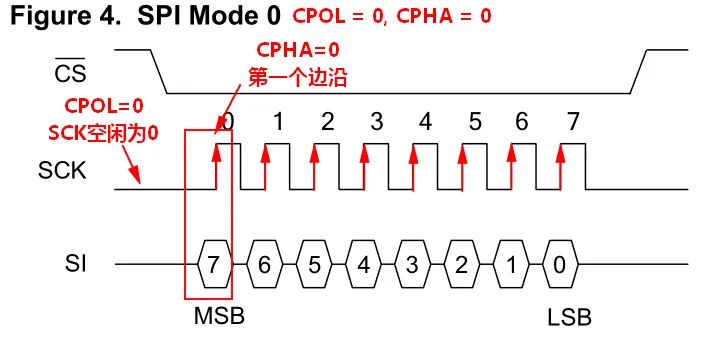
CPOL=0表示,SCK在空闲状态时为0
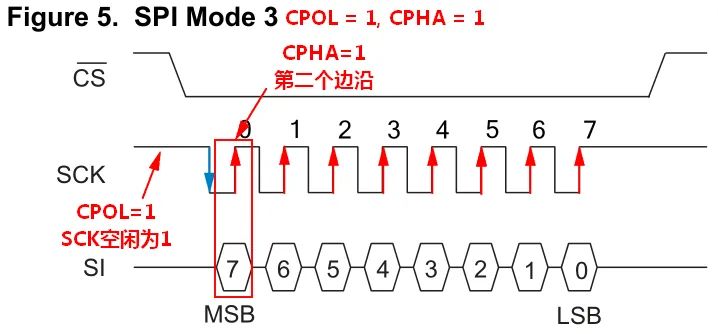
CPOL=1表示,SCK在空闲状态时为1
CPHA=0表示,在SCK第一个边沿时输入输出数据有效
CPHA=1表示,在SCK第二个边沿时输入输出数据有效
这四种模式中,应用最广泛的是模式0和3,大多数SPI器件都同时支持这两种工作模式,其实这些都不重要,具体采用什么模式,看你的器件手册就知道了。
以我最近工作中使用到的一款Cypress的铁电存储器FM25V05为例,在其官方DataSheet上介绍同时支持SPI Mode 0和Mode 3,

根据后面的时序图,可以得知SPI mode 0的读写时序,图中可以看出SCK空闲状态为低电平,主机数据在每个上升沿被从机采样,数据输出同理。
 对于SPI mode3,SCK空闲状态为高电平,主机数据在每个上升沿被从机采样,数据输出同理。
对于SPI mode3,SCK空闲状态为高电平,主机数据在每个上升沿被从机采样,数据输出同理。
模式1和模式2同理,模式1即CPOL=0,CPHA=1,SCK空闲为0,在SCK第二个边沿时数据有效,即SCK下降沿有效。

模式2即CPOL=1,CPHA=0,SCK空闲为1,在SCK第一个边沿时数据有效,即SCK下降沿有效。
 在一些自带SPI硬件外设的MCU上,设置主机的SPI模式非常简单,只需要配置几个寄存器的值即可,而且是写了SCK高电平还是低电平,和第一个还是第二个边沿,不用去记忆等于0还是等于1。
在一些自带SPI硬件外设的MCU上,设置主机的SPI模式非常简单,只需要配置几个寄存器的值即可,而且是写了SCK高电平还是低电平,和第一个还是第二个边沿,不用去记忆等于0还是等于1。
以STM32F103硬件SPI配置为例:
SPI_InitTypeDef SPI_InitStruct;
SPI_InitStruct.SPI_Mode =SPI_Mode_Master; //主
.....
SPI_InitStruct.SPI_CPOL =SPI_CPOL_High; //SCK空闲时为高电平
SPI_InitStruct.SPI_CPHA =SPI_CPHA_1Edge;//SCK第一个边沿有效
.....
SPI_Init(SPI2,&SPI_InitStruct);
而在FPGA中实现,需要严格根据时序来控制SCK和数据的输入输出。
多种传输速率
SCK的速率就是SPI的传输速率,SPI协议没有一个固定的速率,不像IIC标准模式100K,快速模式400K,高速模式3.4M,SPI的传输速率取决于器件本身支持多高的速率,器件手册里都有描述
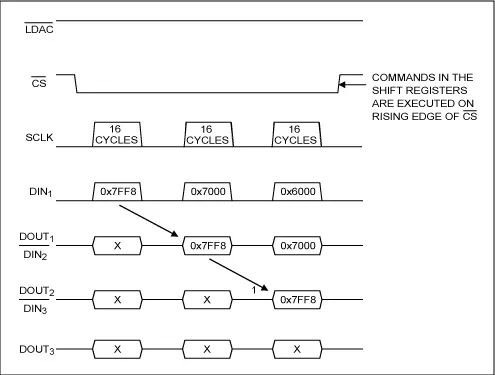
SPI协议的基本时序
CS为低电平时,表示对应的从机设备被使能,在每个SCLK周期可以传输1Bit数据,采样时刻取决于器件支持的SPI mode,根据不同SPI器件的控制方法,在进行正式的数据读写操作前,一般需要先写入控制字,然后是寄存器地址和数据。
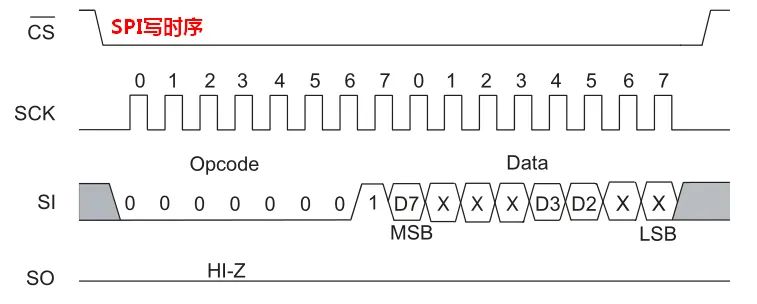
如果要使用FPGA来实现SPI时序,在CS下降沿和SCLK第一个边沿,或CS上升沿和SCLK最后一个边沿之间要留有一定的延迟时间,一般是0.5个SCLK周期。
一些SPI从机设备支持菊花链连接模式,即节省GPIO,又不会占据太多布线面积,但并不是所有的SPI器件都支持菊花链模式。

控制时序:
SPI协议的升级版
传统标准的SPI协议,一个SCLK周期只能传输1Bit数据,能不能一个SCLK传输多个Bit数据呢?答案是可以的。Motorola公司在现有的标准4线SPI协议上,又开发出了多种SPI协议的升级版,通过增加数据线位数的方式,来提高数据传输的效率,目前很多Flash厂家都已经支持多种SPI协议。
以比较常用的一款SPI Flash ROM W25Q128FW为例,在其器件手册上写着除了标准的4线SPI模式,还支持Dual SPI,Quad SPI,QPI等,在这几种模式下,IO0/1/2/3这些IO作为双向端口,大大增加了数据读写的速率。
SPI和IIC的对比
- SPI是全双工,而IIC是半双工。
- IIC支持多主机多从机模式,而SPI只能有一个主机。
- 从GPIO占用上来看,IIC占用更少的GPIO,更节省资源。
- SPI的数据位宽更灵活,可以根据需要选择多位数据宽度。
- SPI协议没有响应机制,主机无法得知从机是否接收到所发的数据,如果不采取一些方法的话可能会导致数据丢帧。
- 正是因为没有复杂的响应机制,SPI协议可以做到非常高的速率(上百兆),每一个SCK都可以进行数据的传输,通过引入CRC校验等校验方法,可以即高速传输数据,又能保持数据的准确度。
- IIC通过器件地址来选择从机,从机数量的增加不会导致GPIO的增加,而SPI通过CS选择从机,每增加一个从机就要多占用一个GPIO,当然也可以通过加入译码器来实现多从机控制。
- SPI协议在SCLK边沿进行采样,IIC在SCL高电平器件进行采样。
- 两者大多都应用于板内器件短距离通讯。
总结
使用FPGA来实现SPI时序,最大的好处就是灵活,时序可以根据需要精确的定制,可以实现非常高的速率,特别是同时驱动多片芯片上有很大的优势,在一些高速AD采集的场合必须使用FPGA来实现,难点就是做起来比较麻烦,需要一点点的调试,仿真,虽然FPGA也有一些现成的IP可以使用,但还是不够灵活。
不像STM32等MCU那样有现成的库函数和寄存器简单几行代码配置一下,就可以实现主从模式、SPI模式、数据位宽、多种速率、单线双线、半双工全双工、DMA等等。
总之,FPGA和MCU各有优点,也各有不足,根据需求来选择吧!无论采用什么控制器实现,只要根据数据手册严格控制时序,就没有什么协议是不能搞定的!
参考资料:关于SPI协议,看这一篇文章就够了!
4.使用IO模拟过SPI吗?
原则:有硬件I2C、SPI时尽量用硬件操作,省去IO模拟繁琐的时序调试。但在内部资源不够时就要用IO模拟总线了。
关于短延时:
模拟时序时是否需要延时要看MCU与device的相对速度。比如I2C如果400K的速率和MCU动辄几十M的速率不再一个量级,肯定要通过延时调整时序;但对于SPI因为其速度很高,甚至有的比单片机的速度还高,这时就没必要延时了。
关于IO模拟的收发函数是否要合并成一个:
对于SPI因为是全双工,所以可以分开,当然也可以合并成一个(发送时不需要返回值,而接收时此时参数是要发送的数据,返回值是要读的值)
关于在什么跳变沿操作:
比如芯片手册中说到在上升沿采样/锁定(也就是在搞定平之后值必须稳定),那么单个位bit的收发都应该在0->1之间进行操作。
关于时钟极性和时钟相位:
CPOL时钟极性只是说明了空闲时总线的电平状态:CPOL=1表明空闲时时钟是搞定平;否则是低电平。
CPOA时钟相位说明了在第几个跳变沿进行采样,CPOA=0表明在第一个沿进行采样,否则在第二个沿。
#include "iom8535v.h"
#define _CPOL 1
#define _CPHA 0
#define SCK_IO DDRA|=0X01
#define MOSI_IO DDRA|=0X02
#define MISO_IO DDRA&=0XFB
#define SSEL_IO DDRA|=0X08
#define SCK_D(X) (X?(PORTA|=0X01):(PORTA&=0XFE))
#define MOSI_D(X) (X?(PORTA|=0X02):(PORTA&=0XFD))
#define SSEL_D(X) (X?(PORTA|=0X08):(PORTA&=0XF7))
#define MISO_I() (PINA&0X04)
void delay()
{
unsigned char m,n;
for(n=0;n<5;n++);
for(m=0;m<100;m++);
}
/************************************************
端口方向配置 与输出初始化
************************************************/
void SPI_Init(void)
{
SCK_IO ;
MOSI_IO ;
MISO_IO ;
SSEL_IO ;
SSEL_D(1);
MOSI_D(1);
#if _CPOL==0
SCK_D(0);
#else
SCK_D(1);
#endif
}
/**********************************************
模式零 写数据
***********************************************/
#if _CPOL==0&&_CPHA==0 //MODE 0 0
void SPI_Send_Dat(unsigned char dat)
{
unsigned char n;
for(n=0;n<8;n++)
{
SCK_D(0);
if(dat&0x80)MOSI_D(1);
else MOSI_D(0);
dat<<=1;
SCK_D(1);
}
SCK_D(0);
}
/*********************************************
模式零 读数据
*********************************************/
unsigned char SPI_Receiver_Dat(void)
{
unsigned char n ,dat,bit_t;
for(n=0;n<8;n++)
{
SCK_D(0);
dat<<=1;
if(MISO_I())dat|=0x01;
else dat&=0xfe;
SCK_D(1);
}
SCK_D(0);
return dat;
}
#endif
/**********************************************
模式二 写数据
***********************************************/
#if _CPOL==1&&_CPHA==0 //MODE 1 0
void SPI_Send_Dat(unsigned char dat)
{
unsigned char n;
for(n=0;n<8;n++)
{
SCK_D(1);
if(dat&0x80)MOSI_D(1);
else MOSI_D(0);
dat<<=1;
SCK_D(0);
}
SCK_D(1);
}
/*********************************************
模式二 读数据
*********************************************/
unsigned char SPI_Receiver_Dat(void)
{
unsigned char n ,dat,bit_t;
for(n=0;n<8;n++)
{
SCK_D(1);
dat<<=1;
if(MISO_I())dat|=0x01;
else dat&=0xfe;
SCK_D(0);
}
SCK_D(1);
return dat;
}
#endif
/*********************************************
模式一 写数据
*********************************************/
#if _CPOL==0&&_CPHA==1 //MODE 0 1
void SPI_Send_Dat(unsigned char dat)
{
unsigned char n;
SCK_D(0);
for(n=0;n<8;n++)
{
SCK_D(1);
if(dat&0x80)MOSI_D(1);
else MOSI_D(0);
dat<<=1;
SCK_D(0);
}
}
/*********************************************
模式一 读数据
*********************************************/
unsigned char SPI_Receiver_Dat(void)
{
unsigned char n ,dat,bit_t;
for(n=0;n<8;n++)
{
SCK_D(1);
dat<<=1;
if(MISO_I())dat|=0x01;
else dat&=0xfe;
SCK_D(0);
}
SCK_D(0);
return dat;
}
#endif
///
///
#if _CPOL==1&&_CPHA==1 //MODE 1 1
void SPI_Send_Dat(unsigned char dat)
{
unsigned char n;
SCK_D(1);
for(n=0;n<8;n++)
{
SCK_D(0);
if(dat&0x80)MOSI_D(1);
else MOSI_D(0);
dat<<=1;
SCK_D(1);
}
}
/************************************
模式三 读数据
************************************/
unsigned char SPI_Receiver_Dat(void)
{
unsigned char n ,dat,bit_t;
SCK_D(0);
for(n=0;n<8;n++)
{ SCK_D(0);
dat<<=1;
if(MISO_I())dat|=0x01;
else dat&=0xfe;
SCK_D(1);
}
SCK_D(1);
return dat;
}
#endif
/*************************************
*************************************/
void main()
{
SPI_Init();
DDRB = 0XFF;
//#if _CPOL
//SCK_D(0);
//#endif
while(1)
{
//SSEL_D(0);
//SPI_Send_Dat(0x01);
//SPI_Send_Dat(0x31);
//SSEL_D(1);
SSEL_D(0);
SPI_Send_Dat(0x81);
PORTB =SPI_Receiver_Dat();
SSEL_D(1);
//delay();
}
}
5.堆和栈有什么区别?
一、堆和栈的区别
1、堆栈空间分配不同
-
栈(操作系统):由操作系统(编译器)自动分配释放,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
-
堆(操作系统):一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收,分配方式类似于链表。
2、堆栈缓存方式不同
-
栈:使用的是一级缓存,它们通常都是被调用时处于存储空间中,调用完毕立即释放。
-
堆:存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
3、堆栈数据结构不同
-
堆(数据结构):可以被看成是一棵树,如:堆排序。先进先出的结构。
-
栈(数据结构):一种先进后出的数据结构。
延伸阅读
二、什么是堆
堆(数据结构)
- 堆可以被看成是一棵树,如:堆排序。
堆(操作系统)
- 堆是由操作系统管理的一片空间,事先没有在进程空间里分配(比如在没有分配堆时就访问堆空间会报内存访问错误)。
- 一般由程序动态分配,分配后需要程序自行释放堆空间。
- 堆的空间较大,但访问速度没有栈快。
- 受垃圾处理器GC管理,GC会清理很久没有引用地址指向的内存块。
三、什么是栈
栈(数据结构)
- 一种先进后出的数据结构。
- 是操作系统在建立进程或线程时为其建立的存储区域,具有FILO特性。
- 编译时可以指定需要的Stack大小。
栈(操作系统)
- 栈上是向下填充的,数据只能从栈的顶端插入和删除(先进后出原则)。
- 把数据放入栈顶称为入栈(push),从栈顶删除数据称为出栈(pop)。
- 栈的空间较小,但访问速度快。
- 栈的生长方向是从高地址向低地址生长,栈的清理由系统自动完成。
6.调用函数时,有那些内容需要压栈?
当调用函数时,可能需要压栈的内容主要有以下几项:
- 函数的返回地址:当调用一个函数时,需要将当前函数的执行位置(即返回地址)压入栈中,以便在函数执行完毕后能够返回到正确的位置继续执行。
- 函数的参数:如果函数需要参数,这些参数也需要压入栈中。具体的压栈顺序和方式可能依赖于所使用的函数调用约定(如cdecl、stdcall等),但一般来说,参数会按照某种特定的顺序(如从右到左)被压入栈中。
- 局部变量:函数在执行过程中可能需要使用一些局部变量,这些局部变量通常会在栈上分配空间。然而,这并不意味着局部变量的值需要被“压栈”,因为局部变量在函数执行期间一直存在于栈上的固定位置。但是,如果函数调用了其他函数,并且这些局部变量在被调用的函数执行期间仍然需要被访问,那么它们的值可能需要被保存起来,这通常是通过将它们压入栈或其他方式来实现的。
- 栈帧指针:在某些情况下,可能还需要将栈帧指针压入栈中。栈帧指针用于标识当前函数栈帧的起始位置,它对于函数内部的局部变量访问以及返回值的处理都是非常重要的。
请注意,以上内容并不是在每次函数调用时都需要压栈的,它们是否需要压栈取决于具体的函数调用约定、函数实现以及优化策略。
“在函数调用时,通常需要压栈的内容包括函数的返回地址、函数的参数以及可能的局部变量和栈帧指针。这些内容的压栈是为了在函数执行过程中维护正确的执行上下文,确保函数能够正确地获取参数、访问局部变量,并在执行完毕后返回到正确的位置继续执行。具体的压栈内容和方式可能依赖于所使用的编程语言、编译器以及函数调用约定。 虽然函数调用时通常会涉及压栈操作以维护执行上下文,但也存在一些特殊情况或优化后的场景,其中某些内容可能不需要压栈。例如,当函数采用内联方式实现时,函数体直接嵌入到调用代码中,因此没有需要压栈的内容。另外,当使用寄存器传递参数时,参数可以直接通过寄存器进行传递,而不需要被压入栈中。这些优化策略通常由编译器自动处理,程序员在编写代码时通常不需要关心这些细节。
太细节了是不是哈哈
# 7.有什么要问我的?
4.4号打来电话,告知一面通过,清明节后安排二面。
二面(4.9,40min)
# 1.自我介绍
# 2.项目
3.uboot启动流程
详细版本:【系统启动】uboot启动流程源码分析
1> 建立异常向量表 2> 显示的切换到 SVC 且 32 指令模式 3> 设置异常向量表 4> 关闭 TLB,MMU,cache,刷新指令 cache 数据 cache 5> 关闭内部看门狗 6> 禁止所有的中断 7> 串口初始化 8> tzpc(TrustZone Protection Controller) 9> 配置系统时钟频率和总线频率 10> 设置内存区的控制寄存器 11> 设置堆栈 12> 代码的搬移阶段
代码的搬移阶段:为了获得更快的执行速度,通常把stage2加载到RAM空间中来执行,因此必须为加载Boot Loader的stage2准备好一段可用的RAM空间范围。空间大小最好是memory page大小(通常是4KB)的倍数,一般而言,1M的RAM空间已经足够了。 flash中存储的u-boot可执行文件中,代码段、数据段以及BSS段都是首尾相连存储的,所以在计算搬移大小的时候就是利用了用BSS段的首地址减去代码的首地址,这样算出来的就是实际使用的空间。 程序用一个循环将代码搬移到0x81180000,即RAM底端1M空间用来存储代码。然后程序继续将中断向量表搬到RAM的顶端。 由于stage2通常是C语言执行代码,所以还要建立堆栈去。在堆栈区之前还要将malloc分配的空间以及全局数据所需的空间空下来,他们的大小是由宏定义给出的,可以在相应位置修改。
13> 跳到 C 代码部分执行
下来是u-boot启动的第二个阶段,是用c代码写的, 这部分是一些相对变化不大的部分,我们针对不同的板子改变它调用的一些初始化函数,并且通过设置一些宏定义来改变初始化的流程, 所以这些代码在移植的过程中并不需要修改,也是错误相对较少出现的文件。 在文件的开始先是定义了一个函数指针数组,通过这个数组,程序通过一个循环来按顺序进行常规的初始化,并在其后通过一些宏定义来初始化一些特定的设备。 在最后程序进入一个循环,main_loop。这个循环接收用户输入的命令,以设置参数或者进行启动引导。
在嵌入式系统面试中,当面试官问及u-boot的启动流程时,你可以按照以下结构来回答:
首先,简要介绍u-boot:
- u-boot,即Universal Boot Loader,是一个开源的、多平台的引导加载程序,广泛应用于嵌入式系统中。它负责初始化硬件设备、设置系统环境,并最终引导操作系统启动。
接下来,详细描述u-boot的启动流程:
- 启动阶段一(Stage 1):
- 硬件初始化:u-boot在启动时首先会进行一些基本的硬件初始化,例如关闭看门狗、设置时钟系统等。
- 复制自身到RAM:由于u-boot通常存储在ROM或Flash等非易失性存储器中,而这些存储器的访问速度可能较慢,因此u-boot会将自己复制到RAM中以便快速执行。
- 跳转到RAM中的地址:完成复制后,u-boot会跳转到RAM中的新地址继续执行。
- 启动阶段二(Stage 2):
- 更详细的硬件初始化:在阶段二中,u-boot会进行更详细的硬件初始化,包括内存控制器、串口、网络等外设的初始化。
- 加载设备树(Device Tree):现代嵌入式系统通常使用设备树来描述硬件结构,u-boot会加载并解析设备树,以便了解硬件的配置和连接方式。
- 环境变量设置:u-boot会设置一些环境变量,这些变量可以用来配置引导过程,例如设置启动参数、选择启动设备等。
- 引导操作系统:最后,u-boot会根据配置信息引导操作系统启动。这通常涉及到加载操作系统的内核映像、设置启动参数,并跳转到操作系统的入口点。
在描述过程中,可以强调u-boot的灵活性和可配置性,例如:
它支持多种处理器架构、多种启动方式(如从Flash启动、从网络启动等),以及通过环境变量和配置文件进行定制。
最后,总结并强调你对u-boot的理解和实际应用经验。
这一部分真的知识很多,但是如果这部分蛮重要的。建议结合代码,梳理一遍流程,记起来就没有那么不快乐了。
主页直接搜索uboot,会把你看个爽。
4.uboot启动前还需要做那些事情?
首先,需要明确uboot启动前的准备工作主要是为了确保uboot能够正确且稳定地启动。这涉及到选择合适的启动介质和设置相关参数。启动介质的选择取决于具体的嵌入式系统硬件和需求,可能包括USB口、串口、SD卡或EMMC等。同时,需要根据实际情况设置一些关键参数,以确保uboot能够正确地识别和执行。
其次,可以提到在uboot启动前,需要进行一些硬件设备的初始化工作。这包括设置状态寄存器,使CPU进入特定的特权模式(如svc模式),并禁止某些中断和看门狗功能。同时,还需要初始化RAM存储器,为加载uboot的第二阶段代码准备足够的RAM空间。
此外,还需要注意uboot的stage1代码通常是用汇编语言编写的,并且负责完成一些依赖CPU体系结构的初始化工作。例如,将uboot的stage2代码拷贝到RAM中,设置好栈并清除bss段等。这些操作都是为了保证uboot能够顺利过渡到C语言阶段,并继续执行后续的启动流程。
uboot启动前需要做的事情包括选择合适的启动介质和参数、进行硬件设备的初始化、完成依赖CPU体系结构的初始化工作等。这些步骤都是为了确保uboot能够正确且稳定地启动,并顺利执行后续的启动流程。
追问一下:选择合适的启动介质和参数呢?
首先,在选择启动介质时,需要考虑嵌入式系统的硬件配置和需求。**常见的启动介质包括USB口、串口、SD卡、EMMC以及Flash等存储设备。**如果您的系统支持多种介质,您可以根据介质的读写速度、容量和可靠性等因素进行选择。例如,如果您的系统需要快速启动并且对读写速度有较高要求,那么USB口或SD卡可能是更好的选择。
其次,**关于启动参数的选择,这通常取决于您的嵌入式系统的具体配置和uboot版本。**您可以通过查阅uboot的文档或参考嵌入式系统的硬件手册来获取更多关于启动参数的信息。**一些常见的启动参数包括设置串口波特率、指定内核启动地址、设置根文件系统位置等。**确保这些参数与您的硬件配置和启动需求相匹配。
此外,您还可以考虑使用配置文件来设置启动参数。在uboot源码目录下,通常会有一个名为“include/configs”的文件夹,其中包含了针对不同硬件平台的配置文件。您可以根据自己的硬件平台选择相应的配置文件,并在其中设置启动参数。这样可以更方便地管理和修改启动参数。
最后,实际的选择过程可能需要一些实验和调试。您可以尝试不同的启动介质和参数组合,观察启动过程中的输出和结果,逐步调整以获得最佳的启动效果。
综上所述,选择合适的启动介质和参数需要考虑**嵌入式系统的硬件配置、需求以及uboot版本等因素。**通过查阅文档、参考手册和实验调试,您可以找到最适合您系统的启动介质和参数组合。
5.uboot启动时使用的是物理地址还是虚拟地址?MMU要开启吗?
首先,U-Boot在启动初期主要使用的是物理地址。这是因为在这个阶段,系统尚未完成全面的初始化,包括内存管理单元(MMU)的初始化。
MMU的主要作用是负责将虚拟地址映射到物理地址,提供内存保护,并管理内存分页。然而,在U-Boot启动的早期阶段,MMU尚未被启用,因此此时对内存的访问都是基于物理地址的。
其次,关于MMU是否要开启的问题,**通常在U-Boot的启动初期,MMU是关闭的。**这是因为在这个阶段,系统尚未准备好进行虚拟地址到物理地址的映射。开启MMU需要在系统初始化到一定程度,内存管理、分页机制等都已经设置好之后进行。过早地开启MMU可能会导致地址转换错误,影响系统的正常启动。
然而,值得注意的是,在某些特定的嵌入式系统设计中,可能会根据实际需求在U-Boot启动的某个阶段开启MMU。这通常需要对系统的硬件架构和内存管理有深入的了解,并且需要确保在开启MMU之前,所有相关的初始化工作都已经完成。
6.x86汇编和Arm汇编有什么区别?
首先,从指令集架构的角度来看,x86架构采用复杂指令集(CISC),而ARM架构则采用精简指令集(RISC)。
CISC架构的指令集设计复杂,每个指令可以执行多个操作,这种设计有助于提高处理器的性能,但也可能导致更高的功耗和更复杂的硬件实现。
而RISC架构则追求指令的精简和高效,每个指令执行单一操作,通过简单的指令和高效的流水线操作来降低功耗和提高效率。
其次,从编译器和软件生态的角度来看,x86架构拥有庞大的生态系统和广泛的应用支持。由于其在PC机和服务器领域的广泛应用,许多常见的操作系统、应用程序和开发工具都是基于x86架构开发的。这使得x86汇编在软件开发和兼容性方面具有较大的优势。
而ARM架构虽然在移动设备和嵌入式系统领域有广泛的应用支持,但在桌面计算机领域的应用相对较少,因此其软件生态和工具链可能不如x86丰富。
此外,从性能和功耗的角度来看,x86架构通过复杂的指令集和多核处理能力,实现了高性能计算和数据处理。这使得x86架构在需要高性能的应用场景中具有优势,如高性能计算、游戏等。然而,高性能往往伴随着高功耗,这使得x86架构在功耗控制方面存在一定的挑战。
相比之下,ARM架构通过精简指令集和高效的流水线操作,实现了较低的功耗,适合移动设备和嵌入式系统等对功耗要求较高的应用场景。
最后,从开发者的角度来看,x86汇编和ARM汇编在语法和编程模型上也有所不同。开发者需要根据具体的应用场景和需求,选择适合的汇编语言和架构进行开发。同时,由于两者的差异,开发者在跨平台开发时可能需要考虑代码移植和优化的问题。
感觉有点都是大白话
7.介绍一个你熟悉的驱动程序?
这种题真的是送上门的肥肉,挑个自己擅长的。讲讲驱动,讲讲驱动架构。
按照以下结构来回答:
-
- 选择驱动程序:首先,我会选择一个我真正熟悉且理解深入的驱动程序。这可以是一个通用的驱动程序,如UART(通用异步收发传输器)驱动程序,或者是一个特定于项目的驱动程序,如某个传感器的驱动程序。
-
- 介绍驱动程序的基本功能:我会解释该驱动程序的主要功能。例如,如果我选择的是UART驱动程序,我会说:“UART驱动程序是用于实现串行通信的,它允许设备与其他设备进行异步数据传输。通过UART,我们可以发送和接收字节流数据。”
-
- 描述驱动程序的工作原理:我会解释驱动程序是如何工作的。这包括它如何与硬件交互,以及它如何提供API(应用程序接口)给上层应用程序使用。例如:“UART驱动程序通常通过特定的寄存器与UART硬件进行交互。它提供了打开、关闭、读取和写入等API,使得上层应用程序可以方便地使用UART进行通信。”
-
- 讨论驱动程序的实现细节:如果可能的话,我会提及一些具体的实现细节,如中断处理、缓冲区管理、错误处理等。这可以展示我对驱动程序内部工作原理的深入理解。
-
- 分享我的经验:如果有的话,我会分享一些我在使用或开发这个驱动程序时遇到的挑战和解决方案。这可以展示我的问题解决能力和实践经验。
-
- 总结:我会简要总结我的回答,并强调我对这个驱动程序的熟悉程度以及我在嵌入式系统开发方面的能力。
以下是一个示例回答:
“我熟悉的驱动程序是UART驱动程序。UART是一种通用的串行通信协议,广泛应用于各种嵌入式系统中。UART驱动程序的主要功能是提供串行通信的能力,使得设备可以与其他设备进行异步数据传输。
UART驱动程序通常通过特定的寄存器与UART硬件进行交互。它实现了打开、关闭、配置、读取和写入等API,使得上层应用程序可以方便地使用UART进行通信。
在驱动程序的实现中,中断处理是一个重要的部分,用于在接收到数据时通知上层应用程序。.
此外,缓冲区管理也是关键,它用于存储待发送或已接收的数据。
在我之前的一个项目中,我使用了UART驱动程序来实现设备之间的通信。
我遇到了一个关于中断处理的问题,即在高频率的数据传输下,中断处理函数可能会占用过多的CPU时间。
为了解决这个问题,我优化了中断处理函数的实现,并使用了DMA(直接内存访问)来减少CPU的负载。这次经验让我更深入地理解了UART驱动程序工作原理和性能优化。”
通过这样的回答,我可以展示我对驱动程序的理解、实践经验以及解决问题的能力。”
8.操作系统学过吗?自旋锁和信号量有什么区别?
在嵌入式面试中,当面试官询问自旋锁和信号量的区别时,你可以从以下几个方面进行回答:
实现机制:
- 自旋锁:当一个线程尝试获取锁时,如果锁已经被其他线程持有,该线程会进入忙等待状态,不断循环检查锁是否可用。它不会使线程进入睡眠状态,而是持续消耗CPU资源等待锁释放。
- 信号量:信号量是一种计数器,**用于控制多个线程或进程对共享资源的访问。**当线程尝试获取信号量时,如果信号量的值大于0,则线程可以继续执行;如果信号量的值为0,线程将被阻塞,进入睡眠状态,直到信号量值大于0时才会被唤醒。
适用场景:
- 自旋锁:适用于锁持有时间较短的场景,因为忙等待不会造成过多的CPU资源浪费。同时,自旋锁适用于单核CPU或对于锁的争用不是很激烈的场景,因为在多核CPU上,自旋的线程可能会被调度到其他核上,导致资源浪费。
- 信号量:适用于锁持有时间较长的场景,因为线程在等待过程中可以进入睡眠状态,不消耗CPU资源。同时,信号量也适用于需要控制多个线程或进程访问共享资源的场景。
性能影响:
- 自旋锁:在锁竞争激烈的情况下,可能会导致CPU资源的过度消耗,因为多个线程可能在循环等待同一个锁。
- 信号量:由于线程在等待信号量时可以进入睡眠状态,因此不会造成CPU资源的过度消耗。但需要注意的是,线程的切换和唤醒也需要一定的开销。
安全性与公平性:
- 自旋锁:由于忙等待的特性,自旋锁可能不如信号量在公平性方面做得好。在某些情况下,如果某个线程一直无法获取到锁,它可能会持续消耗CPU资源,而其他线程则无法获得执行的机会。
- 信号量:信号量通常具有更好的公平性和安全性,因为它可以控制线程的唤醒顺序,避免某些线程长时间无法获取到资源。
9.Linux系统的启动流程
1.总体流程
大致步骤流程:
- 查找处理器内核类型和处理器类型
- 建立页表
- 跳转到 start_kernel()函数开始内核的初始化工作
- 调用 rest_init()函数创建系统的init 进程
- 挂载根文件系统
- 用cpu_idle()函数来使系统处于闲置(idle)状态并等待用户程序的执行
2.具体流程
Linux 内核的入口位于文件/arch/arm/kernel/head-armv.S 中的 stext 段。
该段的基地址就是bootloader的跳转地址。
该程序通过查找处理器内核类型和处理器类型调用相应的初始化函数(即获得处理器的 ID 号,RAM基地址,IO基地址等), 再(即将 RAM 基地址开始的 4M 空间的物理地址映射到 0xC0000000 开始的虚拟地址处),最后跳转到 start_kernel()函数开始内核的初始化工作
start_kernel是内核初始化的入口函数,它主要完成与硬件平台相关的初始化工作,该函数所做的具体工作有:
- 1.调用 setup_arch()函数进行内存结构的初始化,调用paging_init()开启 MMU,创建内核页表,映射所有的物理内存和 IO空间。
- 2.创建异常向量表和初始化中断处理函数;
- 3.初始化系统核心进程调度器和时钟中断处理机制;
- 4.初始化串口控制台(serial-console);
- 5.创建和初始化系统 cache,为各种内存调用机制提供缓存,包括;动态内存分配,虚拟文件系统(VirtualFile System)及页缓存。
- 6.初始化内存管理,检测内存大小及被内核占用的内存情况;
- 7.初始化系统的进程间通信机制(IPC);
- 8.调用 rest_init()函数创建系统的init 进程
- 9.Init 进程进行一系列的硬件初始化,然后通过命令行传递过来的参数挂载根文件系统。最后 init 进程会执行用 户传递过来的“init=”启动参数执行用户指定的命令
- 10.调用cpu_idle()函数来使系统处于闲置(idle)状态并等待用户程序的执行
面试的时候到这按说就很丰富了,其中面试官可能会对你将其中的一个步骤追问,因此有时间还是建议好好梳理一下。
需要的话可以留言,我重新梳理一遍给你。
# 10.学过哪些专业课,哪些学的比较好?
# 11.你有什么想问我的?
三面(4.12,15min)
HR面,等我输出专门的文章。
# 1.自我介绍
# 2.HR介绍部门
# 3.和哪个公司签约了?
# 4.对工作地有什么要求?
# 5.你有什么想问我的?
Offer
- 4.15收到录用排序的通知,4.20发下正式offer。影像部门,在深圳,C/C++岗位,工作内容主要是相机驱动,图像调测等,进去后随机分岗。
- oppo软工和影像加班是真的多,11点后下班是常态,每周六天,每年强制淘汰5%。薪资待遇给的白菜价,而且,没有argue的余地。综合各个方面考虑,拒绝了。
面试题来自:不错发几女
后面会梳理一下整个启动流程,面试官很喜欢问这个东西~~~
--->****************
#在国企工作的人,躺平了吗?##国企和大厂硬件兄弟怎么选?##稳定和高薪机械人更看重哪个?#让实战与真题助你offer满天飞!!! 华为、OPPO、大疆、Vivo、小米、海康、大华等大厂嵌入式工程师面试真题与经验。 每周两更,共计100篇! 励志做最全ARM/Linux嵌入式面试经验与题库。 励志讲清每一个知识点,找到每个问题最好的答案。 让你学懂,掌握,融会贯通。订阅即赠送学习笔记、简历模板、面试提纲模板【正在精心完善丰富中】。同时不定期更新内推招聘机会。
