算法工程师的独孤九剑秘籍(经典&热门模型高频面试题大汇总)

写在前面
【三年面试五年模拟】栏目专注于分享AI行业中实习/校招/社招维度的必备面积知识点与面试方法,并向着更实战,更真实,更从容的方向不断优化迭代。也欢迎大家提出宝贵的意见或优化ideas,一起交流学习💪
大家好,我是Rocky。
本文是“三年面试五年模拟”之独孤九剑秘籍的特别系列,Rocky将独孤九剑秘籍前十二式的深度学习基础高频面试题梳理成汇总篇,分享给牛友们。
由于【三年面试五年模拟】系列都是Rocky在工作之余进行整理总结,难免有疏漏与错误之处,欢迎大家对可优化的部分进行指正,我将在后续的优化迭代版本中及时更正。
在【人人都是算法工程师】算法工程师的“三年面试五年模拟”之独孤九剑秘籍(先行版)中我们阐述了这个program的愿景与规划。
希望独孤九剑秘籍的每一式都能让江湖中的英雄豪杰获益。

关于作者
Rocky在校招期间拿到了北京,上海,杭州,深圳,广州等地的约10个算法offer,现在是一名算法研究员,目前在国内大厂专注于AI算法解决方案的实现与创新业务的应用落地。
在研究生期间,Rocky曾在京东研究院,星环科技,联想研究院,北大方正信产集团研究院,百融云创等公司做算法实习生。
Rocky喜欢参加算法竞赛,多次获得CVPR,AAAI,Kaggle平台的算法竞赛冠军和Top成绩。
Rocky相信人工智能,数据科学,商业逻辑,金融工具,终身成长,以及顺应时代的潮流会赋予我们超能力。
Rocky多次进行创业实践,深刻理解商业模式,上下游,现金流,成本利润,产品销量等维度对公司生存的影响。
Rocky喜欢分享和交流,秉持着“也要学习也要酷”的生活态度,希望能和大家多多交流。CV算法,面试,简历,求职等问题都可直接和我交流~
So,enjoy:
正文开始
----【目录先行】----
经典模型&&热门模型:
-
Focal Loss的作用?
-
YOLO系列的面试问题
-
有哪些经典的轻量型人脸检测模型?
-
LFFD人脸检测模型的结构和特点?
-
U-Net模型的结构和特点?
-
RepVGG模型的结构和特点?
-
GAN的核心思想?
-
面试常问的经典GAN模型?
-
FPN(Feature Pyramid Network)的相关知识
-
SPP(Spatial Pyramid Pooling)的相关知识
-
目标检测中AP,AP50,AP75,mAP等指标的含义
-
YOLOv2中的anchor如何生成?
-
目标检测中IOU的相关概念与计算
-
目标检测中NMS的相关概念与计算
-
One-stage目标检测与Two-stage目标检测的区别?
-
哪些方法可以提升小目标检测的效果?
-
ResNet模型的特点以及解决的问题?
-
ResNeXt模型的结构和特点?
-
MobileNet系列模型的结构和特点?(二)
-
ViT(Vision Transformer)模型的结构和特点?
-
MobileNet系列模型的结构和特点?
-
EfficientNet系列模型的结构和特点?
-
面试常问的经典模型?
【一】Focal Loss的作用?
Focal Loss是解决了分类问题中类别不均衡、分类难度差异的一个损失函数,使得模型在训练过程中更加聚焦在困难样本上。
Focal Loss是从二分类问题出发,同样的思想可以迁移到多分类问题上。
我们知道二分类问题的标准loss是交叉熵:
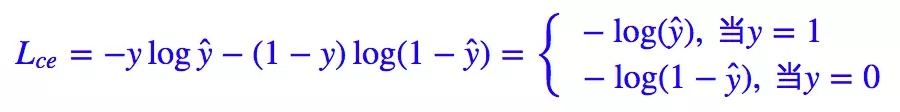 对于二分类问题我们也几乎适用sigmoid激活函数,所以上面的式子可以转化成:
对于二分类问题我们也几乎适用sigmoid激活函数,所以上面的式子可以转化成:
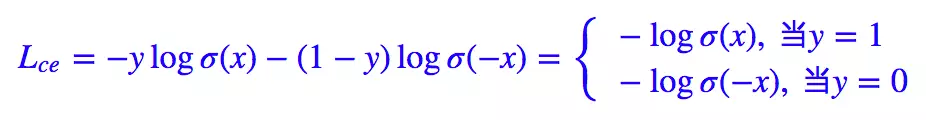 这里有。
这里有。
Focal Loss论文中给出的式子如下:

其中是真实标签,是预测概率。
我们再定义

那么,上面的交叉熵的式子可以转换成:

有了上面的铺垫,最初Focal Loss论文中接着引入了均衡交叉熵函数:

针对类别不均衡问题,在Loss里加入一个控制权重,对于属于少数类别的样本,增大即可。但这样有一个问题,它仅仅解决了正负样本之间的平衡问题,并没有区分易分/难分样本。
为什么上述公式只解决正负样本不均衡问题呢?
因为增加了一个系数,跟的定义类似,当的时候 ;当的时候,,的范围也是。因此可以通过设定的值(如果这个类别的样本数比这个类别的样本数少很多,那么可以取到来增加这个类的样本的权重)来控制正负样本对整体Loss的贡献。
Focal Loss
为了可以区分难/易样本,Focal Loss雏形就出现了:

用于平衡难易样本的比例不均,起到了对的放大作用。减少易分样本的损失,使模型更关注于困难易错分的样本。例如当时,模型对于某正样本预测置信度为,这时,也就是FL值变得很小;而当模型对于某正样本预测置信度为0.3时,,此时它对Loss的贡献就变大了。当时变成交叉熵损失。
为了应对正负样本不均衡的问题,在上面的式子中再加入平衡交叉熵的因子,用来平衡正负样本的比例不均,最终得到Focal Loss:
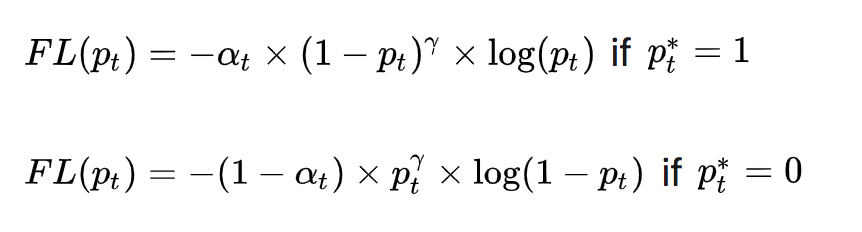
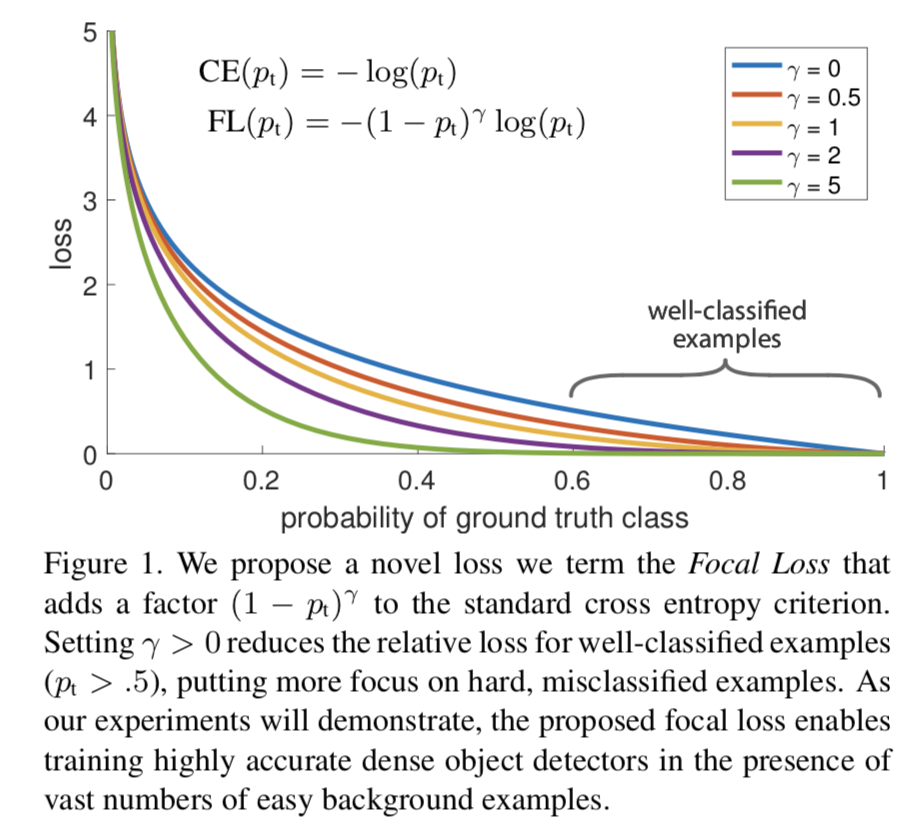
Focal Loss论文中给出的实验最佳取值为,。
【二】YOLO系列的面试问题
Rocky之前总结了YOLOv1-v7全系列的解析文章,帮助大家应对可能出现的与YOLO相关的面试问题,大家可按需取用:
【Make YOLO Great Again】YOLOv1-v7全系列大解析(汇总篇)
【三】有哪些经典的轻量型人脸检测模型?
人脸检测相对于通用目标检测来说,算是一个子任务。比起通用目标检测任务动辄检测1000个类别,人脸检测任务主要聚焦于人脸的单类目标检测,使用通用目标检测模型太过奢侈,有点“杀鸡用牛刀”的感觉,并且大量的参数冗余,会影响部署侧的实用性,故针对人脸检测任务,学术界提出了很多轻量型的人脸检测模型,Rocky在这里给大家介绍一些比较有代表性的:
- libfacedetection
- Ultra-Light-Fast-Generic-Face-Detector-1MB
- A-Light-and-Fast-Face-Detector-for-Edge-Devices
- CenterFace
- DBFace
- RetinaFace
- MTCNN
【四】LFFD人脸检测模型的结构和特点?
Rocky在实习/校招面试中被多次问到LFFD模型以及面试官想套取LFFD相关算法方案的情况,说明LFFD模型在工业界还是比较有价值的,下面Rocky就带着大家学习一下LFFD模型的知识:
LFFD(A-Light-and-Fast-Face-Detector-for-Edge-Devices)适用于人脸、行人、车辆等单目标检测任务,具有速度快,模型小,效果好的特点。LFFD是Anchor-free的方法,使用感受野替代Anchors,并在主干结构上抽取8路特征图对从小到大的人脸进行检测,检测模块分为类别二分类与边界框回归。
LFFD模型结构
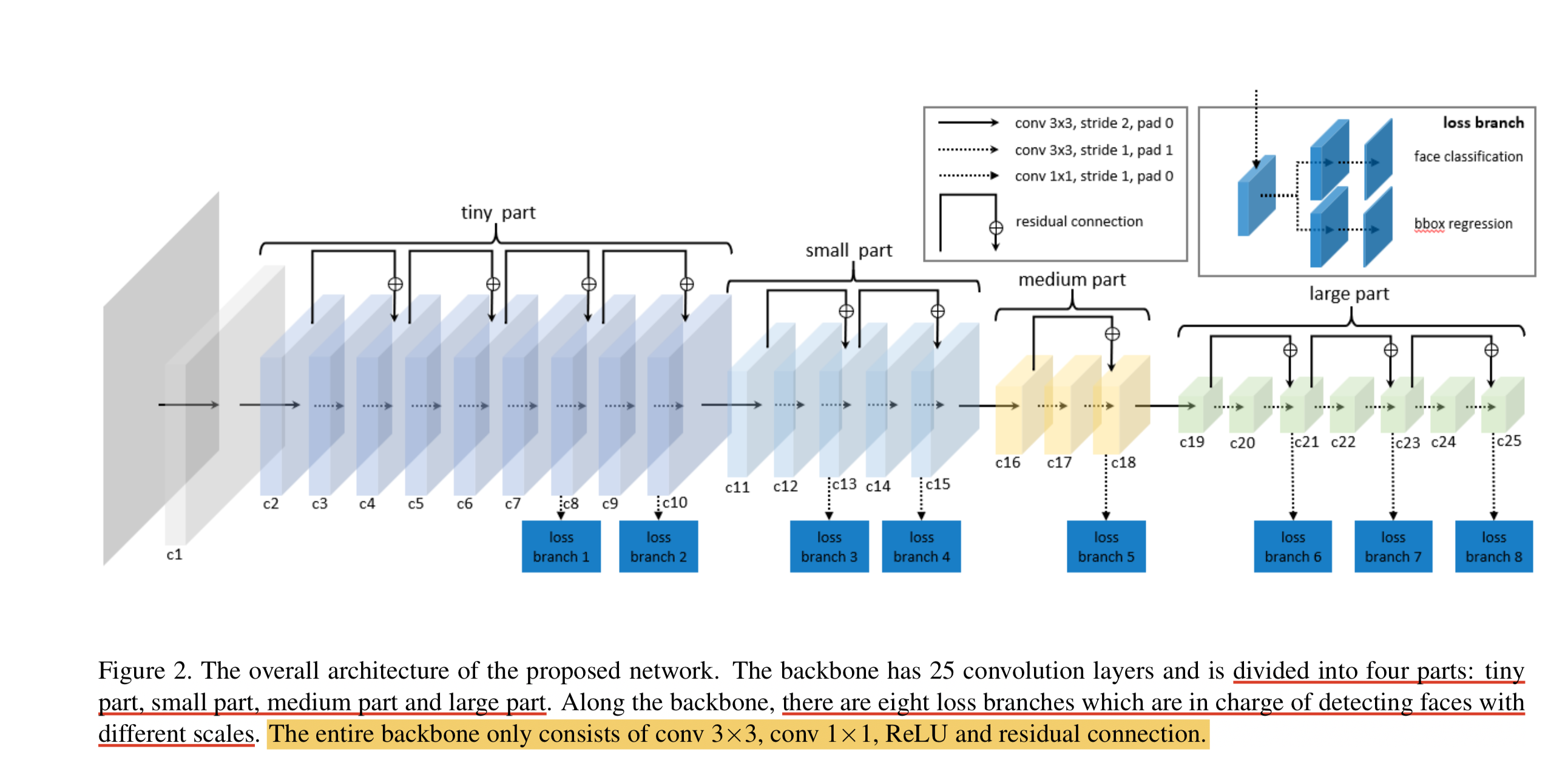
我们可以看到,LFFD模型主要由四部分组成:tiny part、small part、medium part、large part。
模型中并没有采用BN层,因为BN层会减慢17%的推理速度。其主要采用尽可能快的下采样来保持100%的人脸覆盖。
LFFD主要特点:
-
结构简单直接,易于在主流AI端侧设备中进行部署。
-
检测小目标能力突出,在极高分辨率(比如8K或更大)画面,可以检测其间10个像素大小的目标;
LFFD损失函数
LFFD损失函数是由regression loss和classification loss的加权和。
分类损失使用了交叉熵损失。
回归损失使用了L2损失函数。
【五】U-Net模型的结构和特点?
U-Net网络结构如下所示:
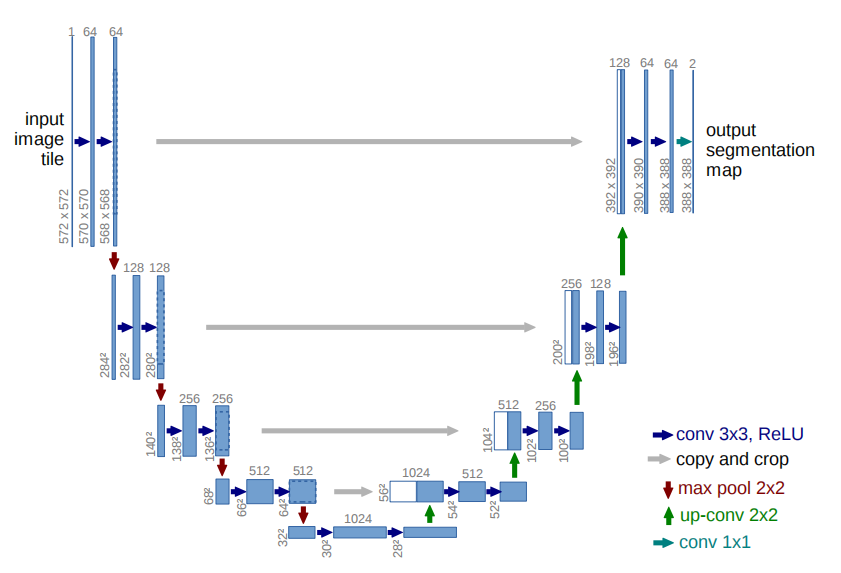
U-Net网络的特点:
- 全卷积神经网络:使用卷积完全取代了全连接层,使得模型的输入尺寸不受限制。
- 左半部分网络是收缩路径(contracting path):使用卷积和max pooling层,对feature map进行下采样。
- 右半部分网络是扩张路径(expansive path):使用转置卷积对feature map进行上采样,并将其与收缩路径对应层产生的特征图进行concat操作。上采样可以补充特征信息,加上与左半部分网络收缩路径的特征图进行concat(通过crop操作使得两个特征图尺寸一致),这就相当于在高分辨率和高维特征当中做一个融合折中。
- U-Net提出了让人耳目一新的编码器-解码器整体结构,让U-Net充满了生命力与强适应性。
U-Net在医疗图像,缺陷检测以及交通场景中有非常丰富的应用,可以说图像分割实际场景,U-Net是当仁不让的通用Baseline。
【六】RepVGG模型的结构和特点?
RepVGG模型的基本架构由20多层卷积组成,分成5个stage,每个stage的第一层是stride=2的降采样,每个卷积层用ReLU作为激活函数。
RepVGG的主要特点:
- 卷积在GPU上的计算密度(理论运算量除以所用时间)可达1x1和5x5卷积的四倍.
- 直筒型单路结构的计算效率比多路结构高。
- 直筒型单路结构比起多路结构内存占用少。
- 单路架构灵活性更好,容易进一步进行模型压缩等操作。
- RepVGG中只含有一种算子,方便芯片厂商设计专用芯片来提高端侧AI效率。
那么是什么让RepVGG能在上述情形下达到SOTA效果呢?
答案就是结构重参数化(structural re-parameterization)。
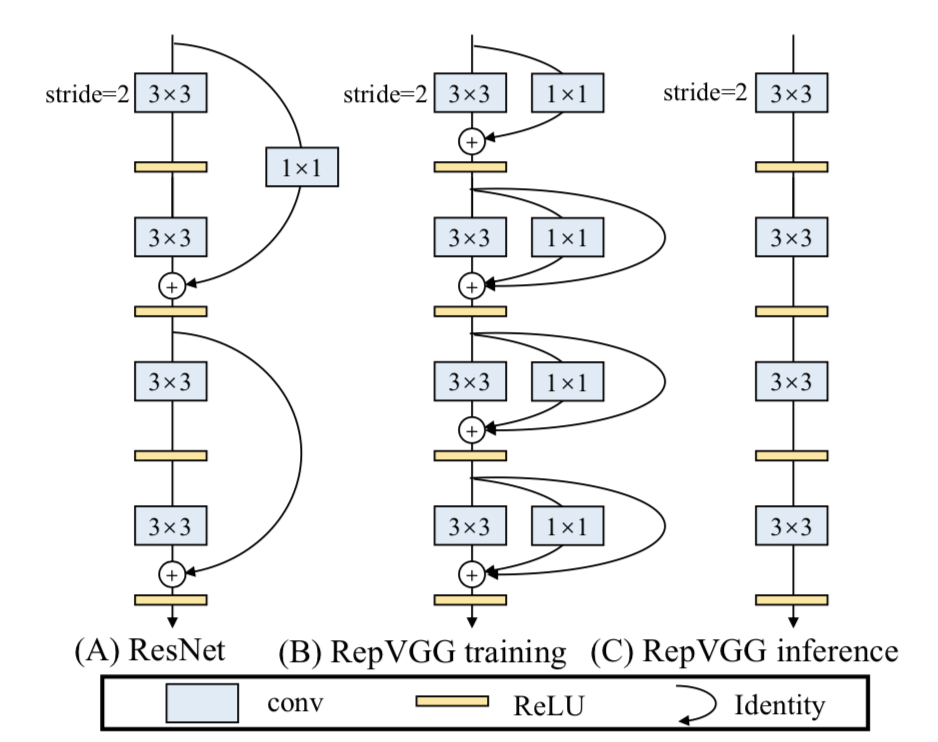
在训练阶段,训练一个多分支模型,并将多分支模型等价转换为单路模型。在部署阶段,部署单路模型即可。这样就可以同时利用多分支模型训练时的优势(性能高)和单路模型推理时的好处(速度快、省内存)。
更多结构重参数化细节知识将在后续的篇章中展开介绍,大家尽情期待!
【七】GAN的核心思想?
2014年,Ian Goodfellow第一次提出了GAN的概念。Yann LeCun曾经说过:“生成对抗网络及其变种已经成为最近10年以来机器学习领域最为重要的思想之一”。GAN的提出让生成式模型重新站在了深度学习这个浪潮的璀璨舞台上,与判别式模型开始谈笑风生。
GAN由生成器和判别器组成。其中,生成器主要负责生成相应的样本数据,输入一般是由高斯分布随机采样得到的噪声。而判别器的主要职责是区分生成器生成的样本与样本,输入一般是样本与相应的生成样本,我们想要的是对样本输出的置信度越接近越好,而对生成样本输出的置信度越接近越好。与一般神经网络不同的是,GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的。
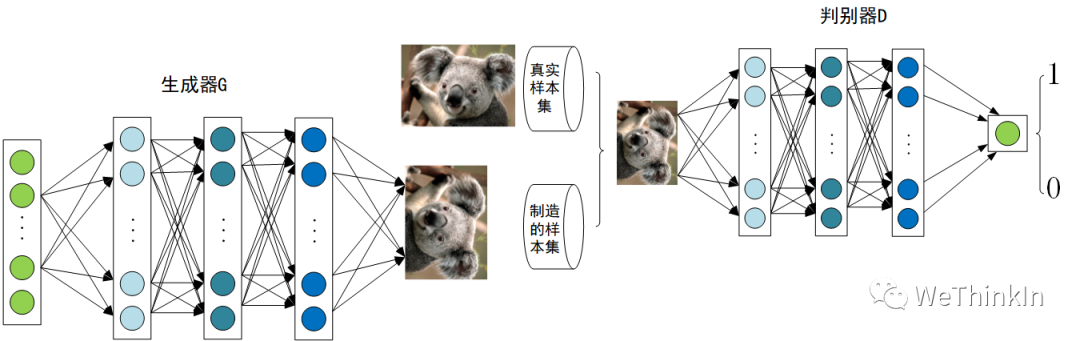
在提出GAN的第一篇论文中,生成器被比喻为印假钞票的犯罪分子,判别器则被当作警察。犯罪分子努力让印出的假钞看起来逼真,警察则不断提升对于假钞的辨识能力。二者互相博弈,随着时间的进行,都会越来越强。在图像生成任务中也是如此,生成器不断生成尽可能逼真的假图像。判别器则判断图像是图像,还是生成的图像。二者不断博弈优化,最终生成器生成的图像使得判别器完全无法判别真假。
GAN的对抗思想主要由其目标函数实现。具体公式如下所示:
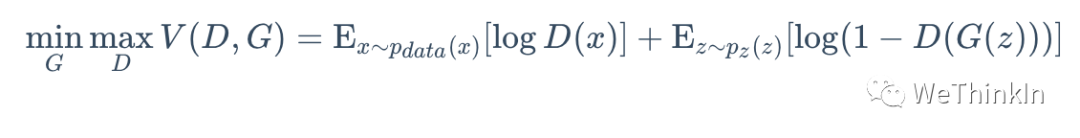
上面这个公式看似复杂,其实不然。跳出细节来看,整个公式的核心逻辑其实就是一个min-max问题,深度学习数学应用的边界扩展到这里,GAN便开始发光了。
接着我们再切入细节。我们可以分两部分开看这个公式,即判别器最小化角度与生成器最大化角度。在判别器角度,我们希望最大化这个目标函数,因为在公示第一部分,其表示样本输入判别器后输出的置信度,当然是越接近越好。而公式的第二部分表示生成器输出的生成样本再输入判别器中进行进行二分类判别,其输出的置信度当然是越接近越好,所以越接近越好。
在生成器角度,我们想要最小化判别器目标函数的最大值。判别器目标函数的最大值代表的是真实数据分布与生成数据分布的JS散度,JS散度可以度量分布的相似性,两个分布越接近,JS散度越小(JS散度是在初始GAN论文中被提出,实际应用中会发现有不足的地方,后来的论文陆续提出了很多的新损失函数来进行优化)
写到这里,大家应该就明白GAN的对抗思想了,下面是初始GAN论文中判别器与生成器损失函数的具体设置以及训练的具体流程:

在图中可以看出,将判别器损失函数离散化,其与交叉熵的形式一致,我们也可以说判别器的目标是最小化交叉熵损失。
【八】面试常问的经典GAN模型?
- 原始GAN及其训练逻辑
- DCGAN
- CGAN
- WGAN
- LSGAN
- PixPix系列
- CysleGAN
- SRGAN系列
【九】FPN(Feature Pyramid Network)的相关知识
FPN的创新点
- 设计特征金字塔的结构
- 提取多层特征(bottom-up,top-down)
- 多层特征融合(lateral connection)
设计特征金字塔的结构,用于解决目标检测中的多尺度问题,在基本不增加原有模型计算量的情况下,大幅度提升小物体(small object)的检测性能。
原来很多目标检测算法都是只采用高层特征进行预测,高层的特征语义信息比较丰富,但是分辨率较低,目标位置比较粗略。假设在深层网络中,最后的高层特征图中一个像素可能对应着输出图像的像素区域,那么小于像素的小物体的特征大概率已经丢失。与此同时,低层的特征语义信息比较少,但是目标位置准确,这是对小目标检测有帮助的。FPN将高层特征与底层特征进行融合,从而同时利用低层特征的高分辨率和高层特征的丰富语义信息,并进行了多尺度特征的独立预测,对小物体的检测效果有明显的提升。
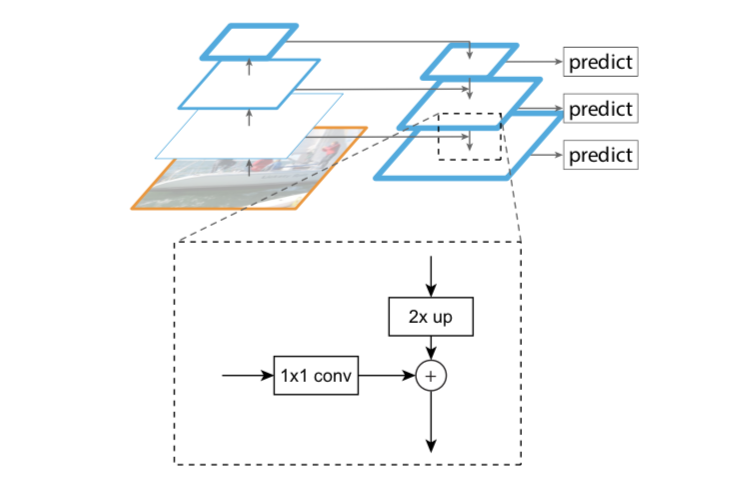
传统解决这个问题的思路包括:
- 图像金字塔(image pyramid),即多尺度训练和测试。但该方法计算量大,耗时较久。
- 特征分层,即每层分别输出对应的scale分辨率的检测结果,如SSD算法。但实际上不同深度对应不同层次的语义特征,浅层网络分辨率高,学到更多是细节特征,深层网络分辨率低,学到更多是语义特征,单单只有不同的特征是不够的。
FPN的主要模块
- Bottom-up pathway(自底向上线路)
- Top-down path(自顶向下线路)
- Lareral connections(横向链路)
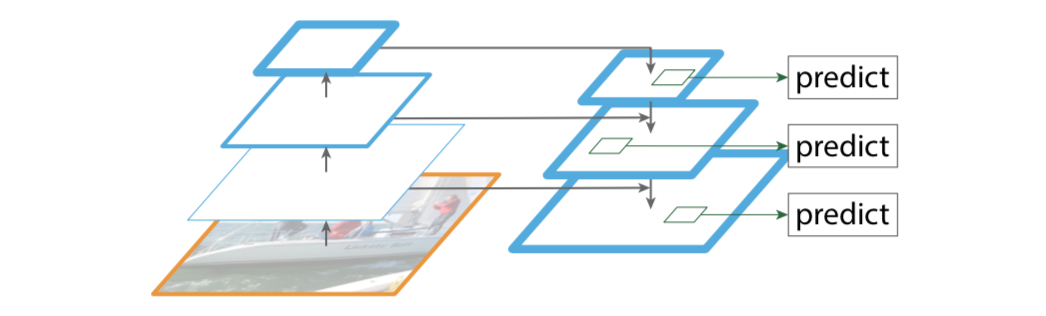
Bottom-up pathway(自底向上线路)
自底向上线路是卷积网络的前向传播过程。在前向传播过程中,feature map的大小可以在某些层发生改变。
Top-down path(自顶向下线路)和Lareral connections(横向链路)
自顶向下线路是上采样的过程,而横向链路是将自顶向下线路的结果和自底向上线路的结构进行融合。
上采样的feature map与相同大小的下采样的feature map进行逐像素相加融合(element-wise addition),其中自底向上的feature先要经过卷积层,目的是为了减少通道维度。
FPN应用
论文中FPN直接在Faster R-CNN上进行改进,其backbone是ResNet101,FPN主要应用在Faster R-CNN中的RPN和Fast R-CNN两个模块中。
FPN+RPN:
将FPN和RPN结合起来,那RPN的输入就会变成多尺度的feature map,并且在RPN的输出侧接多个RPN head层用于满足对anchors的分类和回归。
FPN+Fast R-CNN:
Fast R-CNN的整体结构逻辑不变,在backbone部分引入FPN思想进行改造。
【十】SPP(Spatial Pyramid Pooling)的相关知识
在目标检测领域,很多检测算法最后使用了全连接层,导致输入尺寸固定。当遇到尺寸不匹配的图像输入时,就需要使用crop或者warp等操作进行图像尺寸和算法输入的匹配。这两种方式可能出现不同的问题:裁剪的区域可能没法包含物体的整体;变形操作造成目标无用的几何失真等。
而SPP的做法是在卷积层后增加一个SPP layer,将features map拉成固定长度的feature vector。然后将feature vector输入到全连接层中。以此来解决上述的尴尬问题。
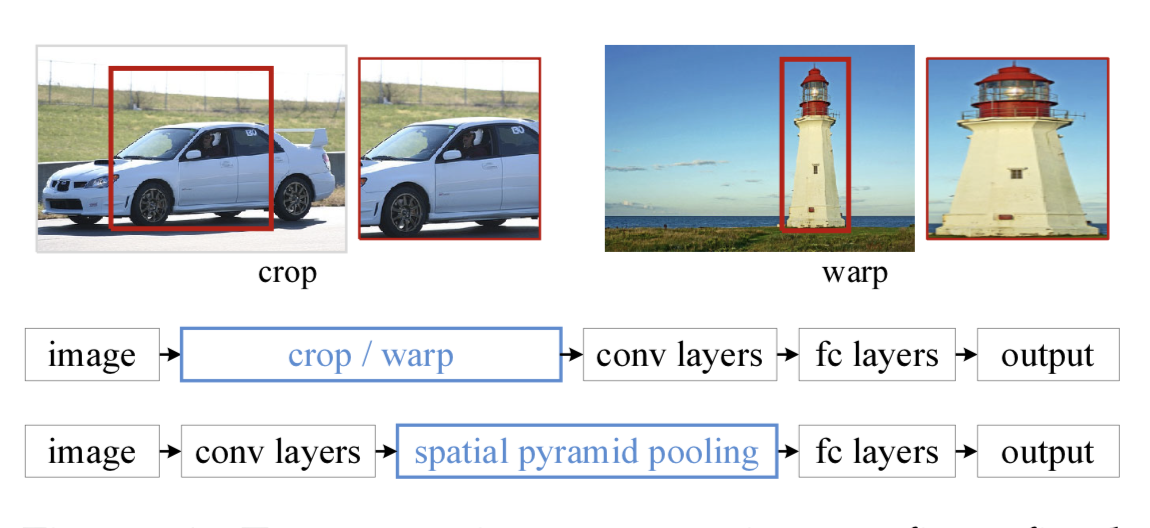
SPP的优点:
- SPP可以忽略输入尺寸并且产生固定长度的输出。
- SPP使用多种尺度的滑动核,而不是只用一个尺寸的滑动窗口进行pooling。
- SPP在不同尺寸feature map上提取特征,增大了提取特征的丰富度。
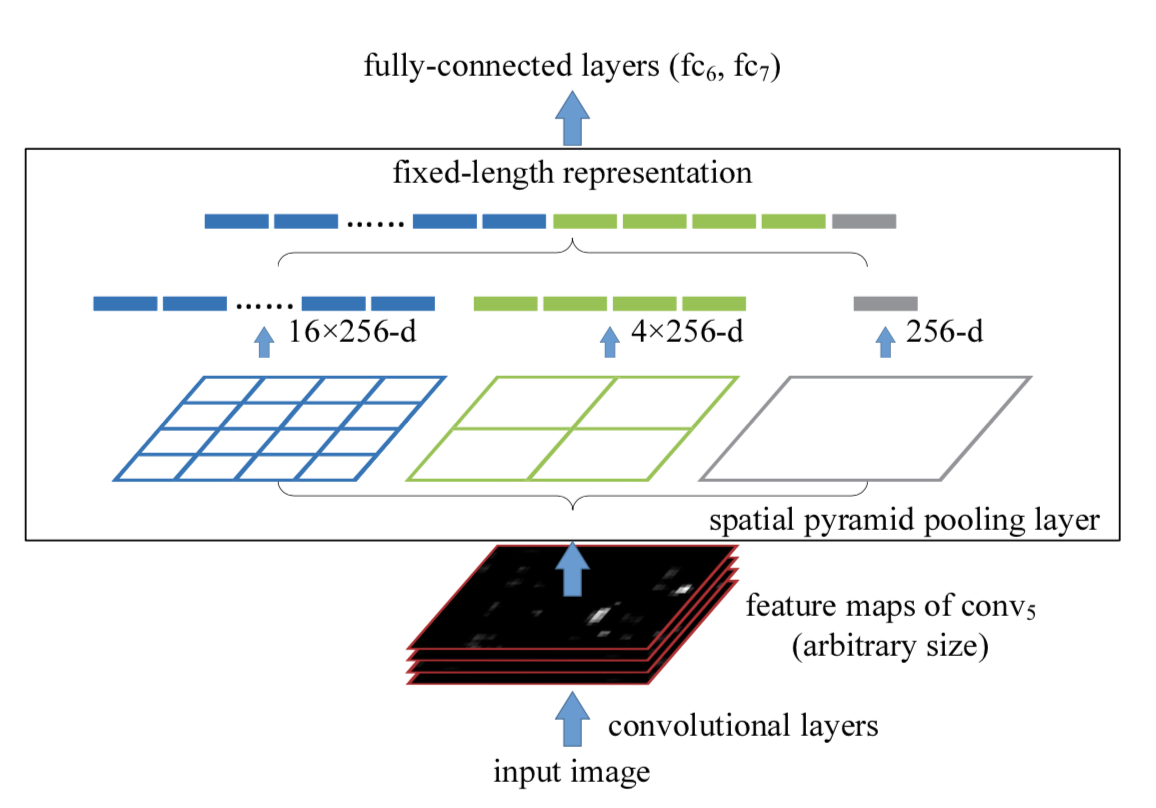
在YOLOv4中,对SPP进行了创新使用,Rocky已在【Make YOLO Great Again】YOLOv1-v7全系列大解析(Neck篇)中详细讲解,大家可按需取用~
【十一】目标检测中AP,AP50,AP75,mAP等指标的含义
AP:PR曲线下的面积。
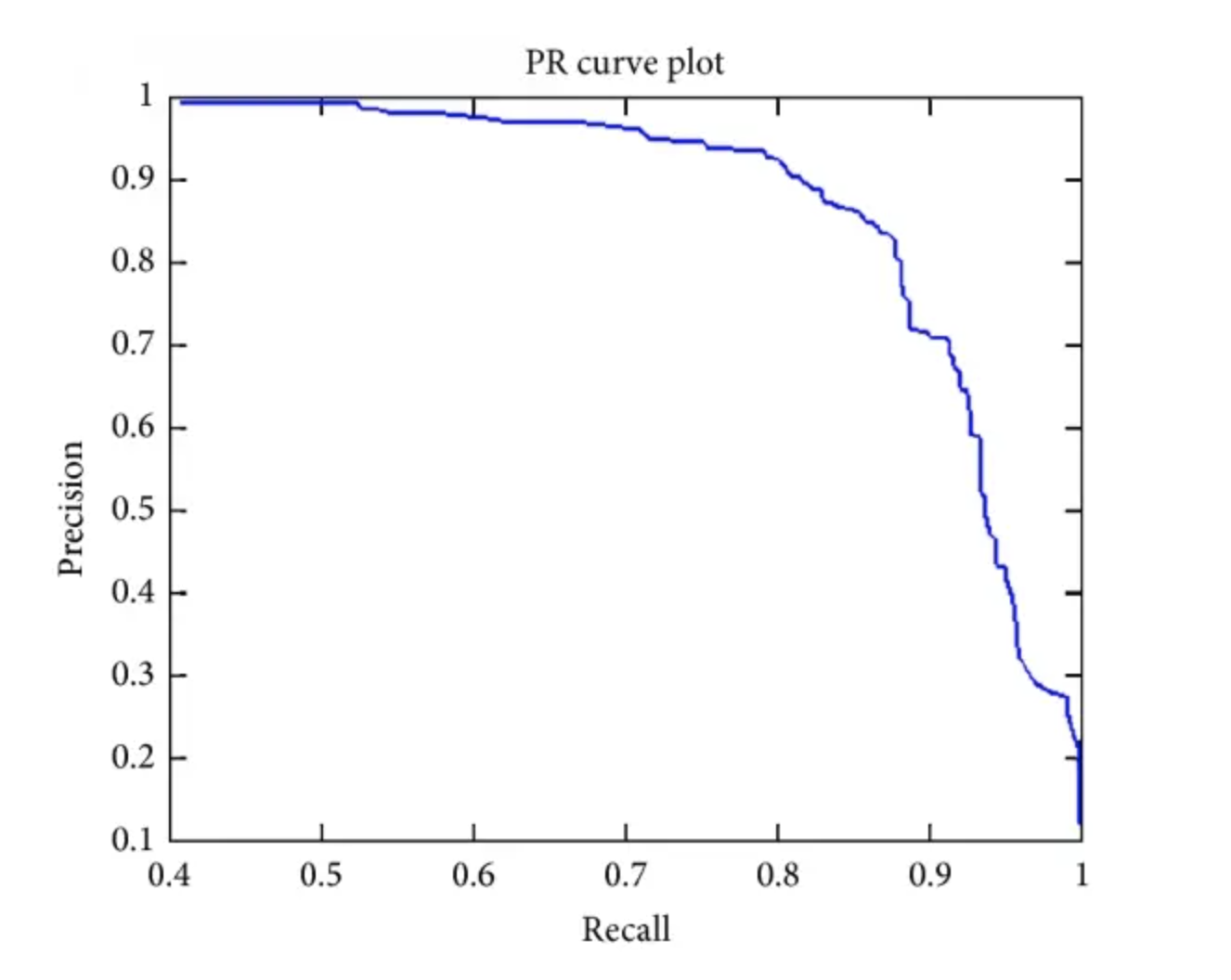
AP50: 固定IoU为50%时的AP值。
AP75:固定IoU为75%时的AP值。
AP@[0.5:0.95]:把IoU的值从50%到95%每隔5%进行了一次划分,并对这10组AP值取平均。
mAP:对所有的类别进行AP的计算,然后取均值。
mAP@[.5:.95](即mAP@[.5,.95]):表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。
【十二】YOLOv2中的anchor如何生成?
YOLOv2中引入K-means算法进行anchor的生成,可以自动找到更好的anchor宽高的值用于模型训练的初始化。
但如果使用经典K-means中的欧氏距离作为度量,意味着较大的Anchor会比较小的Anchor产生更大的误差,聚类结果可能会偏离。
由于目标检测中主要关心anchor与ground true box(gt box)的IOU,不关心两者的大小。因此,使用IOU作为度量更加合适,即提高IOU值。因此YOLOv2采用IOU值为评判标准:
具体anchor生成步骤与经典K-means大致相同,在下一个章节中会详细介绍。主要的不同是使用的度量是,并将anchor作为簇的中心。
【十三】目标检测中IOU的相关概念与计算
IoU(Intersection over Union)即交并比,是目标检测任务中一个重要的模块,其是GT bbox与pred bbox交集的面积 / 二者并集的面积。

下面我们用坐标(top,left,bottom,right),即左上角坐标,右下角坐标。从而可以在给定的两个矩形中计算IOU值。
def compute_iou(rect1,rect2):
# (y0,x0,y1,x1) = (top,left,bottom,right)
S_rect1 = (rect1[2] - rect1[0]) * (rect1[3] - rect1[1])
S_rect2 = (rect2[2] - rect2[0]) * (rect2[3] - rect1[1])
sum_all = S_rect1 + S_rect2
left_line = max(rect1[1],rect2[1])
right_line = min(rect1[3],rect2[3])
top_line = max(rect1[0],rect2[0])
bottom_line = min(rect1[2],rect2[2])
if left_line >= right_line or top_line >= bottom_line:
return 0
else:
intersect = (right_line - left_line) * (bottom_line - top_line)
return (intersect / (sum_area - intersect)) * 1.0
【十四】目标检测中NMS的相关概念与计算
在目标检测中,我们可以利用非极大值抑制(NMS)对生成的大量候选框进行后处理,去除冗余的候选框,得到最具代表性的结果,以加快目标检测的效率。
如下图所示,消除多余的候选框,找到最佳的bbox:

非极大值抑制(NMS)流程:
-
首先我们需要设置两个值:一个Score的阈值,一个IOU的阈值。
-
对于每类对象,遍历该类的所有候选框,过滤掉Score值低于Score阈值的候选框,并根据候选框的类别分类概率进行排序:。
-
先标记最大概率矩形框F是我们要保留下来的候选框。
-
从最大概率矩形框F开始,分别判断A~E与F的交并比(IOU)是否大于IOU的阈值,假设B、D与F的重叠度超过IOU阈值,那么就去除B、D。
-
从剩下的矩形框A、C、E中,选择概率最大的E,标记为要保留下来的候选框,然后判断E与A、C的重叠度,去除重叠度超过设定阈值的矩形框。
-
就这样重复下去,直到剩下的矩形框没有了,并标记所有要保留下来的矩形框。
-
每一类处理完毕后,返回步骤二重新处理下一类对象。
import numpy as np
def py_cpu_nms(dets, thresh):
#x1、y1(左下角坐标)、x2、y2(右上角坐标)以及score的值
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
#每一个候选框的面积
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
#按照score降序排序(保存的是索引)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
#计算当前概率最大矩形框与其他矩形框的相交框的坐标,会用到numpy的broadcast机制,得到向量
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
#计算相交框的面积,注意矩形框不相交时w或h算出来会是负数,用0代替
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
#计算重叠度IOU:重叠面积 / (面积1 + 面积2 - 重叠面积)
ovr = inter / (areas[i] + areas[order[1:]] - inter)
#找到重叠度不高于阈值的矩形框索引
inds = np.where(ovr < thresh)[0]
# 将order序列更新,由于前面得到的矩形框索引要比矩形框在原order序列中的索引小1,所以要加1操作
order = order[inds + 1]
return keep
【十五】One-stage目标检测与Two-stage目标检测的区别?
Two-stage目标检测算法:先进行区域生成(region proposal,RP)(一个有可能包含待检物体的预选框),再通过卷积神经网络进行样本分类。其精度较高,速度较慢。
主要逻辑:特征提取—>生成RP—>分类/定位回归。
常见的Two-stage目标检测算法有:Faster R-CNN系列和R-FCN等。
One-stage目标检测算法:不用RP,直接在网络中提取特征来预测物体分类和位置。其速度较快,精度比起Two-stage算法稍低。
主要逻辑:特征提取—>分类/定位回归。
常见的One-stage目标检测算法有:YOLO系列、SSD和RetinaNet等。

【十六】哪些方法可以提升小目标检测的效果?
-
提高图像分辨率。小目标在边界框中可能只包含几个像素,那么能通过提高图像的分辨率以增加小目标的特征的丰富度。
-
提高模型的输入分辨率。这是一个效果较好的通用方法,但是会带来模型inference速度变慢的问题。
-
平铺图像。

-
数据增强。小目标检测增强包括随机裁剪、随机旋转和镶嵌增强等。
-
自动学习anchor。
-
类别优化。
【十七】ResNet模型的特点以及解决的问题?
每次回答这个问题的时候,都会包含我的私心,我喜欢从电气自动化的角度去阐述,而非计算机角度,因为这会让我想起大学时代的青葱岁月。
ResNet就是一个差分放大器。ResNet的结构设计,思想逻辑,就是在机器学习中抽象出了一个差分放大器,其能让深层网络的梯度的相关性增强,在进行梯度反传时突出微小的变化。
模型的特点则是设计了残差结构,其对模型输出的微小变化非常敏感。

为什么加入残差模块会有效果呢?
假设:如果不使用残差模块,输出为,期望输出为,如果想要学习H函数,使得,这个变化率比较低,学习起来是比较困难的。
但是如果设计为 ,进行一种拆分,使得,那么学习目标就变为让,一个映射函数学习使得它输出由0.1变为0,这个是比较简单的。也就是说引入残差模块后的映射对输出变化更加敏感了。
进一步理解:如果,现在继续训练模型,使得映射函数。变化率为:,如果不用残差模块的话可能要把学习率从0.01设置为0.0000001。层数少还能对付,一旦层数加深的话可能就不太好使了。
这时如果使用残差模块,也就是变化为。这个变化率增加了100%。明显这样的话对参数权重的调整作用更大。
【十八】ResNeXt模型的结构和特点?
ResNeXt模型是在ResNet模型的基础上进行优化。其主要是在ResNeXt中引入Inception思想。如下图所示,左侧是ResNet经典结构,右侧是ResNeXt结构,其将单路卷积转化成多支路的多路卷积,进行分组卷积。
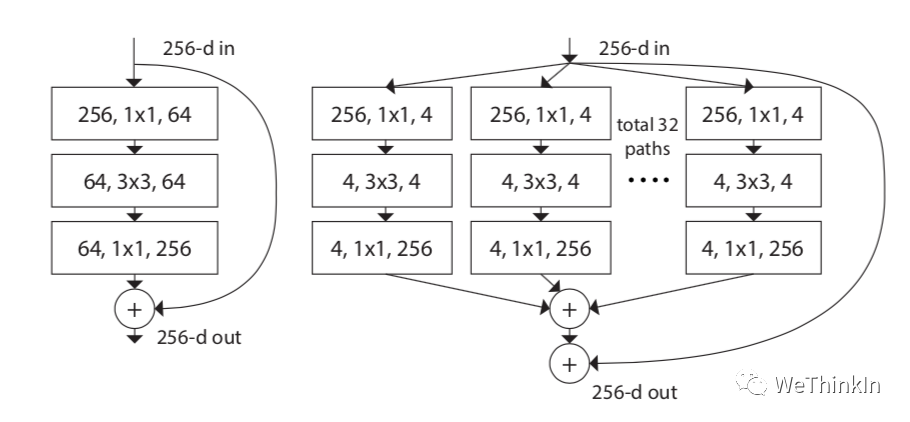
作者进一步提出了ResNeXt的三种等价结构,其中c结构中的分组卷积思想就跃然纸上了。
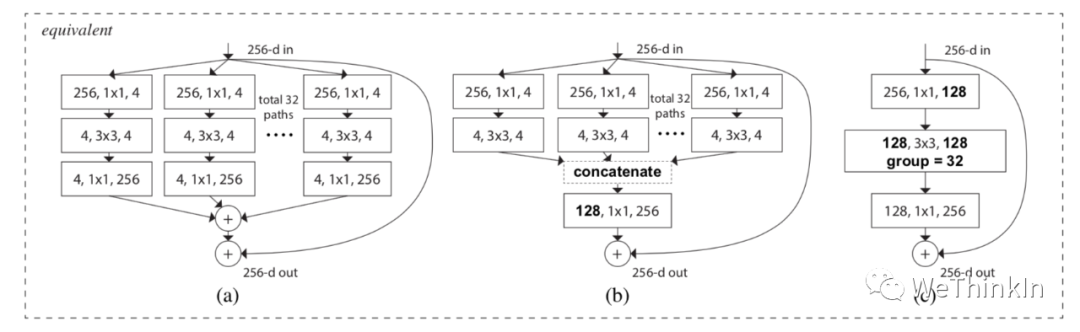
最后我们看一下ResNeXt50和ResNet50结构上差异的对比图:
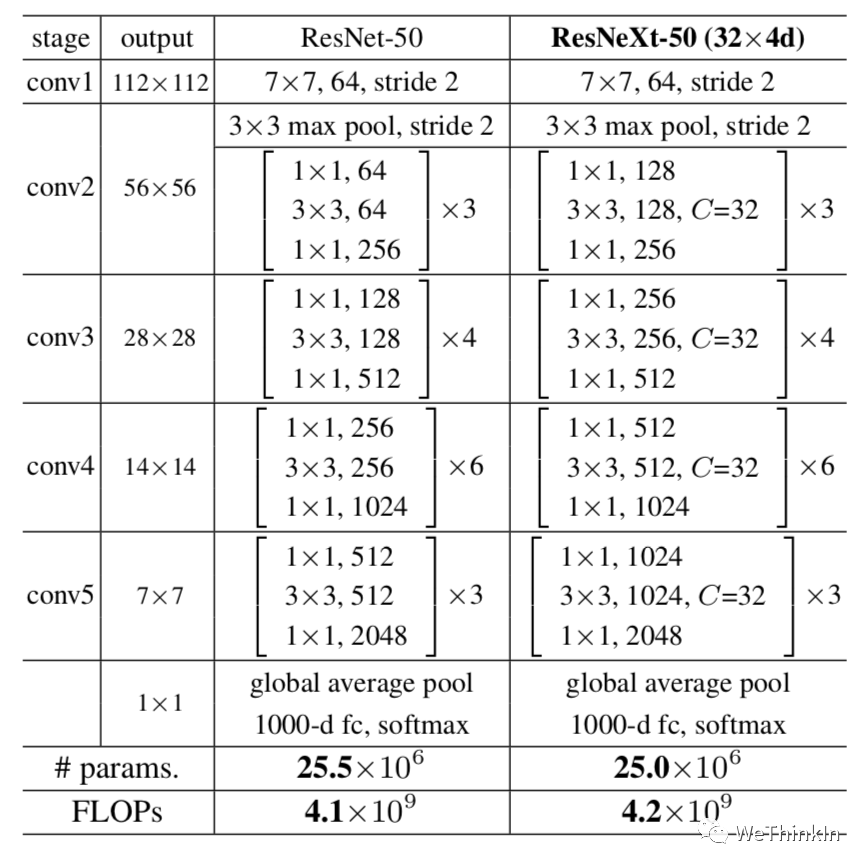
ResNeXt论文:《Aggregated Residual Transformations for Deep Neural Networks》
【十九】MobileNet系列模型的结构和特点?
MobileNet是一种轻量级的网络结构,主要针对手机等嵌入式设备而设计。MobileNetv1网络结构在VGG的基础上使用depthwise Separable卷积,在保证不损失太大精度的同时,大幅降低模型参数量。
Depthwise separable卷积是由Depthwise卷积和Pointwise卷积构成。 Depthwise卷积(DW)能有效减少参数数量并提升运算速度。但是由于每个特征图只被一个卷积核卷积,因此经过DW输出的特征图只包含输入特征图的全部信息,而且特征之间的信息不能进行交流,导致“信息流通不畅”。Pointwise卷积(PW)实现通道特征信息交流,解决DW卷积导致“信息流通不畅”的问题。
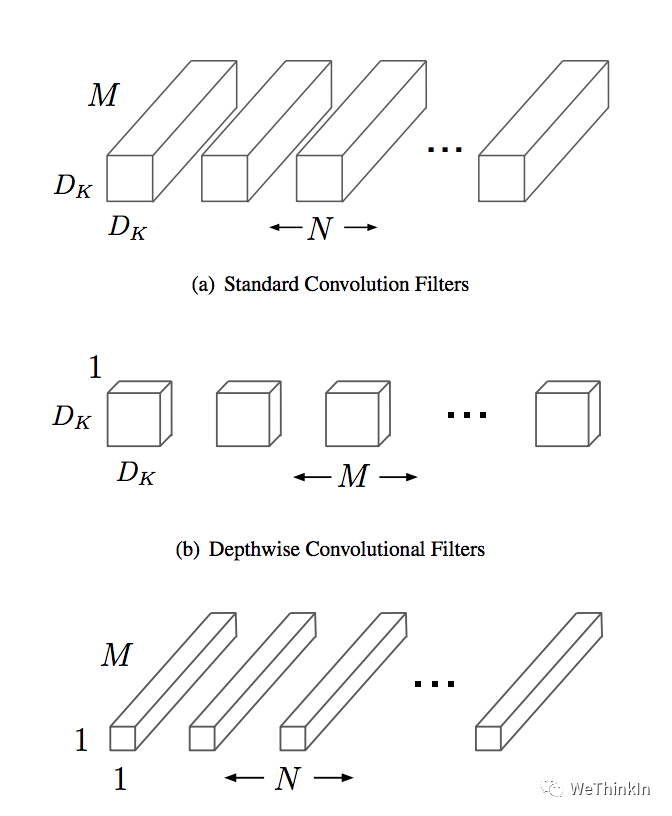
Depthwise Separable卷积和标准卷积的计算量对比:
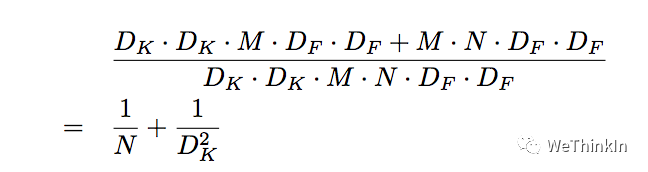
相比标准卷积,Depthwise Separable卷积可以大幅减小计算量。并且随着卷积通道数的增加,效果更加明显。
并且Mobilenetv1使用stride=2的卷积替换池化操作,直接在卷积时利用stride=2完成了下采样,从而节省了卷积后再去用池化操作去进行一次下采样的时间,可以提升运算速度。
MobileNetv1论文:《MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications》
【二十】MobileNet系列模型的结构和特点?(二)
MobileNetV2在MobileNetV1的基础上引入了Linear Bottleneck 和 Inverted Residuals。
MobileNetV2使用Linear Bottleneck(线性变换)来代替原本的非线性激活函数,来捕获感兴趣的流形。实验证明,使用Linear Bottleneck可以在小网络中较好地保留有用特征信息。
Inverted Residuals与经典ResNet残差模块的通道间操作正好相反。由于MobileNetV2使用了Linear Bottleneck结构,使其提取的特征维度整体偏低,如果只是使用低维的feature map效果并不会好。如果卷积层都是使用低维的feature map来提取特征的话,那么就没有办法提取到整体的足够多的信息。如果想要提取全面的特征信息的话,我们就需要有高维的feature map来进行补充,从而达到平衡。

MobileNetV2的论文:《MobileNetV2: Inverted Residuals and Linear Bottlenecks》
MobileNetV3在整体上有两大创新:
1.互补搜索技术组合:由资源受限的NAS执行模块级搜索;由NetAdapt执行局部搜索,对各个模块确定之后网络层的微调。
2.网络结构改进:进一步减少网络层数,并引入h-swish激活函数。
作者发现swish激活函数能够有效提高网络的精度。然而,swish的计算量太大了。作者提出h-swish(hard version of swish)如下所示:
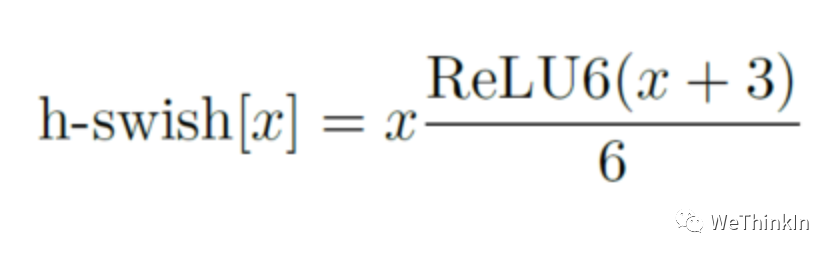
这种非线性在保持精度的情况下带了了很多优势,首先ReLU6在众多软硬件框架中都可以实现,其次量化时避免了数值精度的损失,运行快。
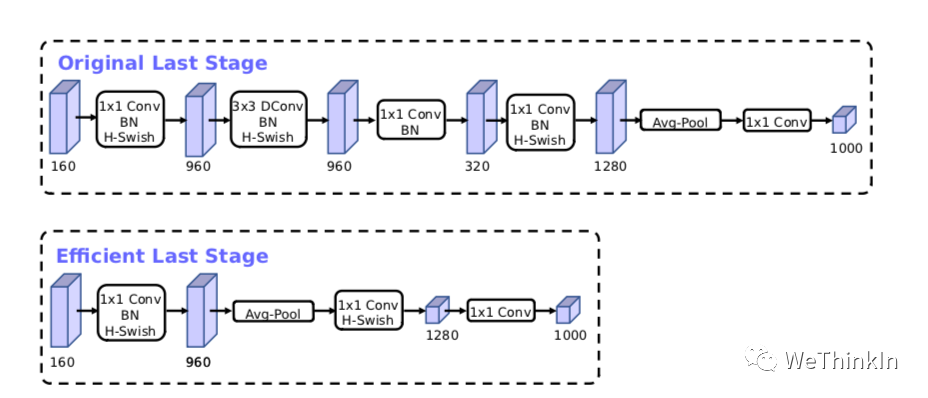
MobileNetV3模型结构的优化:
MobileNetV3的论文:《Searching for MobileNetV3》
【二十一】ViT(Vision Transformer)模型的结构和特点?
ViT模型特点: 1.ViT直接将标准的Transformer结构直接用于图像分类,其模型结构中不含CNN。 2.为了满足Transformer输入结构要求,输入端将整个图像拆分成小图像块,然后将这些小图像块的线性嵌入序列输入网络中。在最后的输出端,使用了Class Token形式进行分类预测。 3.Transformer比CNN结构少了一定的平移不变性和局部感知性,在数据量较少的情况下,效果可能不如CNN模型,但是在大规模数据集上预训练过后,再进行迁移学习,可以在特定任务上达到SOTA性能。
ViT的整体模型结构:

其可以具体分成如下几个部分:
-
图像分块嵌入
-
多头注意力结构
-
多层感知机结构(MLP)
-
使用DropPath,Class Token,Positional Encoding等操作。
【二十二】EfficientNet系列模型的结构和特点?
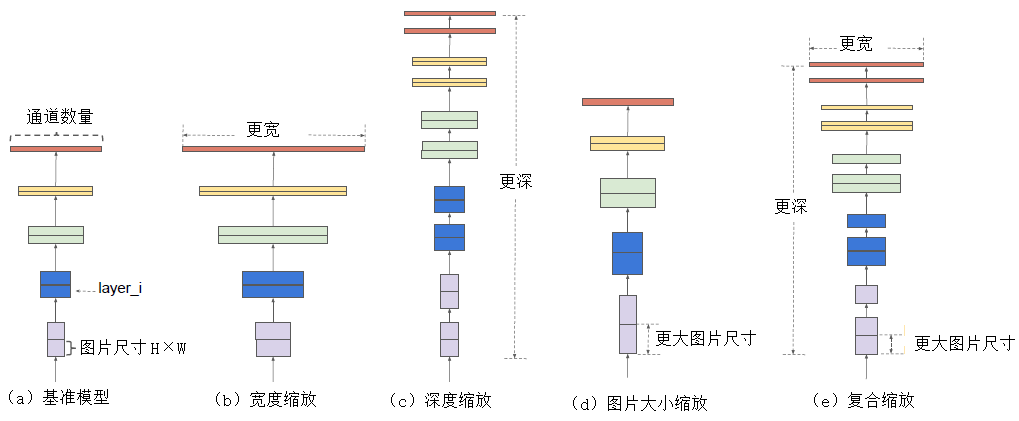
Efficientnet系列模型是通过grid search从深度(depth)、宽度(width)、输入图片分辨率(resolution)三个角度共同调节搜索得来的模型。其从EfficientNet-B0到EfficientNet-L2版本,模型的精度越来越高,同样,参数量和对内存的需求也会随之变大。
深度模型的规模主要是由宽度、深度、分辨率这三个维度的缩放参数决定的。这三个维度并不是相互独立的,对于输入的图片分辨率更高的情况,需要有更深的网络来获得更大的感受视野。同样的,对于更高分辨率的图片,需要有更多的通道来获取更精确的特征。
EfficientNet模型的内部是通过多个MBConv卷积模块实现的,每个MBConv卷积模块的具体结构如下图所示。其用实验证明Depthwise Separable卷积在大模型中依旧非常有效;Depthwise Separable卷积较于标准卷积有更好的特征提取表达能力。

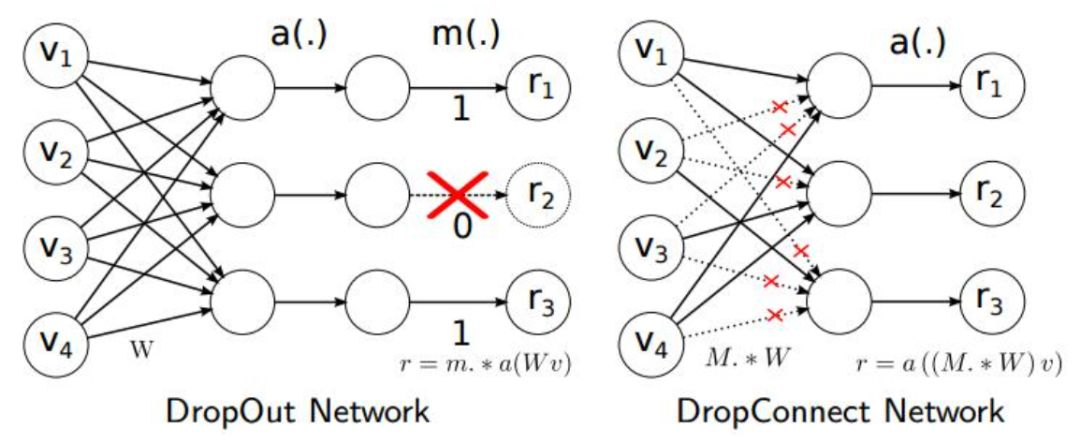
另外论文中使用了Drop_Connect方法来代替传统的Dropout方法来防止模型过拟合。DropConnect与Dropout不同的地方是在训练神经网络模型过程中,它不是对隐层节点的输出进行随机的丢弃,而是对隐层节点的输入进行随机的丢弃。
EfficientNet论文:《EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks》
说点题外话,隔着paper都能看到作者那窒息的调参过程。。。

【二十三】面试常问的经典模型?
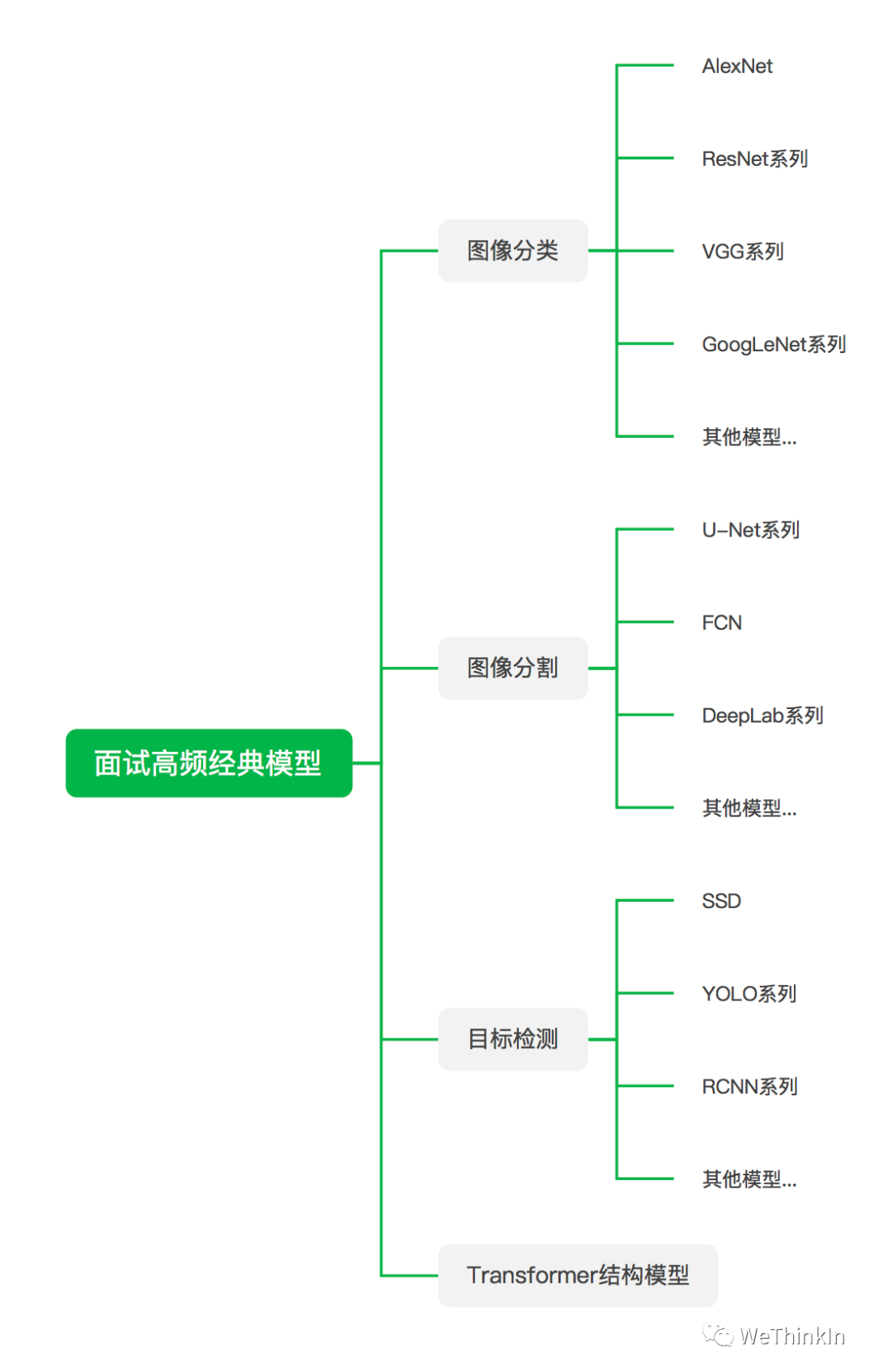
面试中经常会问一些关于模型方面的问题,这也是不太好量化定位的问题,因为模型繁杂多样,面试官问哪个都有可能,下面的逻辑图里我抛砖引玉列出了一些不管是在学术界还是工业界都是高价值的模型,供大家参考。
最好还是多用项目,竞赛,科研等工作润色简历,并在面试过程中将模型方面的问题引向这些工作中用到的熟悉模型里。

三年面试五年模拟之独孤九剑秘籍专注于分享算法工程师校招/社招/实习中会遇到的高价值知识点。关注本专栏,不仅能助你拿到心仪的offer,也能让你构建算法工程师的完整知识结构。



