KMeans讲讲,KMeans有什么缺点,K怎么确定

缺点
- 在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
- 必须事先给出K,而且对初值敏感,对于不同的初始值,结果可能不不同
- 只能发现球状Cluster,不适合于发现非凸形状的簇或者大小差别很大的簇(DBSCAN算法克服了这个弱点,可以发现任意图形的族)
- 对噪声和孤立点数据敏感,如簇中含有异常点,将导致均值偏离严重。因为均值体现的
是数据集的整体特征,容易掩盖数据本身的特性。比如数组1,2,3,4,100的均值为
22,显然距离“大多数”数据1、2、3、4比较远,如果改成数组的中位数3,在该实例中更为稳妥,这种聚类也叫作K-mediods聚类
确定K个初始类簇中心点
最简单的确定初始类簇中心点的方法是随机选择K个点作为初始的类簇中心点,但是该方法在有些情况下的效果较差,如下(下图中的数据是用五个二元正态高斯分布生成的,颜色代表聚类效果):
《大数据》一书中提到K个初始类簇点的选取还有两种方法:1)选择彼此距离尽可能远的K个点 2)先对数据用层次聚类算法或者Canopy算法进行聚类,得到K个簇之后,从每个类簇中选择一个点,该点可以是该类簇的中心点,或者是距离类簇中心点最近的那个点。
1) 选择批次距离尽可能远的K个点
首先随机选择一个点作为第一个初始类簇中心点,然后选择距离该点最远的那个点作为第二个初始类簇中心点,然后再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
该方法经过我测试效果很好,用该方法确定初始类簇点之后运行KMeans得到的结果全部都能完美区分五个类簇: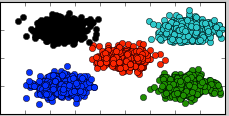
2) 选用层次聚类或者Canopy算法进行初始聚类,然后利用这些类簇的中心点作为KMeans算法初始类簇中心点。
常用的层次聚类算法有BIRCH和ROCK,在此不作介绍,下面简单介绍一下Canopy算法,主要摘自Mahout的Wiki:
首先定义两个距离T1和T2,T1>T2.从初始的点的集合S中随机移除一个点P,然后对于还在S中的每个点I,计算该点I与点P的距离,如果距离小于T1,则将点I加入到点P所代表的Canopy中,如果距离小于T2,则将点I从集合S中移除,并将点I加入到点P所代表的Canopy中。迭代完一次之后,重新从集合S中随机选择一个点作为新的点P,然后重复执行以上步骤。
Canopy算法执行完毕后会得到很多Canopy,可以认为每个Canopy都是一个Cluster,与KMeans等硬划分算法不同,Canopy的聚类结果中每个点有可能属于多个Canopy。我们可以选择距离每个Canopy的中心点最近的那个数据点,或者直接选择每个Canopy的中心点作为KMeans的初始K个类簇中心点。
k值的确定
《大数据》中提到:给定一个合适的类簇指标,比如平均半径或直径,只要我们假设的类簇的数目等于或者高于真实的类簇的数目时,该指标上升会很缓慢,而一旦试图得到少于真实数目的类簇时,该指标会急剧上升。
- 类簇的直径是指类簇内任意两点之间的最大距离。
- 类簇的半径是指类簇内所有点到类簇中心距离的最大值。
下图是当K的取值从2到9时,聚类效果和类簇指标的效果图:

左图是K取值从2到7时的聚类效果,右图是K取值从2到9时的类簇指标的变化曲线,此处我选择类簇指标是K个类簇的平均质心距离的加权平均值。从上图中可以明显看到,当K取值5时,类簇指标的下降趋势最快,所以K的正确取值应该是5.
部分内容转于:博客
编辑于 2019-04-21 19:44:36
回复(0)


问题信息



-

扫描二维码,关注牛客网
- 意见反馈
-

下载牛客APP,随时随地刷题



扫一扫,把题目装进口袋
- 求职之前,先上牛客
-
扫描二维码,进入QQ群

扫描二维码,关注牛客公众号

- 公司地址:北京市朝阳区北苑路北美国际商务中心K1座一层-北京牛客科技有限公司
- 联系方式:010-60728802 投诉举报电话:010-57596212(朝阳人力社保局)
- 牛客科技© All rights reserved admin@nowcoder.com
- 京ICP备14055008号-4 增值电信业务经营许可证 营业执照 人力资源服务许可证
-
 京公网安备
11010502036488号
京公网安备
11010502036488号