
百度2024秋招机器学习一面面经
百度2024秋招机器学习一面面经
岗位:机器学习/数据挖掘/NLP-T联合
一面
-
自我介绍
-
对项目和实习的大概询问,没有去深挖,只是对一些问题进行询问
-
询问对大模型的了解,讲了 RLHF 的原理
-
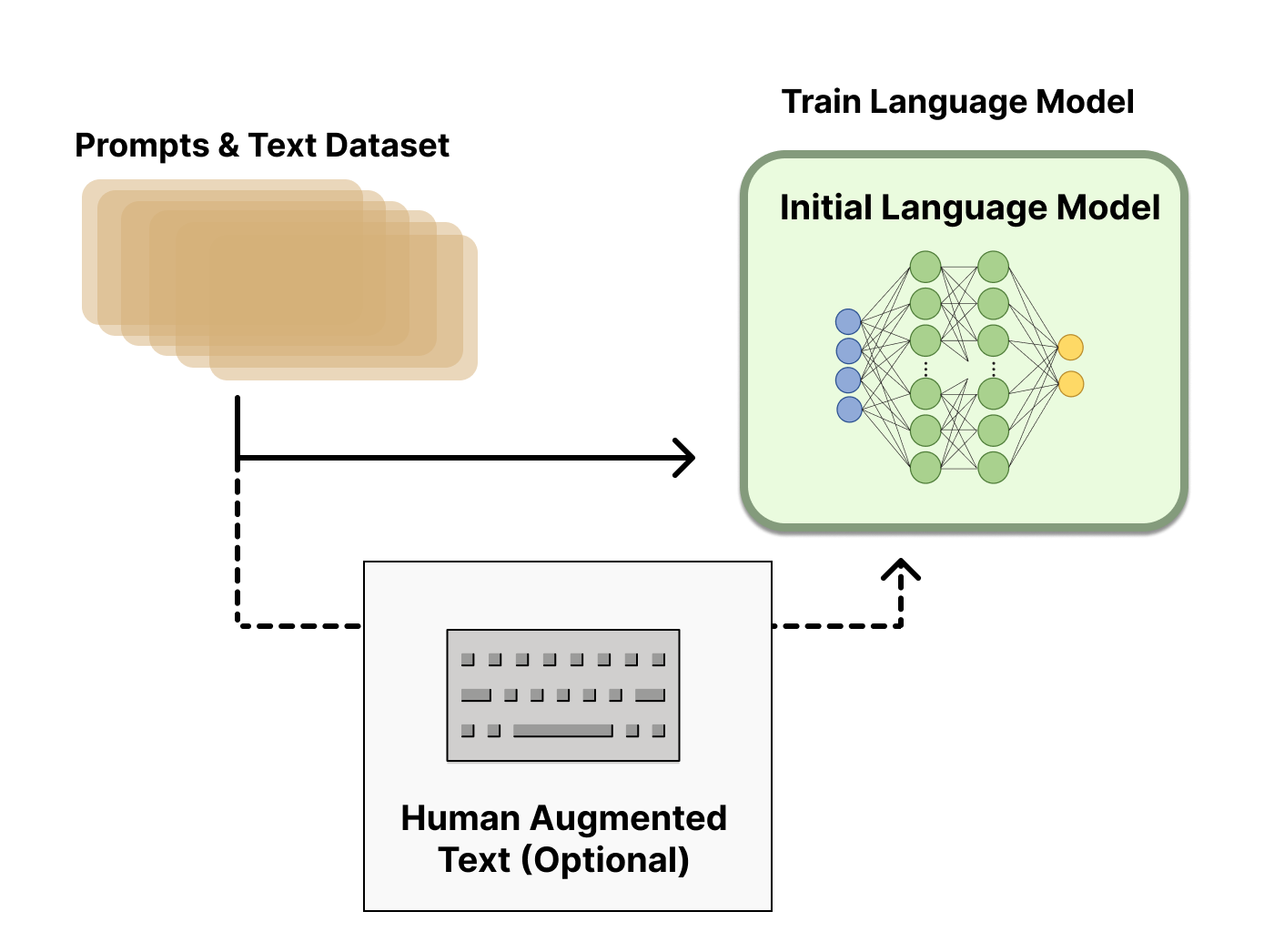
RLHF是一种新的训练范式,通过使用强化学习方式根据人类反馈来优化语言模型。一共包括三个步骤:
- 预训练一个语言模型(LM)
- 收集数据并训练奖励模型 (Reward Model,RM)
- 用强化学习 (RL) 方式微调语言模型(LM)
-
使用一个已经用经典的预训练目标进行了预训练的语言模型,在 InstructGPT 中就是使用的 GPT-3 版本的预训练模型;
-
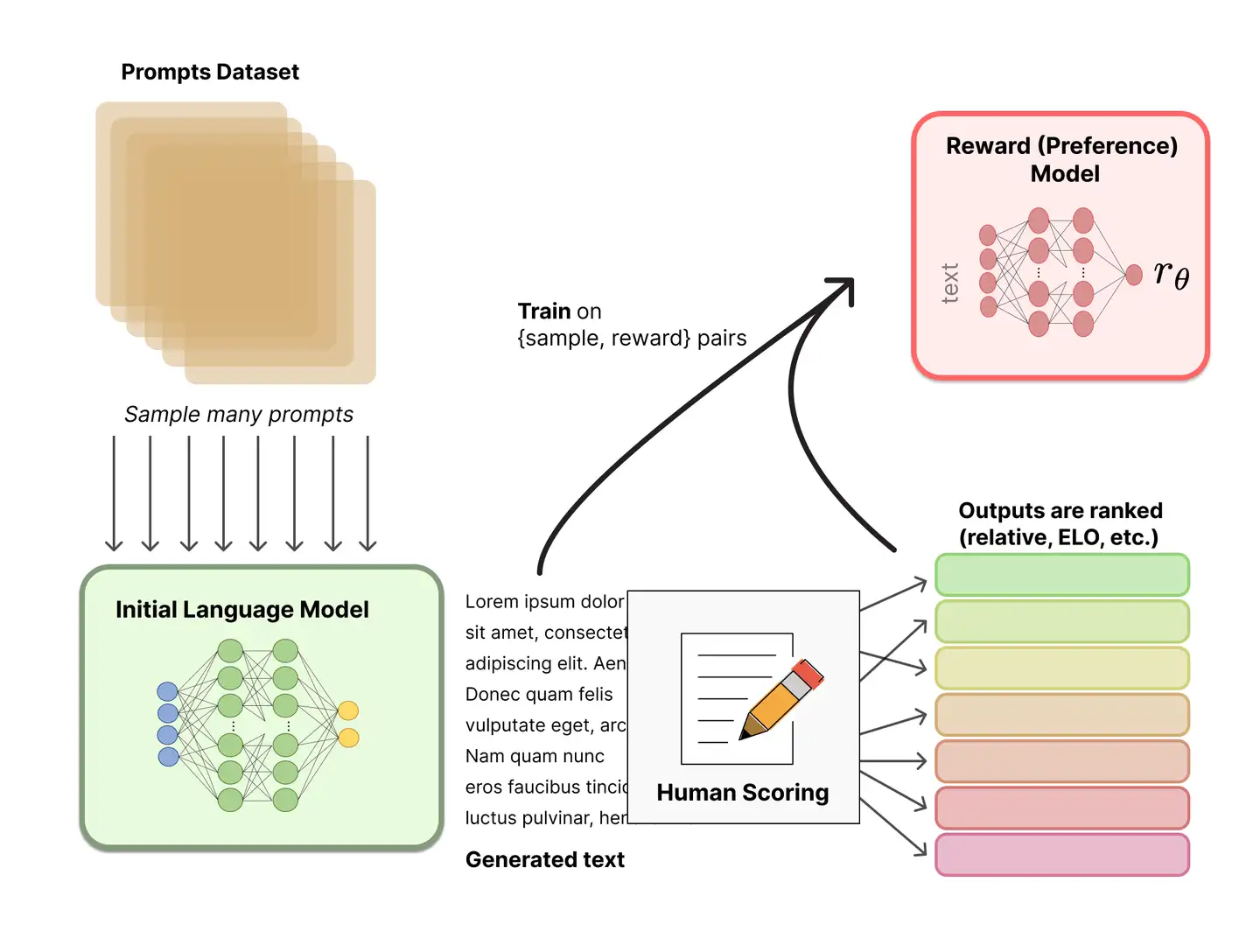
生成一个用人类偏好校准的奖励模型(RM,也称为偏好模型)是RLHF中相对较新的研究开始的地方。基本目标是获得一个模型或系统,该模型或系统接收一系列文本,并返回标量奖励,该奖励应在数字上代表人类偏好。该系统可以是端到端LM,也可以是输出奖励的模块化系统(例如,模型对输出进行排序,并将排序转换为奖励)。标量奖励的输出对于RLHF过程中稍后无缝集成的现有RL算法至关重要。当前主要使用的是人工进行排序的方式,而不是标注分数的方式。
-
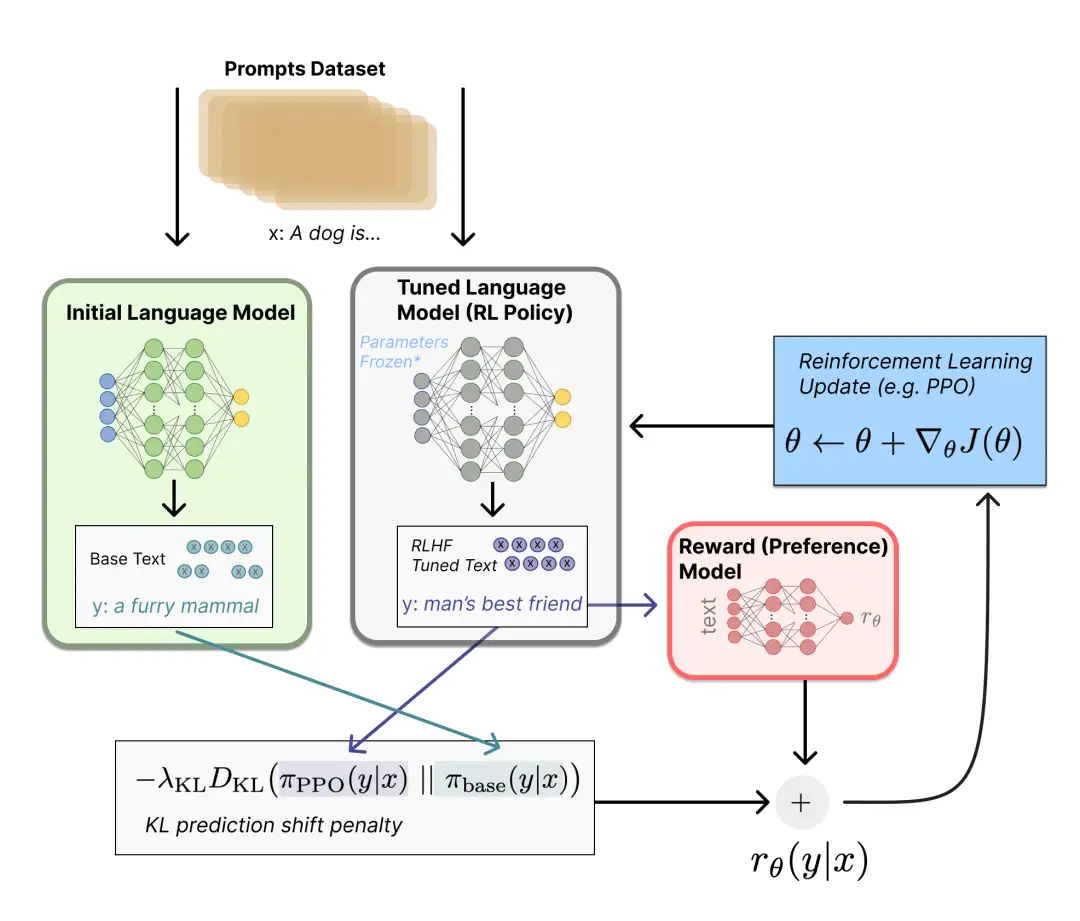
使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数。将微调任务表述为 RL 问题。首先,该策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,奖励函数是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
-
-
详细讲一下 PPO 算法
-
PPO(Proximal Policy Optimization)算法是一种常用的策略梯度强化学习算法,用于优化策略函数。它通过近端策略优化的方式来提高训练的稳定性和效率。
-
PPO算法的核心思想是在每次更新策略时,通过限制新策略与旧策略之间的差异,来保证更新的幅度不会过大,从而避免策略的剧烈变化。这种限制差异的方式可以通过引入一个剪切函数来实现,常用的剪切函数是克里夫-泰勒展开(Clipped Surrogate Objective)。
-
下面是PPO算法的核心公式:
-
其中,
表示剪切后的目标函数,
表示策略函数的参数,
表示对时间步t的期望,
表示策略更新前后的比率,
表示优势函数的估计值,clip函数用于限制差异的范围,
是一个超参数,用于控制剪切的幅度。
-
PPO算法通过最大化剪切后的目标函数来更新策略函数的参数,具体的更新方式可以使用梯度下降等优化算法进行。
-
-
MapReduce 的问题,在 reduce 阶段如何将数据的相同的每一列合并到同一个 partition 上。没听懂题目,没回答上来。
- 在 MapReduce 中,reduce 阶段是用于对 map 阶段输出的中间结果进行合并和处理的阶段。在 reduce 阶段,数据会按照 key 进行分组,即具有相同 key 的数据会被分配到同一个 reduce task 中进行处理。
- 在默认情况下,MapReduce 框架会根据 key 的哈希值将数据分配到不同的 reduce task 中。这意味着具有相同 key 的数据可能会被分配到不同的 partition 中。如果希望将具有相同列值的数据合并到同一个 partition 中,可以通过自定义分区函数来实现。
- 自定义分区函数可以根据数据的列值来确定数据应该被分配到哪个 partition 中。具体而言,可以在自定义分区函数中根据数据的列值计算出一个哈希值,并将该哈希值作为分区的标识。这样,具有相同列值的数据就会被分配到同一个 partition 中。
- 通过将具有相同列值的数据合并到同一个 partition 中,可以方便地对这些数据进行进一步的处理和分析。同时,这也可以减少数据在网络中的传输量,提高 MapReduce 的效率。
-
大数据的机器学习流程
- 使用 HIVE SQL 查询数据表;
- 将数据表写成 ETL 转成 HIVE 表的视图,这一步的作用是,ETL 一天执行一次,将数据倾斜的问题提前,提高后续操作的速度;
- 通过 Pyspark 调用spark SQL 方式读取视图,并与处理数据,将数据保存成 libsvm;
- 读取 libsvm 数据,开发分布式机器学习模型
-
介绍一下 CGC 模型以及 MMOE 模型
- CGC模型(Customized Gate Control Model)是一种共享结构设计的渐进式分层提取(PLE)模型的一部分。它通过显式分离任务共享专家部分和任务独享专家部分来实现与单任务相似的性能。CGC模型包含多个任务相关的多层塔网络和多个专家模块。专家模块分为任务共享的专家模块和任务独享的专家模块。每个塔网络从所有专家模块学习知识。CGC模型使用门控网络来融合所有专家模块的输出。门控网络是一个单层前馈网络,使用softmax作为激活函数。它基于输入生成选择概率,并基于选择概率融合所有专家模块的输出。
- MMOE 同样是一个多任务模型,只有共享专家模块,没有任务独立专家部分。CGC 模型是在 MMOE 的基础上改进的。
-
对现在的 AIGC有什么认识
- 文本生成:ChatGPT、文言一心
- 图像生成:DALL-E、MidJourney、Stable Diffusion、DragGAN(最新的技术)
- 多模态生成:DALL-E、MidJourney、Stable Diffusion
-
介绍一下 BERT 与 GPT 的区别
- BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)是两种常见的自然语言处理模型,它们在设计和应用上存在一些区别。
- 模型结构:
- BERT:BERT是一种双向的Transformer编码器模型。它通过预训练和微调的方式,能够学习到丰富的语言表示。BERT的输入是一段文本,输出是每个输入标记的上下文相关表示。
- GPT:GPT是一种基于Transformer的解码器生成模型。它通过预训练和微调的方式,能够生成连贯的文本。GPT的输入是一个上下文序列,输出是下一个标记的概率分布。
- 预训练任务:
- BERT:BERT使用了两个预训练任务,即Masked Language Model(MLM)和Next Sentence Prediction(NSP)。MLM任务要求模型预测被遮盖的标记,以学习上下文相关的表示。NSP任务要求模型判断两个句子是否是连续的。
- GPT:GPT使用了单一的预训练任务,即语言建模。语言建模任务要求模型根据前面的标记预测下一个标记,以学习语言的概率分布。
- 应用领域:
- BERT:BERT在自然语言处理领域广泛应用,包括文本分类、命名实体识别、问答系统等。它的双向编码能力使得它在理解上下文相关性方面表现出色。
- GPT:GPT在生成文本方面表现出色,常用于文本生成、机器翻译、对话系统等任务。它的生成能力使得它能够生成连贯、富有创造性的文本。
- 模型结构:
- BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)是两种常见的自然语言处理模型,它们在设计和应用上存在一些区别。
-
如何理解当初BERT 大热,GPT 不被看好,到现在 GPT 大热,BERT 备受冷落
- 这个就是仁者见仁智者见智了,我就大致回答了风水轮流转,迟早到我家,哈哈哈哈。
- 技术没有大热和冷落之分,只是当前时代的潮流而已。现在依旧有很多将 19xx 年的技术拿过来用在新模型上,可以具体结合自己的方向谈谈。多年之后,BERT 也有可能再次翻身。
-
查找链表的倒数第 k 个节点
-
要查找链表的倒数第k个节点,可以使用双指针技巧。我们可以初始化两个指针,slow和fast,都指向链表的头部。然后我们将fast指针向前移动k步。之后,我们同时移动两个指针,直到fast指针到达链表的末尾。此时,slow指针将指向倒数第k个节点。
ListNode* findKthFromEnd(ListNode* head, int k) { ListNode* slow = head; ListNode* fast = head; // Move the fast pointer k steps ahead for (int i = 0; i < k; i++) { if (fast == nullptr) { // Handle the case when k is greater than the length of the linked list return nullptr; } fast = fast->next; } // Move both pointers simultaneously until the fast pointer reaches the end while (fast != nullptr) { slow = slow->next; fast = fast->next; } // At this point, the slow pointer will be pointing to the kth node from the end return slow; }
-
-
如何查找数组的 Top K 数字,考查如何实现堆排序
-
堆排序是一种利用堆这种数据结构进行排序的算法。堆一般指的是二叉堆,是一棵完全二叉树,每个节点的值都大于或等于其子节点的值。堆排序的基本思想是将待排序的序列构造成一个最大堆,然后依次将根节点与待排序序列的最后一个元素交换,并维护堆的性质,最终得到一个递增序列。堆排序的时间复杂度为O(nlogn),是一种不稳定的排序算法。
-
堆排序算法可以通过构造大根堆的方式找到数组中的最大值,并通过固定最大值再构造堆的方式找到数组中的Top K数字。
堆排序的具体步骤如下:
- 构造堆:将无序数组构造成一个大根堆。从最后一个非叶子节点开始,从左至右,从下到上进行调整,使得每个非叶子节点的值都大于其左右孩子节点的值。
- 固定最大值再构造堆:将堆顶元素(最大值)与数组的最后一个元素交换,然后将剩余的元素重新构造成一个大根堆。重复这个过程,直到得到一个有序序列。
-
构建堆:首先,我们需要将无序数组构建成一个大根堆。可以使用数组来表示堆,其中根节点的索引为0,左孩子节点的索引为2i+1,右孩子节点的索引为2i+2(其中i为父节点的索引)。通过从最后一个非叶子节点开始,从右至左,从下到上进行调整,使得每个非叶子节点的值都大于其左右孩子节点的值。
void heapify(int arr[], int n, int i) { int largest = i; // 将当前父节点设为最大值 int left = 2 * i + 1; // 左孩子节点的索引 int right = 2 * i + 2; // 右孩子节点的索引 // 如果左孩子节点大于父节点,则更新最大值的索引 if (left < n && arr[left] > arr[largest]) { largest = left; } // 如果右孩子节点大于父节点,则更新最大值的索引 if (right < n && arr[right] > arr[largest]) { largest = right; } // 如果最大值的索引不是父节点的索引,则交换父节点和最大值节点的值,并递归调整最大值节点的子树 if (largest != i) { swap(arr[i], arr[largest]); heapify(arr, n, largest); } } void buildHeap(int arr[], int n) { // 从最后一个非叶子节点开始,从右至左,从下到上进行调整 for (int i = n / 2 - 1; i >= 0; i--) { heapify(arr, n, i); } } -
堆排序:构建好堆后,我们可以通过固定最大值再构建堆的方式进行堆排序。
void heapSort(int arr[], int n) { // 构建堆 buildHeap(arr, n); // 依次将堆顶元素(最大值)与数组的最后一个元素交换,并重新构建堆 for (int i = n - 1; i > 0; i--) { swap(arr[0], arr[i]); heapify(arr, i, 0); } } -
查找TOP K数字:通过堆排序算法,我们可以得到一个递增序列。然后,取出前K个数字即为TOP K数字。
vector<int> findTopK(int arr[], int n, int k) { vector<int> topK; // 使用堆排序算法对数组进行排序 heapSort(arr, n); // 取出前K个数字 for (int i = n - 1; i >= n - k; i--) { topK.push_back(arr[i]); } return topK; }
-
-
如何实现 KDTree
-
定义KDTree的节点结构,包含一个数据点和一个分割维度。
class Node: def __init__(self, point, split_dimension): self.point = point self.split_dimension = split_dimension self.left = None self.right = None -
构建KD Tree:选择一个分割维度,将数据点划分为两个子集,一个子集包含小于等于分割值的数据点,另一个子集包含大于分割值的数据点。递归地对子集进行构建,直到每个节点只包含一个数据点或子集为空。
def construct_kd_tree(data, depth=0): if not data: return None k = len(data[0]) split_dimension = depth % k data.sort(key=lambda x: x[split_dimension]) median_index = len(data) // 2 median_point = data[median_index] node = Node(median_point, split_dimension) node.left = construct_kd_tree(data[:median_index], depth + 1) node.right = construct_kd_tree(data[median_index + 1:], depth + 1) return node -
搜索KD Tree:给定一个查询点,从根节点开始,根据查询点的值与节点的分割值进行比较,确定下一步搜索的方向。递归地在子树中搜索,直到找到与查询点最近的数据点或搜索到叶子节点为止。
def search_kd_tree(node, query_point, k, depth=0, best_points=None, best_distances=None): if node is None: return best_points, best_distances if best_points is None: best_points = [] if best_distances is None: best_distances = [] k = len(query_point) split_dimension = depth % k if query_point[split_dimension] <= node.point[split_dimension]: next_node = node.left else: next_node = node.right best_points, best_distances = search_kd_tree(next_node, query_point, k, depth + 1, best_points, best_distances) current_distance = distance(query_point, node.point) if len(best_points) < k or current_distance < best_distances[-1]: insert_index = bisect_left(best_distances, current_distance) best_points.insert(insert_index, node.point) best_distances.insert(insert_index, current_distance) if len(best_points) > k: best_points.pop() best_distances.pop() opposite_node = node.right if next_node == node.left else node.left if opposite_node is not None: opposite_distance = abs(node.point[split_dimension] - query_point[split_dimension]) if len(best_points) < k or opposite_distance < best_distances[-1]: best_points, best_distances = search_kd_tree(opposite_node, query_point, k, depth + 1, best_points, best_distances) return best_points, best_distances def distance(point1, point2): return sum((a - b) ** 2 for a, b in zip(point1, point2)) ** 0.5
-
-
编程题:三数之和,target 不是 0
vector<vector<int>> gettreenum(vector<int>& nums,int target){ sort(nums.begin(),nums.end()); //对数组进行排序 vector<vector<int>> res; //保存结果 for(int i=0;i<nums.size();i++){ if(nums[i]>target&&(nums[i]>=0||target>=0))break; // 剪枝 if(i>0&&nums[i]==nums[i-1])continue; // 对第一个数据进行去重 // 双指针方法 int left = i+1; int right = nums.size()-1; while(left<right){ int sum = nums[i]+nums[left]+nums[right]; if(sum<target)left++; // 数据总和小于目标值,left增加 else if(sum>target)right--; // 数据总和大于目标值,right 减少 else{ res.push_back({nums[i],nums[left],nums[right]}) while(left<right&&nums[left]==nums[left+1])left++; // 第二个数去重 while(left<right&&nums[right]==nums[right-1])right--; // 第三个数去重 left++; right--; } } } return res; } -
Linux编程题:计算文档最后一列数据的均值
awk '{ sum += $NF } END { avg = sum / $NR; print avg }' filename其中,
$NF表示当前行的最后一列数据,sum用于累加最后一列的数据,NR表示行数。在END块中,我们将累加的和除以行数得到均值,并将其打印出来。 -
SQL 注入的危害以及预防
- SQL注入是一种常见的安全漏洞,攻击者通过在应用程序的输入中插入恶意的SQL代码,从而可以执行未经授权的数据库操作。为了预防SQL注入攻击,可以采取以下措施:使用参数化查询或预编译语句、输入验证和过滤、最小权限原则、错误处理和日志记录、定期更新和维护。这些措施可以有效减少SQL注入攻击的风险,但并不能保证绝对安全,因此还需要持续关注安全动态并采取相应的安全措施。
-
反问
总结
面试的问题和岗位确实很匹配,三个方面的问题都有问到。除了简历上提到的内容,还是会问 Linux 等内容的。百度的面试官人也不错,整体问题比较基础且全面,体验非常好的的一场面试。
#百度##百度信息集散地##百度2024校园招聘##如何一边实习一边秋招#
 查看11道真题和解析
查看11道真题和解析