人工智能中小样本问题相关的系列模型(一):元学习、小样本学习
目录
【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
【再啰嗦一下】本来只想记一下GAN的笔记,没想到发现了一个大宇宙,很多个人并不擅长,主要是整理归纳!
一、Meta Learning 元学习综述
Meta Learning,又称为 learning to learn,已经成为继 Reinforcement Learning 之后又一个重要的研究分支。
元学习区别于机器学习的是:机器学习通常是在拟合一个数据的分布,而元学习是在拟合一系列相似任务的分布。
本节主要参考了大佬的知乎专栏:https://zhuanlan.zhihu.com/p/28639662
推荐Stanford助理教授Chelsea Finn开设的CS330 multitask and meta learning课程
- 在 Machine Learning 机器学习时代,对于复杂一点的分类问题,模型效果就不好了。
- Deep Learning 深度学习解决了一对一映射问题,但如果输出对下一个输入有影响,也就是sequential decision making问题,单一的深度学习就解决不了了。
- Deep Reinforcement Learning 深度强化学习对序列决策取得成效,但深度强化学习太依赖于巨量的训练,并且需要精确的Reward。
- 人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分利用以往的知识经验来指导新任务的学习,因此 Meta Learning 成为新的攻克方向。
1. 基本概念
元学习是要去学习任务中的特征表示,从而在新的任务上泛化。举个例子,以下图的图像分类来说,元学习的训练过程是在task1和task2上训练模型(更新模型参数),而在训练样本中的训练集一般称作support set,训练样本中的测试集一般叫做query set。测试过程是在测试任务上评估模型好坏,从图中可以看出,测试任务和训练任务内容完全不同。
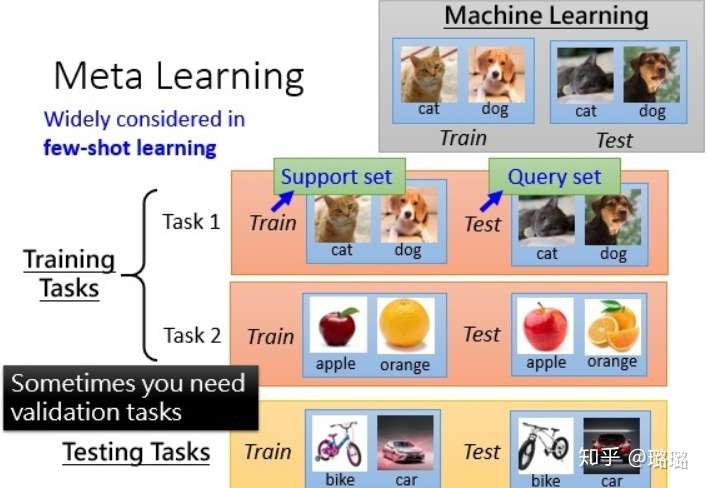
元学习解决的是学习如何学习的问题,元学习的思想是学习「学习(训练)」过程。元学习主要包括Zero-Shot/One-Shot/Few-Shot 学习、模型无关元学习(Model Agnostic Meta Learning)和元强化学习(Meta Reinforcement Learning)等。
- Zero-shot Learing 就是训练样本里没有这个类别的样本,但是如果我们可以学到一个牛逼的映射,这个映射好到我们即使在训练的时候没看到这个类,但是我们在遇到的时候依然能通过这个映射得到这个新类的特征。
- One-shot Learing 就是类别下训练样本只有一个或者很少,我们依然可以进行分类。比如我们可以在一个更大的数据集上或者利用knowledge graph、domain-knowledge 等方法,学到一个一般化的映射,然后再到小数据集上进行更新升级映射。
- Few-Shot Learing 的综述将在下一节重点整理,这里暂时不展开介绍。
元学习的主要方法包括基于记忆Memory的方法、基于预测梯度的方法、利用Attention注意力机制的方法、借鉴LSTM的方法、面向RL的Meta Learning方法、利用WaveNet的方法、预测Loss的方法等。
2. 基于记忆Memory的方法
基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢?
代表方法包括:Meta-learning with memory-augmented neural networks、Meta Networks等。
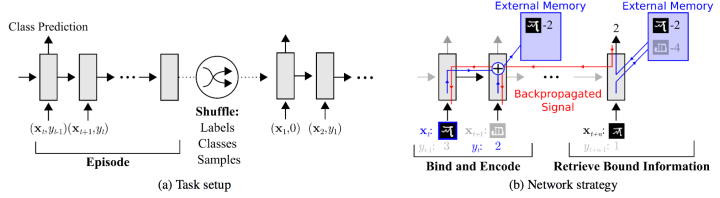
可以看到,网络的输入把上一次的y label也作为输入,并且添加了external memory存储上一次的x输入,这使得下一次输入后进行反向传播时,可以让y label和x建立联系,使得之后的x能够通过外部记忆获取相关图像进行比对来实现更好的预测。
3. 基于预测梯度的方法
基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
代表方法包括:Learning to learn by gradient descent by gradient descent 等。
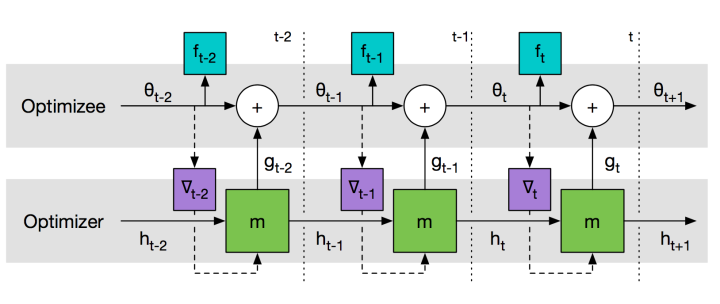
该方法训练一个通用的神经网络来预测梯度,用一次二次方程的回归问题来训练,优化器效果比Adam、RMSProp好,显然就加快了训练。
4. 利用Attention注意力机制的方法
基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
代表方法包括:Matching networks for one shot learning 等。

这篇文章构造一个attention机制,也就是最后的label判断是通过attention的叠加得到的:

attention a 则通过 g 和 f 得到。基本目的就是利用已有任务训练出一个好的attention model。
5. 借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?
代表方法包括:Optimization as a model for few-shot learning 等。
这篇文章的核心思想是下面这一段:

怎么把LSTM的更新和梯度下降联系起来才是更值得思考的问题吧。
6. 面向RL的Meta Learning方法
基本思路:Meta Learning可以用在监督学习,那么增强学习上怎么做呢?能否通过增加一些外部信息比如reward,之前的action来实现?
代表方法包括:Learning to reinforcement learn、Rl2: Fast reinforcement learning via slow reinforcement learning 等。
两篇文章思路一致,就是额外增加reward和之前action的输入,从而强制让神经网络学习一些任务级别的信息:
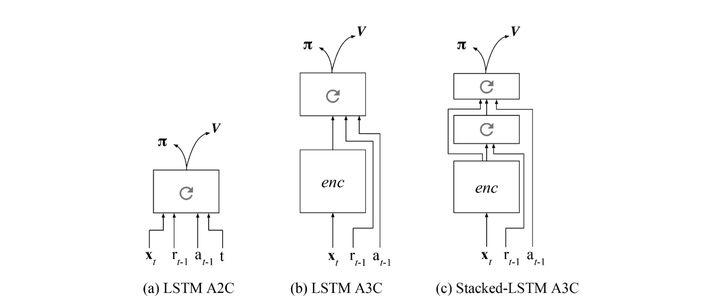
7. 通过训练一个好的base model的方法,并且同时应用到监督学习和强化学习
基本思路:之前的方法都只能局限在监督学习或强化学习上,能搞个更通用的?是不是相比finetune学习一个更好的base model就能work?
主要方法包括:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks 等。
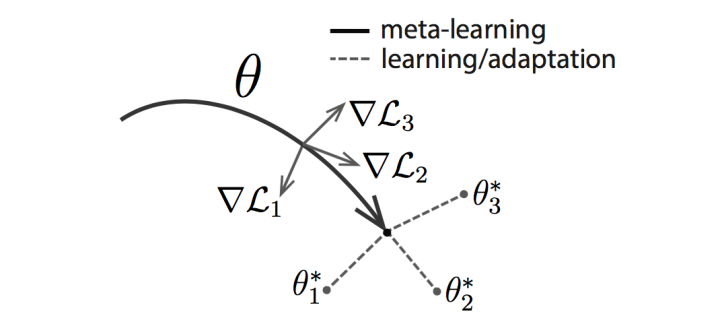
这篇文章的基本思路是同时启动多个任务,然后获取不同任务学习的合成梯度方向来更新,从而学习一个共同的最佳base。
8. 利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
主要方法包括:Meta-Learning with Temporal Convolutions 等。

直接利用之前的历史数据,思路极其简单,效果极其之好,是目前omniglot,mini imagenet图像识别的state-of-the-art。
9. 预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?
主要方法包括:Learning to Learn: Meta-Critic Networks for Sample Efficient Learning 等。
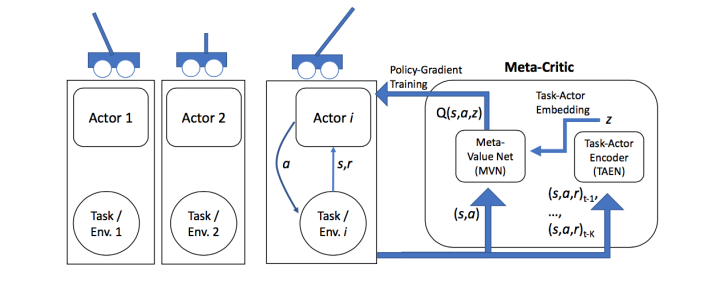
本文构造了一个Meta-Critic Network(包含Meta Value Network和Task-Actor Encoder)来学习预测Actor Network的Loss。对于Reinforcement Learning而言,这个Loss就是Q Value。
10. 小结
这是两年前的综述了,但是感觉质量很高。当然,后续又有了一些新进展。在应用上,元学习应用到了更广泛的问题上,例如小样本图像分类、视觉导航、机器翻译和语音识别等。在算法上,最值得一提的应该就是元强化学习,因为这样的结合将有望使智能体能够更快速地学习新的任务,这个能力对于部署在复杂和不断变化的世界中的智能体来说是至关重要的。
具体的,以上关于元学习的论文已经介绍了在策略梯度(policy gradient)和密集奖励(dense rewards)的有限环境中将元学习应用于强化学习的初步结果。此后,很多学者对这个方法产生了浓厚的兴趣,也有更多论文展示了将元学习理念应用到更广泛的环境中,比如:从人类演示中学习、模仿学习以及基于模型的强化学习。除了元学习模型参数外,还考虑了超参数和损失函数。为了解决稀疏奖励设置问题,也有了一种利用元学习来探索策略的方法。
尽管取得了这些进展,样本效率仍然是一项挑战。当考虑将 meta-RL 应用于实际中更复杂的任务时,快速适应这些任务则需要更有效的探索策略。因此在实际学习任务中,需要考虑如何解决元训练样本效率低下的问题。因此,伯克利 AI 研究院基于这些问题进行了深入研究,并开发了一种旨在解决这两个问题的算法。
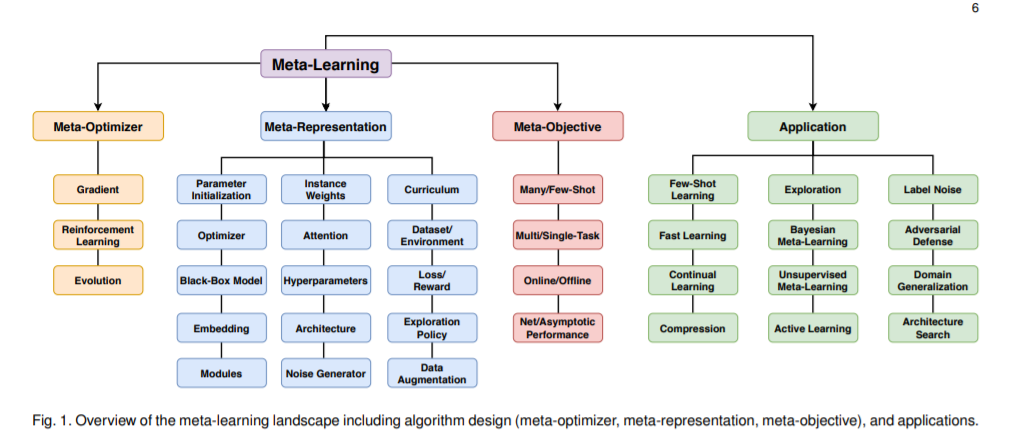
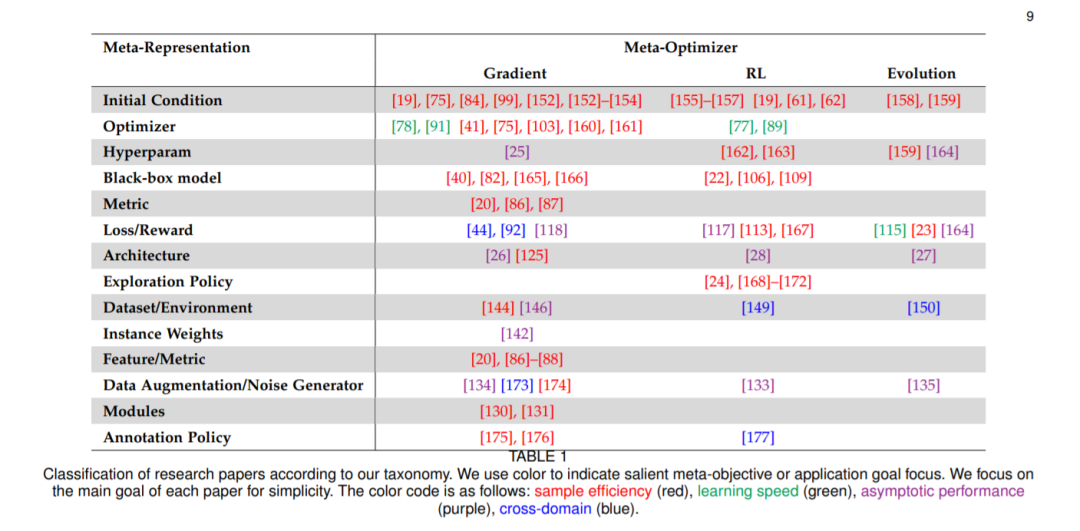
最后分享看到的元学习 meta learning 的2020综述论文。提出了一个新的分类法,对元学习方法的空间进行了更全面的细分:[认真看图]
论文标题:Meta-Learning in Neural Networks: A Survey
论文链接:https://arxiv.org/abs/2004.05439
二、Few-shot Learning 小样本学习综述
Few-shot Learning 可以说是 元学习 Meta Learning 在监督学习领域的一个应用,当然也有它自己研究领域的东西。
本节来自香港科技大学和第四范式的综述:Generalizing from a Few Examples: A Survey on Few-Shot Learning
该综述已被 ACM Computing Surveys 接收,还建立了 GitHub repo,持续更新:https://github.com/tata1661/FewShotPapers
1. 基本概念
机器学习在数据密集型应用中非常成功,但当数据集很小时,它常常受到阻碍。为了解决这一问题,近年来提出了小样本学习(FSL)。利用先验知识,FSL可以快速地泛化到只包含少量有监督信息的样本的新任务中。
大多数人认为FSL就是 meta learning,其实不是。FSL可以是各种形式的学习(例如监督、半监督、强化学习、迁移学习等),本质上的定义取决于可用的数据。但现在大多数时候在解决FSL任务时,采用的都是 meta Learning 的一些方法。
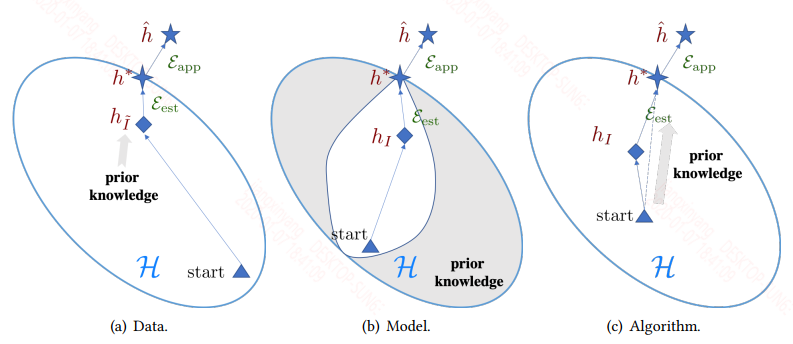
基于各个方法利用先验知识处理核心问题的方式,该综述将 FSL 方法分为三大类:
- 数据:利用先验知识增强监督信号
- 模型:利用先验知识缩小假设空间的大小
- 算法:利用先验知识更改给定假设空间中对最优假设的搜索
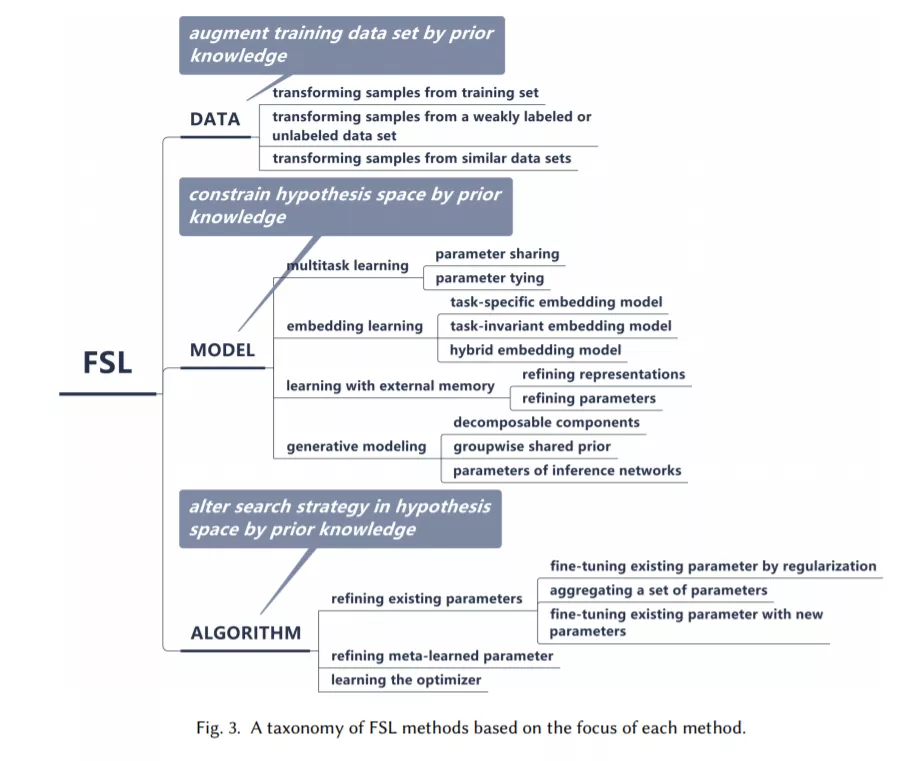
基于此,该综述将现有的 FSL 方法纳入此框架,得到如下分类体系:
2. DATA
数据增强的方式有很多种,平时也被使用的比较多,在这里作者将数据增强的方法概括成三类:

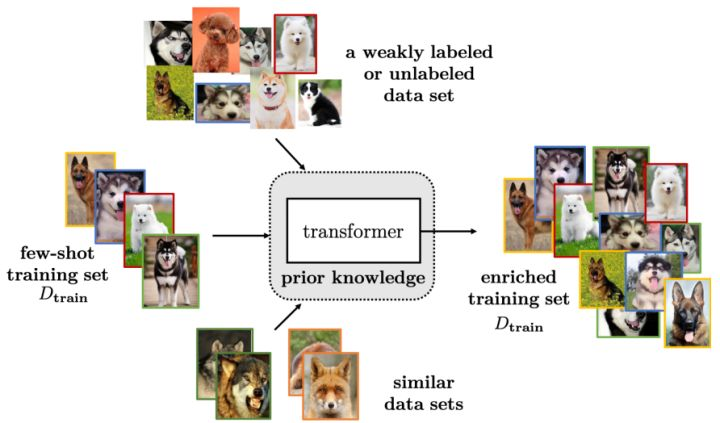
总之,数据增强没有什么神秘感,可以是手动在数据上修改(例如图片的旋转、句子中的同义词替换等),也可以是复杂的生成模型(生成和真实数据相近的数据)。数据增强的方式有很多种,大量合适的增强一定程度上可以缓解FSL问题,但其能力还是有限的。
3. MODEL
和模型剪枝中的理念类似,你一开始给一个小的模型,这个模型空间离真实假设太远了。而你给一个大的模型空间,它离真实假设近的概率比较大,然后通过先验知识去掉哪些离真实假设远的假设。
作者根据使用不同的先验知识将MODEL的方法分成4类:

3.1 Multitask Learning
对于多个共享信息的任务(例如数据相同任务不同、数据和任务都不同等),都可以用多任务学习来训练。
多任务分为硬参数共享和软参数共享两种模式:
- 硬参数共享认为任务之间的假设空间是有部分重叠的,体现在模型上就是有部分参数是共享的。而共享的参数可以是模型的前面一些层,表征任务的低阶信息。也可以是在嵌入层之后,不同的嵌入层将不同任务嵌入到同一不变任务空间,然后共享模型参数等。
- 软参数共享不再显示的共享模型参数,而是让不同的任务的参数相似。这就可以通过不同任务的参数正则,或者通过损失来影响参数的相似,以此让不同任务的假设空间类似。
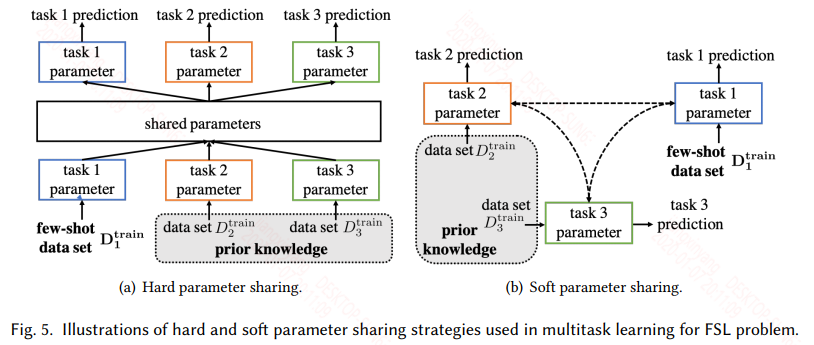
多任务通过多个任务来限制模型的假设空间:
- 对于硬参数共享,多个任务会有一个共享的假设空间,然后每个任务还有自己特定的假设空间。
- 对于软参数共享也类似,软参数更灵活,但也需要精心设计。
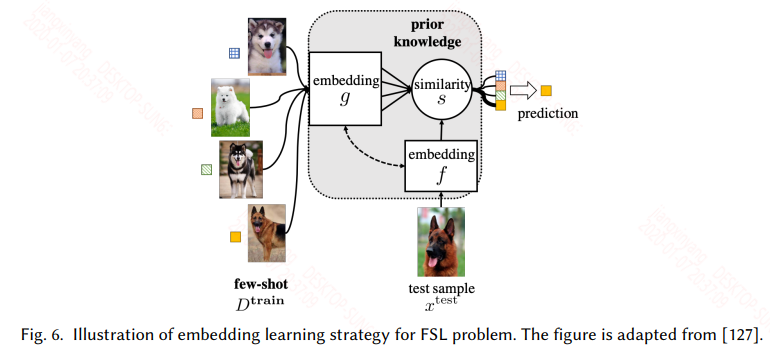
3.2 Embedding Learning
嵌入学习很好理解,将训练集中所有的样本通过一个函数 f 嵌入到一个低维可分的空间Z,然后将测试集中的样本通过一个函数 g 嵌入到这个低维空间Z,然后计算测试样本和所有训练样本的相似度,选择相似度最高的样本的标签作为测试样本的标签。
根据task-specific和task-invariant,以及两者的结合可以分为三种,嵌入学习如下:
- Task-specific是在任务自身的训练集上训练的,通过构造同类样本相同,不同类样本不同的样本对作为数据集,这样数据***有一个爆炸式的扩充,可以提高样本的复杂度,然后可以用如siamese network等来训练。
- Task-invariant是在一个大的且和任务相似的source数据集上训练一个嵌入模型,然后直接用于当前任务的训练集和测试集嵌入。
- 实际上现在用的比较多的还是两者的结合,既可以利用大的通用数据集学习通用特征,又可以在特定任务上学习特定的特征,而现在常用的训练模式是meta learning中的metric-based的方式,此类常见的模型有match network、prototypical network、relation network等。
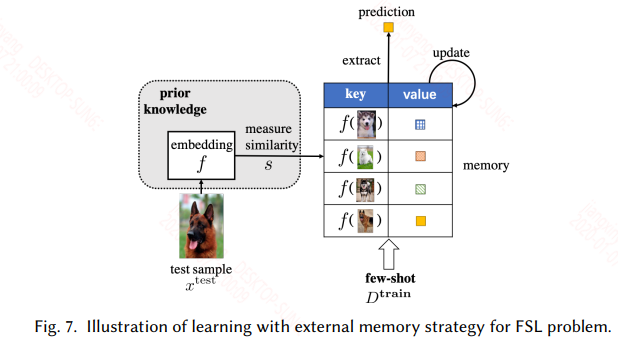
3.3 Learning with External Memory
具有外部存储机制的网络都可以用来处理这一类问题,其实本质上和迁移学习一样。只不过这里不更新模型的参数,只更新外部记忆库。外部记忆库一般都是一个矩阵,如神经图灵机,其外部记忆库具有读写操作。
在这里就是在一个用大量类似的数据训练的具有外部存储机制的网络上,用具体task的样本来更新外部记忆库。这类方法需要精心设计才能有好的效果,比如外部记忆库写入或更新的规则可能就影响模型能够在当前任务上的表现。具体的如下图所示:
3.4 Generative Modeling
引入了生成式的模型来解FSL问题。
4. ALGORITHM
在机器学习中,通常使用SGD及其变体(例如ADAM、RMSProp等)来寻找最优参数。但是在FSL中,样本数量很少,这种方法就失效了。
在这一节,我们不再限制假设空间。根据使用不同的先验知识,可以将ALGORITHM分为下面3类:

4.1 Refine Existing Parameters
本质就是pretrained + fine-tuning的模式,最常见的就是直接在pre-trianed的模型上直接fine-tuning参数,还可以在一个新的网络上使用pre-trained的部分参数来初始化等。
4.2 Refine Meta-learned Parameters
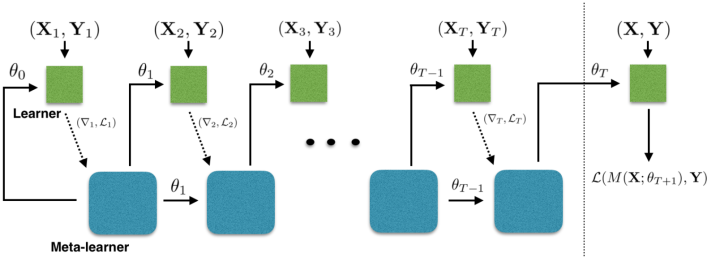
该小节是基于 meta learning 的解决方法,利用元学习器学习一个好的初始化参数。之后在新的任务上,只要对这个初始化参数少量迭代更新就能很好的适应新的任务。这种方法最经典的模型就是MAML,MAML的训练模式如下图所示:
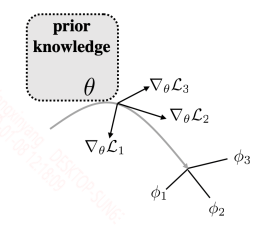
上面的参数是元学习器的参数,最后用多个任务的梯度矢量和来更新参数。这样的方式也有一个问题,就是新的任务的特性必须要和元训练中的任务相近,这样值才能作为一个较好的初始化值,否则效果会很差。因此,也就有不少研究在根据新任务的数据集来动态的生成一个适合它的初始化参数。
4.3 Learn Search Steps
上一节使用元学习来获得一个较好的初始化参数,而本节旨在用元学习来学习一个参数更新的策略。针对每一个子任务能给定特定的优化方式实际上是提高性能的唯一方法,这里就是设计一个元优化器来为特定的任务提供特定的优化方法,具体的如下图所示:

梯度的更新也可以写成:

在这里使用RNN来实现,因为RNN具有时序记忆功能,而梯度迭代的过程中正好是一个时序操作。具体的训练如下图所示:
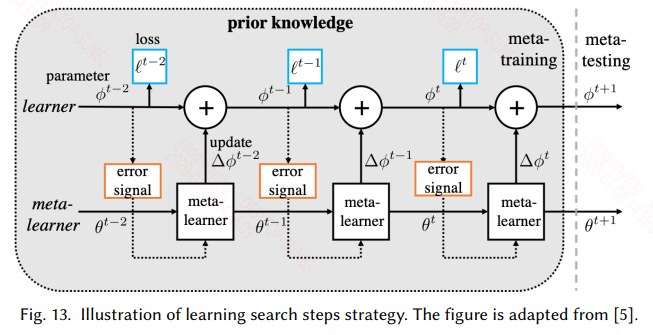
训练过程大致如下:
- 对于每个任务,同样划分训练集和测试集,训练集经过meta-learner得到一系列的梯度,因为RNN每个时刻都有输出,因此每个时刻的梯度都去依次更新learner的参数ϕ。这样看就相当于一个batch的样本就更新了T次learner
- 训练完一轮之后,用测试集在learner上的到的梯度来更新meta-learner的参数
这和上一节面临的问题一样,meta-learner 学到的更新策略是针对这一类任务的,一旦新任务和元训练中的任务偏差较大时,这种更新策略可能就失效了。
5. FUTURE WORKS
未来的方向可能有:
- 从使用的先验数据:例如利用更多的先验知识、多模态的数据等
- 从使用的模型方法:用新的网络结构去替换以前的,例如用transformer替换RNN
- 从使用的场景:现在FSL在字符识别、图像识别、小样本分割等取得效果,在目标检测、目标跟踪、NLP中的各项任务上等值得尝试
- 理论分析
- ......
欢迎持续关注我的下一篇随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(二):生成对抗网络 GAN
欢迎持续关注我的下一篇随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(三):迁移学习
欢迎持续关注我的下一篇随笔:人工智能中小样本问题相关的系列模型演变及学习笔记(四):知识蒸馏、增量学习
如果您对异常检测感兴趣,欢迎浏览我的另一篇博客:异常检测算法演变及学习笔记
如果您对智能推荐感兴趣,欢迎浏览我的另一篇博客:智能推荐算法演变及学习笔记 、CTR预估模型演变及学习笔记
如果您对知识图谱感兴趣,欢迎浏览我的另一篇博客:行业知识图谱的构建及应用、基于图模型的智能推荐算法学习笔记
如果您对时间序列分析感兴趣,欢迎浏览我的另一篇博客:时间序列分析中预测类问题下的建模方案 、深度学习中的序列模型演变及学习笔记
如果您对数据挖掘感兴趣,欢迎浏览我的另一篇博客:数据挖掘比赛/项目全流程介绍 、机器学习中的聚类算法演变及学习笔记
如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)、人工智能领域常用的开源框架和库(含机器学习/深度学习/强化学习/知识图谱/图神经网络)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
如题,本专栏将持续分享应届生求职就业过程中的经验,包括但不限于求职准备、撰写简历、网申投递、笔面试经验、offer比较等,哨哥将全程陪伴,欢迎关注哨哥,一起寻找最美丽的offer!
